
今回は、JS 正規表現の解析の原則と構文、および JS 正規表現の原則と構文を解析する際の 注意事項について説明します。実際のケースを見てみましょう。
鄭澤は、文字列の海で迷ったときに、いつでもアイデアを与えてくれる灯台のようなものです。ユーザー、それが偽物の場合は、いつでもそれを識別するのに役立ちます。正常な場合は、懐中電灯のようなもので、何かを見つける必要がある場合には、いつでも欲しいものを手に入れるのに役立ちます...——スティンソンより抜粋中国語並列文演習「正規」文学的な抜粋を鑑賞した後、JSの正規表現を正式に整理していきます この記事の主な目的は正規表現の使い方を忘れないようにすることですので、整理して書きました。私の習熟度を高め、使用法を向上させることが主な目的です。間違いがある場合は、お気軽に教えてください。 この記事は「ワンストップ」というタイトルなので、「ドラゴン」にふさわしい内容でなければならず、規則性の原則、構文の概要、JS (ES5) の規則性、ES6 での規則性の拡張、規則性を実践するためのアイデアが含まれます。できるだけ深く掘り下げて、簡単な方法で説明してみます(応用方法を知りたいだけなら)。 、その後、基本的にニーズを満たす 2 番目、3 番目、および 5 番目のパートを読んでください。JS をマスターしたい場合は、定期的なものなので、申し訳ないと思って私の考えに従ってください。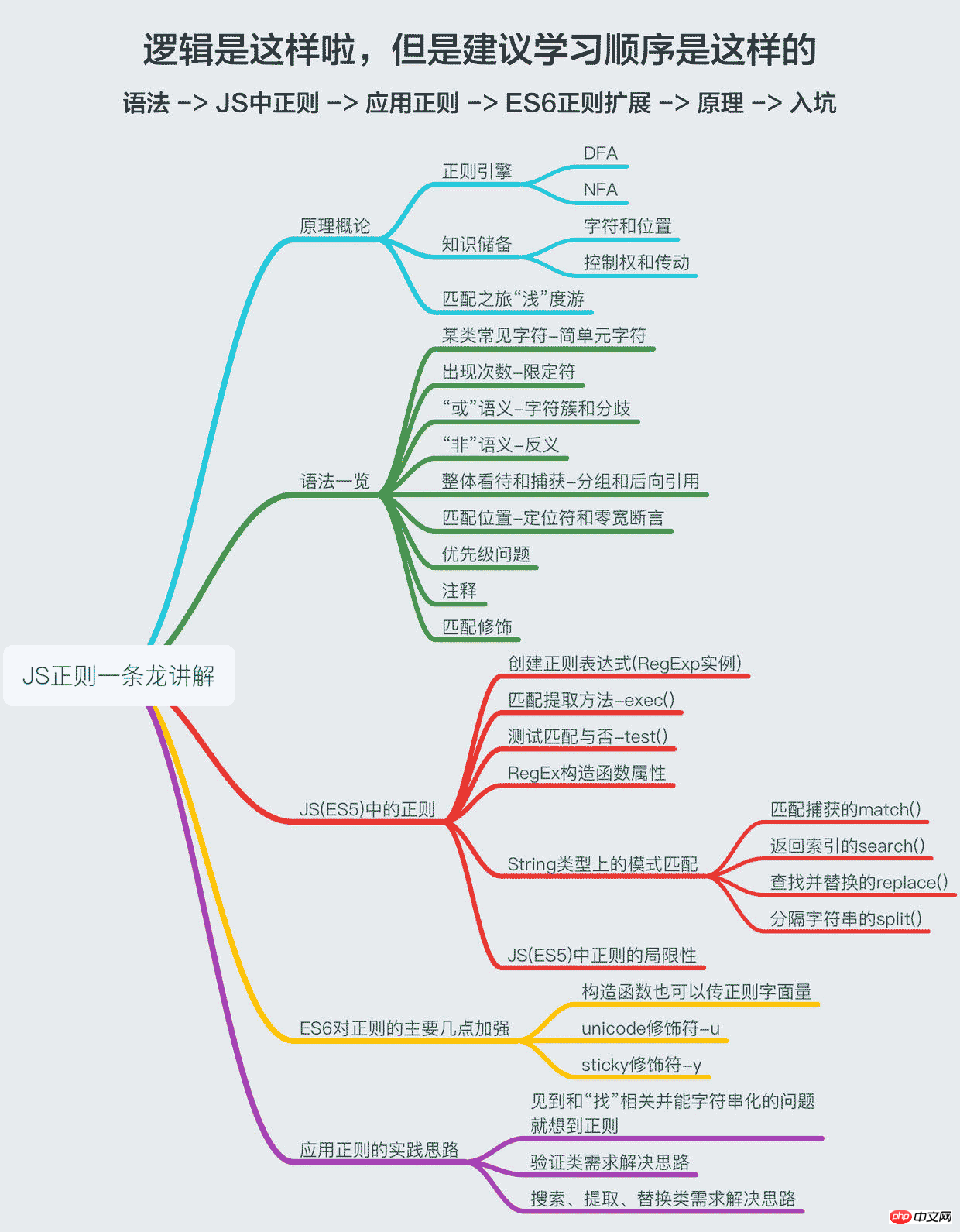
1. 原則の概要
正規表現を初めて使い始めたとき、コンピューターは一体どうやって正規表現 に基づいて文字列を照合するのでしょうか?その後、「計算理論」という本に出会い、規則性、DFA、NFA の概念とつながりを知り、突然悟りを開きました。
しかし、本当に正規表現を原理的に理解したいのであれば、最善の方法は次のとおりです: まず、O'REILLY の「Animal Story」シリーズなど、正規表現に特化した本を探します。あなたはそれを持っています
2. 通常のエンジンを自分で実装します。
1. 通常のエンジン 正規表現が有効な理由は、JS が実行できる理由と同じです。正規表現に基づいてマシンをシミュレートするアルゴリズム マシン、このマシンにはテスト対象の文字列を読み取ることによって、これらの状態の間をジャンプし、最終的に「ハッピー エンディング」状態で停止する場合は、Say I Do になります。あなたは良い人だと言ってください
。正規表現を限られたステップ数で結果を計算できるマシンに変換することで、エンジンが実装されます。
1. DFA(決定論的有限オートマトン) 決定論的有限オートマトン 2. 非決定論的有限オートマトン の2つに分類されます。 NFA
ここでの「決定的」とは、ある文字の入力に対して、マシンの状態が必ず a から b にジャンプすることを意味し、「非決定的」とは、ある文字の入力に対して、このマシンが入力としていくつかの状態ジャンプ方法を持つことができます。ここでの「有限」とは、状態が制限されており、特定の文字列が受け入れられるか善人カードが発行されるかを限られた数のステップ内で決定できることを意味します。この機械のルールが一度設定されれば、誰にも見られずに自ら判断できるという意味として理解されたい。
DFA エンジンはバックトラックする必要がないため、一般にマッチング効率が高くなりますが、キャプチャ グループをサポートしていないため、逆参照や $ 形式の参照、ルックアラウンド、一部の NFA もサポートしていません非貪欲モードなどのエンジン固有の機能。
正規表現、DFA、NFA について詳しく知りたい場合は、「計算理論」を読むと、特定の正規表現に基づいてオートマトンを描画できます。
2. 知識の備蓄このセクションは、正規表現、特に文字とは何か、位置とは何かを理解するのに非常に役立ちます。
2.1 正規表現における文字列 - n 文字、n+1 位置

上記の「笑い」の文字列には、あなたが見ることができる文字が合計 8 つと、賢い人だけが見ることができる 9 つの位置があります。なぜキャラクターとポジションが必要なのでしょうか?場所を合わせることができるからです。
次に、「占有文字」と「ゼロ幅」を理解するためにさらに一歩進んでみましょう:
サブ正規表現が位置ではなく文字に一致し、最終結果に保存される場合、このサブ正規表現はたとえば、/ha/ (ha と一致) は文字を占有します。
サブレギュラーが文字ではなく位置に一致する場合、または一致したコンテンツが結果に保存されない場合もあります。位置とみなされます)、この部分式は /read(?=ing)/ のようにゼロ幅になります (読み取り値と一致しますが、結果に read のみが入ります。構文については以下で詳しく説明します。これは単なる例です。)ここで、(?=ing) はゼロ幅であり、本質的に位置を表します。
所有文字は相互排他的であり、幅ゼロは相互排他的ではありません。つまり、1 つの文字は同時に 1 つの部分式でのみ一致しますが、1 つの位置は複数の幅ゼロの部分式で同時に一致できます。たとえば、/aa/ は a に一致できません。この文字列の a は正規表現の最初の a 文字にのみ一致し、2 番目の a に同時に一致することはできませんが、複数存在する可能性があります。たとえば、/bba/ は a に一致します。正規表現には単語の先頭を表す 2 つの b メタ文字がありますが、これら 2 つの b は同時に位置 0 (この例では) に一致します。
注: 文字と位置について話すときは文字列について話し、占有文字とゼロ幅について話すときは正規表現について話します。
2.2 制御と送信
ブログの投稿や情報を検索しているときに、これらの 2 つの単語に遭遇することがあります。説明は次のとおりです:
どの正規部分式が参照しているか (通常の文字、メタ文字、またはシーケンスの可能性があります)。のメタ文字) が文字列と一致している場合、コントロールは横にあります。
送信は、正規表現エンジンのメカニズムを指し、送信デバイスは文字列内の正規表現が一致し始める場所を特定します。
正規表現が一致を開始すると、通常、部分表現が制御を引き継ぎ、文字列内の特定の位置から一致を試みます。その位置は、前の部分表現の正常終了位置から始まります。
例を挙げると、read(?=ing)ingsbook は reading book と一致します。この正規表現は read、(?=ing)、ing、s、book の 5 つの部分表現と見なされます。もちろん、read とみなすこともできます。 as 4 単一文字の部分式。ここでは便宜上このように扱います。 read は位置 0 から開始され、位置 4 と一致します。次の (?=ing) は位置 4 から一致し続けます。位置 4 の後に実際に ing が続いていることがわかり、一致が成功したことがアサートされます。全体 (?=ing) は位置に一致します (ここでゼロ幅が何であるかをよく理解できます)。次に、次の ing は位置 4 から位置 7 に一致し、s は位置 7 から位置 8 に一致します。 、最後のブックはポジション 8 からマッチします。ポジション 12 で、マッチ全体が完了します。
3. 「浅い」マッチングの旅(スキップ可能)
ここまでは言いましたが、私たちは自分たちを通常のエンジンとして捉え、最小単位である「キャラクター」と「ポジション」を段階的に見てみましょう通常のマッチングのプロセスで、いくつかの例を挙げます。
3.1 基本的なマッチング
正規表現: 簡単
ソース文字列: とても簡単
マッチングプロセス: まず、正規表現文字 e が制御を取り、文字列の位置 0 からマッチングを開始し、一致する文字列文字 'S' に遭遇します。が失敗すると、通常のエンジンが前進して位置 1 から試行し、文字列文字「o」に遭遇すると、一致は失敗し、送信は続行されます。当然、後続のスペースも失敗するため、位置 3 から一致を試みます。文字列文字 'e'、制御は正規表現の部分表現 (ここにも文字) a に渡され、最後に成功した一致の終了位置 4 から一致を試み、文字列文字 'a と正常に一致します。 'と入力し、このように'y'にマッチングを続けるとマッチングが完了し、マッチング結果が簡単になります。
3.2 ゼロ幅マッチング
正则:^(?=[aeiou])[a-z]+$ 源字符串:apple
まず、この正規表現は、このような完全な文字列を最初から最後まで一致させます。この文字列全体は小文字のみで構成され、a、e、i、o の 5 文字で始まります。 、および u のいずれかの文字で始まります。
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
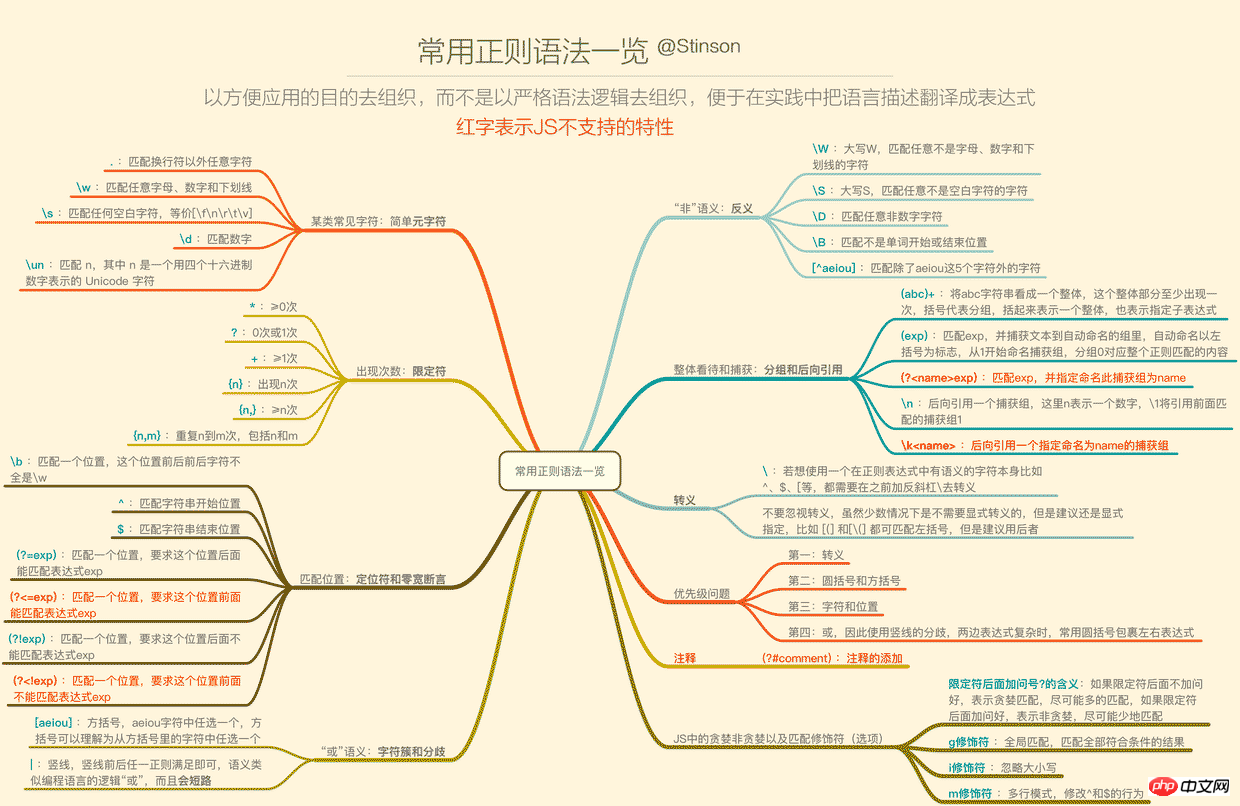
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a? は文字 a が 0 回または 1 回出現する回数を表します
a{5} は文字 a が 5 回連続して出現する回数を表します
a{5,} は連続する回数を表します文字 a >= 5 回の出現
a{5,10} は、文字 a の連続出現回数が 5 回と 10 回を含む 5 回から 10 回であることを意味します
特定の位置の式に一致します。 式はすべてゼロ幅で、主に 2 つの部分で構成されます。1 つは特定の位置に一致するロケーターで、もう 1 つはゼロ幅アサーションです。一定の条件を満たさなければならないポジション。
以下のロケーターが一般的に使用されます:
b は単語の境界位置に一致します。正確には、この位置の前後のすべての文字が w で記述できるわけではないため、u597dbabc のように「」に一致します。良いABC「」の。
^ は文字列の開始位置、つまり位置 0 に一致します。 RegExp オブジェクトの Multiline プロパティが設定されている場合、 ^ は 'n' または 'r' の後の位置にも一致します
$ は末尾に一致しますRegExp オブジェクトの Multiline プロパティが設定されている場合、$ は 'n' または 'r' の前の位置にも一致します
ゼロ幅アサーション (JS でサポート) には次の 2 つがあります:
(?=exp) は Position に一致します。この位置の右側は式 exp に一致します。この式は 1 つの位置にのみ一致しますが、この位置の右側と右側のものに対する要件があることに注意してください。 「reading」と一致するために read(?=ing ) を使用するなど、side は結果には入れられません。結果は「read」であり、「ing」は結果に入れられません
(?!exp ) は位置に一致しますが、この位置の右側は式 exp に一致することはできません
例えば「または」の意味を表現することがよくあります。 、これらの文字のどれか 1 つを指定するか、5 つの数字または 5 つの文字を一致させると OK になります。
文字クラスターは、角括弧内の文字のいずれかを表す文字レベルの「または」セマンティクスを表現するために使用できます:
[abc] は、3 つの文字 a、b、c のいずれかを表します。文字または数字が連続している場合は、- を使用してそれらを表すことができます。[b-f] は b から f までの任意の文字を表します。[(ab)(cd)] は文字列「ab」または「ab」と一致するために使用されません。 "cd" ですが、a、b、c、d、(,) の 6 文字のいずれかに一致します。つまり、「文字列 ab または cd に一致する」という要件を表現したい場合、これを書くことはできません。 ab|cd はこのようになります。ただし、論理的に言えば、括弧自体をバックスラッシュでエスケープする必要がありますが、それでも、括弧は明示的にエスケープすることをお勧めします。
さまざまな用途 式の式レベルでの「or」セマンティクスは、左または右の任意の式と一致することを意味します:上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
ついに、JS の規則性についての説明を 10,000 文字以上書き終えました。書き終えた後、規則性の習熟度が 1 歩前進したことがわかりました。非常に役立つので、頻繁に整理することをお勧めします。そして、それを自分自身に喜んで共有してください。これは誰にとっても非常に有益です。読んでくれる人に感謝します。
この記事の事例を読んだ後は、この方法を習得したと思います。さらに興味深い情報については、php 中国語 Web サイトの他の関連記事に注目してください。
推奨読書:
通常の非キャプチャグループとキャプチャグループの使用の詳細な説明
ユーザーが入力した銀行カード番号を照合するためのLuhnアルゴリズム
以上がJS 正規表現の原則と構文を分析するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



