

この記事では主に、クローラー フレームワークのリクエスト メソッドを完全に記述する方法について説明します。これは非常に参考になるので、皆さんのお役に立てれば幸いです。編集者をフォローして見てみましょう。皆さんのお役に立てれば幸いです。
クローラー フレームワークを生成します:
1. スクレイピー クローラー プロジェクトを作成します
2. スパイダー クローラーを構成します
4.クローラーを実行する、Web ページを取得します
特定の操作:
1. プロジェクトを作成します
という名前のプロジェクトを定義します: python123demo
方法:
cm d、d:Dドライブに入る, cd pycodes ファイルpycodes
を入力し、
scrapy startproject python123demo
と入力すると、pycodesでファイルが生成されます:

 _init_.py はそうではありませんユーザーの書き込みが必要です
_init_.py はそうではありませんユーザーの書き込みが必要です


2. プロジェクトでスクレイピー クローラーを生成します
コマンドを実行し、クローラー名とクロールされた Web サイトを指定します
クローラー:
 demo という名前のスパイダーを生成します
demo という名前のスパイダーを生成します
demo.py のみを生成します。その内容は次のとおりです:
 name = 'demo' 現在のクローラー名は、demo
name = 'demo' 現在のクローラー名は、demo
です許可_domains = " Web サイトのドメイン名の下にあるリンクをクロールします。ドメイン名は cmd コマンド コンソールから入力されます
start_urls = [] クロールされた最初のページ
parse() は、対応するページを処理するために使用されます。コンテンツを解析して辞書を形成し、新しい URL クローリング リクエストを検出します
3. ニーズを満たすように生成されたスパイダー クローラーを構成します
解析されたページをファイルに保存します
デモを変更します。 py ファイル

4. クローラーを実行して Web ページを取得します
cmd を開き、クロールするコマンド ラインを入力します
 その後、コンピューターにエラーが表示されました
その後、コンピューターにエラーが表示されました
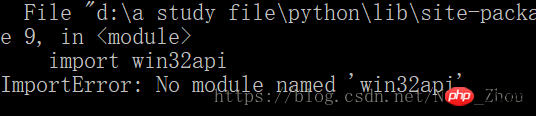 Windows システム この問題を解決するには、Py32Win モジュールをインストールする必要がありますが、公式 Web サイトのリンクから exe を直接インストールすると、何百ものエラーが発生します。
Windows システム この問題を解決するには、Py32Win モジュールをインストールする必要がありますが、公式 Web サイトのリンクから exe を直接インストールすると、何百ものエラーが発生します。
pip3 install pypiwin32
これは py3 の解決策です
注: py3 バージョンに対して pip install pypiwin32 コマンドを使用すると、エラーが発生します
インストールが完了したら、再度クローラーを実行してください、成功しました!
キャプチャ ページは、demo.html ファイルに保存されます

demo.py 対応する完全なコード:

2 つのバージョンは同等です:

以上が完全なクローラー フレームワークを作成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



