

この記事の内容は、Pythonを使用してjsでコンテンツをクロールする方法を共有することです。必要な友達はそれを参照できます
1. 書くときに取得します。クローラーソフトウェア 必要なコンテンツに遭遇した場合、JavaScriptによって追加され、取得時に空である場合があります。例えば、新浪ニュースのコメント数を取得する場合、通常の方法では取得できません
。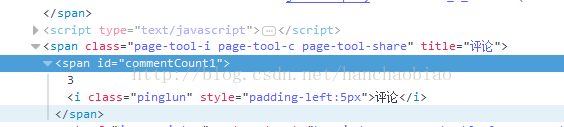
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
この時点で得られる結果は空です。これは、コンテンツが js ファイルに保存されているためです
コメント内容を検索すると、変更されたIn jsに保存されていることが分かりました
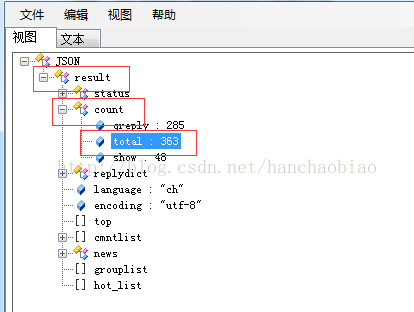
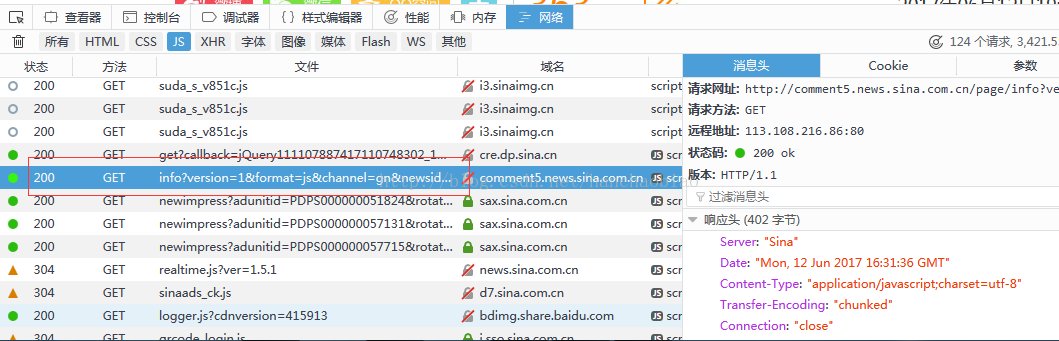 該当する内容をjsonデータビューアに入れると、コメントの総数とコメントの内容が判明しました。 jsファイルにjson形式で保存
該当する内容をjsonデータビューアに入れると、コメントの総数とコメントの内容が判明しました。 jsファイルにjson形式で保存
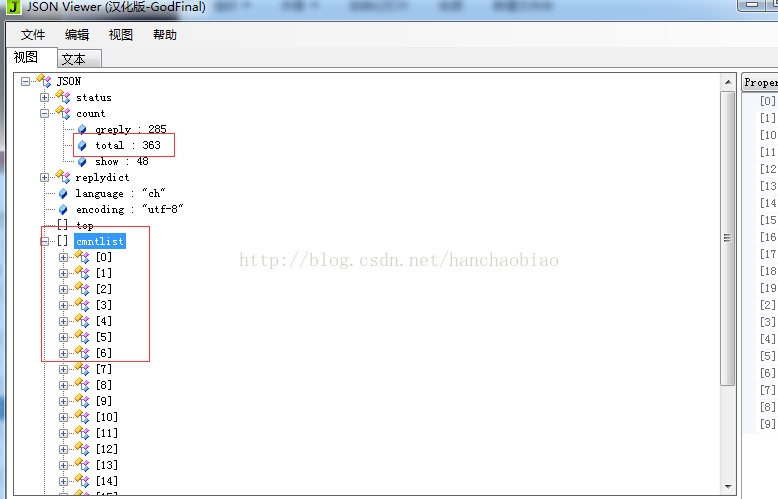
メッセージ内 ヘッダーには、jsファイルへのアクセスパスとリクエストメソッドが表示されます
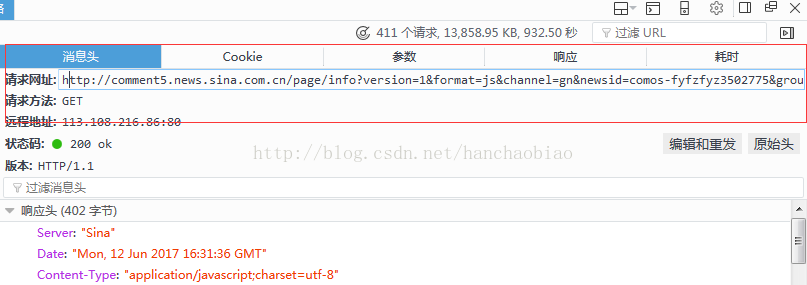 コード例
コード例
import json comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783') comments.encoding = 'utf-8' print(comments) jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据 print(jd['result']['count']['total'])
なぜ jd[ 'result'
'result'
'count'を使用するのか]['total']
以上がPythonを使用してjsのコンテンツをクロールする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



