

Python を学習すると、Web サイトのコンテンツが Ajax の動的リクエストと非同期更新によって生成された JSON データである状況に必ず遭遇します。また、Python を通じて静的な Web コンテンツをクロールする以前の方法は不可能です。そこで、この記事ではその方法について説明します。 Python で ajax によって動的に生成されたデータをクロールします。
Python を学習すると、Web サイトのコンテンツが Ajax の動的リクエストと非同期更新によって生成された JSON データである状況に必ず遭遇し、Python を介して静的な Web コンテンツをクロールする以前の方法は不可能であるため、この記事ではこの記事について説明しますPython で Ajax によって動的に生成されたデータをクロールする方法。
静的Webコンテンツの読み方については、興味のある方はこの記事の内容をご覧ください。
ここでは、淘宝網のコメントをクロールする例を取り上げ、その方法を説明します。
これは主に 4 つのステップに分かれています:
まず、淘宝網のレビューを取得するときに、Ajax はリンク (URL) をリクエストします
次に、Ajax リクエストによって返された JSON データを取得します
3、Pythonを使用してjsonデータを解析します
4 解析結果を保存します
ステップ1:
淘宝のコメントを取得するとき、Ajaxリクエストリンク(URL) ここではChromeブラウザを使用します完了します。 Taobao リンクを開き、検索ボックスで商品を検索します (例: 「靴」)。ここでは最初の商品を選択します。

その後、新しい Web ページにジャンプします。ここでは、ユーザー レビューをクロールする必要があるため、[累積評価] をクリックします。

次に、図に示すように、Web ページを右クリックしてレビュー要素を選択し (または F12 を使用して直接開き)、[ネットワーク] オプションを選択します。写真内:
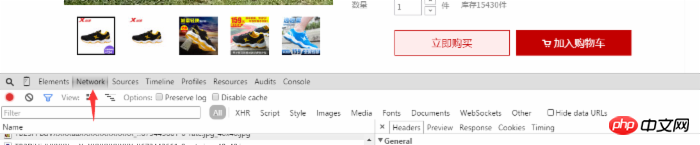
ユーザーのコメントで、一番下までスクロールし、次または 2 番目のページをクリックすると、ネットワークに動的に追加された項目が list_detail_rate.htm?itemId= で始まります。 35648967399。

次に、このオプションをクリックすると、右側のオプションボックスにリンクに関する情報が表示されます。リクエストURLのリンクコンテンツをコピーします。

取得した URL リンクをブラウザのアドレス バーに入力すると、ページが必要なデータを返しますが、JSON データであるため非常に乱雑に見えます。

2 ajaxリクエストで返されるjsonデータを取得する
次に、URL内のjsonデータを取得します。私が使用する Python エディターは pycharm です。Python コードを見てみましょう:
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import requests url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长 content=requests.get(url).content
print content #印刷されたコンテンツは、以前 Web ページから取得した JSON データです。ユーザーのコメントを含めます。
ここのコンテンツは必要な json データです。次のステップは、これらの json データを解析することです。
3 Python を使用して json データを解析する
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']
分析:
ここで必要なパッケージをインポートする必要があります。re は正規表現に必要なパッケージで、json データを解析しますjson をインポートする必要があります
cont=requests.get(url).content #Web ページ内の json データを取得します
rex=re.compile(r'w+[(]{1}(.*)[)]{ 1}') #正規表現を削除 contデータの冗長部分は、実際のjson形式のデータとなるデータです {"a":"b","c":"d"}
con=json.loads( content,"gbk") json を使用して、loads 関数はコンテンツのコンテンツを json ライブラリ関数で処理できるデータ形式に変換します。win システムのデフォルトは gbk
count です。 =len(con['rateDetail']['rateList']) # ユーザーのコメント数を取得します (ここでは現在のページのみ)
for i in xrange(count):
print con['rateDetail'] ['rateList'][i]['appendComment']
#ループトラバーサル ユーザーのコメントと出力 (必要に応じてデータを保存することもできます。4 番目の部分を確認できます)
ここでの困難はパスを見つけることです乱雑な JSON データ内のユーザー コメントの数
IV 解析結果を保存します
ここで、ユーザーはユーザーのコメント情報を csv 形式で保存するなど、ローカルに保存できます。
この記事は以上です。皆さんに気に入っていただければ幸いです。
以上が淘宝網のコメントを取得する例を取り上げて、Ajax (クラシック) によって動的に生成されたデータを Python がどのようにクロールするかを説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



