

正規表現を使用した一致する単一文字の詳細な分析
今回は、正規表現を使用して単一の文字を照合する場合の詳細な分析をお届けします。正規表現を使用して単一の文字を照合する場合の注意事項は何ですか?実際のケースを見てみましょう。
この記事の例では、単一文字の一致に関する正規表現のチュートリアルについて説明します。参考として、次のようにみんなと共有してください。
注: すべての例では、正規表現の一致結果はソース テキストの [] の間に含まれています。一部の例は、Java を使用して実装されます。 Java 自体での正規表現の使用法については、対応する場所で説明します。すべての Java サンプルは JDK1.6.0_13 でテストされています。 javaテストコード:
/**
* 根据正则表达式和要匹配的源文本,输出匹配结果
* @param regex 正则表达式
* @param sourceText 要匹配的源文本
*/
public static void matchAndPrint(String regex, String sourceText){
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(sourceText);
while(matcher.find()){
System.out.println(matcher.group());
}
}
1. マッチング結果は1つだけです まず、それ自体はプレーンですが、今日は簡単な正規表現を見てみましょうテキストですが、正規表現です。例を見てみましょう:
ソーステキスト:
昨日は歴史、明日は謎、しかし今日は贈り物正規表現:
today結果: 昨日は歴史、明日は謎ですが。
[今日]は贈り物です。分析: ここで使用される正規表現はプレーン テキストであり、ソース テキストの今日と一致します。
matchAndPrint メソッドを呼び出すと、出力結果は次のようになります:
today
2. 複数の一致結果がありますソーステキスト:
昨日は歴史、明日は謎、しかし今日は贈り物です。正規表現:
is結果: 昨日は歴史、明日は謎ですが、
[今日]は贈り物です。 分析: ソーステキストには 3 つの is がありますが、4 つの is があります出力は、履歴にあるため、も一致します。
matchAndPrint メソッドを呼び出すと、出力結果は次のようになります:
isis
is
is
3. 大文字と小文字の問題 正規表現は区別するためのものです文字 大文字と小文字は区別されませんが、多くの正規表現実装では大文字と小文字を区別しない一致操作もサポートされています。
JavaScript では、i フラグを使用して、大文字と小文字を区別しない一致を実行します。 Java では、大文字と小文字を区別しないようにしたい場合は、正規表現をコンパイルするときに次のように指定できます。 Patternpattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE);
前に見た正規表現はすべて静的なプレーン テキストです。正規表現の力を反映していません。次に、正規表現を使用して予測できない文字と一致する方法を見てみましょう。
正規表現では、検索対象を指定するために
特殊文字(または文字のコレクション) が使用されます。 . 文字 (英語のステータスピリオド) は、任意の 1 文字と一致します。 DOS の ? 文字および SQL の _ (アンダースコア) 文字に相当します。例: 正規表現 c.t は、cat、cut、cot などに一致します。例を見てみましょう。 テキスト:
orders1.txtorders2.txt
sales1.txt
salesA.txt
orders3.txt
sales2.txt
売上.txt
正規表現:
sales.結果:
orders1.txt
orders2.txt
【売上1】.txt
【売上A】.txt
orders3.txt
【売上2】.txt
分析: ポジティブ 次に、式販売。結果からわかるように、 は文字、数字、およびそれ自体と一致します。 7 つのファイルのうち 4 つがこのパターンに一致します。
matchAndPrint メソッドが呼び出された場合、出力結果は次のようになります:salesA
sales2
sales.
3. 特殊文字の一致
.通常のキャラクター式には特別な意味があります。パターンに . が必要な場合は、正規表現における特別な意味ではなく、 . 文字自体が必要であることを正規表現に伝える方法を見つける必要があります。これを行うには、 . 文字を前に付けてエスケープする必要があります。これはメタキャラクター(文字自体の意味ではなく、この文字が特別な意味を持っていることを示すメタキャラクター)でもあります。次の例を考えてみましょう。その後に続く数字に関係なく、na または sa で始まるファイルを検索します。
テキスト:sales.txt
na1.txt
na2.txt
sa1.txt
sanatxt.txt
正規表現: .a..txt
結果:【sal】es.txt
【na1】.txt
【na2】.txt
【sa1】.txt
【sanatxt】。
分析: この正規表現では na1.txt、na2.txt、sa1.txt が見つかりましたが、2 つの予期しない結果も見つかりました。正規表現 .a..txt 内の . 文字は任意の文字と一致するためです。 . 文字自体と一致させるには、エスケープを使用する必要があります。正規表現を .a..txt に変更すると、ニーズを満たすことができます。注: Java を使用する場合、正規表現 .a..txt は Java 言語のエスケープ文字でもあるため、.a.\.txt として記述する必要があります。
4. 概要
正規表現は、実際にはいくつかの文字で構成される文字列です。これらの文字は、通常の文字 (プレーン テキスト) またはメタ文字 (特別な意味を持つ特殊文字) にすることができます。ここでは、ユニット文字に合わせて通常文字とメタ文字を使用する方法を紹介します。 . 任意の文字に一致します。文字をエスケープするために使用されます。正規表現では、特別な意味を持つ文字シーケンスは常に文字で始まります。この記事の事例を読んだ後は、この方法を習得したと思います。さらに興味深い情報については、php 中国語 Web サイトの他の関連記事に注目してください。
推奨読書:phpとjsを使用して数字と文字の定期的なパスワード照合を実装する
以上が正規表現を使用した一致する単一文字の詳細な分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7698
7698
 15
1640
14
1393
52
1287
25
1229
29
15
1640
14
1393
52
1287
25
1229
29

 Java の Character.isDigit() 関数を使用して、文字が数字かどうかを判断します
Jul 27, 2023 am 09:32 AM
Java の Character.isDigit() 関数を使用して、文字が数字かどうかを判断します
Jul 27, 2023 am 09:32 AM
文字が数字かどうかを判断するには、Java の Character.isDigit() 関数を使用します。文字はコンピュータ内部で ASCII コードの形式で表されます。各文字には対応する ASCII コードがあります。このうち、0~9の数字に対応するASCIIコードの値は、それぞれ48~57となります。文字が数値かどうかを判断するには、Java の Character クラスによって提供される isDigit() メソッドを使用できます。 isDigit() メソッドは Character クラスに属します
 Wordで矢印を入力する方法
Apr 16, 2023 pm 11:37 PM
Wordで矢印を入力する方法
Apr 16, 2023 pm 11:37 PM
オートコレクトを使用して Word で矢印を入力する方法 Word で矢印を入力する最も速い方法の 1 つは、定義済みのオートコレクト ショートカットを使用することです。特定の一連の文字を入力すると、Word はそれらの文字を矢印記号に自動的に変換します。この方法を使用すると、さまざまな矢印スタイルを描画できます。 Word でオートコレクトを使用して矢印を入力するには: 矢印を表示する文書内の位置にカーソルを移動します。次の文字の組み合わせのいずれかを入力します。 入力した文字を矢印記号に修正したくない場合は、キーボードのバックスペース キーを押してください。
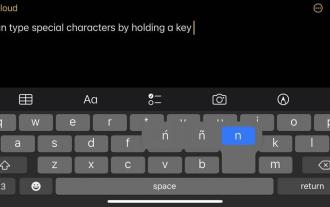 iPhone や Mac で度記号などの拡張文字を入力するにはどうすればよいですか?
Apr 22, 2023 pm 02:01 PM
iPhone や Mac で度記号などの拡張文字を入力するにはどうすればよいですか?
Apr 22, 2023 pm 02:01 PM
物理キーボードまたは数字キーボードでは、表面上に提供される文字オプションの数が限られています。ただし、iPhone、iPad、Mac ではアクセント付き文字や特殊文字などにアクセスする方法がいくつかあります。標準の iOS キーボードを使用すると、大文字、小文字、標準の数字、句読点、文字にすばやくアクセスできます。もちろん他にもたくさんのキャラクターがいます。発音記号を含む文字から逆さまの疑問符まで選択できます。隠れた特殊文字を見つけてしまったかもしれません。そうでない場合は、iPhone、iPad、Mac でアクセスする方法を次に示します。 iPhone および iPad で拡張文字にアクセスする方法 iPhone または iPad で拡張文字を取得するのは非常に簡単です。 「お知らせ」には「
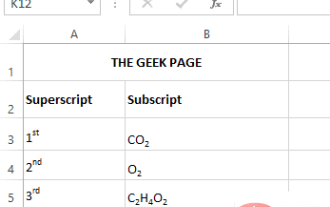 Microsoft Excel で上付き文字と下付き文字の書式設定オプションを適用する方法
Apr 14, 2023 pm 12:07 PM
Microsoft Excel で上付き文字と下付き文字の書式設定オプションを適用する方法
Apr 14, 2023 pm 12:07 PM
上付き文字は、通常のテキスト行の少し上に設定する必要がある、文字または数字の 1 つまたは複数の文字です。たとえば、1st と書く必要がある場合、st の文字は 1 の文字より少し高い位置にある必要があります。同様に、下付き文字は文字のグループまたは単一の文字であり、通常のテキスト レベルよりわずかに低く設定する必要があります。たとえば、化学式を書くときは、通常の文字行の下に数字を配置する必要があります。次のスクリーンショットは、上付き文字と下付き文字の書式設定の例をいくつか示しています。難しい作業のように思えるかもしれませんが、テキストに上付き文字と下付き文字の書式を適用するのは実際には非常に簡単です。この記事では、上付き文字または下付き文字を使用してテキストを簡単に書式設定する方法をいくつかの簡単な手順で説明します。この記事を楽しんで読んでいただければ幸いです。 Excelで上付き文字を適用する方法
 matplotlibで中国語の文字を表示する正しい方法
Jan 13, 2024 am 11:03 AM
matplotlibで中国語の文字を表示する正しい方法
Jan 13, 2024 am 11:03 AM
matplotlib で中国語の文字を正しく表示することは、多くの中国人ユーザーがよく遭遇する問題です。デフォルトでは、matplotlib は英語フォントを使用するため、中国語の文字を正しく表示できません。この問題を解決するには、正しい中国語フォントを設定し、それを matplotlib に適用する必要があります。以下は、matplotlib で中国語の文字を正しく表示するのに役立ついくつかの具体的なコード例です。まず、必要なライブラリをインポートする必要があります: importmatplot
 Golang を使用して文字が文字であるかどうかを判断する方法
Dec 23, 2023 am 11:57 AM
Golang を使用して文字が文字であるかどうかを判断する方法
Dec 23, 2023 am 11:57 AM
Golang を使用して文字が文字であるかどうかを判断する方法 Golang では、Unicode パッケージの IsLetter 関数を使用して、文字が文字であるかどうかを判断できます。 IsLetter 関数は、指定された文字が文字であるかどうかを確認します。次に、Golangを使って文字かどうかを判定するコードを書く方法を詳しく紹介します。まず、コードを記述する新しい Go ファイルを作成する必要があります。ファイルに「main.go」という名前を付けることができます。コード
 JavaのEnterキーの文字表現についてですが、どれでしょうか?
Mar 29, 2024 am 11:48 AM
JavaのEnterキーの文字表現についてですが、どれでしょうか?
Mar 29, 2024 am 11:48 AM
Java における Enter キーの文字表現は ` です。 Java では、` は改行文字を表し、この文字が出現するとテキスト出力が折り返されます。以下は、`` を使用して Enter キーを表す方法を示す簡単なコード例です。 publicclassMain{publicstaticvoidmain(String[]args){System.out.println("これは、この最初の行です。
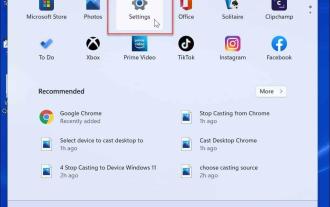 Windows 11 で特殊文字を入力する方法
Apr 17, 2023 pm 08:28 PM
Windows 11 で特殊文字を入力する方法
Apr 17, 2023 pm 08:28 PM
タブレット モードでタッチ キーボードを有効にする タッチ スクリーンのラップトップをお持ちの場合は、Windows 11 でタッチ キーボードを使用して複数の特殊文字を入力できます。おそらくこれが特殊文字を追加する最も簡単な方法です。 Windows 11 でタッチスクリーンの特殊文字を有効にする: [スタート] メニューを開き、[設定] を選択します。 [設定] が開いたら、[時刻と言語] > [入力] > [タッチ キーボード] に移動します。 [入力] メニューで、[キーボードが使用できない場合はタッチ キーボードを表示する] オプションをオンにします。タブレット モードなしでタッチ キーボードを有効にする タッチ キーボードにアクセスするもう 1 つの方法は、タッチ キーボードをタスク バーにフルタイムで表示することです。タッチ キーボードにアクセスできるようにするには、Windows 11 にタッチ キーボードを表示するように指示する必要があります。次の手順を実行します。 [スタート] メニューから、
