

スレッド プールはスレッドを繰り返し管理し、大量のスレッドを作成してオーバーヘッドを増加させることを避けるのに役立つことを私たちは知っています。
スレッド プールを適切に使用すると、次の 3 つの明らかな利点が得られます。
1. リソース消費の削減: すでに作成されたスレッドを再利用することで、スレッドの作成と破棄のコストを削減します。
2. 応答速度の向上: タスクの到着を待つ必要がありません。すぐに実行されました。
3. スレッドの管理性の向上: スレッド プールは、統合された方法で管理、割り当て、調整、監視できます。
Java 派生のスレッド プールは ThreadPoolExecutor クラスに実装されており、これが今日の議論の焦点でもあります
Jdk は ThreadPoolExecutor クラスを使用してスレッド プールを作成します。その構築メソッドを見てみましょう。
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:<br>
* {@code corePoolSize < 0}<br>
* {@code keepAliveTime < 0}<br>
* {@code maximumPoolSize <= 0}<br>
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}int corePoolSize, //コアスレッドの数
int minimumPoolSize, //スレッドの最大数
long keepAliveTime, //コアスレッド数以外のスレッドが存在する場合にスレッドが存続する時間コアスレッドはアイドル状態です
TimeUnit Unit, //生存時間の単位
BlockingQueue ThreadFactory threadFactory, //新しいスレッドを使用します RejectedExecutionHandler handler // タスクが実行できない場合のハンドラ (スレッド拒否ポリシー) ThreadPoolExecutor には ctl と呼ばれる状態制御属性があります。 AtomicInteger 型の変数です。int 値には、次の 2 つの概念の情報を格納できます。 workerCount: workerCountOf メソッドを通じて取得された、現在のプール内の有効なスレッドの数を示します。workerCount の上限は (2^) 29)-1. (最終的に ctl の下位 29 ビットに格納されます) runState: workerCountOf メソッドを通じて取得され、最終的に ctl の上位 3 ビットに格納される現在のスレッド プールのステータスを示します。スレッド プール全体。次の値を持ちます。それぞれの意味は次のとおりです: 実行中: 新しいスレッドを追加でき、キュー内のスレッドを同時に処理できます。 SHUTDOWN: 新しいスレッドを追加しませんが、キュー内のスレッドを処理します。 STOP は、新しいスレッドを追加せず、キュー内のスレッドを処理しません。 - 3=29 なので、29 ビット左にシフトされた 5 つの状態は次のとおりです。 0000000000000000000 停止: 0110000000000000000000000 0000 runStateOf メソッドと workerCountOf メソッドは、ctl 変数の 2 つの有効な値をどのように削除しますか?その中で、1 つのフィールドに 2 つの値を格納できる CAPACITY が最も重要なフィールドであることがわかります。 明らかに、その焦点は上位 3 ビットが 0、下位 29 ビットが 1 であるということです。このように、workerCountOf メソッドでは、CAPACITY と ctl が & 操作を実行すると、上位 3 ビットがすべて取得されます。 0、ctl の下位 29 ビットと下位 29 ビットは同じ値を持ちます。この値は workerCount ;workQueueコアクラス変数
ctl 変数
0100000000000000000000000000000
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
workers/**
* The queue used for holding tasks and handing off to worker
* threads. We do not require that workQueue.poll() returning
* null necessarily means that workQueue.isEmpty(), so rely
* solely on isEmpty to see if the queue is empty (which we must
* do for example when deciding whether to transition from
* SHUTDOWN to TIDYING). This accommodates special-purpose
* queues such as DelayQueues for which poll() is allowed to
* return null even if it may later return non-null when delays
* expire.
*/
private final BlockingQueue<Runnable> workQueue;
コア内部クラス
Worker
/**
* Class Worker mainly maintains interrupt control state for
* threads running tasks, along with other minor bookkeeping.
* This class opportunistically extends AbstractQueuedSynchronizer
* to simplify acquiring and releasing a lock surrounding each
* task execution. This protects against interrupts that are
* intended to wake up a worker thread waiting for a task from
* instead interrupting a task being run. We implement a simple
* non-reentrant mutual exclusion lock rather than use
* ReentrantLock because we do not want worker tasks to be able to
* reacquire the lock when they invoke pool control methods like
* setCorePoolSize. Additionally, to suppress interrupts until
* the thread actually starts running tasks, we initialize lock
* state to a negative value, and clear it upon start (in
* runWorker).
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
//设置AQS的同步状态private volatile int state,是一个计数器,大于0代表锁已经被获取
// 在调用runWorker()前,禁止interrupt中断,在interruptIfStarted()方法中会判断 getState()>=0
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);//根据当前worker创建一个线程对象
//当前worker本身就是一个runnable任务,也就是不会用参数的firstTask创建线程,而是调用当前worker.run()时调用firstTask.run()
//后面在addworker中,我们会启动worker对象中组合的Thread,而我们的执行逻辑runWorker方法是在worker的run方法中被调用。
//为什么执行thread的run方法会调用worker的run方法呢,原因就是在这里进行了注入,将worker本身this注入到了thread中
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}//runWorker()是ThreadPoolExecutor的方法
// Lock methods
//
// The value 0 represents the unlocked state. 0代表“没被锁定”状态
// The value 1 represents the locked state. 1代表“锁定”状态
protected boolean isHeldExclusively() {
return getState() != 0;
}
/**
* 尝试获取锁
* 重写AQS的tryAcquire(),AQS本来就是让子类来实现的
*/
protected boolean tryAcquire(int unused) {
//尝试一次将state从0设置为1,即“锁定”状态,但由于每次都是state 0->1,而不是+1,那么说明不可重入
//且state==-1时也不会获取到锁
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
/**
* 尝试释放锁
* 不是state-1,而是置为0
*/
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
/**
* 中断(如果运行)
* shutdownNow时会循环对worker线程执行
* 且不需要获取worker锁,即使在worker运行时也可以中断
*/
void interruptIfStarted() {
Thread t;
//如果state>=0、t!=null、且t没有被中断
//new Worker()时state==-1,说明不能中断
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}我们看worker类时,会发现最重要的几个部分在于它里面定义了一个Thread thread和Runnable firstTask。看到这里,我们可能会比较奇怪,我们只是要一个可以执行的线程,这里放一个Thread和一个Runnable的变量做什么呢?
其实之所以Worker自己实现Runnable,并创建Thread,在firstTask外包一层,是因为要通过Worker负责控制中断,而firstTask这个工作任务只是负责执行业务,worker的run方法调用了runWorker方法,在这里面,worker里的firstTask的run方法被执行。稍后我们会聚焦这个执行任务的runWorker方法。
好了,基本上我们将线程池的几个主角,ctl,workQueue,workers,Worker简单介绍了一遍,现在,我们来看看线程池是怎么玩的。
这是线程池实现类外露供给外部实现提交线程任务command的核心方法,对于无需了解线程池内部的使用者来说,这个方法就是把某个任务交给线程池,正常情况下,这个任务会在未来某个时刻被执行,实现和注释如下:
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
* * 在未来的某个时刻执行给定的任务。这个任务用一个新线程执行,或者用一个线程池中已经存在的线程执行
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
* 如果任务无法被提交执行,要么是因为这个Executor已经被shutdown关闭,要么是已经达到其容量上限,任务会被当前的RejectedExecutionHandler处理
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/ public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
* 如果运行的线程少于corePoolSize,尝试开启一个新线程去运行command,command作为这个线程的第一个任务
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
* 如果任务成功放入队列,我们仍需要一个双重校验去确认是否应该新建一个线程(因为可能存在有些线程在我们上次检查后死了)
* 或者 从我们进入这个方法后,pool被关闭了
* 所以我们需要再次检查state,如果线程池停止了需要回滚入队列,如果池中没有线程了,新开启 一个线程
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
* 如果无法将任务入队列(可能队列满了),需要新开区一个线程(自己:往maxPoolSize发展)
* 如果失败了,说明线程池shutdown 或者 饱和了,所以我们拒绝任务
*/
int c = ctl.get();
// 1、如果当前线程数少于corePoolSize(可能是由于addWorker()操作已经包含对线程池状态的判断,如此处没加,而入workQueue前加了)
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
/**
* 没有成功addWorker(),再次获取c(凡是需要再次用ctl做判断时,都会再次调用ctl.get())
* 失败的原因可能是:
* 1、线程池已经shutdown,shutdown的线程池不再接收新任务
* 2、workerCountOf(c) < corePoolSize 判断后,由于并发,别的线程先创建了worker线程,导致workerCount>=corePoolSize
*/
c = ctl.get();
}
/**
* 2、如果线程池RUNNING状态,且入队列成功
*/
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
/**
* 再次校验放入workerQueue中的任务是否能被执行
* 1、如果线程池不是运行状态了,应该拒绝添加新任务,从workQueue中删除任务
* 2、如果线程池是运行状态,或者从workQueue中删除任务失败(刚好有一个线程执行完毕,并消耗了这个任务),
* 确保还有线程执行任务(只要有一个就够了)
*/
//如果再次校验过程中,线程池不是RUNNING状态,并且remove(command)--workQueue.remove()成功,拒绝当前command
if (! isRunning(recheck) && remove(command))
reject(command);
//如果当前worker数量为0,通过addWorker(null, false)创建一个线程,其任务为null
//为什么只检查运行的worker数量是不是0呢?? 为什么不和corePoolSize比较呢??
//只保证有一个worker线程可以从queue中获取任务执行就行了??
//因为只要还有活动的worker线程,就可以消费workerQueue中的任务
else if (workerCountOf(recheck) == 0)
addWorker(null, false);//第一个参数为null,说明只为新建一个worker线程,没有指定firstTask
////第二个参数为true代表占用corePoolSize,false占用maxPoolSize
}
/**
* 3、如果线程池不是running状态 或者 无法入队列
* 尝试开启新线程,扩容至maxPoolSize,如果addWork(command, false)失败了,拒绝当前command
*/
else if (!addWorker(command, false))
reject(command);
}我们可以简单归纳如下(注:图来源见水印,谢谢大神的归纳):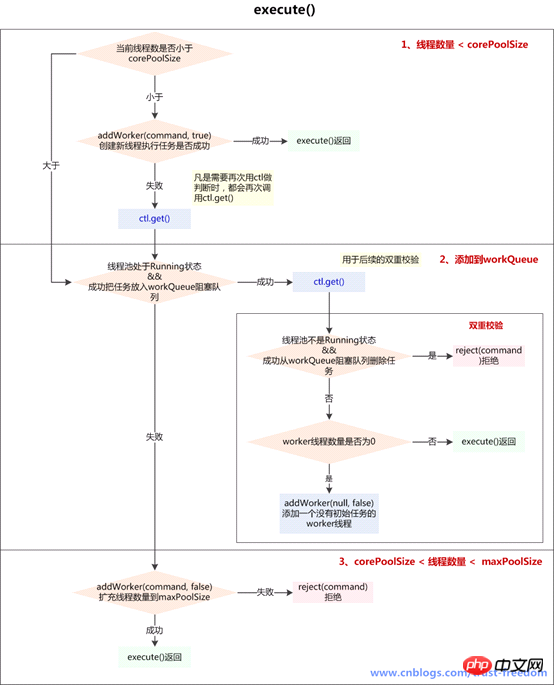
在execute方法中,我们看到核心的逻辑是由addWorker方法来实现的,当我们将一个任务提交给线程池,线程池会如何处理,就是主要由这个方法加以规范:
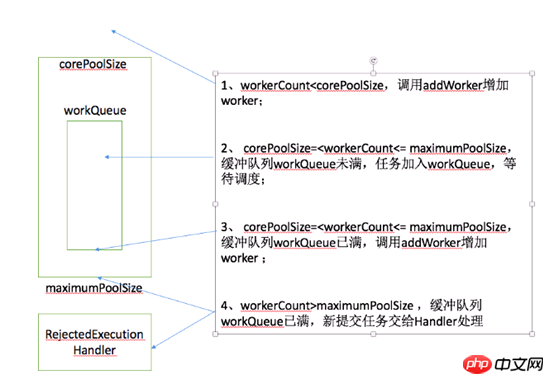
该方法有两个参数:
firstTask: worker线程的初始任务,可以为空
core: true:将corePoolSize作为上限,false:将maximumPoolSize作为上限
排列组合,addWorker方法有4种传参的方式:
1、addWorker(command, true) 2、addWorker(command, false) 3、addWorker(null, false) 4、addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
第一个:线程数小于corePoolSize时,放一个需要处理的task进Workers Set。如果Workers Set长度超过corePoolSize,就返回false 第二个:当队列被放满时,就尝试将这个新来的task直接放入Workers Set,而此时Workers Set的长度限制是maximumPoolSize。如果线程池也满了的话就返回false 第三个:放入一个空的task进workers Set,长度限制是maximumPoolSize。这样一个task为空的worker在线程执行的时候会去任务队列里拿任务,这样就相当于创建了一个新的线程,只是没有马上分配任务 第四个:这个方法就是放一个null的task进Workers Set,而且是在小于corePoolSize时,如果此时Set中的数量已经达到corePoolSize那就返回false,什么也不干。实际使用中是在prestartAllCoreThreads()方法,这个方法用来为线程池预先启动corePoolSize个worker等待从workQueue中获取任务执行
/**
* Checks if a new worker can be added with respect to current
* pool state and the given bound (either core or maximum). If so,
* the worker count is adjusted accordingly, and, if possible, a
* new worker is created and started, running firstTask as its
* first task. This method returns false if the pool is stopped or
* eligible to shut down. It also returns false if the thread
* factory fails to create a thread when asked. If the thread
* creation fails, either due to the thread factory returning
* null, or due to an exception (typically OutOfMemoryError in
* Thread.start()), we roll back cleanly.
* 检查根据当前线程池的状态和给定的边界(core or maximum)是否可以创建一个新的worker
* 如果是这样的话,worker的数量做相应的调整,如果可能的话,创建一个新的worker并启动,参数中的firstTask作为worker的第一个任务
* 如果方法返回false,可能因为pool已经关闭或者调用过了shutdown
* 如果线程工厂创建线程失败,也会失败,返回false
* 如果线程创建失败,要么是因为线程工厂返回null,要么是发生了OutOfMemoryError
*
* @param firstTask the task the new thread should run first (or
* null if none). Workers are created with an initial first task
* (in method execute()) to bypass queuing when there are fewer
* than corePoolSize threads (in which case we always start one),
* or when the queue is full (in which case we must bypass queue).
* Initially idle threads are usually created via
* prestartCoreThread or to replace other dying workers.
*
* @param core if true use corePoolSize as bound, else
* maximumPoolSize. (A boolean indicator is used here rather than a
* value to ensure reads of fresh values after checking other pool
* state).
* @return true if successful
*/
private boolean addWorker(Runnable firstTask, boolean core) {
//外层循环,负责判断线程池状态
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/**
* 线程池的state越小越是运行状态,runnbale=-1,shutdown=0,stop=1,tidying=2,terminated=3
* 1、如果线程池state已经至少是shutdown状态了
* 2、并且以下3个条件任意一个是false
* rs == SHUTDOWN (隐含:rs>=SHUTDOWN)false情况: 线程池状态已经超过shutdown,
* 可能是stop、tidying、terminated其中一个,即线程池已经终止
* firstTask == null (隐含:rs==SHUTDOWN)false情况: firstTask不为空,rs==SHUTDOWN 且 firstTask不为空,
* return false,场景是在线程池已经shutdown后,还要添加新的任务,拒绝
* ! workQueue.isEmpty() (隐含:rs==SHUTDOWN,firstTask==null)false情况: workQueue为空,
* 当firstTask为空时是为了创建一个没有任务的线程,再从workQueue中获取任务,
* 如果workQueue已经为空,那么就没有添加新worker线程的必要了
* return false,即无法addWorker()
*/
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//内层循环,负责worker数量+1
for (;;) {
int wc = workerCountOf(c);
//入参core在这里起作用,表示加入的worker是加入corePool还是非corepool,换句话说,受到哪个size的约束
//如果worker数量>线程池最大上限CAPACITY(即使用int低29位可以容纳的最大值)
//或者( worker数量>corePoolSize 或 worker数量>maximumPoolSize ),即已经超过了给定的边界,不添加worker
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS尝试增加线程数,,如果成功加了wc,那么break跳出检查
//如果失败,证明有竞争,那么重新到retry。
if (compareAndIncrementWorkerCount(c))
break retry;
//如果不成功,重新获取状态继续检查
c = ctl.get(); // Re-read ctl
//如果状态不等于之前获取的state,跳出内层循环,继续去外层循环判断
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
// else CAS失败时因为workerCount改变了,继续内层循环尝试CAS对worker数量+1
}
}
//worker数量+1成功的后续操作
// 添加到workers Set集合,并启动worker线程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//新建worker//构造方法做了三件事//1、设置worker这个AQS锁的同步状态state=-1
w = new Worker(firstTask); //2、将firstTask设置给worker的成员变量firstTask
//3、使用worker自身这个runnable,调用ThreadFactory创建一个线程,并设置给worker的成员变量thread
final Thread t = w.thread;
if (t != null) {
//获取重入锁,并且锁上
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// rs!=SHUTDOWN ||firstTask!=null
// 如果线程池在运行running<shutdown 或者
// 线程池已经shutdown,且firstTask==null(可能是workQueue中仍有未执行完成的任务,创建没有初始任务的worker线程执行)
// worker数量-1的操作在addWorkerFailed()
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // // precheck that t is startable 线程已经启动,抛非法线程状态异常
throw new IllegalThreadStateException();
workers.add(w);
//设置最大的池大小largestPoolSize,workerAdded设置为true
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {//如果往HashSet中添加worker成功,启动线程
//通过t.start()方法正式执行线程。在这里一个线程才算是真正的执行起来了。
t.start();
workerStarted = true;
}
}
} finally {
//如果启动线程失败
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}同样的,我们可以归纳一下: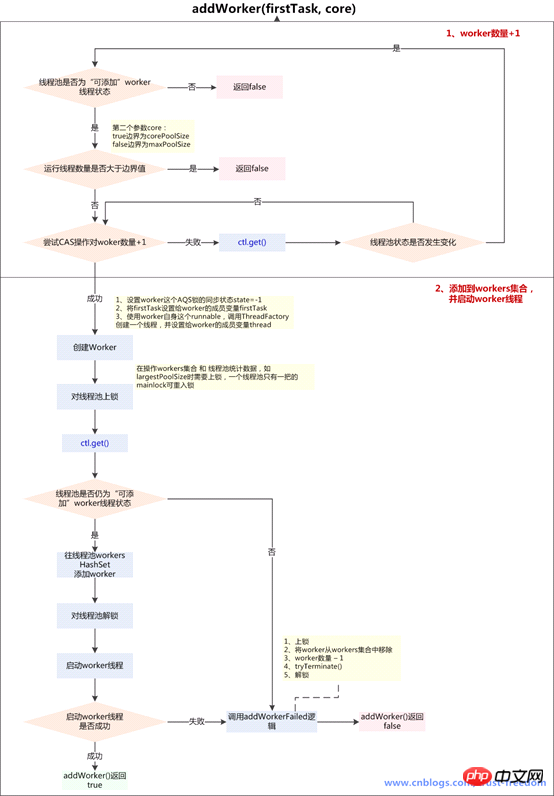
在addWorker方法中,我们将一个新增进去的worker所组合的线程属性thread启动了,但我们知道,在worker的构造方法中,它将自己本身注入到了thread的target属性里,所以绕了一圈,线程启动后,调用的还是worker的run方法,而在这里面,runWorker定义了线程执行的逻辑:
/** * Main worker run loop. Repeatedly gets tasks from queue and * executes them, while coping with a number of issues: * * 1. We may start out with an initial task, in which case we * don't need to get the first one. Otherwise, as long as pool is * running, we get tasks from getTask. If it returns null then the * worker exits due to changed pool state or configuration * parameters. Other exits result from exception throws in * external code, in which case completedAbruptly holds, which * usually leads processWorkerExit to replace this thread. * 我们可能使用一个初始化任务开始,即firstTask为null * 然后只要线程池在运行,我们就从getTask()获取任务 * 如果getTask()返回null,则worker由于改变了线程池状态或参数配置而退出 * 其它退出因为外部代码抛异常了,这会使得completedAbruptly为true,这会导致在processWorkerExit()方法中替换当前线程 * * 2. Before running any task, the lock is acquired to prevent * other pool interrupts while the task is executing, and then we * ensure that unless pool is stopping, this thread does not have * its interrupt set. * 在任何任务执行之前,都需要对worker加锁去防止在任务运行时,其它的线程池中断操作 * clearInterruptsForTaskRun保证除非线程池正在stoping,线程不会被设置中断标示 * * 3. Each task run is preceded by a call to beforeExecute, which * might throw an exception, in which case we cause thread to die * (breaking loop with completedAbruptly true) without processing * the task. * 每个任务执行前会调用beforeExecute(),其中可能抛出一个异常,这种情况下会导致线程die(跳出循环,且completedAbruptly==true),没有执行任务 * 因为beforeExecute()的异常没有cache住,会上抛,跳出循环 * * 4. Assuming beforeExecute completes normally, we run the task, * gathering any of its thrown exceptions to send to afterExecute. * We separately handle RuntimeException, Error (both of which the * specs guarantee that we trap) and arbitrary Throwables. * Because we cannot rethrow Throwables within Runnable.run, we * wrap them within Errors on the way out (to the thread's * UncaughtExceptionHandler). Any thrown exception also * conservatively causes thread to die. * * 5. After task.run completes, we call afterExecute, which may * also throw an exception, which will also cause thread to * die. According to JLS Sec 14.20, this exception is the one that * will be in effect even if task.run throws. * * The net effect of the exception mechanics is that afterExecute * and the thread's UncaughtExceptionHandler have as accurate * information as we can provide about any problems encountered by * user code. * * @param w the worker */
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
//标识线程是不是异常终止的
boolean completedAbruptly = true;
try {
//task不为null情况是初始化worker时,如果task为null,则去队列中取线程--->getTask()
//可以看到,只要getTask方法被调用且返回null,那么worker必定被销毁,而确定一个线程是否应该被销毁的逻辑,在getTask方法中
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//线程开始执行之前执行此方法,可以实现Worker未执行退出,本类中未实现
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();//runWorker方法最本质的存在意义,就是调用task的run方法
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//线程执行后执行,可以实现标识Worker异常中断的功能,本类中未实现
afterExecute(task, thrown);
}
} finally {
task = null;//运行过的task标null
w.completedTasks++;
w.unlock();
}
}
//标识线程不是异常终止的,是因为不满足while条件,被迫销毁的
completedAbruptly = false;
} finally {
//处理worker退出的逻辑
processWorkerExit(w, completedAbruptly);
}
}我们归纳: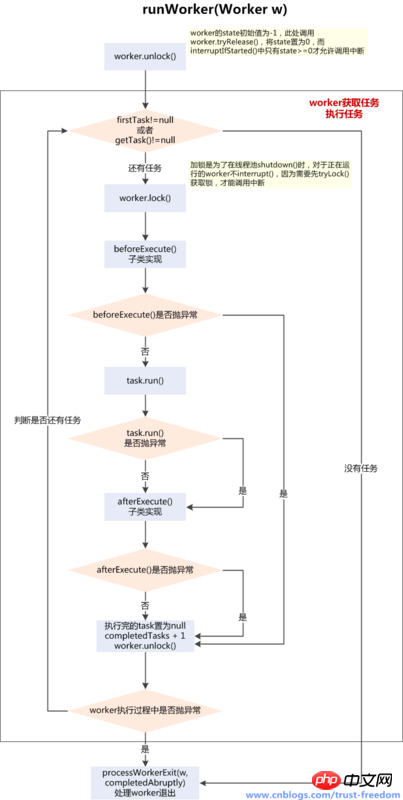
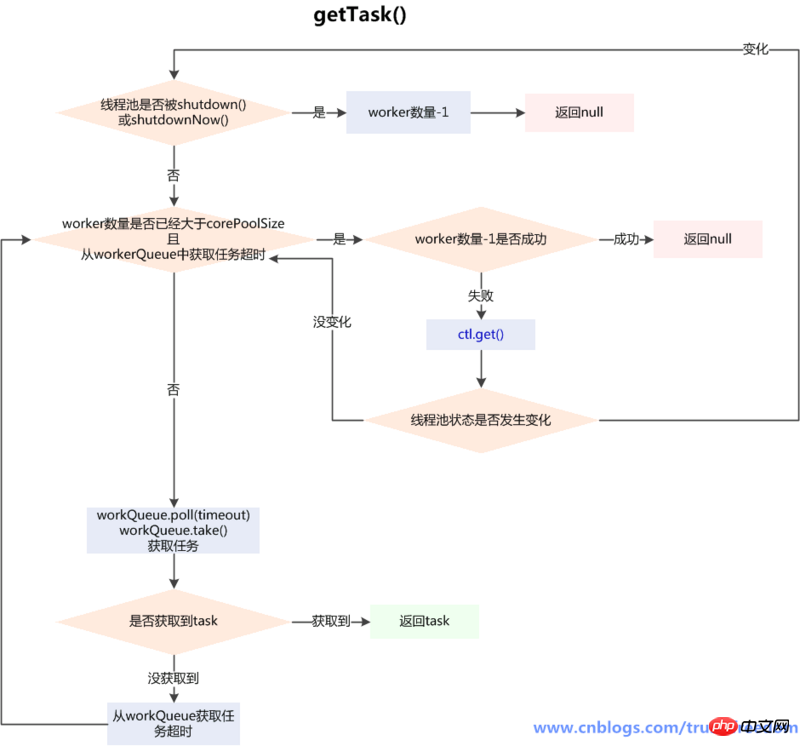
runWorker方法中的getTask()方法是线程处理完一个任务后,从队列中获取新任务的实现,也是处理判断一个线程是否应该被销毁的逻辑所在:
/**
* Performs blocking or timed wait for a task, depending on
* current configuration settings, or returns null if this worker
* must exit because of any of: 以下情况会返回null
* 1. There are more than maximumPoolSize workers (due to
* a call to setMaximumPoolSize).
* 超过了maximumPoolSize设置的线程数量(因为调用了setMaximumPoolSize())
* 2. The pool is stopped.
* 线程池被stop
* 3. The pool is shutdown and the queue is empty.
* 线程池被shutdown,并且workQueue空了
* 4. This worker timed out waiting for a task, and timed-out
* workers are subject to termination (that is,
* {@code allowCoreThreadTimeOut || workerCount > corePoolSize})
* both before and after the timed wait.
* 线程等待任务超时
*
* @return task, or null if the worker must exit, in which case
* workerCount is decremented
* 返回null表示这个worker要结束了,这种情况下workerCount-1
*/
private Runnable getTask() {
// timedOut 主要是判断后面的poll是否要超时
boolean timedOut = false; // Did the last poll() time out?
/**
* 用于判断线程池状态
*/
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
/**
* 对线程池状态的判断,两种情况会workerCount-1,并且返回null
* 线程池状态为shutdown,且workQueue为空(反映了shutdown状态的线程池还是要执行workQueue中剩余的任务的)
* 线程池状态为>=stop()(只有TIDYING和TERMINATED会大于stop)(shutdownNow()会导致变成STOP)(此时不用考虑workQueue的情况)
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();//循环的CAS减少worker数量,直到成功
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
//allowCoreThreadTimeOut字段,表示是否允许核心线程超过闲置时间后被摧毁,默认为false
//我们前面说过,如果getTask方法返回null,那么这个worker只有被销毁一途
//于是这个timed有3种情况
//(1)当没有超过核心线程,且默认allowCoreThreadTimeOut为false时
// timed值为false,除非目前线程数大于最大值,否则下面的if始终进不去,该方法不可能返回null,worker也就不可能被销毁
//(2)当超过核心线程数,且默认allowCoreThreadTimeOut为false时//timed值为true,
//(3)如果allowCoreThreadTimeOut为true,则timed始终为true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//wc > maximumPoolSize则必销毁,因为wc>1也肯定满足
//wc <= maximumPoolSize,如果(timed && timedOut) = true 一般情况下也意味着worker要被销毁,因为超时一般是由阻塞队列为空造成的
//一般情况是这样,那不一般的情况呢?阻塞队列没有为空,但是因为一些原因,还是超时了,这时候取决于wc > 1,它为真就销毁,为假就不销毁。
// 也就是说,如果阻塞队列还有任务,但是wc=1,线程池里只剩下自己这个线程了,那么就不能销毁,这个if不满足,我们的代码继续往下走
//当核心线程数<线程数<最大线程数,或者允许核心线程超时时,
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//如果timed为true那么使用poll取线程。否则使用take()
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
//workQueue.poll():如果在keepAliveTime时间内,阻塞队列还是没有任务,返回null
workQueue.take();
//workQueue.take():如果阻塞队列为空,当前线程会被挂起等待;当队列中有任务加入时,线程被唤醒,take方法返回任务
//如果正常返回,那么返回取到的task。
if (r != null)
return r;
//否则,设为超时,重新执行循环,
timedOut = true;
} catch (InterruptedException retry) {
//在阻塞从workQueue中获取任务时,可以被interrupt()中断,代码中捕获了InterruptedException,重置timedOut为初始值false,再次执行第1步中的判断,满足就继续获取任务,不满足return null,会进入worker退出的流程
timedOut = false;
}
}归纳:
在runWorker方法中,我们看到当不满足while条件后,线程池会执行退出线程的操作,这个操作,就封装在processWorkerExit方法中。
/**
* Performs cleanup and bookkeeping for a dying worker. Called
* only from worker threads. Unless completedAbruptly is set,
* assumes that workerCount has already been adjusted to account
* for exit. This method removes thread from worker set, and
* possibly terminates the pool or replaces the worker if either
* it exited due to user task exception or if fewer than
* corePoolSize workers are running or queue is non-empty but
* there are no workers.
*
* @param w the worker
* @param completedAbruptly if the worker died due to user exception
*/
private void processWorkerExit(Worker w, boolean completedAbruptly) {
//参数:
//worker: 要结束的worker
//completedAbruptly: 是否突然完成(是否因为异常退出)
/**
* 1、worker数量-1
* 如果是突然终止,说明是task执行时异常情况导致,即run()方法执行时发生了异常,那么正在工作的worker线程数量需要-1
* 如果不是突然终止,说明是worker线程没有task可执行了,不用-1,因为已经在getTask()方法中-1了
*/
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted 代码和注释正好相反啊
decrementWorkerCount();
/**
* 2、从Workers Set中移除worker
*/
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks; //把worker的完成任务数加到线程池的完成任务数
workers.remove(w); //从HashSet<Worker>中移除
} finally {
mainLock.unlock();
}
/**
* 3、在对线程池有负效益的操作时,都需要“尝试终止”线程池
* 主要是判断线程池是否满足终止的状态
* 如果状态满足,但线程池还有线程,尝试对其发出中断响应,使其能进入退出流程
* 没有线程了,更新状态为tidying->terminated
*/
tryTerminate();
/**
* 4、是否需要增加worker线程
* 线程池状态是running 或 shutdown
* 如果当前线程是突然终止的,addWorker()
* 如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker()
* 故如果调用线程池shutdown(),直到workQueue为空前,线程池都会维持corePoolSize个线程,然后再逐渐销毁这corePoolSize个线程
*/
int c = ctl.get();
//如果状态是running、shutdown,即tryTerminate()没有成功终止线程池,尝试再添加一个worker
if (runStateLessThan(c, STOP)) {
//不是突然完成的,即没有task任务可以获取而完成的,计算min,并根据当前worker数量判断是否需要addWorker()
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize; //allowCoreThreadTimeOut默认为false,即min默认为corePoolSize
//如果min为0,即不需要维持核心线程数量,且workQueue不为空,至少保持一个线程
if (min == 0 && ! workQueue.isEmpty())
min = 1;
//如果线程数量大于最少数量,直接返回,否则下面至少要addWorker一个
if (workerCountOf(c) >= min)
return; // replacement not needed
}
//添加一个没有firstTask的worker
//只要worker是completedAbruptly突然终止的,或者线程数量小于要维护的数量,就新添一个worker线程,即使是shutdown状态
addWorker(null, false);
}
}总而言之:如果线程池还没有完全终止,就仍需要保持一定数量的线程。
线程池状态是running 或 shutdown的情况下:
A、如果当前线程是突然终止的,addWorker() B、如果当前线程不是突然终止的,但当前线程数量 < 要维护的线程数量,addWorker() 故如果调用线程池shutdown(),直到workQueue为空前,线程池都会维持corePoolSize个线程,然后再逐渐销毁这corePoolSize个线程
前面我们讲过execute方法,其作用是将一个任务提交给线程池,以期在未来的某个时间点被执行。
submit方法在作用上,和execute方法是一样的,将某个任务提交给线程池,让线程池调度线程去执行它。
那么它和execute方法有什么区别呢?我们来看看submit方法的源码:
submit方法的实现在ThreadPoolExecutor的父类AbstractExecutorService类中,有三种重载方法:
/**
* 提交一个 Runnable 任务用于执行,并返回一个表示该任务的 Future。该Future的get方法在成功完成时将会返回null。
* submit 参数: task - 要提交的任务 返回:表示任务等待完成的 Future
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
/**
* 提交一个Runnable 任务用于执行,并返回一个表示该任务的 Future。该 Future 的 get 方法在成功完成时将会返回给定的结果。
* submit 参数: task - 要提交的任务 result - 完成任务时要求返回的结果
* 返回: 表示任务等待完成的 Future
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
}
/**
* 提交一个Callable的任务用于执行,返回一个表示任务的未决结果的 Future。该 Future 的 get
方法在成功完成时将会返回该任务的结果。
* 如果想立即阻塞任务的等待,则可以使用 result =
exec.submit(aCallable).get(); 形式的构造。
* 参数: task - 要提交的任务 返回: 表示任务等待完成的Future
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}源码很简单,submit方法,将任务task封装成FutureTask(newTaskFor方法中就是new了一个FutureTask),然后调用execute。所以submit方法和execute的所有区别,都在这FutureTask所带来的差异化实现上。
总而言之,submit方法将一个任务task用future模式封装成FutureTask对象,提交给线程执行,并将这个FutureTask对象返回,以供主线程在该任务被线程池执行之后得到执行结果。
注意,获得执行结果的方法FutureTask.get(),会阻塞执行该方法的线程。
以上がJava の基礎 - スレッド プールのソース コード分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



