
今回は、最短一致モードの使用方法について詳しく説明します。 最短一致モードを使用する際の注意事項は何ですか?実際のケースを見てみましょう。
前書き
最近、正規表現を使用してWebページから何かを取得したいと考えていました。内容は複雑ではありませんでしたが、多くの問題がありました。以下で言うことはあまりありませんが、詳細な紹介を見てみましょう:
<h1>hello world</h1>
の h1 の開始タグと終了タグを一致させるなど、タグの先頭と末尾を一致させるために正規表現を使用する場合、多くの人は次のように書くかもしれません。こんな感じ
/<.*h1>/g
でも本当にこれでいいの?
* 一致する文字は前の文字の 0 個以上と一致し、貪欲一致であるため
、次の結果が得られます。
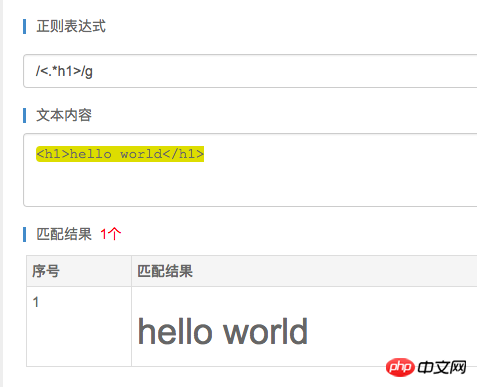
明らかにこれは私たちが望んでいることではないので、貪欲なマッチングを最小のマッチングに変更するにはどうすればよいでしょうか?
/<.*?h1>/g
以下に示すように、上記の書き方で十分です:
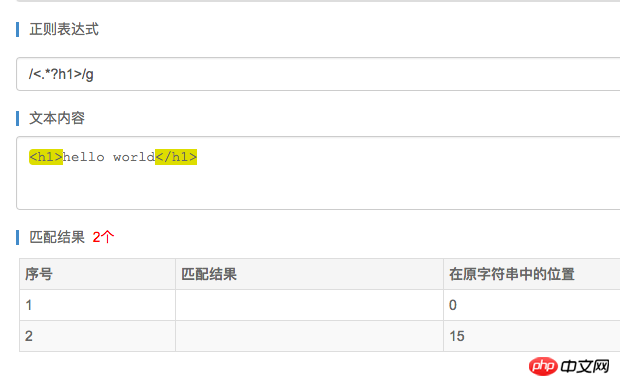
実際、原則は次のようになります。 ? も欲張りマッチであり、0 から 1 にのみマッチするため、最初のマッチに一致すると終了するので、 * が複数の貪欲マッチにマッチすることを防ぎます。
追記: ご参考までに、さらに便利な正規表現ツールを 2 つ紹介します:
この記事のケースを読んだ後は、この方法を習得したと思います。その他の関連記事は php 中国語 Web サイトにあります。
推奨読書:
Linux grep と正規表現の使用正規表現を使用してログイン ページの入力内容を検証する以上が最短一致モードの使い方の詳しい説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



