

この記事で紹介した内容は、一定の参考価値のあるPHP面接の要約ですので、困っている友達にぜひシェアしてください
select_type
table
type
possible_keys
key
key_len
ref
rows
Extra
MySQLのバージョン:
テストテーブルを作成
CREATE TABLE people( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ); CREATE TABLE people_car( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp );

テストデータを挿入
insert into people (zipcode,address,lastname,firstname,birthdate) values ('230031','anhui','zhan','jindong','1989-09-15'), ('100000','beijing','zhang','san','1987-03-11'), ('200000','shanghai','wang','wu','1988-08-25') insert into people_car (people_id,plate_number,engine_number,lasttime) values (1,'A121311','12121313','2013-11-23 :21:12:21'), (2,'B121311','1S121313','2011-11-23 :21:12:21'), (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
テスト用のインデックスを作成しますalter table people add key(zipcode,firstname,lastname);
最も単純なクエリから始めましょう:
Query-1 explain select zipcode,firstname,lastname from people;
EXPLAIN の出力結果には、id、select_type、table、type、 possible_keys、key、key_len、行および追加の列。 
Query-2 explain select zipcode from (select * from people a) b;
id は、クエリ全体で SELECT ステートメントを順番に識別するために使用されます。上記の単純なネストされたクエリを通じて、より大きな ID を持つステートメントが最初に実行されることがわかります。この行が UNION ステートメントなど、他の行の結合結果を記述するために使用される場合、値は NULL になる可能性があります。ステートメントは次のとおりです。 
SIMPLE
UNION やサブクエリを使用しない最も単純な SELECT クエリ。  クエリ-1を参照してください。
クエリ-1を参照してください。
は、ネストされたクエリの最も外側の SELECT ステートメントであり、UNION クエリの最前面の SELECT ステートメントです。 Query-2 と Query-3 を参照してください。
UNION
UNION の 2 番目以降の SELECT ステートメント。 クエリ-3を参照してください。
DERIVED
派生テーブルの SELECT 文の FROM 句内の SELECT 文。 クエリ-2を参照してください。
ユニオン結果
一个UNION查询的结果。见Query-3。
DEPENDENT UNION
顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。
Query-4 explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。
这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。
SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
类似这样的语句会被重写成这样:
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
所以Query-4实际上被重写成这样:
Query-5 explain select * from people o where exists ( select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。
SUBQUERY
子查询中第一个SELECT语句。
Query-6 explain select * from people where id = (select id from people where zipcode = 100000);

DEPENDENT SUBQUERY
和DEPENDENT UNION相对UNION一样。见Query-5。
除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。
显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。
Query-7 explain select * from (select * from (select * from people a) b ) c;

可以看到如果指定了别名就显示的别名。
<strong><em>N</em></strong>>N就是id值,指该id值对应的那一步操作的结果。
还有
注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。
type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。
const
当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是:
Query-8 explain select * from people where id=1;

Query-9 explain select * from people where zipcode = 100000;

注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。
Query-10 explain select * from people where id >2;

system
这是const连接类型的一种特例,表仅有一行满足条件。
Query-11 explain select * from (select * from people where id = 1 )b;

eq_ref
eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。
需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。
Query-12 explain select * from people a,people_car b where a.id = b.people_id;

我们创建两个MyISAM表people2和people_car2试试:
CREATE TABLE people2( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ) ENGINE = MyISAM; CREATE TABLE people_car2( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp )ENGINE = MyISAM;
Query-13 explain select * from people2 a,people_car2 b where a.id = b.people_id;

我想这是InnoDB对性能权衡的一个结果。
eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了:
Query-14 explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

ref
这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。
为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。
reate index people_id on people2(id); create index people_id on people_car2(people_id);
然后再执行下面的查询:
Query-15 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

Query-16 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

Query-17 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-18 explain select * from people2 where id = 1;

看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。
对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。
fulltext
链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。
ref_or_null
该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。
Query-19 mysql> explain select * from people2 where id = 2 or id is null;

Query-20 explain select * from people2 where id = 2 or id is not null;

注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。
index_merger
该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。
unique_subquery
该类型替换了下面形式的IN子查询的ref:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。
index_subquery
该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:<br/>
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range:
Query-21 explain select * from people where id = 1 or id = 2;
 <br/>
<br/>
注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。
这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。
explain select * from people where id >1;

explain select * from people where id in (1,2);

但事实上这两种情况下MySQL如何使用索引是有很大差别的:
我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。
——出自《高性能MySQL第三版》
index
该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。
Query-22 explain select * from people order by id;

至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。
ALL
最も遅い方法はフルテーブルスキャンです。
一般に、上記の接続タイプのパフォーマンスは (system>const) の順に低下し、MySQL バージョン、ストレージ エンジン、さらにはデータ ボリュームが異なるとパフォーマンスが異なる場合があります。
possible_keys 列は、MySQL がこのテーブル内の行を検索するために使用できるインデックスを示します。 key 列には、MySQL が実際に使用することを決定したキー (インデックス) が表示されます。インデックスが選択されていない場合、キーは NULL になります。 MySQL に possible_keys カラムのインデックスの使用または無視を強制するには、クエリで FORCE INDEX、USE INDEX、または IGNORE INDEX を使用します。 key_len 列は、MySQL が使用することを決定したキーの長さを示します。キーが NULL の場合、長さは NULL になります。使用されるインデックスの長さ。長さが短いほど、精度を損なうことなく良好になります。
ref列は、テーブルから行を選択するためにキーとともに使用される列または定数を示します。 rows 列には、クエリの実行時に MySQL がチェックする必要があると判断した行数が表示されます。これは推定値であることに注意してください。
Extra は、クエリ プロセス中の MySQL に関する詳細情報を表示する列です。紹介対象に選ばれました。
filesort の使用
<br/>
一時テーブルを使用する
MYSQL は、LEFT JOIN 条件に一致する行を見つけると、検索を停止します。
インデックス
を使用することは、クエリがインデックスをカバーしていることを示します。これは良いことです。 MySQL は、不要なレコードをインデックスから直接フィルタリングし、ヒットを返します。これは MySQL サービス層によって行われますが、レコードをクエリするためにテーブルに戻る必要はありません。
インデックス条件の使用
これは、「インデックス条件プッシュ」と呼ばれる MySQL 5.6 の新機能です。簡単に言うと、MySQL は元々インデックスに対して like などの操作を実行できませんでしたが、これにより不要な IO 操作が削減されます。詳細については、ここをクリックしてください。
where
の使用では、WHERE句を使用して、次のテーブルと一致する行、またはユーザーに返される行を制限します。
注: where を使用すると、[追加] 列に表示され、MySQL サーバーが WHERE 条件フィルタリングを適用する前にストレージ エンジンをサービス層に戻すことを示します。
EXPLAIN の出力内容は基本的に導入されており、EXPLAIN EXTENDED と呼ばれる拡張コマンドもあり、SHOW WARNINGS コマンドと組み合わせて詳細情報を確認できます。さらに便利なことの 1 つは、MySQL オプティマイザーによる再構築後の SQL を確認できることです。
説明は以上です。実際、これらのコンテンツはオンラインで入手できますが、実際に自分で実践すると、より感動するでしょう。次のセクションでは、SHOW PROFILE、スロー クエリ ログ、およびいくつかのサードパーティ ツールを紹介します。 <br/> サードパーティ アプリケーション: サードパーティ アプリケーション。この記事では「クライアント」とも呼ばれます。前のセクションの例では「クラウド印刷」です。 HTTP サービス: HTTP サービス プロバイダー。この記事では「サービス プロバイダー」と呼ばれます。前のセクションの例では Google です。 リソース所有者: リソース所有者。この記事では「ユーザー」とも呼ばれます。 ユーザー エージェント: この記事では、ユーザー エージェントはブラウザーを指します。 認可サーバー: 認証サーバー、つまり、サービスプロバイダーが認証を処理するために使用するサーバーです。 リソースサーバー: リソースサーバー、つまりサービスプロバイダーがユーザー生成のリソースを保存するサーバーです。これと認証サーバーは同じサーバーであっても、異なるサーバーであっても構いません。 (F)资源服务器确认令牌无误,同意向客户端开放资源。 不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。 下面一一讲解客户端获取授权的四种模式。 客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。 授权码模式(authorization code) 简化模式(implicit) 密码模式(resource owner password credentials) 客户端模式(client credentials) 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。 它的步骤如下: (A)用户访问客户端,后者将前者导向认证服务器。 (B)用户选择是否给予客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。 (D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。 (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。 下面是上面这些步骤所需要的参数。 A步骤中,客户端申请认证的URI,包含以下参数: response_type:表示授权类型,必选项,此处的值固定为"code" client_id:表示客户端的ID,必选项 redirect_uri:表示重定向URI,可选项 scope:表示申请的权限范围,可选项 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,服务器回应客户端的URI,包含以下参数: code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数: grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。 code:表示上一步获得的授权码,必选项。 redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。 client_id:表示客户端ID,必选项。 下面是一个例子。 E步骤中,认证服务器发送的HTTP回复,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 下面是一个例子。 从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。 简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。 它的步骤如下: (A)客户端将用户导向认证服务器。 (B)用户决定是否给于客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。 (D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。 (E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。 (F)浏览器执行上一步获得的脚本,提取出令牌。 (G)浏览器将令牌发给客户端。 下面是上面这些步骤所需要的参数。 A步骤中,客户端发出的HTTP请求,包含以下参数: response_type:表示授权类型,此处的值固定为"token",必选项。 client_id:表示客户端的ID,必选项。 redirect_uri:表示重定向的URI,可选项。 scope:表示权限范围,可选项。 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,认证服务器回应客户端的URI,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。 根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。 密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。 在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。 它的步骤如下: (A)用户向客户端提供用户名和密码。 (B)客户端将用户名和密码发给认证服务器,向后者请求令牌。 (C)认证服务器确认无误后,向客户端提供访问令牌。 B步骤中,客户端发出的HTTP请求,包含以下参数: grant_type:表示授权类型,此处的值固定为"password",必选项。 username:表示用户名,必选项。 password:表示用户的密码,必选项。 scope:表示权限范围,可选项。 下面是一个例子。 C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 整个过程中,客户端不得保存用户的密码。 客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。 它的步骤如下: (A)客户端向认证服务器进行身份认证,并要求一个访问令牌。 (B)认证服务器确认无误后,向客户端提供访问令牌。 A步骤中,客户端发出的HTTP请求,包含以下参数: granttype:表示授权类型,此处的值固定为"clientcredentials",必选项。 scope:表示权限范围,可选项。 认证服务器必须以某种方式,验证客户端身份。 B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。 客户端发出更新令牌的HTTP请求,包含以下参数: granttype:表示使用的授权模式,此处的值固定为"refreshtoken",必选项。 refresh_token:表示早前收到的更新令牌,必选项。 scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。 下面是一个例子。 (完) <br/> yii2框架的安装我们在之前文章中已经提到下面我们开始了解YII2框架 强大的YII2框架网上指南:http://www.yii-china.com/doc/detail/1.html?postid=278或者<br/> http://www.yiichina.com/doc/guide/2.0<br/> Yii2的应用结构:<br/> 目录篇:<br/> <br/> <br/> <br/>3.コンソール コンソール アプリケーションには、システムに必要なコンソール コマンドが含まれています。 <br/> その中で: config は共通の構成であり、これらの構成はフロント、バックエンド、およびコマンド ラインに適用されます。 mailは、アプリケーションのフロントエンドとバックエンド、およびコマンドラインの電子メール関連のレイアウト ファイルです。 モデルは、フロントエンドとバックエンドの両方、およびコマンドラインで使用できるデータモデルです。 これはcommonの最も重要な部分でもあります。 <br/> パブリックディレクトリ (Common) に含まれるファイルは、他のアプリケーション間で共有するために使用されます。たとえば、各アプリケーションは ActiveRecord を使用してデータベースにアクセスする必要がある場合があります。したがって、AR モデル クラスを共通ディレクトリに配置できます。同様に、一部のヘルパーまたはウィジェットが複数のアプリケーションで使用されている場合は、コードの重複を避けるために、これらも共通のディレクトリに配置する必要があります。 すぐに説明しますが、アプリケーションは共通の構成の一部を共有することもできます。したがって、共通の共通設定を config ディレクトリに保存することもできます。 <br/>開発サイクルが長い大規模プロジェクトを開発する場合、データベース構造を常に調整する必要があります。このため、DB 移行機能を使用してデータベースの変更を追跡することもできます。また、すべての DB 移行ディレクトリを共通ディレクトリの下に配置します。 <br/><br/>5.環境 各 Yii 環境は、エントリースクリプトの Index.php やさまざまな設定ファイルを含む設定ファイルのセットです。 実際、これらはすべて /environments ディレクトリの下に配置されています <br/> ディレクトリ dev ディレクトリ ファイルindex.php その中で、devとprodは同じ構造を持ち、それぞれ4つのディレクトリと1つのファイルを含みます: フロントエンドアプリケーションに使用されるフロントエンドディレクトリには、保存する構成が含まれます設定ファイル Web エントリ スクリプトを保存するディレクトリと Web ディレクトリ backend ディレクトリ、バックグラウンド アプリケーションに使用され、内容はフロントエンドと同じです console ディレクトリ、コマンド ライン アプリケーションに使用され、config ディレクトリのみが含まれます、コマンド ライン アプリケーションの Web エントリ スクリプトには必要ないため、Web ディレクトリはありません。 common ディレクトリは、さまざまな Web アプリケーションやコマンド ライン アプリケーションの共通の環境設定に使用されます。異なるアプリケーションは同じエントリ スクリプトを共有できないため、config ディレクトリのみが含まれます。 このコモンのレベルは環境のレベルよりも低い、つまり、その普遍性は特定の環境でのみ共通であり、すべての環境で共通であるわけではないことに注意してください。 yii ファイルは、コマンド ライン アプリケーションのエントリ スクリプト ファイルです。 あちこちに散らばる Web ディレクトリと config ディレクトリには、共通点もあります。 すべての Web ディレクトリには、Web アプリケーションのエントリ スクリプト、index.php と、index-test.php のテスト バージョンが保存されます すべての config ディレクトリには、ローカル構成情報 main-local.php および params-local が保存されます.php <br/>6.vendor 1、入口文件路径:<br/> http://127.0.0.1/yii2/advanced/frontend/web/index.php 每个应用都有一个入口脚本 web/index.PHP,这是整个应用中唯一可以访问的 PHP 脚本。一个应用处理请求的过程如下: 1.用户向入口脚本 web/index.php 发起请求。 <br/>2.入口脚本加载应用配置并创建一个应用实例去处理请求。 <br/>3.应用通过请求组件解析请求的路由。 <br/>4.应用创建一个控制器实例去处理请求。 <br/>5.控制器创建一个操作实例并针对操作执行过滤器。 <br/>6.如果任何一个过滤器返回失败,则操作退出。 <br/>7.如果所有过滤器都通过,操作将被执行。 <br/>8.操作会加载一个数据模型,或许是来自数据库。<br/>9.操作会渲染一个视图,把数据模型提供给它。 <br/>10.渲染结果返回给响应组件。 <br/>11.响应组件发送渲染结果给用户浏览器 可以看到中间有模型-视图-控制器 ,即常说的MVC。入口脚本并不会处理请求,而是把请求交给了应用主体,在处理请求时,会用到控制器,如果用到数据库中的东西,就会去访问模型,如果处理请求完成,要返回给用户信息,则会在视图中回馈要返回给用户的内容。<br/> 2、为什么我们访问方法会出现url加密呢? 我们找到文件:vendor/yiisoft/yii2/web/UrlManager.php <br/> MVC篇: 一、控制器详解: 1、修改默认控制器和方法 修改全局控制器:打开vendor/yiisoft/yii2/web/Application.php eg: 2、建立控制器示例:StudentController.php //命名空间<br/> <br/> <br/><br/> //显示视图<br/> return $this->render('add'); 默认.php<br/> return $this->render('upda',["data"=>$data]); <br/><br/> } <br/>}<br/><br/> 二、模型层详解 简单模型建立: <br/> <br/><br/> 三、视图层详解首先在frontend下建立与控制器名一致的文件(小写)eg:student 在文件下建立文件<br/> eg:index.php<br/>每一个controller对应一个view的文件夹,但是视图文件yii不要求是HTML,而是php,所以每个视图文件php里面都是视图片段: 当然了,视图与模板之间还有数据传递以及继承覆盖的功能。<br/><br/><br/><br/><br/><br/> YII2框架数据的运用 1、数据库连接 简介 一个项目根据需要会要求连接多个数据库,那么在yii2中如何链接多数据库呢?其实很简单,在配置文件中稍加配置即可完成。 配置 打开数据库配置文件common\config\main-local.php,在原先的db配置项下面添加db2,配置第二个数据库的属性即可 [php] view plain copy 如上配置就可以完成yii2连接多个数据库的功能,但还是需要注意几个点 如果使用的数据库前缀 在建立模型时 这样: eg:这个库叫 haiyong_test return {{%test}}<br/> 应用 1.我们在hyii数据库中新建一个测试表test 2.通过gii生成模型,这里需要注意的就是数据库链接ID处要改成db2<br/> 3.查看生成的模型,比正常的model多了红色标记的地方 所以各位童鞋,如果使用多数据配置,在建db2的模型的时候,也要加上上图红色的代码。 好了,以上步骤就完成了,yii2的多数据库配置,配置完成之后可以和原因一样使用model或者数据库操作 2、数据操作: <br/>方式一:使用createCommand()函数<br/> 增加 <br/> 获取自增id [php] view plain copy 批量插入数据 [php] view plain copy 修改 [php] view plain copy 方式二:模型处理数据(优秀程序媛必备)!! <br/> 新增(因为save方法有点low)所以自己在模型层中定义:add和addAll方法<br/> 注意:!!!当setAttributes($attributes,fase);时不用设置rules规则,否则则需要设置字段规则;<br/> 删除<br/> 使用model::delete()进行删除 [php] view plain copy 直接删除:删除年龄为30的所有用户 [php] view plain copy 根据主键删除:删除主键值为1的用户<br/> [php] view plain copy <br/> <br/> <br/> <br/> <br/> 修改<br/> 使用model::save()进行修改 <br/> <br/> <br/> 直接修改:修改用户test的年龄为40<br/> <br/> <br/> 基础查询 <br/> <br/> 关联查询 <br/> <br/> <br/> 翻译 2015年07月30日 10:29:03 <br/> yii2 rbac 详解DbManager <br/> 1.yii config文件配置(我用的高级模板)(配置在common/config/main-local.php或者main.php) 'authManager' => [ 'class' => 'itemTable' => 'auth_assignment', 'itemChildTable' => <br/> 2. もちろん、設定でデフォルトのロールを設定することもできますが、私はそれを書きませんでした。 Rbac は、PhpManager と DbManager の 2 つのクラスをサポートしています。ここでは DbManager を使用します。 yii merge (このコマンドを実行してユーザーテーブルを生成します) <br/>yii merge --migrationPath=@yii/rbac/migrations/ このコマンドを実行して、以下に示すように権限データテーブルを生成します<br/>3.yii rbac の実際の操作 4 つのテーブルです <br/> 推荐文章 微信H5支付完整版含PHP回调页面.代码精简2018年2月 <br/>支付宝手机支付,本身有提供一个手机网站支付DEMO,是lotusphp版本的,里面有上百个文件,非常复杂.本文介绍的接口, <br/>只需通过一个PHP文件即可实现手机支付宝接口的付款,非常简洁,并兼容微信. <br/>代码在最下面. 注意事项(重要): <br/>一,支付宝接口已经升级了加密方式,现在申请的接口都是公钥加私钥的加密形式.公钥与私钥都需要申请者自己生成,而且是成对的,不能拆开用.并把公钥保存到支付宝平台,该公钥对应的私钥不需要保存在支付宝,只能自己保存,并放在api支付宝接口文件中使用.下面会提到. APPID 应该填哪个呢? 这个是指开放平台id,格式应该填2018或2016等日期开头的,不要填合作者pid,那个pid新版不需要的.APPID下面还对应一个网关.这个也要对应填写.正式申请通过的网关为https://openapi.alipay.com/gateway.do 如果你是沙箱测试账号, <br/>则填https://openapi.alipaydev.com/gateway.do 注意区别 <br/>密钥生成方式为, https://docs.open.alipay.com/291/105971 打开这个地址,下载该相应工具后,解压打开文件夹,运行“RSA签名验签工具.bat”这个文件后.打开效果如下图 <br/>如果你的网站是jsp的,密钥格式如下图,点击选择第一个pkcs8的,如果你的网站是php,asp等,则点击pkcs1 <br/>密钥长度统一为2048位. <br/>然后点击 生成密钥 <br/>然后,再点击打开密钥文件路径按钮.即可看到生成的密钥文件,打开txt文件.即可看到生成的公钥与私钥了. <br/>公钥复制后(注意不要换行),需提供给支付宝账号管理者,并上传到支付宝开放平台。如下图第二 <br/>界面示例: <br/> 二,如下,同步回调地址与异步回调地址的区别. <br/>同步地址是指用户付款成功,他自动跳转到这个地址,以get方式返回,你可以设置为跳转回会员中心,也可以转到网站首页或充值日志页面,通过$_GET 的获取支付宝发来的签名,金额等参数.然后进本地数据库验证支付是否正常. <br/>而异步回调地址指支付成功后,支付宝会自动多次的访问你的这个地址,以静默方式进行,用户感受不到地址的跳转.注意,异步回调地址中不能有问号,&等符号,可以放在根目录中.如果你设置为notify_url.php,则你也需要在notify_url.php这个文件中做个判断.比如如果用户付款成功了.则用户的余额则增加多少,充值状态由付款中.修改为付款成功等. 1 2 三,orderName 订单名称,注意编码,否则签名可能会失败 <br/>向支付宝发起支付请求时,有个orderName 订单名称参数.注意这个参数的编码,如果你的本页面是gb2312编码,$this->charset = ‘UTF-8’这个参数最好还是UTF-8,不需要修改.否则签名时,可能会出现各种问题.,可用下面的方法做个转码. 1 四,微信中如何使用支付宝 <br/>支付宝有方案,可以进这个页面把ap.js及pay.htm下载后,保存到你的支付文件pay.php文件所在的目录中. <br/>方案解释,会员在微信中打开你网站的页面,登录,并点击充值或购买链接时,他如果选择支付宝付款,则ap.js会自动弹出这个pay.htm页面,提示你在右上角选择用浏览器中打开,打开后,自动跳转到支付宝app中,不需要重新登录原网站的会员即可完成充值,并跳转回去. <br/>注意,在你的客户从微信转到手机浏览器后,并没有让你重新登录你的商城网站,这是本方案的优势所在. <br/>https://docs.open.alipay.com/203/105285/ 五,如果你申请的支付宝手机支付接口在审核中,则可以先申请一个沙箱测试账号,该账号申请后就可以使用非常方便.同时会提供你一个支付宝商家账号及买家测试账号.登录即可测试付款情况. 代码如下(参考) <br/>一.表单付款按钮所在页面代码 <br/> 二,pay.php页面代码(核心代码) 三,回调页面案例一,即notify_url.php文件. post回调, 四.异步回调案例2, 与上面三是重复的,可选择其中一个.本回调可直接放根目录中 如果你服务器不支持mysqli 就替换为mysql 测试回调时, 请先直接访问本页面,进行测试.订单号可以先写一个固定值. 参考原文 <br/>http://blog.csdn.net/jason19905/article/details/78636716 <br/>https://github.com/dedemao/alipay <br/> 抓包就是把网络数据包用软件截住或者纪录下来,这样做我们可以分析网络数据包,可以修改它然后发送一个假包给服务器,这种技术多应用于网络游戏外挂的制作方面或者密码截取等等 常用的几款抓包工具!<br/>标签: 软件测试软件测试方法软件测试学习<br/>原创来自于我们的微信公众号:软件测试大师 <br/>最近很多同学,说面试的时候被问道,有没有用过什么抓包工具,其实抓包工具并没有什么很难的工具,只要你知道你要用抓包是干嘛的,就知道该怎么用了!一般<br/>对于测试而言,并不需要我们去做断点或者是调试代码什么的,只需要用一些抓包工具抓取发送给服务器的请求,观察下它的请求时间还有发送内容等等,有时候,<br/>可能还会用到这个去观察某个页面下载组件消耗时间太长,找出原因,要开发做性能调优。那么下面就给大家推荐几款抓包工具,好好学习下,下次面试也可以拿来<br/>装一下了! <br/>1<br/>Flidder<br/>Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 <br/>HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是<br/>web调试的利器。<br/>小编发现了有个兄台写的不错的文章,分享给大家,有兴趣的同学,可以自己去查阅并学习下,反正本小编花了点时间就学会了,原来就这么回事!作为测试学会这点真的是足够用了!<br/>学习链接如下:<br/>http://blog.csdn.net/ohmygirl/article/details/17846199<br/>http://blog.csdn.net/ohmygirl/article/details/17849983<br/>http://blog.csdn.net/ohmygirl/article/details/17855031 2<br/>Httpwatch<br/>火狐浏览器下有著名的httpfox,而HttpWatch则是IE下强大的网页数据分析工具。教程小编也不详述了,找到了一个超级棒的教程!真心很赞!要想学习的同学,可以点击链接去感受下!<br/>http://jingyan.baidu.com/article/5553fa820539ff65a339345d.html <br/>3其他浏览器的内置抓包工具<br/>如果用过Firefox的F12功能键,应该也知道这里也有网络抓包的工具,是内置在浏览器里面的,貌似现在每款浏览器都有这个内置的抓包工具,虽然没有上面两个工具强大,但是对于测试而言,我觉得是足够了!下面是一个非常详细的教程,大家可以去学习下。<br/>http://jingyan.baidu.com/article/3c343ff703fee20d377963e7.html 对于想学习点新知识去面试装逼的同学,小编只能帮你们到这里了,要想学习到新知识,除了动手指去点击这些链接,还需要你们去动脑好好学习下! <br/> <br/> 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。 为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。 一、HTTP和HTTPS的基本概念 HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。 HTTPS: セキュリティを目的とした HTTP チャネルです。簡単に言えば、HTTP の安全なバージョンです。つまり、HTTPS のセキュリティ基盤は SSL であるため、暗号化の詳細には SSL が必要です。 HTTPS プロトコルの主な機能は 2 つのタイプに分類できます。1 つは、データ送信のセキュリティを確保するための情報セキュリティ チャネルを確立することで、もう 1 つは Web サイトの信頼性を確認することです。 2. HTTP と HTTPS の違いは何ですか? HTTP プロトコルによって送信されるデータは暗号化されていない、つまり平文であるため、これらの個人データを確実に暗号化して送信するために HTTP プロトコルを使用することは非常に危険です。 Netscape が設計した SSL (Secure Sockets Layer) ) プロトコルは、HTTP プロトコルによって送信されるデータを暗号化するために使用され、HTTPS が誕生しました。 簡単に言うと、HTTPS プロトコルは、SSL+HTTP プロトコルから構築されたネットワーク プロトコルであり、暗号化された送信と ID 認証を実行できます。http プロトコルよりも安全です。 HTTPS と HTTP の主な違いは次のとおりです: 1. https プロトコルでは CA に証明書を申請する必要があるため、一般に無料の証明書が少ないため、一定の料金が必要です。 2. http はハイパーテキスト転送プロトコルであり、情報は平文で送信されますが、https は安全な SSL 暗号化送信プロトコルです。 3. http と https はまったく異なる接続方法を使用し、前者は 80、後者は 443 を使用します。 4. http 接続は非常にシンプルでステートレスです。HTTPS プロトコルは、暗号化された送信と ID 認証を実行できる SSL+HTTP プロトコルから構築されたネットワーク プロトコルであり、http プロトコルよりも安全です。 3. HTTPS の仕組み HTTPS が情報を暗号化して機密情報が第三者に取得されるのを防ぐことができることは誰もが知っているため、より高いセキュリティ レベルを備えた多くの銀行 Web サイトや電子メール、その他のサービスでは HTTPS プロトコルが使用されます。 。 1. クライアントが HTTPS リクエストを開始します これについては何も言うことはありません。ブラウザに https URL を入力し、サーバーの 443 ポートに接続します。 2. サーバー構成 HTTPS プロトコルを使用するサーバーには、自分で作成することも、組織に申請することもできる一連のデジタル証明書が必要です。信頼できる会社によって適用された証明書を使用する場合、プロンプト ページは表示されません (1 年間の無料サービスが提供される startssl が適切な選択です)。 この証明書のセットは実際には公開鍵と秘密鍵のペアです。公開鍵と秘密鍵を理解していない場合は、それらを鍵と錠前として想像してください。この鍵を持っている人は他の人にロックを渡すことができ、その人はこのロックを使って重要なものをロックし、あなたに送ることができます。なぜならあなただけが鍵を持っているので、あなただけがロックされたものを見ることができます。この錠前で。 3. 証明書を転送します この証明書は実際には公開鍵ですが、証明書の発行機関や有効期限など、多くの情報が含まれています。 4. クライアントは証明書を解析します この部分の作業は、まず、発行局、有効期限など、公開キーが有効であるかどうかを検証します。異常が見つかった場合は、証明書に問題があることを示す警告ボックスが表示されます。 証明書に問題がない場合は、ランダムな値を生成し、その証明書を使用してランダムな値を暗号化します。前述のように、ランダムな値をロックでロックし、キーを持っていない限り暗号化できません。ライブコンテンツがロックされていることを確認してください。 5. 暗号化された情報の送信 この部分は、証明書で暗号化されたランダムな値を送信し、将来的にはクライアントとサーバー間の通信を暗号化できるようにすることです。このランダムな値は復号化されます。 6. サービスセグメントの復号化情報 サーバーは秘密鍵で情報を復号化した後、クライアントから渡されたランダムな値 (秘密鍵) を取得し、この値を使用してコンテンツを対称的に暗号化します。対称暗号化と呼ばれるものは、情報と秘密鍵が特定のアルゴリズムを通じて混合されるため、秘密鍵が分からない限りコンテンツを取得できず、クライアントとサーバーの両方がこの秘密鍵を知っているため、暗号化が行われる限り、コンテンツを取得できないことを意味します。アルゴリズムは十分に強力であり、秘密キーは十分に複雑ですが、データは十分に安全です。 7. 暗号化された情報の送信 この部分の情報は、サービスセグメント内の秘密鍵で暗号化された情報であり、クライアントで復元できます。 8. クライアントは情報を復号化します クライアントは、以前に生成された秘密キーを使用してサービスセグメントによって渡された情報を復号化し、プロセス全体で第三者がデータを監視したとしても、復号化されたコンテンツを取得します。何もすることはありません。 6. HTTPS の利点 HTTPS は非常に安全であるため、攻撃者が攻撃を開始する場所を見つけることができません。Web マスターの観点から見ると、HTTPS の利点は次の 2 点です。 SEO の側面 Google は 2014 年 8 月に検索エンジンのアルゴリズムを調整し、「同等の HTTP Web サイトと比較して、HTTPS 暗号化を使用している Web サイトは検索結果で上位にランクされる」と述べました。 2. セキュリティ HTTPS は完全に安全ではありませんが、ルート証明書を管理する機関や暗号化アルゴリズムを管理する組織も中間者攻撃を実行する可能性があります。現在のアーキテクチャの主な利点は次のとおりです: (1)、HTTPS プロトコルを使用してユーザーとサーバーを認証し、データが正しいクライアントとサーバーに送信されるようにします。 (2)、HTTPS プロトコルは、暗号化された送信と ID を実行できる SSL+HTTP プロトコルによって構築されたネットワークです。認証 このプロトコルは HTTP プロトコルよりも安全であり、送信中のデータの盗難や変更を防ぎ、データの整合性を保証します。 (3) HTTPS は現在のアーキテクチャでは最も安全なソリューションですが、絶対に安全というわけではありませんが、中間者攻撃のコストが大幅に増加します。 7. HTTPS の欠点 HTTPS には大きな利点がありますが、相対的に言えば、まだいくつかの欠点があります: 1. SEO の側面 2. 経済的側面 <br/> <br/> <br/> <br/><br/>一般に、同様のファジー クエリは次のように記述されます (フィールドはインデックス付けされています): <br/><br/>SELECT `column` FROM `table` WHERE `field` like '%keyword%'; <br/><br/>上記のステートメントは Explain によって説明されます。見てください、SQL ステートメントはインデックスを使用せず、全テーブル検索です。データ量が非常に大きい場合、最終的な効率は次のようになると想像できます<br/><br/>次の記述を比較してください: <br/><br/>SELECT ` column` FROM `table ` WHERE `field` like 'keyword%';<br/><br/>この書き方を説明すると、SQL文にインデックスが使用されており、検索効率が大幅に向上していることがわかります。 <br/><br/> <br/><br/>しかし、ファジークエリを実行するとき、クエリしたいすべてのキーワードが先頭にあるとは限らないため、特別な要件がない限り、「keywork%」はすべてのファジークエリに適しているわけではありません <br/><br/> <br/><br/> 現時点では時間が経ったら、他のメソッドの使用を検討してみましょう<br/><br/>1.LOCATE('substr',str,pos)メソッド<br/>コードをコピー<br/><br/>SELECT LOCATE('xbar',`foobar`); <br/>###Return 0 <br/><br/> SELECT LOCATE ('bar',`foobarbar`); <br/>###Return 4<br/><br/>SELECT LOCATE('bar',`foobarbar`,5);<br/>###Return 7<br/><br/> コードをコピー<br/><br/> 備考: 部分文字列を返します。 str 内で str が最初に出現した場合、str 内に substr が存在しない場合、戻り値は 0 です。 pos が存在する場合は、str の pos 番目の位置の後に substr が最初に出現する位置を返します。substr が str に存在しない場合、戻り値は 0 です。 <br/><br/>SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0<br/><br/>備考: キーワードは検索する内容、フィールドは一致したフィールド、キーワードで存在するすべてのデータをクエリします<br/> <br/> <br/>2.POSITION('substr' IN `field`) メソッド <br/><br/>position は、locate と同じ関数を持つ、locate のエイリアスとみなすことができます <br/><br/>SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)<br/><br/>3.INSTR(`str`,'substr')メソッド<br/><br/>SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword' )>0 <br/><br/> <br/><br/>さらに上記のメソッドに加えて、FIND_IN_SET 関数もあります<br/><br/>FIND_IN_SET(str1,str2):<br/><br/>str2 内の str1 の位置インデックスを返します。str2 は「,」で区切る必要があります。 <br/><br/>SELECT * FROM `person` WHERE FIND_IN_SET('apply',`name`);<br/><br/> 30、2013 15 :36:36 : UNIONオペレーター UNION <br/>演算子は、他の 2 つの結果テーブル ( TABLE1 と TABLE2 など) を結合し、テーブル内の重複行を削除することによって、結果テーブルを導出します。 ALL が UNION とともに使用される場合 (つまり、 UNION ALL)、重複する行は削除されません。どちらの場合も、派生テーブルの各行は TABLE1 または TABLE2 から取得されます。 B<br/>: EXCEPToperatorEXCEPT <br/>演算子は、 TABLE1のすべてを含めることによって機能しますが、には含めません 内の 行を削除し、重複する行をすべて削除します。結果テーブルを導出します。 ALL が EXCEPT (EXCEPT ALL) とともに使用される場合、重複行は削除されません。 C<br/>: INTERSECToperator <br/> TABLE1 と TABLE2 のみを含めた INTERSECT 演算子 そして重複する行をすべて削除し、結果テーブルを派生します。 ALL を INTERSECT (INTERSECT ALL) と一緒に使用する場合、重複する行は削除されません。 注: 演算子単語を使用するいくつかのクエリ結果行は一貫している必要があります。 <br/>次のステートメントに変更することをお勧めします --重複行を含む 2 つの結果セットを並べ替えずに結合します SELECT * FROM 4 Includeデフォルトのルールで並べ替えを行う間、行を重複させます SELECT *FROM dbo.banji INTERSECT SELECT * FROM dbo.banjinew; --运算符通过包括所有在TABLE1中但不在TABLE2中的行并消除所有重复行而派生出一个结果表 SELECT * FROM dbo.banji EXCEPT SELECT * FROM dbo.banjinew;<br/>有些DBMS不支持except all和intersect all <br/> 1. 接口<br/> 在php编程语言中接口是一个抽象类型,是抽象方法的集合。接口通常以interface来声明。一个类通过实现接口的方式,从而来实现接口的方法(抽象方法)。<br/> 接口定义: 特别注意:<br/> * 类全部为抽象方法(不需要声明abstract) <br/> * 接口抽象方法是public <br/> * 成员(字段)必须是常量 2. 继承<br/> 继承自另一个类的类被称为该类的子类。这种关系通常用父类和孩子来比喻。子类将继 <br/>承父类的特性。这些特性由属性和方法组成。子类可以增加父类之外的新功能,因此子类也 <br/>被称为父类的“扩展”。<br/> 在PHP中,类继承通过extends关键字实现。继承自其他类的类成为子类或派生类,子 <br/>类所继承的类成为父类或基类。 特别注意:<br/> 有时候并不需要父类的字段和方法,那么可以通过子类的重写来修改父类的字段和方法。 通过重写调用父类的方法<br/> 有的时候,我们需要通过重写的方法里能够调用父类的方法内容,这个时候就必须使用<br/> 语法:父类名::方法()、parent::方法()即可调用。<br/>final关键字可以防止类被继承,有些时候只想做个独立的类,不想被其他类继承使用。 3. 抽象类和方法<br/>抽象类特性:<br/>* 抽象类不能产生实例对象,只能被继承; <br/>* 抽象方法一定在抽象类中,抽象类中不一定有抽象方法; <br/>* 继承一个抽象类时,子类必须重写父类中所有抽象方法; <br/>* 被定义为抽象的方法只是声明其调用方式(参数),并不实现。 3. 多态<br/>多态是指OOP 能够根据使用类的上下文来重新定义或改变类的性质或行为,或者说接口的多种不同的实现方式即为多态。<br/> 関連する推奨事項: <br/> PHPオブジェクト指向識別オブジェクト PHPオブジェクト指向プログラミングの開発アイデアと事例分析 PHPオブジェクト指向の実践的な基礎知識 上記は、PHPオブジェクト指向の継承、ポリモーフィズムの概要です、およびカプセル化 詳細については、php 中国語 Web サイトの他の関連記事に注目してください。 タグ: PHP のポリモーフィックカプセル化 前の記事: PHP は WeChat アプレット支払いコード共有を実装 次の記事: PHP セッション制御セッションと Cookie の紹介 あなたにお勧め 2018 -02- 1174 2018-02-1074 2018-02-1059 2018-01-0567 <br/> MVC パターン (Model-View-Controller) は ソフトウェアエンジニアリング の 1 つです。 ソフトウェア アーキテクチャ パターンソフトウェア システムを 3 つの基本部分 (モデル、ビュー、コントローラー) に分割します。 MVCパターンは、1978年に「Trygve Reenskaug」によって最初に提案されました。 Smalltalk によって発明されたソフトウェア設計パターン MVC パターン の目的は、動的なプログラム設計を実装し、その後のプログラムの変更や拡張を簡素化し、プログラムの特定の部分を再利用できるようにすることです。さらに、このモードは複雑さを単純化することでプログラム構造をより直感的にします。ソフトウェアシステムは基本的な部分を分離し、またそれぞれの基本的な部分に適切な機能を与えます。専門家は、それぞれの専門知識によってグループ化できます。 (コントローラー) - リクエストの転送と処理を担当します。 (ビュー) - インターフェイスデザイナーは、グラフィカルインターフェイスのデザインを行います。 データがオンラインで保存されているのか、ビューとして従業員のリストが保存されているのかにかかわらず、ビューでは実際の処理は行われず、データを出力してユーザーが操作できるようにする手段としてのみ機能します。 <br/>モデル: <br/>モデルは企業データとビジネスルールを表します。 MVC の 3 つのコンポーネントの中で、 モデルには最も多くの処理タスク があります。たとえば、EJB や ColdFusionComponents などのコンポーネント オブジェクトを使用してデータベースを処理する場合があります。モデルによって返されるデータは中立です。つまり、モデルはデータ形式とは何の関係もないため、モデルは複数のビューにデータを提供できます。モデルに適用されるコードは 1 回記述するだけで済み、複数のビューで再利用できるため、コードの重複が削減されます。 Controller: <br/>Controllerは、ユーザー入力を受け入れ、モデルとビューを呼び出してユーザーのニーズを満たします<br/>。そのため、Web ページ内のハイパーリンクがクリックされて HTML フォームが送信された場合、コントローラー自体は何も出力したり、処理を実行したりしません。リクエストを受信し、リクエストを処理するためにどのモデル コンポーネントを呼び出すかを決定し、返されたデータを表示するためにどのビューを使用するかを決定するだけです。 MVCの利点<br/>1.結合度が低い<br/> ビュー層とビジネス層が分離されているため、モデルとコントローラーのコードを再コンパイルすることなくビュー層のコードを変更できます、同様に、アプリケーション ビジネス プロセスまたはビジネス ルールの変更には、MVC のモデル層の変更のみが必要です。モデルはコントローラーやビューから分離されているため、アプリケーションのデータ層やビジネス ルールを簡単に変更できます。 <br/>2. 高い再利用性と応用性<br/> テクノロジーの継続的な進歩に伴い、アプリケーションにアクセスするために必要な方法はますます増えています。 MVC パターンを使用すると、さまざまなスタイルのビューを使用して同じサーバー側コードにアクセスできます。たとえば、ユーザーはコンピューターまたは携帯電話を通じて特定の商品を注文できますが、注文した商品を処理する方法は同じです。モデルから返されるデータはフォーマットされていないため、同じコンポーネントを異なるインターフェイスで使用できます。たとえば、多くのデータは HTML で表現できますが、WAP で表現することもできます。これらの表現に必要なコマンドはビュー層の実装を変更することですが、コントロール層とモデル層は変更する必要がありません。変更を加えます。 <br/>3. ライフサイクルコストの削減<br/> MVC により、ユーザー インターフェイスの開発と保守の技術的負担が軽減されます。 <br/>4. 迅速なデプロイメント<br/> MVC パターンを使用すると、プログラマ (Java 開発者) がビジネス ロジックとインターフェイス プログラマ (HTML および JSP 開発者) のマニフェストに集中できるようになります。 <br/>5. 保守性<br/> ビュー層とビジネスロジック層を分離することで、WEBアプリケーションの保守や変更も容易になります。 <br/>6. ソフトウェアエンジニアリング管理に役立つ<br/>異なる層が独自の役割を実行するため、各層の異なるアプリケーションは特定の同じ特性を持ち、エンジニアリングとツールによるプログラムコード管理に役立ちます。 拡張子: WAP (ワイヤレス アプリケーション プロトコル) は、ワイヤレス アプリケーション プロトコル、グローバルなネットワーク通信プロトコルです。 WAP はモバイル インターネットの共通規格を提供しており、その目的は、インターネットの豊富な情報と高度なサービスを携帯電話などの無線端末に導入することです。 WAPは、インターネット上のHTML言語で記述された情報をWML(Wireless Markup Language)で記述された情報に変換し、携帯電話のディスプレイに表示するユニバーサルプラットフォームを定義しています。 WAP は、携帯電話と WAP プロキシ サーバーのサポートのみを必要とし、既存のモバイル通信ネットワークネットワーク プロトコルを変更する必要がないため、GSM、CDMA、TDMA、3G およびその他のネットワークで広く使用できます。 モバイル インターネット アクセスがインターネット時代の新たな寵児となるにつれ、WAP のさまざまなアプリケーション要件が登場しました。 PDA などの一部のハンドヘルド デバイスは、マイクロブラウザをインストールした後、WAP を使用してインターネットにアクセスします。 マイクロブラウザ ファイルは非常に小さいため、ハンドヘルド デバイスのメモリ容量が小さく、ワイヤレスネットワーク帯域幅が不十分であるという制限をより適切に解決できます。 WAP は HTHL と XML をサポートできますが、WML は小さな画面やキーボードのないハンドヘルド デバイス向けに特別に設計された言語です。 WAP は WMLScript もサポートしています。このスクリプト言語はJavaScriptに似ていますが、他のスクリプト言語に含まれる無駄な機能が基本的にないため、メモリとCPUの要件が低くなります。 <br/> <br/> 5回目が追加されます-in は、前のファイルがロードされるまでブロックされます。 CDNファイルは異なる領域(異なるIP)に保存されているため、ブラウザはページに必要なすべてのファイルを同時に( よりもはるかに多く)読み込むことができます。これにより、ページの読み込み速度が向上します。 2. ファイルは、 のキャッシュにロードされ、保存されている可能性があります。ネットワークでの使用は非常に一般的です。ユーザーがあなたの Web ページの 1 つを閲覧しているとき、その Web サイトで使用されている CDN を介して別の Web サイトにアクセスしている可能性が非常に高くなります。そのとき、この Web サイトでも jQuery が使用されています。 、ユーザーのブラウザはすでに jQuery ファイルをキャッシュしています (IP と同じ名前のファイルがキャッシュされている場合、ブラウザはキャッシュされたファイルを直接使用し、再度ロードしません)。一度読み込まれると再読み込みされなくなり、間接的に Web サイトのアクセス速度が向上します。 3. 高い効率あなたのウェブサイトがどんなに優れていてもNB、BaiduNBには合格しませんNB CDN は、効率が高く、ネットワーク遅延が短く、パケット損失率が小さくなります。 4. 分散データセンター あなたのサイトが北京にある場合、香港またはそれより遠くからユーザーがあなたのサイトを訪問すると、そのデータリクエストは必然的に非常に遅くなります。 CDNを使用すると、ユーザーは最も近いノードから必要なファイルを読み込むことができるため、読み込み速度が向上するのは当然です。 5. 組み込みのバージョン管理 通常、CSSファイルとJavaScriptライブラリには、特定のバージョン番号を使用してからダウンロードできます。 CDN 必要なファイルをロードします。latestを使用して最新バージョンをロードすることもできます (推奨されません)。 6. 使用状況分析 一般に、CDNプロバイダー(Baidu Cloud Acceleration など)は、ユーザーの Web サイトへの訪問をタイムリーに把握するためのデータ統計機能を提供します。統計データに基づいてサイトを適切に調整します。 7. Web サイトへの攻撃を効果的に防止します 通常の状況では、CDNプロバイダーも Web サイトのセキュリティ サービスを提供します。 動機付け なぜデータを直接配信しないのですか?つまり、ユーザーがソース ステーションから直接データを取得できるようにしないのですか? <br/>私たちがよく言うインターネットは、実はTCP/IPを中心としたネットワーク層、つまりインターネットと、World Wide WebのWWWに代表されるアプリケーション層から構成されています。データがサーバーからクライアントに配信されるとき、少なくとも 4 か所でネットワークの輻輳が発生する可能性があります。 1. 「最初の 1 マイル」とは、ユーザーに送信される World Wide Web トラフィックの最初の出口を指し、Web サイト サーバーがインターネットにアクセスするためのリンクです。この下り帯域幅によって、Web サイトがユーザーに提供できるアクセス速度と同時アクセスが決まります。ユーザーのリクエストが Web サイトの出力帯域幅を超えると、出力で輻輳が発生します。 上記のネットワーク混雑の分析に基づいて、ネットワーク上のデータがソースサイトからユーザーに直接配信される場合、アクセス混雑が発生する可能性が高くなります。 <br/>ユーザーが最も速い速度でデータを取得できるように、ユーザーに最も近い場所にデータをキャッシュする技術的ソリューションがあれば、Web サイトのエクスポート帯域幅の圧力を軽減し、ネットワーク伝送の混雑を軽減する上で大きな役割を果たすでしょう。効果。 CDN はまさにそのような技術的なソリューションです。 <br/> ユーザーがブラウザーを通じて従来の (CDN なしの) Web サイトにアクセスするプロセスは次のとおりです。 <br/> CDNを利用する場合は以下のような処理となります。 <br/> Web サイトとユーザーの間に CDN を導入した後、ユーザーは元の Web サイトと何の違いも感じなくなります。 <br/> CDN サービスを使用する Web サイトは、ドメイン名の解決権限を CDN の負荷分散デバイスに引き渡すだけで済み、CDN 負荷分散デバイスはユーザーに適したキャッシュ サーバーを選択し、ユーザーはアクセスすることで必要なものを取得できます。このキャッシュサーバー。 <br/>キャッシュサーバーはネットワーク事業者のコンピュータルームに設置されており、ネットワーク事業者はユーザーのネットワークサービスプロバイダーであるため、ユーザーは最短経路かつ最速でウェブサイトにアクセスできます。したがって、CDN はユーザー アクセスを高速化し、オリジン センターにかかる負荷を軽減します。 <br/> <br/> 1. ネットワークからの各リクエストは、1からNまで順番に内部サーバーに割り当てられます。その後、再度開始します。このバランシング アルゴリズムは、サーバー グループ内のすべてのサーバーが同じハードウェアおよびソフトウェア構成を持ち、平均的なサービス リクエストが比較的バランスがとれている状況に適しています。 2. 加重ラウンドロビン: サーバーのさまざまな処理能力に応じて、各サーバーに異なる加重が割り当てられ、対応する加重でサービス リクエストを受け入れることができます。たとえば、サーバー A の重みは 1、B の重みは 3、C の重みは 6 になるように設計されている場合、サーバー A、B、および C はサービスの 10%、30%、および 60% を受け取ることになります。それぞれリクエストします。このバランシング アルゴリズムにより、高性能サーバーの使用率が向上し、低パフォーマンス サーバーの過負荷が防止されます。 3. ランダムバランス (Random): ネットワークからのリクエストを複数の内部サーバーにランダムに分散します。 4. 加重ランダム バランシング (加重ランダム): このバランシング アルゴリズムは加重ラウンドロビン アルゴリズムに似ていますが、リクエストの共有を処理する際のランダムな選択プロセスです。 5. 応答時間のバランシング (応答時間): 負荷分散デバイスは各内部サーバーに検出リクエスト (Ping など) を送信し、各内部サーバーの検出に対する最速の応答時間に基づいて応答するサーバーを決定します。クライアントのサービスリクエスト。このバランシング アルゴリズムは、サーバーの現在の実行ステータスをより適切に反映できますが、最速の応答時間は、負荷分散デバイスとサーバー間の最速の応答時間を指すだけであり、クライアントとサーバー間の最速の応答時間ではありません。 サービス障害の検出方法と機能: <br/> <br/> Smarty のようなテンプレート エンジンや Zend や Diango のような MVC フレームワークなど、ページ キャッシュの実装方法は数多くあります。コントローラーとビューは分離されており、コントローラーは独自のキャッシュ コントロールを簡単に持つことができます。 通常、動的コンテンツのキャッシュはディスクに保存されます。ディスクは、大量のファイルを保存するための安価な方法を提供します。これはスペースの問題を解決するための簡単な方法です。ただし、キャッシュ ディレクトリ内に多数のキャッシュ ファイルが存在する可能性があり、CPU がディレクトリの移動に多くの時間を費やしてしまう可能性があります。この問題を解決するには、キャッシュ ディレクトリ階層を使用します。各ディレクトリの下のサブディレクトリが存在することを確認するか、ファイル数を狭い範囲内に収めてください。このようにして、多数のキャッシュ ファイルが保存されている場合、CPU がディレクトリを走査する時間の消費を削減できます。 キャッシュデータがディスクファイルに保存される場合、キャッシュロードと有効期限チェックごとにディスクI/Oオーバーヘッドが発生し、ディスクI/O負荷が大きい場合はディスク負荷の影響も受けます。キャッシュファイルのI/O 動作に多少の遅延が発生します。 さらに、キャッシュをローカル メモリに配置することもできます。これは、PHP の APC モジュールまたは PHP キャッシュ拡張機能 XCache を使用して簡単に実装でき、キャッシュのロード時にディスク I/O 操作が発生しません。 。 独立したキャッシュ サーバー に保存することもできます。Memcached を使用すると、TCP 経由で他のサーバーにキャッシュを簡単に保存できます。 memcached を使用すると、ローカル メモリを使用するよりも若干遅くなりますが、キャッシュをローカル メモリに保存する場合と比較して、memcached を使用してキャッシュを実装することには 2 つの利点があります: キャッシュ有効期間 メカニズムに基づいてチェックされます。 いつでもキャッシュを強制的にクリアするための制御方法も提供します。 ブラウザは Web サイトの重要な部分です。ブラウザーにコンテンツをキャッシュすると、サーバーのコンピューティングのオーバーヘッドが削減されるだけでなく、不必要な送信や帯域幅の浪費も回避できます。キャッシュされたコンテンツをブラウザ側に保存するには、通常、キャッシュされたファイルを保存するディレクトリがユーザーのファイル システムに作成され、各キャッシュされたファイルには有効期限などの必要なタグが付けられます。さらに、ブラウザごとにキャッシュ ファイルの保存方法に微妙な違いがあります。 当 Web 服务器接收到浏览器请求后,Web 服务器需要告知浏览器哪些内容可以缓存,一旦浏览器知道哪些内容可以缓存后,下次当浏览器需要请求这个内容时,浏览器便不会直接向服务器请求完整内容,二是询问服务器是否可以使用本地缓存,服务器在收到浏览的询问后回应是使用浏览器本地缓存还是将最新内容传回给浏览器。 Last-Modified Last-Modified 是一种协商方式。通过动态程序为 HTTP 相应添加最后修改时间的标记 此时,Web 服务器的响应头部会多出一条: 这代表 Web 服务器对浏览器的暗示,告诉浏览器当前请求内容的最后修改时间。收到 Web 服务器响应后,再次刷新页面,注意到发出的 HTTP 请求头部多了一段标记: 这表示浏览器询问 Web 服务器在该时间后是否有更新过请求的内容,此时,Web 服务器需要检查请求的内容在该时间后是否有过更新并反馈给浏览器,这其实就是缓存过期检查。 如果这段时间里请求的内容没有发生变化,服务器做出回应,此时,Web 服务器响应头部: 注意到此时的状态码是304,意味着 Web 服务器告诉浏览器这个内容没有更新,浏览器使用本地缓存。如下图所示: ETag HTTP/1.1 还支持ETag缓存协商方法,与最后过期时间不同的是,ETag不再采用内容的最后修改时间,而是采用一串编码来标记内容,称为ETag,如果一个内容的 ETag 没有变化,那么这个内容就一定没有更新。 ETag 由 Web 服务器生成,浏览器在获得内容的 ETag 后,会在下次请求该内容时,在 HTTP 请求头中附加上相应标记来询问服务器该内容是否发生了变化: 这时,服务器需要重新计算这个内容的 ETag,并与 HTTP 请求中的 ETag 进行对比,如果相同,便返回 304,若不同,则返回最新内容。如下图所示,服务器发现请求的 ETag 与重新计算的 ETag 不同,返回最新内容,状态码为200。 Last-Modified VS ETag 基于最后修改时间的缓存协商存在一些缺点,如有时候文件需频繁更新,但内容并没有发生变化,这种情况下,每次文件修改时间变化后,无论内容是否发生变化,都会重新获取全部内容。另外,在采用多台 Web 服务器时,用户请求可能在多台服务器间变化,而不同服务器上同一文件最后修改时间很难保证完全一样,便会导致重新获取所有内容。采用 ETag 方法就可以避免这些问题。 首先,原本使用浏览器缓存的动态内容,在使用浏览器缓存后,能否获得大的吞吐率提升,关键在于是否能避免一些额外的计算开销,同事,还取决于 HTTP 响应正文的长度,若 HTTP 响应较长,如较长的视频,则能带来大的吞吐率提到。 但使用浏览器缓存的最大价值并不在此,而在于减少带宽消耗。使用浏览器缓存后,如果 Web 服务器计算后发现可以使用浏览器端缓存,则返回的响应长度将大大减少,从而,大大减少带宽消耗。 The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases. 在上面两图中,有个 对于主流浏览器,有三种请求页面方式: Ctrl + F5:强制刷新,使网页以及所有组件都直接向 Web 浏览器发送请求,并且不适用缓存协商,从而获取所有内容的最新版本。等价于按住 Ctrl 键后点击浏览器刷新按钮。 F5:允许浏览器在请求中附加必要的缓存协商,但不允许直接使用本地缓存,即让Last-Modified生效、Expires无效。等价于单击浏览器刷新按钮。 单击浏览器地址栏“转到”按钮或通过超链接跳转:浏览器对于所有没过期的内容直接使用本地缓存,Expires只对这种方式生效。等价于在地址栏输入 URL 后回车。 Expires指定的过期时间来源于 Web 服务器的系统时间,如果与用户本地时间不一致,就会影响到本地缓存的有效期检查。 一般情况下,操作系统都使用基于 GMT 的标准时间,然后通过时区来进行偏移计算,HTTP 中也使用 GMT 时间,所以,一般不会因为时区导致本地与服务器相差数个小时,但没人能保证本地时间与服务器一直,甚至有时服务器时间也是错误的。 针对这个问题,HTTP/1.1 添加了标记 Cache-Control,如上图1所示, HTTP 是浏览器与 Web 服务器沟通的语言,且是它们唯一的沟通方式,好好学学 HTTP 吧! 前面提到的动态内容缓存和静态化基本都是通过动态程序来实现的,下面讨论 Web 服务器自己实现缓存机制。 Web 服务器接收到 HTTP 请求后,需要解析 URL,然后将 URL 映射到实际内容或资源,这里的“映射”指服务器处理请求并生成响应内容的过程。很多时候,在一段时间内,一个 URL 对应一个唯一的响应内容,比如静态内容或更新不频繁的动态内容,如果将最终内容缓存起来,下次 Web 服务器接收到请求后可以直接将响应内容返回给浏览器,从而节省大量开销。现在,主流 Web 服务器都提供了对这种类型缓存的支持。 当使用 Web 服务器缓存时,如果直接命中,那么将省略后面的一系列操作,如 CPU 计算、数据库查询等,所以,Web 服务器缓存能带来较大性能提升,但对于普通 HTML 也,带来的性能提升较有限。 那么,缓存内容存储在什么位置呢?一般来说,本机内存和磁盘是主要选择,也可以采用分布式设计,存储到其它服务器的内存或磁盘中,这点跟前面提到的动态内容缓存类似,Apache、lighttpd 和 Nginx 都提供了支持,但配置上略有差别。 提到缓存,就不得不提有效期控制。与浏览器缓存相似,Web 服务器缓存过期检查仍然建立在 HTTP/1.1 协议上,要指定缓存有效期,仍然是在 HTTP 响应头中加入 这样一来,Web服务器就不会将这个动态内容缓存起来,当然,也有其它方法实现这个功能。 如果动态内容没有输出 Expires 标记,也可以采用 那么,是否可以使用 Web 服务器缓存取代动态程序自身的缓存机制呢?当然可以,但有些注意: 让动态程序依赖特定 Web 服务器,降低应用的可移植性。 Web 服务器缓存机制实质上是以 URL 为键的 key-value 结构缓存,所以,必须保证所有希望缓存的动态内容有唯一的 URL。 编写面向 HTTP 缓存友好的动态程序是唯一需要考虑的事。 对静态内容,特别是大量小文件站点, Web 服务器很大一部分开销花在了打开文件上,所以,可以考虑将打开后的文件描述符直接缓存到 Web 服务器的内存中,从而减少开销。但是,缓存文件描述符仅仅适用于静态内容,而且仅适用于小文件,对大文件,处理它们的开销主要在传送数据上,打开文件开销小,缓存文件描述符带来的收益小。 代理(Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(Proxy Server)。 上記は、Wikipedia のプロキシの定義です。この場合、ユーザーはプロキシ サーバーの背後に隠されます。この逆に、Web サーバーはプロキシ サーバーの背後に隠されます。 .プロキシ(リバースプロキシ)と同様に、この仕組みを実現するサーバーをリバースプロキシサーバー(リバースプロキシサーバー)と呼びます。通常、リバース プロキシ サーバーの背後にある Web サーバーをバックエンド サーバー (バックエンド サーバー) と呼び、これに対応して、リバース プロキシ サーバーをフロントエンド サーバー (フロントエンド サーバー) と呼びます。はインターネットに公開されており、バックエンド Web サーバーは内部ネットワークを介して接続されており、ユーザーはリバース プロキシ サーバーを介して間接的に Web サーバーにアクセスします。これにより、ある程度のセキュリティがもたらされるだけでなく、キャッシュも可能になります。ベースの加速。 リバース プロキシを実装するにはさまざまな方法があります。たとえば、最も一般的な Nginx サーバーをリバース プロキシ サーバーとして使用できます。 ユーザーのブラウザと Web サーバーが正常に動作するには、リバース プロキシ サーバーを経由する必要があるため、リバース プロキシ サーバーは優れた制御を備えており、通過するデータを書き換えることができます。 HTTP ヘッダー情報は、他のカスタム メカニズムを通じてキャッシュ戦略に直接介入することもできます。前の内容からわかるように、HTTP ヘッダー情報によってコンテンツをキャッシュできるかどうかが決まります。そのため、リバース プロキシ サーバーは、パフォーマンスを向上させるために、通過するデータの HTTP ヘッダー情報を変更して、どのコンテンツをキャッシュできるかを決定できます。キャッシュされるものとキャッシュできないもの。 リバース プロキシ サーバーは、キャッシュをクリアする機能も提供します。ただし、動的コンテンツ キャッシュでは、キャッシュが期限切れになる前にアクティブにキャッシュを削除できます。ベースのリバース プロキシ キャッシュ メカニズムは更新が簡単ではありません。リバース プロキシ サーバー上のキャッシュ領域がクリアされない限り、バックエンド動的プログラムはキャッシュされたコンテンツをアクティブに削除できません。 memcached など、成熟した分散キャッシュ システムが多数あります。キャッシュを実現するために、キャッシュの内容をディスクに配置しません。この原則に基づいて、memcached は物理メモリをキャッシュ領域として使用し、データをキーと値の形式で保存します。これは、単一インデックス構造とデータ構成です。各キーと対応する値を合わせてデータ項目と呼びます。各データ項目は、キーを使用して一意のインデックスとして使用されます。ハッシュ アルゴリズムを使用してストレージ データ構造を設計し、慎重に設計されたメモリ アロケータを使用してデータ項目のクエリ時間の複雑さを O(1) に達させます。 memcached は、LRU (最近使用されたリース) アルゴリズムに基づく削除メカニズムを使用してデータを削除します。同様に、有効期限の設定についてもデータ項目に設定できます。 memcached は分散キャッシュ システムとして独立したサーバー上で実行でき、動的コンテンツには TCP ソケット経由でアクセスします。この場合、memcached 独自のネットワーク同時処理モデルが非常に重要です。 Memcached は、libevent 関数ライブラリを使用してネットワーク同時実行モデルを実装し、多数の同時ユーザーが存在する環境で使用できます。 キャッシュ システムを使用して読み取り操作を実装する場合、データベースの「事前読み取りキャッシュ」を使用するのと同じになり、スループット レートを大幅に向上させることができます。 書き込み操作の場合、キャッシュ システムも大きなメリットをもたらします。一般的なデータ書き込み操作には、挿入、更新、削除が含まれます。これらの書き込み操作には検索やインデックスの更新が伴うことが多く、多くの場合、膨大なオーバーヘッドが発生します。分散キャッシュを使用すると、データをキャッシュに一時的に保存してから、バッチ書き込み操作を実行できます。 memcached 分散キャッシュ システムとして、タスクを適切に完了することができます。同時に、memcached は、いくつかの重要な情報を含むリアルタイムのステータスを取得できるプロトコルも提供します。 複数のキャッシュ サーバーがある場合、私たちが直面する問題は、キャッシュ データを複数のキャッシュ サーバーに均等に分散する方法です。この場合、キーベースのパーティショニング方法を選択して、異なるサーバー上のすべてのデータ項目のキーを均等に分散することができます (剰余方法など)。この場合、システムを拡張するときに、パーティショニング アルゴリズムの変更により、キャッシュされたデータをあるキャッシュ サーバーから別のキャッシュ サーバーに移行する必要があります。実際には、移行を考慮する必要はまったくありません。キャッシュされたデータである場合は、キャッシュを再構築するだけです。 <br/> と 純粋な静的: PHP は HTML ファイルを生成します。 : コンテンツを nosql メモリ (memcached) に保存し、ページにアクセスするときにメモリから直接読み取ります。 大規模な動的Webサイトの静的化<br/>参考記事:「大規模Webサイトの静的化処理」 動的 Web サイト、特に 大規模な静的 Web サイトが迅速かつ高い同時実行性で応答できる理由は、動的な Web サイトを静的にするために最善を尽くしているためです。 js、css、imgなどのリソースはサーバー側でマージされて返されます 他の2種類のページ(動的ページと擬似静的ページ)と比較すると、は最速で、そうではありません。 データはデータベースから抽出する必要があります。これは高速であり、サーバーに負担をかけません。 短所: データはHTMLで保存されるため、ファイルが非常に大きくなります。そして最も深刻な問題は、ソース コードを変更すると、ソース コード全体を変更する必要があり、1 か所を変更することはできず、サイト全体の静的ページが自動的に変更されてしまうことです。大量のデータを含む大規模な Web サイトの場合、多くのサーバー容量が必要になり、コンテンツが追加されるたびに新しい HTML ページが生成されます。メンテナンスは専門家でないと面倒です。 2. 動的ページ 利点: 一般に、数万のデータを含む Web サイトのファイル サイズは、動的ページを使用すると数 M しかありませんが、静的ページでは可能です。最小値は 12 M、最大値は 10 M、あるいはそれ以上になります。データベースはデータベースから取得されるため、いくつかの値を変更してデータベースを直接変更する必要がある場合、すべての動的 Web ページが自動的に更新されます。静的ページに対するこの利点は明らかです。 短所: ユーザーのアクセス速度が遅いですが、動的ページへのアクセスが遅いのはなぜですか?この問題は、動的ページのアクセス メカニズムから始まります。実際、ユーザーがアクセスすると、この解釈エンジンが動的ページを静的ページに変換します。ブラウザでソースコードを表示します。そして、このソースコードは、解釈エンジンによる翻訳後のソースコードです。アクセス速度が遅いことに加えて、動的ページのデータはデータベースから呼び出されるため、アクセスする人が増えるとデータベースへの負担が非常に大きくなります。ただし、今日の動的プログラムのほとんどはキャッシュ テクノロジを使用しています。しかし、一般的に言えば、動的ページはサーバーに大きな負荷をかけます。同時に、動的なページを含む Web サイトでは、同時にアクセスする人が増えるほど、サーバーに対する要件が高くなります。 3. 疑似静的ページ URL 書き換えにより、index.php は、index.html になります <br/> 疑似静的ページ 定義 : 「偽の」静的ページ、本質的には動的ページです。 利点: 「偽の」静的ページであるため、静的ページと比較して明らかな速度の向上はありませんが、実際には動的ページであり、静的ページに変換する必要もあります。最大の利点は、検索エンジンが Web ページを静的ページとして扱うことができることです。 短所: その名前が示すように、「疑似静的」とは、検索エンジンがそれを静的ページとして扱いません。これは単に経験とロジックに基づいて分析されたものであり、そうではありません。必然的に正確です。おそらく、検索エンジンはそれを動的ページとして直接認識します。 簡単な要約: 静的ページはアクセスが最も速く、メンテナンスはより面倒です。 動的ページはスペースをあまり取らず、保守が簡単ですが、アクセス速度が遅く、多くの人がアクセスするとデータベースに負担がかかります。 SEO (検索エンジン最適化: Search Engine Optimization) での純粋な静的の使用と擬似静的の使用に本質的な違いはありません。 擬似静的を使用すると、一定量の CPU 使用率が占有され、頻繁に使用すると CPU 過負荷が発生します。 <br/> この間何度かCSSスプライトの概念に触れたのは、CSSを使って引き戸を作っていたときと、YSlowを使ってWebサイトのパフォーマンスを分析していたときでした。 CSS スプライトの概念に深く興味があります。インターネットで色々な情報を調べましたが、残念ながら海外の情報を直訳したものが多く、中には海外の情報サイトを直接紹介しているものもあり、残念ながら英語の試験には合格しませんでした。 CSS スプライトの使い方は言うまでもなく、基本的に何も理解していませんでした。 最後に、私は Blue Ideal の記事に触発され、長い間考えた結果、他の人が CSS スプライトをより早く習得できるよう、自分の理解を活用するという意味を理解しました。 まずは簡単にご紹介します コンセプトに関してはネット上に溢れているのでここで簡単に触れておきます。 CSSスプライトとは css スプライトの直訳はCSSスプライトですが、この翻訳は明らかに十分ではありません。実際には、複数の画像を1つの画像にマージし、それをいくつかの画像を通してWebページ上に配置することです。 CSS テクニック。これによる利点も明らかです。写真が多いと http リクエストが増加するため、特に CSS スプライトを使用して写真の数を減らすことができれば、間違いなく Web サイトのパフォーマンスが低下します。画像の速度が向上します。 下面我们来用一个实例来理解css sprites,受蓝色理想中的《制作一副扑克牌系列教程》启发。 我们仅仅只需要制作一个扑克牌,拿黑桃10为例子。 可以直接把蓝色理想中融合好的一幅大图作为背景,这也是css sprites的一个中心思想,就是把多个图片融进一个图里面。 这就是融合后的图,相信对PS熟悉的同学应该很容易的理解,通过PS我们就可以组合多个图为一个图。 现在我们书写html的结构: 在这里我们来分析强调几点: 一:card为这个黑桃十的盒子或者说快,对p了解的同学应该很清楚这点。 二:我用span,b,em三种标签分别代表三种不同类型的图片,span用来表标中间的图片,b用来表示数定,em用来表示数字下面的小图标。 三:class里面的声明有2种,一个用来定位黑桃10中间的图片的位置,一个用来定义方向(朝上,朝下)。 上面是p基本概念,这还不是重点,不过对p不太清楚的同学可以了解。 下面我们重点谈下定义CSS: span{display:block;width:20px;height:21px; osition:absolute;background:url(images/card.gif) no-repeat;} 这个是对span容器的CSS定义,其他属性就不说了,主要谈下如何从这个里面来理解css sprites。 背景图片,大家看地址就是最开始我们融合的一张大图,那么如何将这个大图中的指定位置显示出来呢?因为我们知道我们做的是黑桃10,这个大图其他的图像我们是不需要的,这就用到了css中的overflow:hidden; 但大家就奇怪了span的CSS定义里面没有overflow:hidden啊,别急,我们已经在定义card的CSS里面设置了(这是CSS里面的继承关系): .card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;} 理解到这点还不够,还要知道width:125px;height:170px; 这个可以理解成是对这个背景图片的准确切割,当然其实并不是切割,而是把多余其他的部分给隐藏了,这就是overflow:hidden的妙用。 通过以上的部分的讲解,你一定可以充分的把握css sprites的运用,通过这个所谓的“切割”,然后再通过CSS的定位技术将这些图准确的分散到这个card里面去! PS:CSS的定位技术,大家可以参考其他资料,例如相对定位和绝对定位,这里我们只能尝试用绝对定位。 最后我们来补充一点: 为什么要采取这样的结构? span这个容器是主要作用就是存放这张大的背景图片,并在里面实现”切割“,span里面切割后的背景是所有内容块里面通用的! 后面class为什么要声明2个属性? 很显然,一个是用来定位内容块的位置,一个是用来定义内容块中的图像的朝上和朝下,方位的! 下面我们附上黑桃10的完整源码: 最后感谢蓝色理想提供的参考资料! <br/> <br/> 1、前言 最近仕事でリバース プロキシを使用しましたが、ネットワーク プロキシを使用する方法がたくさんあることがわかりました。ネットワークの背後には学ぶ必要があることがたくさんあります。これまでは、Google にアクセスするにはプロキシ ソフトウェアを使用し、ブラウザでプロキシ アドレスを設定する必要がありました。エージェンシーという概念だけは知っていましたが、順方向エージェンシーや逆方向エージェンシーがあることは知らなかったので、すぐに知って知識を補いました。まず、フォワード プロキシとリバース プロキシが何であるかを理解します。次に、実際の使用で 2 つがどのように実証されるかを説明します。最後に、フォワード プロキシが何に使用されるか、リバース プロキシで何ができるかをまとめます。 2. フォワードプロキシ フォワードプロキシは外部リソースへのアクセスを代理する踏み台のようなものです。 例: 私はユーザーであり、特定の Web サイトにアクセスできませんが、このプロキシ サーバーはアクセスできない Web サイトにアクセスできるため、最初にプロキシ サーバーに接続します。アクセスできない Web サイトのコンテンツが必要であると伝えると、プロキシ サーバーがそれを取得して私に返します。 Web サイトの観点から見ると、プロキシ サーバーがコンテンツを取得するときに存在するレコードは 1 つだけであり、それがユーザーのリクエストであることがわからない場合があり、ユーザーの情報もプロキシが Web サイトに通知するかどうかによって異なります。ない。 もちろん、クライアントはフォワードプロキシサーバーのIPアドレスとプロキシプログラムのポートを知っていることが前提となります。 たとえば、CCproxy、http://www.ccproxy.com/ など、このタイプのソフトウェアを以前に使用したことがある場合は、ブラウザでプロキシ アドレスを設定する必要があります。 要約: フォワードプロキシは、クライアントとオリジンサーバーの間に位置するサーバーであり、オリジンサーバーからコンテンツを取得するために、クライアントはプロキシにリクエストを送信し、ターゲット(オリジンサーバー)を指定します。 )、プロキシはリクエストをオリジンサーバーに転送し、取得したコンテンツをクライアントに返します。フォワード プロキシを使用するには、クライアントで特別な設定を行う必要があります。 フォワードプロキシの目的: (1) google など、元々アクセスできなかったリソースへのアクセス (2) キャッシュを行うことでリソースへのアクセスを高速化できます (3) クライアントの認可アクセス、認証のためにオンラインにする (4) プロキシはユーザーのアクセス記録(オンライン行動管理)を記録し、ユーザー情報を外部から隠すことができます 例えば、CCProxyの使用法: 3. 方向性プロキシとの最初の接触の感覚 はい、クライアントはプロキシの存在を知りません。また、リバース プロキシは外部に対して透過的です。訪問者は自分がプロキシを訪問していることを知りません。クライアントはアクセスするために構成を必要としないためです。 リバースプロキシの実際の運用方法は、プロキシサーバーを利用してインターネット上の接続要求を受け付け、その要求を内部ネットワーク上のサーバーに転送し、サーバーから得られた結果をインターネットに返して接続を要求するというものです。 .クライアントでは、この時点でプロキシ サーバーが外部に対してサーバーとして表示されます。 リバース プロキシの役割: (1) イントラネットのセキュリティを確保するために、リバース プロキシを使用して WAF 機能を提供し、Web 攻撃を防ぐことができます 大規模な Web サイトは通常、パブリック ネットワーク アクセス アドレスとしてリバース プロキシを使用し、 Web サーバーはイントラネットです。 (2) リバースプロキシサーバーを介して Web サイトの負荷を最適化する負荷分散 nginx は proxy_pass_http を通じてプロキシ サイトを構成し、アップストリームは負荷分散を実装します。 参照: プロキシとは、その名前が示すように、自分自身ではなくサードパーティを使用して、ユーザーに代わって実行することを意味し、ローカル マシンとターゲットの間に追加の中間サーバー (プロキシ サーバー) があると想像できます。サーバー フォワードプロキシは、クライアントと元のサーバーの間にあるサーバー (プロキシサーバー) です。 クライアントは、最初に必要な設定を行う必要があります (プロキシサーバーの IP とポートを知っている必要があります)。 各リクエストをプロキシ サーバーに送信します。プロキシ サーバーは応答を実サーバーに転送し、クライアントに返します。 ) に代わってターゲット サーバーにアクセスします。クライアントを非表示にする) ターゲットサーバーを隠す) 元のサーバーを隠し、悪意のあるサーバー攻撃を防ぎます。など、クライアントにプロキシ サーバーが元のサーバーであると思わせ、元のサーバーのデータをキャッシュして、元のサーバーのアクセス圧力を軽減します。これは、クライアントがプロキシ サーバーの存在をまったく知る必要がないことを意味し、リクエスト フィールド (メッセージ) が適応され、暗号化された透過プロキシが匿名プロキシとして送信されることに注意してください。プロキシを設定する必要はありません。透過的なプロキシの実践例は、以下の図 3.1 に示すように、現在多くの企業で使用されている動作管理ソフトウェアです 使用法 フォワード プロキシ リバース プロキシ セキュリティ フォワードプロキシ mysql は、読み取りと書き込みを分離し、メインサーバーへの負荷を軽減するためにマスター/スレーブ同期方式を使用しています。 マスタとスレーブの同期は、基本的にはリアルタイム同期を実現できます。マスターとスレーブの同期回路図を別の Web サイトから借用しました。 <br/> <br/> マスターとスレーブの同期が構成された後、マスターサーバーは更新ステートメントをbinlogに書き込み、スレーブサーバーのIOスレッド(ここでIOスレッドが5.6.3 より前は 1 つだけです。5.6.3 以降は読み取りにマルチスレッドが使用され、自然に速度が向上します) 戻ってメインサーバーのバイナリログを読み取り、それをサーバーのリレーログに書き込みます。スレーブサーバーに接続すると、スレーブサーバーの SQL スレッドがリレーログ内の SQL を 1 つずつ実行してデータ回復を実行します。 <br/> リレーは送信を意味し、リレーレースはリレーレースを意味します <br/> 1.マスターとスレーブの同期が遅れる理由 クライアントが接続するためにサーバーがN個のリンクを開くことがわかっています。この方法では、大規模な同時更新操作が行われますが、特定の SQL がスレーブ サーバーで実行するのに少し時間がかかる場合、または特定の SQL がテーブルをロックする必要がある場合、サーバーからバイナリログを読み取るスレッドは 1 つだけになります。マスター サーバー上に大量の SQL バックログがあり、スレーブ サーバーに同期されていない可能性があります。これは、マスターとスレーブの不一致、つまりマスターとスレーブの遅延につながります。 <br/> 2. マスターとスレーブの同期遅延に対する解決策 実際、すべての SQL はスレーブ サーバーで実行する必要があるため、マスターとスレーブの同期遅延に対するワンストップの解決策はありません。スレーブ同期の遅延 サーバーに継続的に更新操作が書き込まれ続ける場合、一度遅延が発生すると、遅延がさらに悪化する可能性が高くなります。 もちろん、何らかの緩和策を講じることはできます。 a. マスター サーバーは更新操作を担当するため、sync_binlog=1、innodb_flush_log_at_trx_commit = 1 などの一部の設定は変更できますが、このような高度なデータ セキュリティが必要な場合は、sync_binlog を 0 に設定するか、binlog をオフにすることができます。innodb_flushlog、innodb_flush_log_at_trx_commit を 0 に設定して、SQL の実行効率を向上させることもできます。これにより、SQL の実行効率が大幅に向上します。もう 1 つは、メイン ライブラリよりも優れたハードウェア デバイスをスレーブとして使用することです。 b. クエリを提供せずにスレーブサーバーをバックアップとして使用するだけで、負荷が軽減されると、リレーログ内の SQL の実行効率が自然に高くなります。 c. スレーブサーバーを追加する目的は、読み取り圧力を分散し、サーバーの負荷を軽減することです。 <br/> 3. マスターとスレーブの遅延を判断する方法 MySQL には、show smile status を通じて表示できるスレーブ サーバー ステータス コマンドが用意されています。 Seconds_Behind_Master パラメーターを使用して、マスター/スレーブ遅延が発生するかどうかを決定します。 <br/>いくつかの値があります: <br/>NULL - io_thread または sql_thread のいずれかが失敗したことを示します。つまり、スレッドの実行ステータスが Yes ではなく、No であることを示します。 <br/>0 - 値はゼロです。マスター/スレーブのレプリケーション ステータスが正常であることを非常に楽しみにしています <br/> > 1. Redis は、String、Hash、List、Set、Sorted Set というより豊富なデータ ストレージ タイプをサポートします。 Memcached は単純なキーと値の構造のみをサポートします。 <br/>> 2. Memcached のキーと値のストレージは、キーと値のストレージにハッシュ構造を使用する Redis よりもメモリ使用率が高くなります。 <br/>> 3. Redis は、一連のコマンドのアトミック性を保証できるトランザクション機能を提供します <br/>> 4. Redis はデータの永続性をサポートし、データをディスク上のメモリに保持できます <br/>> 5. Redis はシングルコアのみを使用します。一方、Memcached は複数のコアを使用できるため、小規模なデータを保存する場合、各コアの Redis は Memcached よりも平均してパフォーマンスが高くなります。 <br/><br/>- Redis はどのようにして永続性を実現しますか? <br/><br/>> 1. RDB の永続化。メモリ内の Redis の状態をハードディスクに保存します。これはデータベースの状態をバックアップするのと同等です。 <br/>> 2. AOF 永続性 (Append-Only-File)、AOF 永続性は、Redis サーバーのロック実行の書き込みステータスを保存することでデータベースを記録します。バックアップ データベースが受信したコマンドと同様に、AOF に書き込まれたすべてのコマンドは Redis プロトコル形式で保存されます。 <br/> <br/> <br/> コンピュータプラットフォームを使用しました。アプリケーションサーバーに属します。 Apacheは多くのモジュールをサポートしており、安定したパフォーマンスを持っていますApache自体は静的解析であり、静的なHTMLなどに適していますが、拡張スクリプトを通じて動的ページなどをサポートすることができます。 、モジュールなど。 (Apche はPHPcgiperl、をサポートできますが、Javaを使用するには、ApacheのTomcatが必要です バックエンドのサポート、Javaリクエストは Apache によって処理のために Tomcat に転送されます) 欠点: 構成は比較的複雑で、動的ページはサポートされていません。 Tomcat Java)サーバーであり、単なるサーブレット(JSPはサーブレットとも訳される)コンテナです。 Apache の拡張機能とみなされますが、Apache とは独立して実行できます。 3. Nginxinnginxは、ロシア人によって書かれた非常に軽量な です。その発音は「Engine X」の高性能HTTPです。サーバー、および IMAP/POP3/SMTP プロキシ サーバー。 2. 比較 1. Apache と Tomcat の比較 同じ点: l l によって開発されました の特徴どちらも HTTPサービス どちらも無料です の違い: は、HTTPサービスと関連設定(仮想ホスト、URL転送など)を提供するために特に使用されますが、Tomcat は、Java EEに準拠するJSP、Servlet標準に準拠して、Apache組織によって開発されたJSPサーバーです。 l Apache は、Webサーバー環境プログラムであり、Webサーバーとして使用できますが、などの静的なWebページのみをサポートします(ASP 、PHP、CGI、JSP) およびその他の動的 Web ページは機能しません。 Apache環境でJSPを実行したい場合、JSPウェブページ、を実行するためのインタープリタが必要であり、このJSPインタープリタはですトムキャット 。 l Apache: はHTTPServerに焦点を当てます 、Tomcat: はServletエンジンに焦点を当てます(Standaを使用する場合) lone モードで実行され、機能的には と同じですApacheと同等で、JSPをサポートしますが、静的なWebページには理想的ではありませんl ApacheはWeb サーバーです。 Tomcatはアプリケーションです( Java ) サーバー、これは単なる サーブレット (JSP は サーブレットとも訳される) コンテナであり、 Apache の拡張機能と見なされますが、独立して実行できます。 アパッチ。 実際の使用では、ApacheとTomcat が統合されて使用されることがよくあります: l クライアントが静的ページをリクエストする場合、Aのみパチェが必要ですサーバー リクエストに応答します。 l クライアントが動的ページをリクエストした場合、リクエストに応答するのはTomcatサーバーです。 l JSPはサーバー側でコードを解釈するため、統合により のサービスオーバーヘッドを削減できます。 TomcatはApacheの拡張であることが理解できます。 l よりも軽い、同じことから始めるウェブサービスとの比較apache占有するメモリとリソースが少ない l 反同時実行性、nginx リクエストの処理は非同期でノンブロッキングですが、 apache ブロック型です、高い同時実行性の下で nginx は低リソース消費と高いパフォーマンスを維持できます l 高度にモジュール化された設計で、モジュールの作成は比較的簡単です l 負荷分散を提供する l コミュニティが活発で、さまざまな高性能モジュールが迅速に作成されます l アパッチ の書き換え は nginx よりも強力で、基本的にすべてのアプリケーションをカバーします。 。 3) 両者の長所と短所の比較l Nginx 構成が簡単、Apache 複雑 ; lNginx 静的処理パフォーマンス ; シンプル、 Nginx を他のバックエンドで使用する必要があります l Apache には、 Nginx l apache は、1 つの接続が 1 つのプロセスに対応します。非同期、複数の接続 (10,000 レベル) 1 つのプロセスに対応できます; l nginxは静的ファイルの処理に優れています、の消費メモリは少ないです l 動的リクエストはapache、によって実行されます。 nginx 静的のみに適しています l Nginxはフロントエンドサーバーに適しており、優れた負荷パフォーマンスを備えています 3. まとめ l 利点: 負荷分散、リバースプロキシ、静的ファイル処理利点。 nginxは、apache l Apacheの利点: Tomcatサーバーと比較して、静的ファイルの処理が速いという利点があります。スピードも速い。 Apacheは静的解析であり、静的な HTML、画像などに適しています。 ltomcat:動的解析コンテナ、動的要求の処理は、jspservletをコンパイルするためのコンテナであり、nginxには動的な分離メカニズムがあり、静的要求は を直接渡すことができます。 Nginx 処理、動的リクエストは、Tomcat による処理のためにバックグラウンドに転送されます。 Apacheは処理ダイナミクスに優れており、 は同時実行性が優れており、 はメモリ使用量が低く、頻繁に すると、あるいは Apache の方が適しています。 22. ポート、プロセス 1. lsof lsof -i:ポート番号を使用して、ポートが占有されているかどうかを確認します<br/> 2. netstatを使用する <br/> $ top -u oracle<br/><br/>Linux プロセスの表示とプロセスの削除 1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab)。<br/>2. ps 命令用于查看当前正在运行的进程。<br/>grep 是搜索<br/>例如: ps -ef | grep java<br/>表示查看所有进程里 CMD 是 java 的进程信息<br/>ps -aux | grep java<br/>-aux 显示所有状态<br/>ps<br/>3. kill 命令用于终止进程<br/>例如: kill -9 [PID]<br/>-9 表示强迫进程立即停止<br/>通常用 ps 查看进程 PID ,用 kill 命令终止进程<br/>网上关于这两块的内容<br/> <br/> <br/> <br/> 优化手段主要有缓存、集群、异步等。 网站性能优化第一定律:优先考虑使用缓存。 1 2 <br/> <br/> <br/> 任何可以晚点做的事情都应该晚点再做。 摘自《大型网站技术架构》–李智慧 <br/> 手机网站支付主要应用于手机、掌上电脑等无线设备的网页上,通过网页跳转或浏览器自带的支付宝快捷支付实现买家付款的功能,资金即时到账。 1、您申请前必须拥有企业支付宝账号(不含个体工商户账号),且通过支付宝实名认证审核。<br/>2、如果您有已经建设完成的无线网站(非淘宝、天猫、诚信通网店),网站经营的商品或服务内容明确、完整(古玩、珠宝等奢侈品、投资类行业无法申请本产品)。<br/>3、网站必须已通过ICP备案,备案信息与签约商户信息一致。 假设我们已经成功申请到手机网站支付接口,在进行开发之前,需要使用公司账号登录支付宝开放平台。 1、开发者登录开放平台,点击右上角的“账户及密钥管理”。<br/> 2、选择“合作伙伴密钥”,即可查询到合作伙伴身份(PID),以2088开头的16位纯数字。<br/> 支付宝提供了DSA、RSA、MD5三种签名方式,本次开发中,我们使用RSA签名和加密,那就只配置RSA密钥就好了。 关于RSA加密的详解,参见《支付宝签名与验签》。 本节可以忽略,本节可以忽略,本节可以忽略!因为官方文档并没有提及应用环境配置的问题。 进入管理中心,对应用进行设置。<br/> return_url,支付完成后的回调url;notify_url,支付完成后通知的url。支付宝发送给两个url的参数是一样的,只不过一个是get,一个是post。 以上两种发起请求的方式中,return_url在Node端,notify_url在后端。我们也可以根据需要,把两个url都放在后端,或者都放在Node端,改变相应业务逻辑即可。 Node端发起支付请求有两种选择,一种是获取到后端给的参数后,通过request模块发起get请求,获取到支付宝返回的支付页面,然后显示到页面上;另一种是获取到后端给的参数后,把参数全部输出到页面中的form表单,然后通过js自动提交表单,获取到支付宝返回的支付页面(同时显示出来)。 理论上完全正确的请求,然而,获取到的支付页面,输出到页面上,却是乱码。没错,还是一个错误提示页面。<br/> 神奇的地方在于,在刷新页面多次后,正常了!!!啊嘞,这是什么鬼? 先解决乱码问题,看看报什么错! 很遗憾,无效!乱码依然是乱码。。。和沈晨帅哥讨论很久,最终决定换一种方案——利用表单提交。 开始时,打算把alidata直接输出到form表单的action中接口的后面,因为这样似乎最简便。但是,提交表单时,后面的参数全部被丢弃了。所以,不得不得把所有参数放在form表单中。Node端拆分了一下参数,组装成了一个alipayParam对象,这个工作也可以交给后端来做。 显然,request模拟表单提交和真实表单提交结果的不同,得出的结论是,request并不能完全模拟表单提交。或者,request可以模拟,而我不会-_-|||。 以上,大功告成?不!还有一个坑要填,因为微信屏蔽了支付宝!<br/>在电脑上,跳转支付宝支付页面正常,很完美!然而,在微信浏览器中测试时,却没有跳转,而是出现如下信息。<br/> 微信端支付宝支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html 该办法的核心在于:把微信屏蔽的链接,赋值给iframe的src属性。 然而,在改造时,先是报错ILLEGAL_SIGN,于是利用urlencode处理了字符串。接着,又报错ILLEGAL_EXTERFACE,没有找到解决办法。 暂时放弃,以后如果有了解决办法再补上。 关于微信公众平台无法使用支付宝收付款的解决方案说明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 该方法的核心在于:确认支付时,提示用户打开外部系统浏览器,在系统浏览器中支付。 该页面会自动跳转到同一文件夹下的pay.htm,该文件官方已经提供,把其中的引入ap.js的路径修改一下即可。最终效果如下:<br/> 支付宝的支付流程和微信的支付流程,有很多相似之处。沈晨指出一点不同:支付宝支付完成后有return_url和notify_url;微信支付完成后只有notify_url。 研读了一下微信支付的开发文档,确实如此。微信支付完成后的通知也分成两路,一路通知到notify_url,另一路返回给调用支付接口的JS,同时发微信消息提示。也就是说,跳转return_url的工作我们需要自己做。 最后,感谢沈晨帅哥提供的思路和帮助,感谢体超帅哥辛苦改后端。 Alipay オープン プラットフォーム<br/>https://openhome.alipay.com/platform/home.htm Alipay オープン プラットフォーム - モバイル ウェブサイト支払い - ドキュメント センター<br/>https://doc.open.alipay.com/doc2/ detail?treeId=60&articleId=103564&docType=1 Alipay WAP 支払いインターフェース開発<br/>http://blog.csdn.net/tspangle/article/details/39932963 wap h5 モバイル Web サイト支払いインターフェースは、Alipay ウォレット支払いを呼び起こします マーチャント サービス- Alipayは委託を知っています! <br/>https://b.alipay.com/order/techService.htm WeChat 決済開発ドキュメント<br/>https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=7_1 WeChat での Alipay 支払い、iframe の変換<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html WeChat での Alipay の封鎖を突破する方法<br/>http://blog.csdn.net/lee_sire/article /details /49530875 JavaScript トピック (2): iframe についての深い理解<br/>http://www.cnblogs.com/fangjins/archive/2012/08/19/2645631.html 不能の解決策についてAlipay を使用して WeChat パブリック プラットフォームで受け取りと支払いを行う ソリューションの説明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 <br/> 以下にいくつかの方法をまとめます: まず、サーバーのハードウェアがサポートするのに十分であるかどうかを確認します。現在の交通状況。通常の P4 サーバーは、通常、1 日あたり最大 100,000 の独立した IP をサポートできます。アクセス数がこれを超える場合は、まずより高性能の専用サーバーを構成する必要があります。そうしないと、どのように最適化しても問題は解決されません。パフォーマンスの問題を完全に解決することは不可能です。 2 番目に、データベース アクセスを最適化します。サーバーに過剰な負荷がかかる重要な理由は、CPU 負荷が高すぎることです。サーバー CPU の負荷を軽減することによってのみ、ボトルネックを効果的に解消できます。静的ページを使用すると、CPU への負荷を最小限に抑えることができます。もちろん、データベースにアクセスする必要がまったくないため、フロント デスクを完全に静的化することが最善ですが、頻繁に更新される Web サイトの場合、静的化では特定の機能を満たせないことがよくあります。キャッシュ テクノロジは、動的データをキャッシュ ファイルに保存するもう 1 つのソリューションです。WordPress と Z-Blog はどちらも、このキャッシュ テクノロジを広く使用しています。私は Z-Blog カウンタ プラグインも作成しましたが、これもこの原則に基づいています。データベースにアクセスすることがどうしても避けられない場合は、Select *from などのステートメントの使用を避け、短時間に大量の SQL クエリを実行することを回避します。期間。 第三に、外部ホットリンクは禁止されています。外部 Web サイトからの画像やファイルのホットリンクは、多くの場合負荷がかかるため、自分の画像やファイルの外部からのホットリンクは厳密に制限する必要があります。幸いなことに、ホットリンクは Apache 自体で設定できます。リンク、IIS には、同じ機能を実現できるサードパーティの ISAPI もいくつかあります。もちろん、偽の紹介を使用してコードを介してホットリンクを実現することもできますが、現時点では意図的に偽の紹介やホットリンクを行う人は多くありません。今のところ無視することも、ウォーターマークを追加するなどの非技術的な手段を使用して解決することもできます。写真に。 4 番目に、大きなファイルのダウンロードを制御します。大きなファイルをダウンロードすると大量のトラフィックが消費され、非 SCSI ハード ドライブの場合、大量のファイルをダウンロードすると CPU が消費され、Web サイトの応答性が低下します。したがって、2M を超える大きなファイルのダウンロードは提供しないようにしてください。提供する必要がある場合は、大きなファイルを別のサーバーに配置することをお勧めします。現在、画像共有やファイル共有機能を提供する無料の Web2.0 Web サイトが数多く存在するため、これらの共有 Web サイトに画像やファイルをアップロードしてみることができます。 5 番目に、メインのトラフィックを迂回するために別のホストを使用し、ファイルを別のホストに配置し、ユーザーがダウンロードできるように別のイメージを提供します。たとえば、RSS ファイルが大量のトラフィックを消費していると感じる場合は、FeedBurner や FeedSky などのサービスを使用して、RSS 出力を他のホストに配置します。この方法では、他のユーザーのアクセスによるトラフィック プレッシャーのほとんどが集中します。 FeedBurner のホストと RSS は、あまり多くのリソースを占有しません。 6番目、トラフィック分析および統計ソフトウェアを使用します。 Web サイトにトラフィック分析および統計ソフトウェアをインストールすると、どこで多くのトラフィックが消費されているか、どのページを最適化する必要があるかを瞬時に知ることができるため、トラフィック問題を解決するには正確な統計分析が必要です。私が推奨するトラフィック分析および統計ソフトウェアは Google Analytics です。使ってみてとても良い効果を感じました。Google Analyticsの使い方の常識やスキルについては後ほど詳しく紹介します。 1. テーブルの分割 2. 読み取りと書き込みの分離 3. フロントエンドの最適化。 Nginx は Apache に置き換わります (フロントエンドの負荷分散)。ただし、分散アーキテクチャが構築された後、PV が増加した後は、mysql とキャッシュの最適化が重要だと思います。 、ヒープ マシンのみを拡張できます。 最初に、select ステートメントを分析し、インデックスとテーブル構造を最適化するために Explain ステートメントを使用する方法を学びます。次に、mysql の負荷を軽減するために、Facebook の Hiphop を使用してみてください。 -php プログラムの効率を向上させるために PHP をコンパイルします。 <br/> NoSQLとリレーショナルデータベースの設計概念の比較 <br/> リレーショナル データベースのテーブルにはいくつかのものが格納されますフォーマットされたデータ構造。すべてのタプルがすべてのフィールドを必要とするわけではない場合でも、データベースはテーブルとテーブル間での接続やその他の操作を容易に実行できます。 、これはリレーショナル データベースのパフォーマンスのボトルネックの要因でもあります。非リレーショナル データベースはキーと値のペアを格納し、その構造は固定されていないため、各タプルは必要に応じて独自のキーと値のペアを追加できます。構造により、時間とスペースのオーバーヘッドをいくらか削減できます。 <br/><br/>特徴: <br/>非常に大量のデータを処理できます。 <br/>それらは安価な PC サーバーのクラスター上で実行されます。 <br/>パフォーマンスのボトルネックを解消します。 <br/>過度な操作は禁止です。 <br/>ブートストラップ サポート <br/><br/>短所: <br/>しかし、正式な公式サポートがなければ、何か問題が発生した場合に大変なことになる可能性があることを認める人もいます。少なくとも多くのマネージャーはそう考えています。 <br/>さらに、nosql は特定の標準を形成しておらず、さまざまな製品が次々に登場しており、内部混乱があり、さまざまなプロジェクトはまだテストする時間が必要です MySQL か NoSQL: どのように選択するかオープンソース時代のデータベース 要約: リレーショナル データベースである MySQL には、膨大な数の支持者がいます。非リレーショナル データベースである NoSQL は、データベース革命とみなされています。この 2 つは互いに戦う運命にあるように見えますが、どちらもオープンソース ファミリーに属していますが、開発者により良いサービスを提供するために協力し、調和して共存し、協力することができます。 選び方: 常に正しい古典的な答えは、やはり、特定の問題の具体的な分析です。 <br/> MySQL はサイズが小さく、高速で、低コストで、構造が安定しており、クエリが簡単です。しかし、柔軟性に欠けています。 NoSQL は高いパフォーマンス、高いスケーラビリティ、高い可用性を備えており、固定された構造に限定されず、時間とスペースのオーバーヘッドが削減されますが、データの整合性を確保することが困難です。どちらにも多数のユーザーとサポーターがおり、この 2 つを組み合わせることは間違いなく良い解決策です。著者の John Engates は、Rackspace ホスティング部門の CTO であり、オープン クラウドの支持者であり、詳細な分析を提供しています。 http://www.csdn.net/article/2014-03-05/2818637-open-source-data-grows-choosing-mysql-nosql 1 つお選びください?それとも両方欲しいですか? アプリケーションをリレーショナル データベースと NoSQL (おそらく両方) のどちらと連携させる必要があるかは、生成または取得されるデータの性質によって異なります。テクノロジー業界のほとんどの事柄と同様、意思決定を行う際にはトレードオフが存在します。 24 時間のデータ整合性よりもスケールとパフォーマンスが重要な場合は、NoSQL が理想的な選択肢です (NoSQL は BASE モデルに依存しています - 基本的に利用可能、ソフトな状態、結果整合性)。 しかし、特に機密情報や財務情報に関して「常に一貫性」を確保したい場合は、MySQL がおそらく最良の選択です (MySQL は ACID モデル (原子性、一貫性、独立性、耐久性) に依存しています)。 オープンソース データベースとして、リレーショナル データベースと非リレーショナル データベースの両方が常に成熟しており、ACID モデルと BASE モデルに基づいた多数の新しいアプリケーションが登場すると予想されます。 2009 年に「リレーショナル データベースは死んだ」という比較的過激な記事が掲載されましたが、リレーショナル データベースは実際にはまだ健在であり、依然としてリレーショナル データベースを使用する必要があることを私たちは皆心の中で知っています。しかし、これは、WEB2.0 データを処理するときに実際にリレーショナル データベースにボトルネックが発生しているという事実も示しています。 それでは、NoSQL またはリレーショナル データベースを使用する必要がありますか?絶対的な答えを与える必要はないと思います。アプリケーションのシナリオに基づいて何を使用するかを決定する必要があります。 リレーショナル データベースがアプリケーション シナリオで非常にうまく機能し、リレーショナル データベースの使用と保守が非常に得意であれば、面倒なことを好む人でない限り、NoSQL に移行する必要はないと思います。周りの人々。金融や電気通信など、データが重要な分野に携わっている場合は、特に大きなボトルネックに遭遇しない限り、現在 Oracle データベースを使用して NoSQL を試してはいけません。 B、Web2.0 Web サイトでは、ほとんどの関係データベースにボトルネックがあります。開発者は、データベース シャーディング、マスター/スレーブ レプリケーション、異種レプリケーションなど、ディスク IO とデータベースのスケーラビリティを最適化するために多大な労力を費やしています。ただし、これらのタスクにはより高度で困難な作業が必要になります。このような状況に直面している場合は、NoSQL を試してみるべきだと思います。 <br/>27. 構造化データ (つまり、データベースに保存されている行データ、実装されたデータは 2 次元のテーブル構造を使用して論理的に表現できます) 非構造化データ (オフィス文書、テキスト、画像、 XML、HTML、各種レポート、画像や音声・動画情報など いわゆる半構造化データは、完全構造化データ(リレーショナルデータベースやオブジェクト指向データベースのデータなど)と完全に非構造化データの間にあります。データ(音声、画像ファイルなど)やHTML文書間のデータは半構造化データです。一般に自己記述型であり、データの構造と内容が明確な区別なく混在しています。 非構造化データ: なし <br/><br/> RMDBSのデータモデルには、ネットワークデータモデル、階層データなどがあります。モデル、リレーショナル 構造化データ: 最初に構造、次にデータ <br/> 半構造化データ: 最初にデータ、次に構造 ネットワーク技術の発展、特にインターネットとイントラネット技術の急速な発展により、非構造化データの量は日々増加しています。日。この時点で、主に構造化データの管理に使用されるリレーショナル データベースの限界がますます明らかになりました。したがって、データベース技術はそれに応じて「ポストリレーショナルデータベース時代」に入り、ネットワークアプリケーションに基づく非構造化データベースの時代に発展しました。 私の国の非構造化データベースは、Beijing Guoxin Base (iBase) Software Co., Ltd. の IBase データベースによって代表されます。 IBase データベースは、非構造化情報、全文情報、マルチメディア情報、大量情報の処理分野およびインターネット/イントラネット アプリケーションの分野において、国際的に先進的なレベルにあるエンドユーザー向けの非構造化データベースです。非構造化データの管理における画期的なレベル。主に以下のような利点があります: (1) インターネットアプリケーションでは、多数の複雑なデータ型が存在し、iBase は外部ファイルデータ型を通じてさまざまな文書情報やマルチメディア情報を管理できます。 HTML、DOC、RTF、TXT などの文書情報リソースも、強力な全文検索機能を提供します。 (2) サブフィールド、複数値フィールド、可変長フィールドのメカニズムを使用し、さまざまなタイプの非構造化フィールドまたは任意の形式のフィールドの作成を可能にし、それによってリレーショナル データベースの非常に厳密なテーブル構造を突破し、非構造化フィールドを作成します。データを保存して管理することができます。 (3)iBaseは非構造化データと構造化データの両方をリソースとして定義するため、非構造化データベースの基本要素はリソースそのものであり、データベース内のリソースには構造化情報と非構造化情報の両方を含めることができます。したがって、非構造化データベースはさまざまな非構造化データを保存および管理でき、データベース システムのデータ管理からコンテンツ管理への変革を実現します。 (4) iBase は、企業のビジネス データとビジネス ロジックを緊密に統合するためにオブジェクト指向の基礎を採用しており、複雑なデータ オブジェクトやマルチメディア オブジェクトの表現に特に適しています。 (5)iBase は、インターネットの発展のニーズを満たすために作成されたデータベースであり、Web は広域ネットワークの大規模なデータベースであるという考えに基づいており、オンライン リソース管理システム iBase Web を提供します。ネットワーク サーバー (WebServer) とデータベース サーバー (Database Server) を組み合わせたもので、全体として直接統合され、データベース システムとデータベース テクノロジが Web の重要かつ不可欠な部分となり、データベースのみが機能するという制限が打ち破られます。 Web システムのバックエンドの役割として、データベースと Web の有機的でシームレスな組み合わせを実現し、インターネット/イントラネットの情報管理、さらには電子商取引アプリケーションの基盤を提供し、より幅広い分野を切り開きました。 (6) iBase は、大中小規模のさまざまなデータベースと完全な互換性があり、Oracle、Sybase、SQLServer、DB2、Informix などの従来のリレーショナル データベースのインポートとリンクのサポートを提供します。 上記の分析を通じて、ネットワーク技術とネットワークアプリケーション技術の急速な発展に伴い、階層型データベース、ネットワークデータベース、リレーショナルデータベース、ホットテクノロジーに続いて、完全にインターネットアプリケーションに基づいた非構造化データベースが新たな焦点になると予測できます。 情報システムを設計する際には、通常、システム情報を指定されたリレーショナルデータベースに保存することが必ず発生します。データを業務別に分類し、対応するテーブルを設計し、対応する情報を対応するテーブルに保存します。たとえば、ビジネス システムを構築し、役職番号、名前、性別、生年月日などの基本的な従業員情報を保存する必要がある場合は、対応するスタッフ テーブルを作成します。 しかし、テーブル内のフィールドを使用するだけでは、システム内のすべての情報に対応できるわけではありません。 上の例と同じです。このタイプのデータは、対応するテーブルを作成するだけで最もよく処理されます。 写真、音声、ビデオなど。通常、この種の情報の内容を直接知ることはできず、データベースでは BLOB フィールドに保存することしかできないため、将来の検索が非常に困難になります。一般的なアプローチは、3 つのフィールド (数値、コンテンツの説明 varchar(1024)、コンテンツ BLOB) を含むテーブルを作成することです。引用は番号によって行われ、検索は内容の説明によって行われます。非構造化データを処理するためのツールは数多くあり、市販されている一般的なコンテンツ マネージャーもその 1 つです。 この種のデータは上記の2つのカテゴリとは異なり、構造が大きく変わります。データの詳細を把握する必要があるため、単純にファイルにまとめて非構造化データとして扱うことはできず、構造が大きく変化するため、単純にそれに対応するテーブルを作成することはできません。この記事では主に、半構造化データの保存によく使用される 2 つの方法について説明します。 先举一个半结构化的数据的例子,比如存储员工的简历。不像员工基本信息那样一致每个员工的简历大不相同。有的员工的简历很简单,比如只包括教育情况;有的员工的简历却很复杂,比如包括工作情况、婚姻情况、出入境情况、户口迁移情况、党籍情况、技术技能等等。还有可能有一些我们没有预料的信息。通常我们要完整的保存这些信息并不是很容易的,因为我们不会希望系统中的表的结构在系统的运行期间进行变更。 这种方法通常是对现有的简历中的信息进行粗略的统计整理,总结出简历中信息所有的类别同时考虑系统真正关心的信息。对每一类别建立一个子表,比如上例中我们可以建立教育情况子表、工作情况子表、党籍情况子表等等,并在主表中加入一个备注字段,将其它系统不关心的信息和已开始没有考虑到的信息保存在备注中。 优点:查询统计比较方便。 缺点:不能适应数据的扩展,不能对扩展的信息进行检索,对项目设计阶段没有考虑到的同时又是系统关心的信息的存储不能很好的处理。 XML可能是最适合存储半结构化的数据了。将不同类别的信息保存在XML的不同的节点中就可以了。 优点:能够灵活的进行扩展,信息进行扩展式只要更改对应的DTD或者XSD就可以了。 缺点:查询效率比较低,要借助XPATH来完成查询统计,随着数据库对XML的支持的提升性能问题有望能够很好的解决。 <br/> 单链表<br/><br/> 1、链接存储方法<br/> 链接方式存储的线性表简称为链表(Linked List)。<br/> 链表的具体存储表示为:<br/> ① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)<br/> ② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))<br/> 注意:<br/> 链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。<br/> <br/> 2、链表的结点结构<br/> ┌──┬──┐<br/> │data│next│<br/> └──┴──┘ <br/> data域--存放结点值的数据域<br/> next域--存放结点的直接后继的地址(位置)的指针域(链域)<br/>注意:<br/> ①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。<br/> ②每个结点只有一个链域的链表称为单链表(Single Linked List)。<br/> 【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图<br/><br/> 单链表的反转是常见的面试题目。本文总结了2种方法。 单链表node的数据结构定义如下: 把当前链表的下一个节点pCur插入到头结点dummy的下一个节点中,就地反转。 dummy->1->2->3->4->5的就地反转过程: pCur是需要反转的节点。 prev连接下一次需要反转的节点 反转节点pCur 纠正头结点dummy的指向 pCur指向下一次要反转的节点 伪代码 1个头结点,2个指针,4行代码 注意初始状态和结束状态,体会中间的图解过程。 新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。 pCur是要插入到新链表的节点。 pNex是临时保存的pCur的next。 pNex保存下一次要插入的节点 把pCur插入到dummy中 纠正头结点dummy的指向 pCur指向下一次要插入的节点 伪代码 <br/> MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。索引是在存储引擎中实现的,所以每种存储引擎中的索引都不一样。如MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。 这里仅针对常用的InnoDB存储引擎所支持的BTree索引进行介绍: 先创建一个新表,用于演示索引类型 这是最基本的索引,没有任何限制。 索引列的值必须唯一,可以有空值 是一种特殊的唯一索引,必须指定为 PRIMARY KEY,如我们常用的AUTO_INCREMENT自增主键 也称为组合索引,就是在多个字段上联合建立一个索引 这里一个组合索引,相当于在有如下三个索引: name; name,age; name,age,phoneNum; 这里或许有这样一个疑惑:为什么age或者age,phoneNum字段上没有索引。这是由于BTree索引因要遵守最左前缀原则,这个原则在后面详细展开。 创建索引简单,但是在哪些列上创建索引则需要好好思考。可以考虑在where字句中出现列或者join字句中出现的列上建索引 联合索引(name,age,phoneNum) ,B+树是按照从左到右的顺序来建立搜索树的。如('张三',18,'18668247652')来检索数据的时候,B+树会优先匹配name来确定搜索方向,name匹配成功再依次匹配age、phoneNum,最后检索到最终的数据。也就是说这种情况下是有三级索引,当name相同,查找age,age也相同时,去比较phoneNum;但是如果拿 (18,'18668247652')来检索时,B+树没有拿到一级索引,根本就无法确定下一步的搜索方向。('张三','18668247652')这种场景也是一样,当name匹配成功后,没有age这个二级索引,只能在name相同的情况下,去遍历所有的phoneNum。 B+树的数据结构决定了在使用索引的时候必须遵守最左前缀原则,在创建联合索引的时候,尽量将经常参与查询的字段放在联合索引的最左边。 一般情况下不建议使用like操作,如果非使用不可的话,需要注意:like '%abd%'不会使用索引,而like ‘aaa%’可以使用索引。这也是前面的最左前缀原则的一个使用场景。 mysql会按照联合索引从左往右进行匹配,直到遇到范围查询,如:>,<,between,like等就停止匹配,a = 1 and b =2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d是不会使用索引的。但如果联合索引是(a,b,d,c)的话,则a b d c都可以使用到索引,只是最终c是一个范围值。 order by排序有两种排序方式:using filesort使用算法在内存中排序以及使用mysql的索引进行排序;我们在部分不情况下希望的是使用索引。 如果ID是单列索引,则order by会使用索引 ID が単一列インデックスで、名前がインデックスではない場合、または名前も単一列インデックスである場合、order by はインデックスを使用しません。 Mysql クエリでは多数のインデックスから 1 つのインデックスのみが選択され、このクエリでは名前列インデックスではなく ID 列インデックスが使用されるためです。 このシナリオで、order by でインデックスも使用したい場合は、結合インデックス (id、name) を作成します。ここでは、左端のプレフィックスの原則に注意する必要があり、そのような結合インデックス (name、id) は作成しないでください。 )。 最後に、MySQL にはソートされたレコードのサイズに制限があることに注意してください。max_length_for_sort_data のデフォルトは 1024 です。つまり、ソートされるデータの量が 1024 を超える場合、order by はインデックスを使用しません。ただし、ファイルソートを使用します。 <br/> <br/> 現在、分散型大規模ウェブサイトにはいくつかのカテゴリがあります: 1. NetEase、Sina などの大規模ポータル2. Xiaonei、Kaixin.com などの SNS ウェブサイト 3. Alibaba、JD.com、Gome Online、Autohome などの電子商取引ウェブサイト 客户需求: 建立一个全品类的电子商务网站(B2C),用户可以在线购买商品,可以在线支付,也可以货到付款; 用户购买时可以在线与客服沟通; 用户收到商品后,可以给商品打分,评价; 目前有成熟的进销存系统;需要与网站对接; 希望能够支持3~5年,业务的发展; 预计3~5年用户数达到1000万; 定期举办双11,双12,三八男人节等活动; 其他的功能参考京东或国美在线等网站。 客户就是客户,不会告诉你具体要什么,只会告诉你他想要什么,我们很多时候要引导,挖掘客户的需求。好在提供了明确的参考网站。因此,下一步要进行大量的分析,结合行业,以及参考网站,给客户提供方案。 需求管理传统的做法,会使用用例图或模块图(需求列表)进行需求的描述。这样做常常忽视掉一个很重要的需求(非功能需求),因此 本电商网站的需求矩阵如下: 以上是对电商网站需求的简单举例,目的是说明(1)需求分析的时候,要全面,大型分布式系统重点考虑非功能需求;(2)描述一个简单的电商需求场景,使大家对下一步的分析设计有个依据。 一般网站,刚开始的做法,是三台服务器,一台部署应用,一台部署数据库,一台部署NFS文件系统。这是前几年比较传统的做法,之前见到一个网站10万多会员,垂直服装设计门户,N多图片。使用了一台服务器部署了应用,数据库以及图片存储。出现了很多性能问题。如下图: 但是,目前主流的网站架构已经发生了翻天覆地的变化。 3〜5年でユーザー数が1,000万人に達すると予想されます ピークの推定値: 通常の 2 ~ 3 倍。 同時実行性 (同時実行数、トランザクション数) とストレージ容量に基づいてシステム容量を計算します。 ユーザーの数は 3 で 1,000 に達します。 5 年間 10,000 人の登録ユーザー 1 秒あたりの推定同時実行数: 以上预估仅供参考,因为服务器配置,业务逻辑复杂度等都有影响。在此CPU,硬盘,网络等不再进行评估。 根据以上预估,有几个问题: 需要部署大量的服务器,高峰期计算,可能要部署30台Web服务器。并且这三十台服务器,只有秒杀,活动时才会用到,存在大量的浪费。 所有的应用部署在同一台服务器,应用之间耦合严重。需要进行垂直切分和水平切分。 大量应用存在冗余代码。 服务器SESSION同步耗费大量内存和网络带宽。 数据需要频繁访问数据库,数据库访问压力巨大。 大型网站一般需要做以下架构优化(优化是架构设计时,就要考虑的,一般从架构/代码级别解决,调优主要是简单参数的调整,比如JVM调优;如果调优涉及大量代码改造,就不是调优了,属于重构): 业务拆分 应用集群部署(分布式部署,集群部署和负载均衡) 多级缓存 单点登录(分布式Session) 数据库集群(读写分离,分库分表) 服务化 消息队列 其他技术 拆分后的架构图: 参考部署方案2: (1)如上图每个应用单独部署; (2)核心系统和非核心系统组合部署; キャッシュは、一般に、保存場所 缓存的比例,一般1:4,即可考虑使用缓存。(理论上是1:2即可)。 根据业务特性可使用以下缓存过期策略: (1)缓存自动过期; (2)缓存触发过期; 系统分割为多个子系统,独立部署后,不可避免的会遇到会话管理的问题。 再进一步可以根据分布式Session,建立完善的单点登录或账户管理系统。 流程说明: (1)用户第一次登录时,将会话信息(用户Id和用户信息),比如以用户Id为Key,写入分布式Session; (2)用户再次登录时,获取分布式Session,是否有会话信息,如果没有则调到登录页; (3)一般采用Cache中间件实现,建议使用Redis,因此它有持久化功能,方便分布式Session宕机后,可以从持久化存储中加载会话信息; (4)存入会话时,可以设置会话保持的时间,比如15分钟,超过后自动超时; 结合Cache中间件,实现的分布式Session,可以很好的模拟Session会话。 大型网站需要存储海量的数据,为达到海量数据存储, 本案例在业务拆分的基础上,结合分库分表和读写分离。如下图: (1)业务拆分后:每个子系统需要单独的库; (2)如果单独的库太大,可以根据业务特性,进行再次分库,比如商品分类库,产品库; (3)分库后,如果表中有数据量很大的,则进行分表,一般可以按照Id,时间等进行分表;(高级的用法是一致性Hash) (4)在分库,分表的基础上,进行读写分离; 相关中间件可参考Cobar(阿里,目前已不在维护),TDDL(阿里),Atlas(奇虎360),MyCat(在Cobar基础上,国内很多牛人,号称国内第一开源项目)。 分库分表后序列的问题,JOIN,事务的问题,会在分库分表主题分享中,介绍。 キャッシュ比率は通常 1:4 なので、キャッシュの使用を検討できます。 (理論的には 1:2 で十分です)。 ビジネスの特性に応じて次のキャッシュ有効期限戦略を使用できます: (1) 自動キャッシュ有効期限 目前使用较多的MQ有Active MQ,Rabbit MQ,Zero MQ,MS MQ等,需要根据具体的业务场景进行选择。 除了以上介绍的业务拆分, 此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。 <br/> RESTful是"分布式超媒体应用"的架构风格<br/>1.采用URI标识资源;<br/><br/>2.使用“链接”关联相关的资源;<br/><br/>3.使用统一的接口;<br/><br/>4.使用标准的HTTP方法;<br/><br/>5.支持多种资源表示方式;<br/><br/> 6.无状态性; <br/> <br/> windows 最近要熟悉一下网站优化,包括前端优化,后端优化,涉及到的细节Opcode,Xdebuge等,都会浅浅的了解一下。 像类似于,刷刷CSDN博客的人气啦,完全是得心应手啊。 我测试了博客园,使用ab并不能刷访问量,为什么CSDN可以,因为两者统计的方式不同。 1 2 3 4 5 6 PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。这也就是ab可以刷csdn访问的原因了。 UV是指不同的、通过互联网访问、浏览一个网页的自然人。类似于注册用户,保存session的形式 IP就不用说啦。类似于博客园,使用的统计方式就必须是IP啦 ab是Apache的自带的工具,如果是window安装的,找到Apache的bin目录,在系统全局变量中添加Path,然后就可以使用ab了 1 2 3 4 5 6 1 2 3 1 2 3 本文介绍ab测试,并没有恶意使用它。途中的博客地址,也只是测试过程中借用了一下,没有别的恶意。 原创 2015年10月19日 18:24:31 <br/> 安装ab工具 ubuntu安装ab apt-get install apache2-utils centos安装ab yum install httpd-tools ab 测试命令 ab -kc 1000-n 1000 http://localhost/ab.html(是服务器下的页面) <br/> ySQL のログには、エラーログ、バイナリログ、一般クエリログ、スロークエリログなどが含まれます。ここでは主に一般クエリログとスロークエリログというよく使われる2つの機能を紹介します。 1) 一般クエリログ: 確立されたクライアント接続と実行されたステートメントを記録します。 2) スロークエリログ: 実行時間がlong_query_time秒を超えたクエリ、またはインデックスを使用しないクエリをすべて記録します (1) 一般的なクエリログ デフォルトでは閉じられています )。 質問: MySQL の一般的なクエリ ログを有効にする方法、および出力される一般的なログの出力形式を設定する方法を教えてください。 一般的なログ クエリを有効にする: set global general_log=on; 一般的なログ クエリをオフにする: set globalgeneral_log=off; テーブル モードで一般的なログ出力を設定する: set globallog_output='TABLE'; 一般的なログ出力をファイル モードに設定します: set globallog_output='FILE'; 注: 上記のコマンドは現在有効であり、MySQLを再起動すると失敗します。永続的に有効にしたい場合は、my.cnfを設定する必要があります) my.cnf ファイルの構成は次のとおりです (2) スロークエリログ 質問: スロークエリログの現在のステータスを確認するにはどうすればよいですか? (2) throw_query_log_file (3) long_query_time (4) log_queries_not_using_indexes 値が ON に設定されている場合、インデックスを利用しないすべてのクエリが記録されます (注: log_queries_not_using_indexes を ON に設定し、slow_query_log を OFF に設定しただけの場合、この設定はこの時点では有効になりません)つまり、この設定が有効になるには、slow_query_log の値が ON に設定されている必要があります。これは通常、パフォーマンス チューニング中に一時的にオンになります。 質問: MySQL スロークエリの出力ログ形式をファイルまたはテーブル、あるいはその両方に設定しますか? コマンドを使用します: ‘%log_output%’ のような変数を表示します。 log_output の値を通じて出力形式を確認できます。上記の値は TABLE です。もちろん、出力形式をテキストに設定したり、テキストとデータベーステーブルを同時に記録したりすることもできます。設定コマンドは次のとおりです: #スロークエリログをテーブルに出力します (つまり、mysql.slow_log) 。 set globallog_output='TABLE' ; #スロークエリログはテキスト(つまり、slow_query_log_fileで指定されたファイル)にのみ出力されます setglobal log_output='FILE'; #スロークエリログは両方に出力されますテキストとテーブル setglobal log_output='FILE, TABLE'; スロークエリログテーブルのデータテキストのデータ形式分析について: myql.slow_logテーブルのスロークエリログレコード、形式は次のとおりです: スロークエリログ hostname.log ファイルに記録されます。形式は次のとおりです: テーブルであるかファイルであるかがわかります。具体的には、どのステートメントが低速クエリの原因となったか (sql_text)、低速クエリ ステートメントのクエリ時間 (query_time)、テーブル ロック時間 (Lock_time)、スキャンされた行数 (rows_examined) およびその他の情報が記録されます。 質問: 現在の低速クエリ ステートメントの数をクエリするにはどうすればよいですか? MySQL には、現在の遅いクエリ ステートメントの数を具体的に記録する変数があります: コマンドを入力してください: show global status like '%slow%'; (注: 上記すべて)コマンド、MySQL シェルを通じてパラメータが設定されている場合、MySQL が再起動されると、設定されたパラメータはすべて無効になります。それらを永続的に有効にしたい場合は、設定パラメータを my.cnf ファイルに書き込む必要があります。 補足知識ポイント: MySQL 独自のスロークエリログ分析ツール mysqldumpslow を使用してログを分析する方法? perlmysqldumpslow –s c –t 10 throw-query.log 具体的なパラメータ設定は次のとおりです: -s は並べ替え方法を示し、c、t、l、r はレコード数、時間に基づきます、およびクエリ時間はそれぞれ返されたレコードの数で並べ替えられ、 ac、at、al、ar は対応するフラッシュバックを表し、次のデータは返された前のレコードの数を表します。 -g の後には、大文字と小文字を区別せずに一致する正規表現を続けることができます。 Count:414 ステートメントは 414 回出現します。 Time=3.51s (1454) 最大実行時間は 3.51 秒、合計累積時間は 1454 秒です。 Lock =0.0s (0) ロックの最大待機時間は 0 秒、ロックの累積待機時間は 0 秒です。 Rows=2194.9 (9097604) クライアントに送信される最大行数は 2194.9 です。クライアントに送信された関数の累積数は 90976404 です http://blog.csdn.net/a600423444/article/details/6854289 ( mysqldumpslow スクリプトは Perl 言語で書かれており、具体的な使用法はmysqldumpslow については後で説明します) 実際に学習プロセス中に、設定された低速クエリが効果的であることはどのようにしてわかりますか? これは非常に簡単です。たとえば、スロー クエリ log_query_time の値が 1 に設定されている場合、次のステートメントを実行できます: selectsleep(1); このステートメントは次のとおりです。遅い ステートメントをクエリした後、対応するログ出力ファイルまたはテーブルにステートメントが存在するかどうかを確認できます。 <br/> ThinkPHP简称TP,TP借鉴了Java思想,基于PHP5,充分利用了PHP5的特性,部署简单只需要一个入口文件,一起搞定,简单高效。中文文档齐全,入门超级简单。自带模板引擎,具有独特的数据验证和自动填充功能,框架更新速度比较速度。 优点:这个框架易使用 易学 安全 对bae sae支持很好提供的工具也很强大 可以支持比较大的项目开发 易扩展 全中文文档 总的来说这款框架适合非常适合国人使用 性能 上比CI还要强一些 缺点:配置对有些人来说有些复杂(其实是因为没有认真的读过其框架源码)文档有些滞后 有些组件未有文档说明。 CodeIgniter简称CI 简单配置,上手很快,全部的配置使用PHP脚本来配置,没有使用很多太复杂的设计模式,(MVC设计模式)执行性能和代码可读性上都不错。执行效率较高,具有基本的MVC功能,快速简洁,代码量少,框架容易上手,自带了很多简单好用的library。 框架适合中小型项目,大型项目也可以,只是扩展能力差。优点:这个框架的入门槛很底 极易学 极易用 框架很小 静态化非常容易 框架易扩展 文档比较详尽 缺点:在极易用的极小下隐藏的缺点即是不安全 功能不是太全 缺少非常多的东西 比如你想使用MongoDB你就得自己实现接口… 对数据的操作亦不是太安全 比如对update和delete操作等不够安全 暂不支持sae bae等(毕竟是欧洲)对大型项目的支持不行 小型项目会非常好。 CI和TP的对比(http://www.jcodecraeer.com/a/phpjiaocheng/2012/0711/309.html) Laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD和BDD(http://blog.csdn.net/bennes/article/details/47973129 TDD DDD BDD解释 ),作为一个框架,它为你准备好了一切,composer是个php的未来,没有composer,PHP肯定要走向没落。laravel最大的特点和处优秀之就是集合了php比较新的特性,以及各种各样的设计模式,Ioc容器,依赖注入等。因此laravel是一个适合学习的框架,他和其他的框架思想有着极大的不同,这也要求你非常熟练php,基础扎实。 优点:http://www.codeceo.com/article/why-laravel-best-php-framework.html Yii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主体化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。而且这个框架的价格也并不太高。事实上,Yii是最有效率的PHP框架之一。 <br/> 原创 2016年11月09日 17:58:50 <br/> 在PHP中,出现同名函数或是同名类是不被允许的。为防止编程人员在项目中定义的类名或函数名出现重复冲突,在PHP5.3中引入了命名空间这一概念。 1.命名空间,即将代码划分成不同空间,不同空间的类名相互独立,互不冲突。一个php文件中可以存在多个命名空间,第一个命名空间前不能有任何代码。内容空间声明后的代码便属于这个命名空间,例如: 2.调用不同空间内类或方法需写明命名空间。例如: 3.在命名空间内引入其他文件不会属于本命名空间,而属于公共空间或是文件中本身定义的命名空间。例: 首先定义一个1.php和2.php文件: 4.下面我们来看use的使用方法:(use以后引用可简写) 相关推荐: 以上がPHPインタビューのまとめの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。2.author 2.0認証方式
OAuthは、世界中で広く使用されている認証のオープンネットワーク標準です。現在のバージョンはバージョン2.0です。 この記事では、OAuth 2.0 の設計思想と運用プロセスについて簡潔で一般的な説明を提供します。主な参考資料は RFC 6749 です。 

(1) 「クラウド印刷」は、後続のサービスのためにユーザーのパスワードを保存するため、非常に安全ではありません。 (2) Google はパスワード ログインを導入する必要がありますが、単純なパスワード ログインが安全ではないことはわかっています。 (3) 「クラウド印刷」は、Google に保存されているユーザーのすべてのデータを取得する権利を有し、ユーザーは「クラウド印刷」権限の範囲と有効期間を制限することはできません。 (4) ユーザーは、パスワードを変更することによってのみ、「クラウド印刷」に付与された権限を取り戻すことができます。ただし、これを行うと、ユーザーが許可した他のすべてのサードパーティ アプリケーションが無効になります。 (5) サードパーティ製アプリケーションがクラックされる限り、ユーザーのパスワードが漏洩し、パスワードで保護されたすべてのデータが漏洩する可能性があります。
OAuth は上記の問題を解決するために生まれました。 2. 名詞の定義 OAuth 2.0 について詳しく説明する前に、いくつかの特殊名詞を理解する必要があります。これらは、以下の説明、特にいくつかの図を理解するために非常に重要です。 (1)
上記の用語を理解すると、OAuth の機能は、「クライアント」が安全かつ制御可能に「ユーザー」の承認を取得し、「サービス プロバイダー」と対話できるようにすることであることを理解するのは難しくありません。 3. OAuthの考え方OAuthは、「クライアント」と「サービスプロバイダー」の間に認証層を設定します。 「クライアント」は「サービスプロバイダー」に直接ログインすることはできませんが、ユーザーとクライアントを区別するために認可層にのみログインできます。 「クライアント」が認可レイヤーにログインするために使用するトークンは、ユーザーのパスワードとは異なります。ユーザーはログイン時に認可レイヤートークンの権限範囲と有効期間を指定できます。 「クライアント」が認可レイヤーにログインすると、「サービスプロバイダー」は、トークンの許可範囲と有効期間に基づいて、ユーザーの保存情報を「クライアント」に公開します。 4. 動作プロセス OAuth 2.0の動作プロセスは以下の通りです(RFC 6749より抜粋)。 
(A) ユーザーがクライアントを開いた後、クライアントはユーザーに承認を要求します。 (B) ユーザーはクライアントに権限を付与することに同意します。 (C) クライアントは、前のステップで取得した認可を使用して、認証サーバーにトークンを申請します。 (D) クライアントを認証した後、認証サーバーはそれが正しいことを確認し、トークンの発行に同意します。 (E) クライアントはトークンを使用してリソースサーバーに適用し、リソースを取得します。
五、客户端的授权模式
六、授权码模式

GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }七、简化模式

GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600
八、密码模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=password&username=johndoe&password=A3ddj3w
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }九、客户端模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=client_credentials
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "example_parameter":"example_value" }十、更新令牌
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA3. yii 配置文件
 <br/>
<br/>
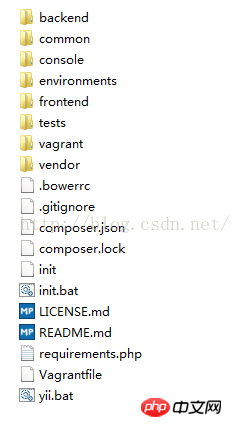 <br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>
<br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/> <br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend
<br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend <br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/><?phpdefined('YII_DEBUG') or define('YII_DEBUG', true);
defined('YII_ENV') or define('YII_ENV', 'dev');
require(__DIR__ . '/../../vendor/autoload.php');
require(__DIR__ . '/../../vendor/yiisoft/yii2/Yii.php');
require(__DIR__ . '/../../common/config/bootstrap.php');
require(__DIR__ . '/../config/bootstrap.php');
$config = yii\helpers\ArrayHelper::merge(
require(__DIR__ . '/../../common/config/main.php'),
require(__DIR__ . '/../../common/config/main-local.php'),
require(__DIR__ . '/../config/main.php'),
require(__DIR__ . '/../config/main-local.php'));
$application = new yii\web\Application($config);$application->run();
 <br/><br/><br/>以下はグローバル パブリック フォルダー 4.common
<br/><br/><br/>以下はグローバル パブリック フォルダー 4.common <br/>
<br/>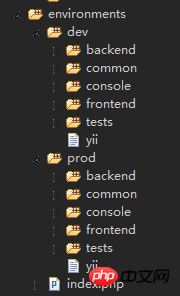 <br/> 上記のディレクトリ構造図から、環境ディレクトリの下に 3 つのものが存在することがわかります:
<br/> 上記のディレクトリ構造図から、環境ディレクトリの下に 3 つのものが存在することがわかります:  vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant
vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant  8.tests
8.tests  <br/>
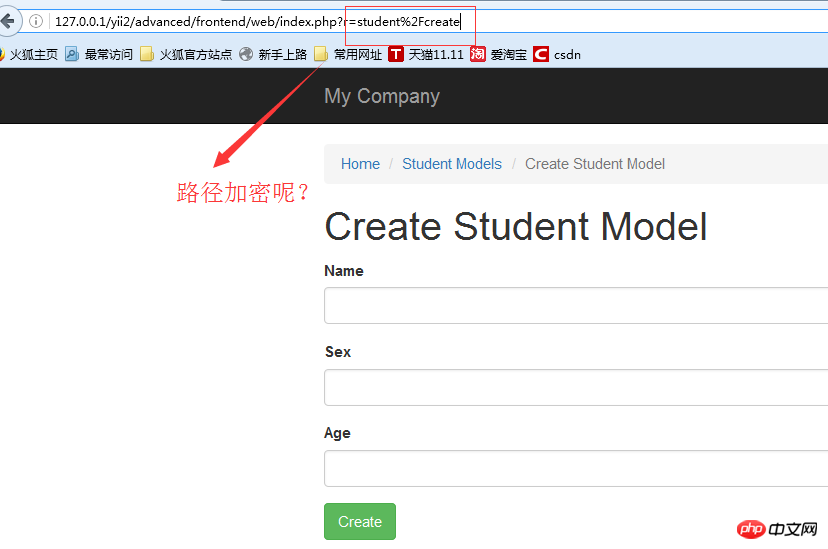
<br/>入口文件篇:
 <br/>
<br/> return "$baseUrl/{$route}{$anchor}"; } else { $url = "$baseUrl?{$this->routeParam}=" . urlencode($route); if (!empty($params) && ($query = http_build_query($params)) !== '') { $url .= '&' . $query; } 将urlencode去掉就可以了 3、入口文件内容 入口文件流程如下: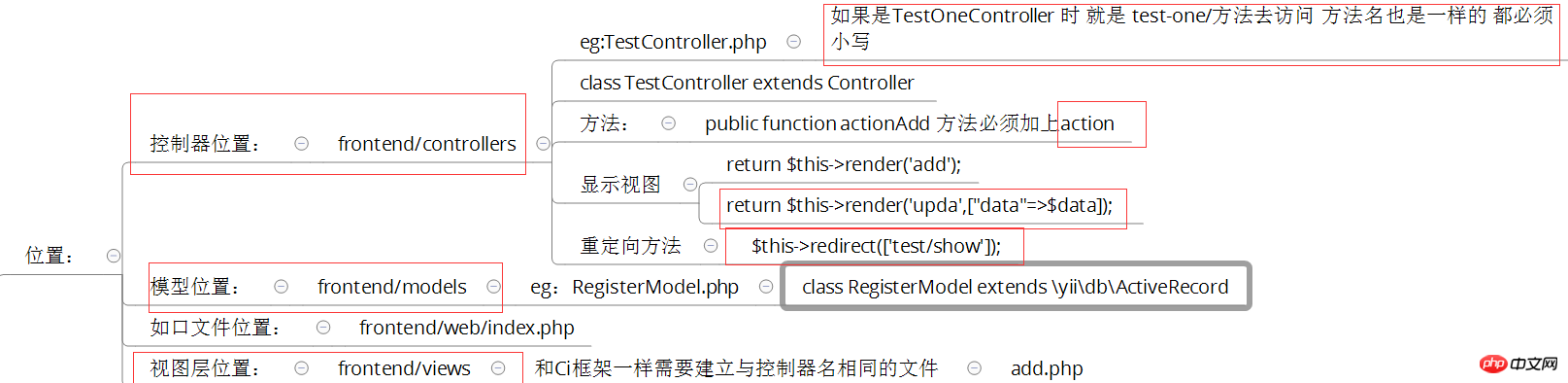 <br/>
<br/>public $defaultRoute = 'student/show';
修改前台或者后台控制器: eg :打开 frontend/config/main.php 中
'params' => $params, 'defaultRoute' => 'login/show',
namespace frontend\controllers;
use Yii;
use yii\web\Controller;
vendor/yiisoft/yii2/web/Controller.php
(该控制器继承的是\yii\base\Controller) \web\Controller.php中干了些什么
1、默认开启了 授权防止csrf攻击
2、响应Ajax请求的视图渲染
3、将参数绑定到动作(就是看是不是属于框架自己定义的方法,如果没有定义就走run方法解析)
4、检测方法(beforeAction)beforeAction() 方法会触发一个 beforeAction 事件,在事件中你可以追加事件处理操作;
5、重定向路径 以及一些http Response(响应) 的设置
<br/>
use yii\db\Query; //使用query查询
use yii\data\Pagination;//分页
use yii\data\ActiveDataProvider;//活动记录
use frontend\models\ZsDynasty;//自定义数据模型
class StudentController extends Controller {
$request = YII::$app->request;//获取请求组件
$request->get('id');//获取get方法数据
$request->post('id');//获取post方法数据
$request->isGet;//判断是不是get请求
$request->isPost;//判断是不是post请求
$request->userIp;//获取用户IP地址
$res = YII::$app->response;//获取响应组件
$res->statusCode = '404';//设置状态码
$this->redirect('http://baodu.com');//页面跳转
$res->sendFile('./b.jpg');//文件下载
$session = YII::$app->session;
$session->isActive;//判断session是否开启
$session->open();//开启session
//设置session值
$session->set('user','zhangsan');//第一个参数为键,第二个为值
$session['user']='zhangsan';
//获取session值
$session->get('user');
$session['user'];
//删除session值
$session-remove('user');
unset($session['user']);
$cookies = Yii::$app->response->cookies;//获取cookie对象
$cookie_data = array('name'=>'user','value'=>'zhangsan')//新建cookie数据
$cookies->add(new Cookie($cookie_data));
$cookies->remove('id');//删除cookie
$cookies->getValue('user');//获取cookie<?php
namespace frontend\models;
class ListtModel extends \yii\db\ActiveRecord {
public static function tableName()
{
return 'listt';
}
public function one(){
return $this->find()->asArray()->one();
}
}控制器引用
<?php namespace frontend\controllers; use Yii; use yii\web\controller; use frontend\models\ListtModel; class ListtController extends Controller{ public function actionAdd(){ $model=new ListtModel; $list=$model->one(); $data=$model->find()->asArray()->where("id=1")->all(); print_r($data); } } ?> <br/>
<br/>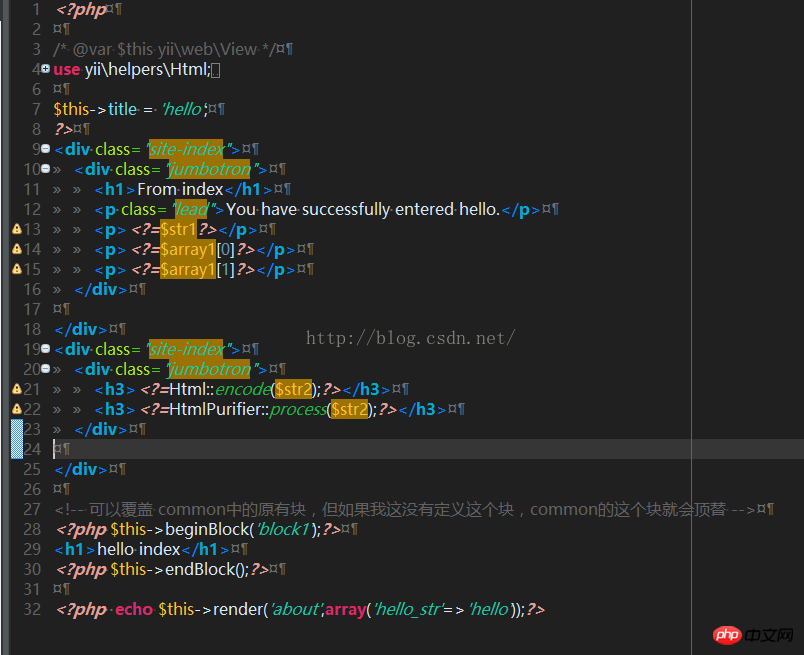 <br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器:
<br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器: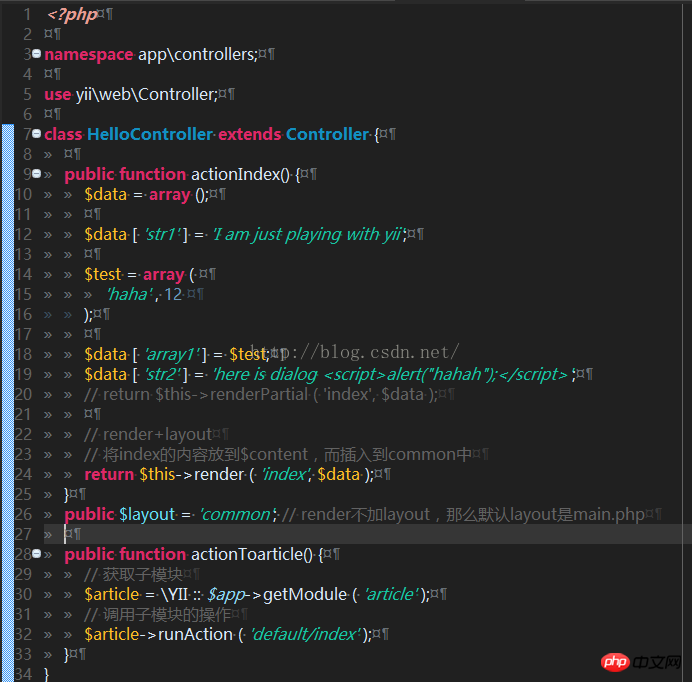 <br/>common.php:
<br/>common.php: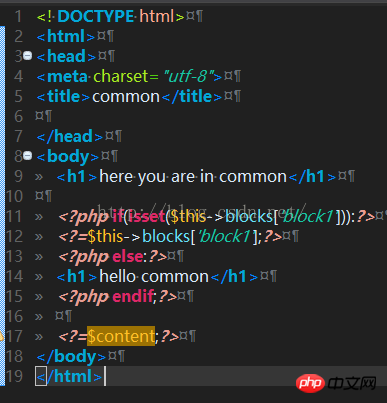 <br/><br/>layouts
<br/><br/>layouts 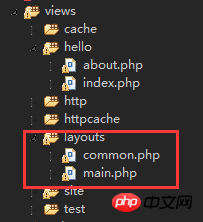 <br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
<br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>//$layout="main" 系统默认文件
//$layout=null 会找父类中默认定义的main public $layout="common";
public function actionIndex(){
return $this->render('index');
}
将以下内容插入 common中 <?=$content;?>
它就是index文件中的内容
'db' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii2', //数据库hyii2
'username' => 'root',
'password' => 'pwhyii2',
'charset' => 'utf8',
],
'db2' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii', //数据库hyii
'username' => 'root',
'password' => 'pwhyii',
'charset' => 'utf8',
],


$id=Yii::$app->db->getLastInsertID();
Yii::$app->db->createCommand()->insert('user', [
'name' => 'test',
'age' => 30,
])->execute();Yii::$app->db->createCommand()->batchInsert('user', ['name', 'age'], [
['test01', 30],
['test02', 20],
['test03', 25],
])->execute();
删除[php] view plain copy
Yii::$app->db->createCommand()->delete('user', 'age = 30')->execute();Yii::$app->db->createCommand()->update('user', ['age' => 40], 'name = test')->execute();
查询[php] view plain copy
//createCommand(执行原生的SQL语句)
$sql= "SELECT u.account,i.* FROM sys_user as u left join user_info as i on u.id=i.user_id";
$rows=Yii::$app->db->createCommand($sql)->query();
查询返回多行:
$command = Yii::$app->db->createCommand('SELECT * FROM post');
$posts = $command->queryAll();
返回单行
$command = Yii::$app->db->createCommand('SELECT * FROM post WHERE id=1');
$post = $command->queryOne();
查询多行单值:
$command = Yii::$app->db->createCommand('SELECT title FROM post');
$titles = $command->queryColumn();
查询标量值/计算值:
$command = Yii::$app->db->createCommand('SELECT COUNT(*) FROM post');
$postCount = $command->queryScalar();
//入库一维数组
public function add($data)
{
$this->setAttributes($data);
$this->isNewRecord = true;
$this->save();
return $this->id;
}
//入库二维数组
public function addAll($data){
$ids=array();
foreach($data as $attributes)
{
$this->isNewRecord = true;
$this->setAttributes($attributes);
$this->save()&& array_push($ids,$this->id) && $this->id=0;
}
return $ids;
}
public function rules()
{
return [
[['title','content'],'required'
]];
}
控制器:
$ids=$model->addAll($data);
var_dump($ids);$user = User::find()->where(['name'=>'test'])->one();
$user->delete();
$result = User::deleteAll(['age'=>'30']);
$result = User::deleteByPk(1);
/**
* @param $files 字段
* @param $values 值
* @return int 影响行数
*/ public function del($field,$values){
//
$res = $this->find()->where(['in', "$files", $values])->deleteAll();
$res=$this->deleteAll(['in', "$field", "$values"]);
return $res;
}[php] view plain copy
$user = User::find()->where(['name'=>'test'])->one(); //获取name等于test的模型
$user->age = 40; //修改age属性值
$user->save(); //保存
[php] view plain copy
$result = User::model()->updateAll(['age'=>40],['name'=>'test']);
/** * @param $data 修改数据 * @param $where 修改条件 * @return int 影响行数 */ public function upda($data,$where){ $result = $this->updateAll($data,$where); // return $this->id; return $result; }Customer::find()->one();
此方法返回一条数据;
Customer::find()->all();
此方法返回所有数据;
Customer::find()->count();
此方法返回记录的数量;
Customer::find()->average();
此方法返回指定列的平均值;
Customer::find()->min();
此方法返回指定列的最小值 ;
Customer::find()->max();
此方法返回指定列的最大值 ;
Customer::find()->scalar();
此方法返回值的第一行第一列的查询结果;
Customer::find()->column();
此方法返回查询结果中的第一列的值;
Customer::find()->exists();
此方法返回一个值指示是否包含查询结果的数据行;
Customer::find()->batch(10);
每次取10条数据
Customer::find()->each(10);
每次取10条数据,迭代查询
//根据sql语句查询:查询name=test的客户 Customer::model()->findAllBySql("select * from customer where name = test");
//根据主键查询:查询主键值为1的数据 Customer::model()->findByPk(1);
//根据条件查询(该方法是根据条件查询一个集合,可以是多个条件,把条件放到数组里面)
Customer::model()->findAllByAttributes(['username'=>'admin']);
//子查询 $subQuery = (new Query())->select('COUNT(*)')->from('customer');
// SELECT `id`, (SELECT COUNT(*) FROM `customer`) AS `count` FROM `customer` $query = (new Query())->select(['id', 'count' => $subQuery])->from('customer');
//关联查询:查询客户表(customer)关联订单表(orders),条件是status=1,客户id为1,从查询结果的第5条开始,查询10条数据 $data = (new Query())
->select('*')
->from('customer')
->join('LEFT JOIN','orders','customer.id = orders.customer_id')
->where(['status'=>'1','customer.id'=>'1'])
->offset(5) ->limit(10) ->all()[php] view plain copy
/**
*客户表Model:CustomerModel
*订单表Model:OrdersModel
*国家表Model:CountrysModel
*首先要建立表与表之间的关系
*在CustomerModel中添加与订单的关系
*/
Class CustomerModel extends \yii\db\ActiveRecord
{
...
//客户和订单是一对多的关系所以用hasMany
//此处OrdersModel在CustomerModel顶部别忘了加对应的命名空间
//id对应的是OrdersModel的id字段,order_id对应CustomerModel的order_id字段
public function getOrders()
{
return $this->hasMany(OrdersModel::className(), ['id'=>'order_id']);
}
//客户和国家是一对一的关系所以用hasOne
public function getCountry()
{
return $this->hasOne(CountrysModel::className(), ['id'=>'Country_id']);
}
....
}
// 查询客户与他们的订单和国家
CustomerModel::find()->with('orders', 'country')->all();
// 查询客户与他们的订单和订单的发货地址(注:orders 与 address都是关联关系)
CustomerModel::find()->with('orders.address')->all();
// 查询客户与他们的国家和状态为1的订单
CustomerModel::find()->with([
'orders' => function ($query) {
$query->andWhere('status = 1');
},
'country',
])->all();yii2 rbac 详解
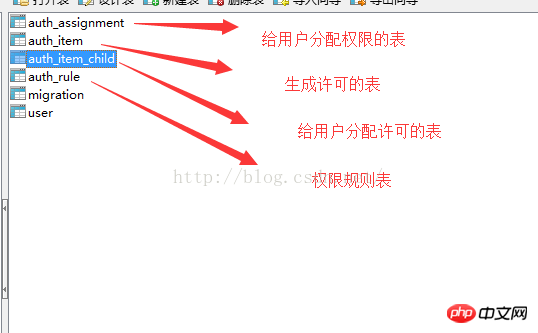 <br/><br/>4. 操作には yii rbac を使用します (実行するすべての操作は、rbac の 4 つのテーブル内のデータを操作します。関連する権限が確立されているかどうかを確認します。これらのテーブルを確認してください)<br/> 権限を登録します: (データは上記の権限テーブルに生成されます) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth ->createPermission($item); $createPost->description = '作成されました' . $auth->add($createPost) }<br/> function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); $role->description = 'Created' 'ロール'; $auth->add($role); }<br/>ロールに権限を割り当てる<br/> public function createEmpowerment($items) { $auth = Yii::$app->authManager;<br/> $parent = $auth- >createRole($items['name']); $child = $auth->createPermission($items['description']); $auth->addChild($parent, $child );権限にルールを追加する: <br/><br/> ルールは、ロールと権限に追加の制約を追加することです。ルールは <br/>
<br/><br/>4. 操作には yii rbac を使用します (実行するすべての操作は、rbac の 4 つのテーブル内のデータを操作します。関連する権限が確立されているかどうかを確認します。これらのテーブルを確認してください)<br/> 権限を登録します: (データは上記の権限テーブルに生成されます) public function createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth ->createPermission($item); $createPost->description = '作成されました' . $auth->add($createPost) }<br/> function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($item); $role->description = 'Created' 'ロール'; $auth->add($role); }<br/>ロールに権限を割り当てる<br/> public function createEmpowerment($items) { $auth = Yii::$app->authManager;<br/> $parent = $auth- >createRole($items['name']); $child = $auth->createPermission($items['description']); $auth->addChild($parent, $child );権限にルールを追加する: <br/><br/> ルールは、ロールと権限に追加の制約を追加することです。ルールは <br/>yiirbacRuleクラスは実装する必要がありますexecute() メソッド。 階層では、先ほど作成したauthorキャラクターは自分の記事を編集できません。それを修正しましょう。 <br/>まず、このユーザーが記事の著者であることを確認するルールが必要です: <br/>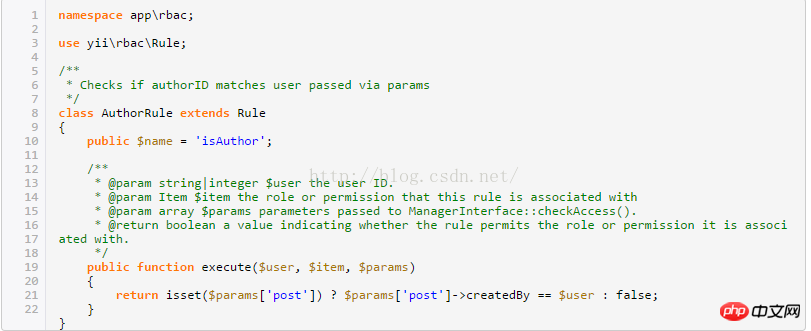 <br/><br/> 注: 上記のメソッドの excute では、$user が後に来ます。ユーザーがログインします user_id<br/>
<br/><br/> 注: 上記のメソッドの excute では、$user が後に来ます。ユーザーがログインします user_id<br/>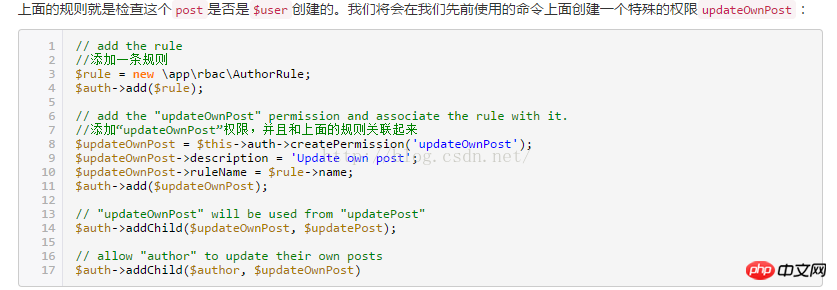 <br/>は、ユーザーがログインした後のユーザーの権限を決定します
<br/>は、ユーザーがログインした後のユーザーの権限を決定します <br/> <br/> 記事を参照するためのリンク: http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/> <br/> 記事を参照するためのリンク: http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>4. 在微信里调支付宝
 <br/>
<br/>
$returnUrl = 'http://域名/user/h5_alipay/return_url.php'; //付款成功后的 同步回调地址,可直接设置为会员中心的地址 $notifyUrl = 'http://域名/notify_url.php'; //付款成功后的异回调地址,如果你的回调地址中包含&符号,最好把回调直接放根目录
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');

密钥管理->开放平台密钥,填写添加了电脑网站支付的应用的APPID
$notifyUrl = 'http://域名/user/h5_alipay/notify_url.php';
//付款成功后的异步回调地址支付宝以post的方式回调
$returnUrl = 'http://域名/user/pay_chongzhi.php';
//付款成功后,支付宝以 get同步的方式回调给发起支付方
$sj=date("Y-m-d H:i:s");
$userid=returnuserid($_SESSION["SHOPUSER"]);
$ddbh=$bh="h5_ali_".time()."_".$userid;
//订单编号
$uip=$_SERVER["REMOTE_ADDR"];
//ip地址 $money1=$_POST[t1];
//bz备注,ddzt与alipayzt及ifok表示订单状态,
intotable("yjcode_dingdang","bh,ddbh,userid,sj,uip,money1,ddzt,alipayzt,bz,ifok","'".$bh."','".$ddbh."',".$userid.",'".$sj."','".$uip."',".$money1.",'等待买家付款','','支付宝充值',0");
//订单入库
//die(mysql_error());
//数据库错误
//订单名称
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
//注意编码
$body = $orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
$outTradeNo = $ddbh;
//你自己的商品订单号
$payAmount = $money1;
//付款金额,单位:元
$signType = 'RSA2';
//签名算法类型,支持RSA2和RSA,推荐使用RSA2
$saPrivateKey='这里填2048位的私钥';
//私钥
$aliPay = new AlipayService($appid,$returnUrl,$notifyUrl,$saPrivateKey);
$payConfigs = $aliPay->doPay($payAmount,$outTradeNo,$orderName,$returnUrl,$notifyUrl);
class AlipayService {
protected $appId;
protected $returnUrl;
protected $notifyUrl;
protected $charset;
//私钥值
protected $rsaPrivateKey;
public function __construct($appid, $returnUrl, $notifyUrl,$saPrivateKey) {
$this->appId = $appid;
$this->returnUrl = $returnUrl;
$this->notifyUrl = $notifyUrl;
$this->charset = 'UTF-8';
$this->rsaPrivateKey=$saPrivateKey;
}
/**
* 发起订单
* @param float $totalFee 收款金额 单位元
* @param string $outTradeNo 订单号
* @param string $orderName 订单名称
* @param string $notifyUrl 支付结果通知url 不要有问号
* @param string $timestamp 订单发起时间
* @return array
*/
public function doPay($totalFee, $outTradeNo, $orderName, $returnUrl,$notifyUrl)
{
//请求参数
$requestConfigs = array( 'out_trade_no'=>$outTradeNo, 'product_code'=>'QUICK_WAP_WAY', 'total_amount'=>$totalFee,
//单位 元 'subject'=>$orderName, //订单标题 );
$commonConfigs = array(
//公共参数
'app_id' => $this->appId, 'method' => 'alipay.trade.wap.pay',
//接口名称 'format' => 'JSON',
'return_url' => $returnUrl, 'charset'=>$this->charset, 'sign_type'=>'RSA2',
'timestamp'=>date('Y-m-d H:i:s'), 'version'=>'1.0', 'notify_url' => $notifyUrl,
'biz_content'=>json_encode($requestConfigs), );
$commonConfigs["sign"] = $this->generateSign($commonConfigs, $commonConfigs['sign_type']);
return $commonConfigs;
}
public function generateSign($params, $signType = "RSA") {
return $this->sign($this->getSignContent($params), $signType);
}
protected function sign($data, $signType = "RSA") {
$priKey=$this->rsaPrivateKey;
$res = "-----BEGIN RSA PRIVATE KEY-----\n" .
wordwrap($priKey, 64, "\n", true) .
"\n-----END RSA PRIVATE KEY-----";
($res) or die('您使用的私钥格式错误,请检查RSA私钥配置');
if ("RSA2" == $signType) {
openssl_sign($data, $sign, $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
//OPENSSL_ALGO_SHA256是php5.4.8以上版本才支持
} else {
openssl_sign($data, $sign, $res);
}
$sign = base64_encode($sign);
return $sign;
}
/**
* 校验$value是否非空
* if not set ,return true;
* if is null , return true;
**/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/**
* 转换字符集编码
* @param $data
* @param $targetCharset
* @return string
*/
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
}
}
return $data;
} }
function isWeixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessenger') !== false ) {
return true;
}
return false;
}
$queryStr = http_build_query($payConfigs); if(isWeixin()):
//注意下面的ap.js ,文件的存在目录,如果不确定.可以写绝对地址.否则可能微信中没法弹出提示窗口,
?>
<script>
var gotoUrl = 'https://openapi.alipaydev.com/gateway.do?<?=$queryStr?>';
//注意上面及下面的alipaydev.com,用的是沙箱接口,去掉dev表示正式上线
_AP.pay(gotoUrl); </script> <?php
header('Content-type:text/html; Charset=GB2312');
//支付宝公钥,账户中心->密钥管理->开放平台密钥,找到添加了支付功能的应用,根据你的加密类型,查看支付宝公钥
$alipayPublicKey=''; $aliPay = new AlipayService($alipayPublicKey);
//验证签名,如果签名失败,注意编码问题.特别是有中文时,可以换成英文,再测试
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
//程序执行完后必须打印输出“success”(不包含引号)。
如果商户反馈给支付宝的字符不是success这7个字符,支付宝服务器会不断重发通知,直到超过24小时22分钟。
一般情况下,25小时以内完成8次通知(通知的间隔频率一般是:4m,10m,10m,1h,2h,6h,15h);
$out_trade_no = $_POST['out_trade_no'];
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
switch($trade_status){
case "WAIT_BUYER_PAY";
$nddzt="等待买家付款";
break;
case "TRADE_FINISHED": case "TRADE_SUCCESS"; $nddzt="交易成功";
break;
}
if(empty($trade_no)){echo "success";exit;}
//注意,这里的查询不能 强制用户登录,则否支付宝没法进入本页面.没法通知成功
$sql="select ifok,jyh from yjcode_dingdang where ifok=1 and jyh='".$trade_no."'";mysql_query("SET NAMES 'GBK'");$res=mysql_query($sql);
//支付宝生成的流水号
if($row=mysql_fetch_array($res)){echo "success";exit;
}
$sql="select * from yjcode_dingdang where ddbh='".$out_trade_no."' and ifok=0 and ddzt='等待买家付款'";
mysql_query("SET NAMES 'GBK'");
$res=mysql_query($sql);
if($row=mysql_fetch_array($res)){
if(1==$row['ifok']){
echo "success";exit;
}
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
if($row['money1']== $_POST['total_fee'] ){
$sj=time();$uip=$_SERVER["REMOTE_ADDR"];
updatetable("yjcode_dingdang","sj='".$sj."',uip='".$uip."',alipayzt='".$trade_status."',ddzt='".$nddzt."',ifok=1,jyh='".$trade_no."' where id=".$row[id]);
$money1=$row["money1"];
//修改订单状态为成功付款
PointIntoM($userid,"支付宝充值".$money1."元",$money1);
//会员余额增加 echo "success";exit;
}
}
}
//——请根据您的业务逻辑来编写程序(以上代码仅作参考)——
echo 'success';exit();
}
echo 'fail';exit();
class AlipayService {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
} // if(!$this->checkEmpty($this->alipayPublicKey)) { //
//释放资源 //
openssl_free_key($res);
// }
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}<?php
define('PHPS_PATH', dirname(__FILE__).DIRECTORY_SEPARATOR);
//$_POST['trade_no']=1; if($_POST['trade_no']){ $alipayPublicKey='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAyg8BC9UffA4ZoMl12zz';
//RSA公钥,与支付时的私钥对应
$aliPay = new AlipayService2($alipayPublicKey);
//验证签名
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
//file_put_contents('333.txt',$_POST);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
$out_trade_no = $_POST['out_trade_no'];
//$out_trade_no = '2018022300293843964';
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
//$trade_status='';
$userinfo = array();
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
//ini_set('display_errors',1);
//错误信息
//ini_set('display_startup_errors',1);
//php启动错误信息
//error_reporting(-1);
//打印出所有的 错误信息
$mysql_user=include(PHPS_PATH.'/caches/configs/database.php');
$username=$mysql_user['default']['username'];
$password=$mysql_user['default']['password'];
$tablepre=$mysql_user['default']['tablepre'];
$database=$mysql_user['default']['database'];
$con = mysqli_connect($mysql_user['default']['hostname'],$username,$password); mysqli_select_db($con,$database);
$sql = ' SELECT * FROM '.$tablepre."pay_account where trade_sn='".$out_trade_no."'";
$result2=mysqli_query($con,$sql);
$orderinfo=mysqli_fetch_array($result2);;
$uid=$orderinfo['userid'];
$sql2 = ' SELECT * FROM '.$tablepre."member where userid=".$uid;
$result1=mysqli_query($con,$sql2); $userinfo=mysqli_fetch_array($result1);;
if($orderinfo){
if($orderinfo['status']=='succ'){
//file_put_contents('31.txt',1);
echo 'success';
mysqli_close($con);
exit();
}else{
// if($orderinfo['money']== $_POST['total_amount'] ){
$money = $orderinfo['money'];
$amount = $userinfo['amount'] + $money;
$sql3 = ' update '.$tablepre."member set amount= ".$amount." where userid=".$uid;
$result3=mysqli_query($con,$sql3);
$sql4 = ' update '.$tablepre."pay_account set status= 'succ' where userid=".$uid ." and trade_sn='".$out_trade_no."'";
$result4=mysqli_query($con,$sql4);
//file_put_contents('1.txt',$result4);
echo 'success';
mysqli_close($con);
exit();
// }
}
} else {
echo 'success';exit();
}
}
echo 'success';exit();
} echo 'fail';exit();
} class AlipayService2 {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
}
// if(!$this->checkEmpty($this->alipayPublicKey)) {
//
//释放资源 //
openssl_free_key($res); //
}
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
} /** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}
?>5. 抓包
常用抓包工具
6. https / http
7. like 効率
msyql をファジークエリに使用する場合、通常、データ量が少ない場合は、like ステートメントを使用するのが自然です。ただし、データの量が数百万または数千万に達すると、クエリの効率が容易に明らかになります。このとき、クエリの効率が非常に重要になります。 8. left、right、join、デカルト積を解く
sql Union、intersect、excelステートメント
9. oop封装、继承、多态
php面向对象之继承、多态、封装简介
作者:PHP中文网2018-03-02 09:49:15
interface InterAnimal{
public function speak();
public function name($name);
}//接口实现 class cat implements InterAnimal{
public function speak(){
echo "speak";
}
public function name($name){
echo "My name is ".$name;
}
}<br/>class Computer {
private $_name = '联想';
public function __get($_key) {
return $this->$_key;
}
public function run() {
echo '父类run方法';
}}class NoteBookComputer extends Computer {}$notebookcomputer = new NoteBookComputer ();
$notebookcomputer->run ();
//继承父类中的run()方法echo $notebookcomputer->_name;
//通过魔法函数__get()获得私有字段<br/>class Computer {
public $_name = '联想';
protected function run() {
echo '我是父类';
}}//重写其字段、方法class NoteBookComputer extends Computer {
public $_name = 'IBM';
public function run() {
echo '我是子类';
}}<br/>abstract class Computer {
abstract function run();
}
final class NotebookComputer extends Computer {
public function run() {
echo '抽象类的实现';
}
}<br/>interface Computer {
public function version();
public function work();
}class NotebookComputer implements Computer {
public function version() {
echo '联想<br>';
}
public function work() {
echo '笔记本正在随时携带运行!';
}}class desktopComputer implements Computer {
public function version() {
echo 'IBM';
}
public function work() {
echo '台式电脑正在工作站运行!';
}}class Person {
public function run($type) {
$type->version ();
$type->work ();
}}
$person = new Person ();
$desktopcomputer = new desktopComputer ();
$notebookcomputer = new NoteBookComputer ();
$person->run ( $notebookcomputer );<br/> PHP オブジェクト指向識別オブジェクト
PHP オブジェクト指向識別オブジェクト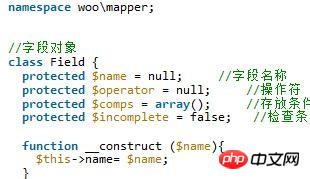 PHPオブジェクト指向識別オブジェクトインスタンスの詳細説明
PHPオブジェクト指向識別オブジェクトインスタンスの詳細説明 画像ウォーターマーククラスのカプセル化コード共有のPHP実装
画像ウォーターマーククラスのカプセル化コード共有のPHP実装 PHPカプセル化Mysqlの詳細説明操作クラス
PHPカプセル化Mysqlの詳細説明操作クラス 10. mvc
11. 有料CDN送信と無料CDN送信の違い リクエスト(ファイル読み込み)の数は通常4
までに制限されており、その後3. ISP 相互接続は、チャイナ テレコムとチャイナ ユニコムという 2 つのネットワーク オペレータ間の相互接続など、インターネット サービス プロバイダー間の相互接続です。 Web サイト サーバーがオペレータ A のコンピュータ ルームに配置されており、オペレータ B のユーザーが Web サイトにアクセスしたい場合、クロスネットワーク アクセスのために A と B の間の相互接続ポイントを経由する必要があります。インターネットのアーキテクチャの観点から見ると、異なる通信事業者間の相互接続帯域幅が占める割合は、通信事業者のネットワーク トラフィックのごくわずかです。したがって、これはネットワーク送信の輻輳ポイントになることがよくあります。
4. 長距離バックボーン伝送。 1 つ目は長距離伝送遅延の問題、2 つ目はバックボーン ネットワークの輻輳問題です。これらの問題は、World Wide Web トラフィックの伝送に輻輳を引き起こします。 基本プロセス
 <br/>1. ユーザーはブラウザにアクセスしたいドメイン名を入力します。 <br/>2. ブラウザは DNS サーバーにドメイン名の解決を要求します。 <br/>3. DNS サーバーはドメイン名の IP アドレスをブラウザーに返します。 <br/>4. ブラウザは IP アドレスを使用してサーバーにコンテンツをリクエストします。 <br/>5. サーバーはユーザーが要求したコンテンツをブラウザーに返します。
<br/>1. ユーザーはブラウザにアクセスしたいドメイン名を入力します。 <br/>2. ブラウザは DNS サーバーにドメイン名の解決を要求します。 <br/>3. DNS サーバーはドメイン名の IP アドレスをブラウザーに返します。 <br/>4. ブラウザは IP アドレスを使用してサーバーにコンテンツをリクエストします。 <br/>5. サーバーはユーザーが要求したコンテンツをブラウザーに返します。  <br/>1. ユーザーはブラウザにアクセスしたいドメイン名を入力します。 <br/>2. ブラウザは DNS サーバーにドメイン名の解決を要求します。 CDN はドメイン名解決を調整するため、DNS サーバーは最終的に、CNAME が指す CDN 専用 DNS サーバーにドメイン名解決権限を引き渡します。 <br/>3. CDN の DNS サーバーは、CDN の負荷分散デバイスの IP アドレスをユーザーに返します。 <br/>4. ユーザーは、CDN の負荷分散デバイスへのコンテンツ URL アクセス要求を開始します。 <br/>5. CDN 負荷分散デバイスは、ユーザーにサービスを提供するために適切なキャッシュ サーバーを選択します。 <br/>選択の基準には、ユーザーの IP アドレスに基づいてユーザーに最も近いサーバーを判断すること、ユーザーが要求した URL に含まれるコンテンツ名に基づいてユーザーが必要とするコンテンツがあるサーバーを判断すること、および負荷状況を問い合わせることが含まれます。各サーバーで、どのサーバーの負荷が小さいかを判断します。 <br/>上記の包括的な分析に基づいて、負荷分散設定によりキャッシュ サーバーの IP アドレスがユーザーに返されます。 <br/>6. ユーザーがキャッシュ サーバーにリクエストを送信します。 <br/>7. キャッシュサーバーはユーザーのリクエストに応答し、ユーザーが必要とするコンテンツをユーザーに配信します。 <br/>このキャッシュ サーバーにユーザーが必要とするコンテンツがなく、負荷分散デバイスがそれをユーザーに割り当てている場合、このサーバーは、コンテンツのソースを追跡するまで、上位レベルのキャッシュ サーバーにコンテンツを要求します。 Web サイト サーバーはコンテンツをローカルにプルします。
<br/>1. ユーザーはブラウザにアクセスしたいドメイン名を入力します。 <br/>2. ブラウザは DNS サーバーにドメイン名の解決を要求します。 CDN はドメイン名解決を調整するため、DNS サーバーは最終的に、CNAME が指す CDN 専用 DNS サーバーにドメイン名解決権限を引き渡します。 <br/>3. CDN の DNS サーバーは、CDN の負荷分散デバイスの IP アドレスをユーザーに返します。 <br/>4. ユーザーは、CDN の負荷分散デバイスへのコンテンツ URL アクセス要求を開始します。 <br/>5. CDN 負荷分散デバイスは、ユーザーにサービスを提供するために適切なキャッシュ サーバーを選択します。 <br/>選択の基準には、ユーザーの IP アドレスに基づいてユーザーに最も近いサーバーを判断すること、ユーザーが要求した URL に含まれるコンテンツ名に基づいてユーザーが必要とするコンテンツがあるサーバーを判断すること、および負荷状況を問い合わせることが含まれます。各サーバーで、どのサーバーの負荷が小さいかを判断します。 <br/>上記の包括的な分析に基づいて、負荷分散設定によりキャッシュ サーバーの IP アドレスがユーザーに返されます。 <br/>6. ユーザーがキャッシュ サーバーにリクエストを送信します。 <br/>7. キャッシュサーバーはユーザーのリクエストに応答し、ユーザーが必要とするコンテンツをユーザーに配信します。 <br/>このキャッシュ サーバーにユーザーが必要とするコンテンツがなく、負荷分散デバイスがそれをユーザーに割り当てている場合、このサーバーは、コンテンツのソースを追跡するまで、上位レベルのキャッシュ サーバーにコンテンツを要求します。 Web サイト サーバーはコンテンツをローカルにプルします。 まとめ
12. nginx負荷分散戦略:
13. キャッシュ (7 レベルの説明)
ディレクトリ
1.1 ページ キャッシュ 動的 Web ページの場合、ページ キャッシュ (ページ キャッシュ) と呼ばれる、生成された HTML をキャッシュします。動的画像や動的 XML データなどの他の動的コンテンツについても、同じ戦略を使用してキャッシュすることができます。結果は全体としてキャッシュされます。 1.1.1 保存方法
1.1.2 有効期限チェック キャッシュの話をするので、有効期限チェックについても話さなければなりません。 キャッシュ有効期限チェックは主に の 2 つの主要なメカニズムがあります。
キャッシュの有効期間を設定するのは簡単ではありませんが、長すぎるとキャッシュヒット率は高くなりますが、短すぎると動的コンテンツの更新が間に合わなくなります。時間内に更新されると、キャッシュ ヒット率が低下します。したがって、適切な有効期間を設定することは非常に重要ですが、それよりも重要なのは、有効期間をいつ変更する必要があるかを認識し、いつでも適切な値を見つけることができる必要があります。 キャッシュの有効期間に加えて、キャッシュは
前述の動的キャッシュと同様に、静的ページはページ全体を更新する必要がなく、サーバーインクルージョン (SSI) テクノロジーを通じて各部分ページを個別に更新できるため、再構築に伴う計算オーバーヘッドとディスク I が大幅に削減されます。ページ全体の /O オーバーヘッド、および配布時のネットワーク I/O オーバーヘッド。現在、主流の Web サーバーは、Apache、lighttpd などの SSI テクノロジーをサポートしています。 2. ブラウザ キャッシュ 共謀の観点から、人々はブラウザを PC 上の単なるソフトウェアの一部として考えることに慣れていますが、実際には、2.1.1 缓存协商
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");Last-Modified: Fri, 9 Dec 2014 23:23:23 GMT
If-Modified-Since: Fri, 9 Dec 2014 23:23:23 GMT
HTTP/1.1 304 Not Modified
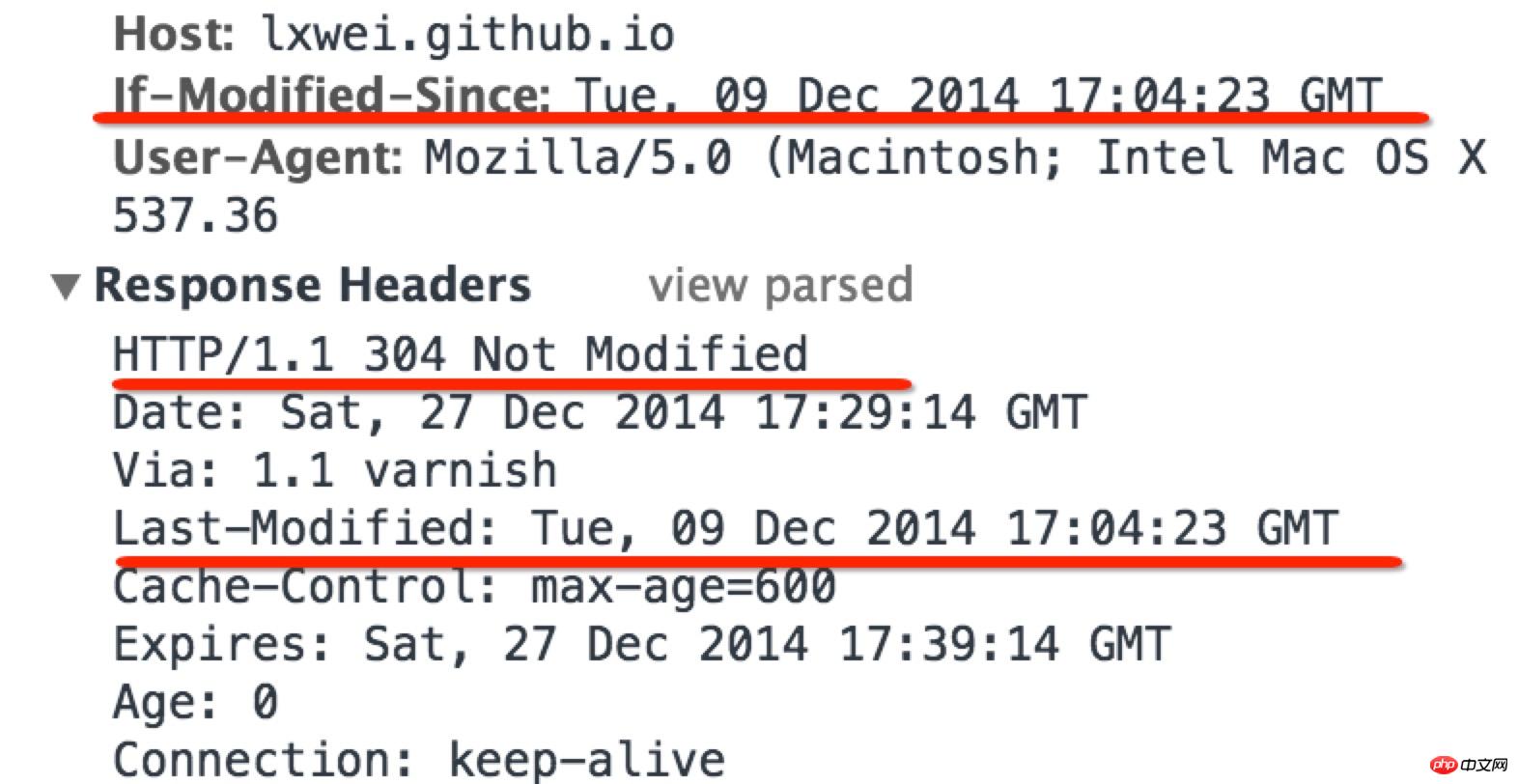
If-None-Match: "87665-c-090f0adfadf"
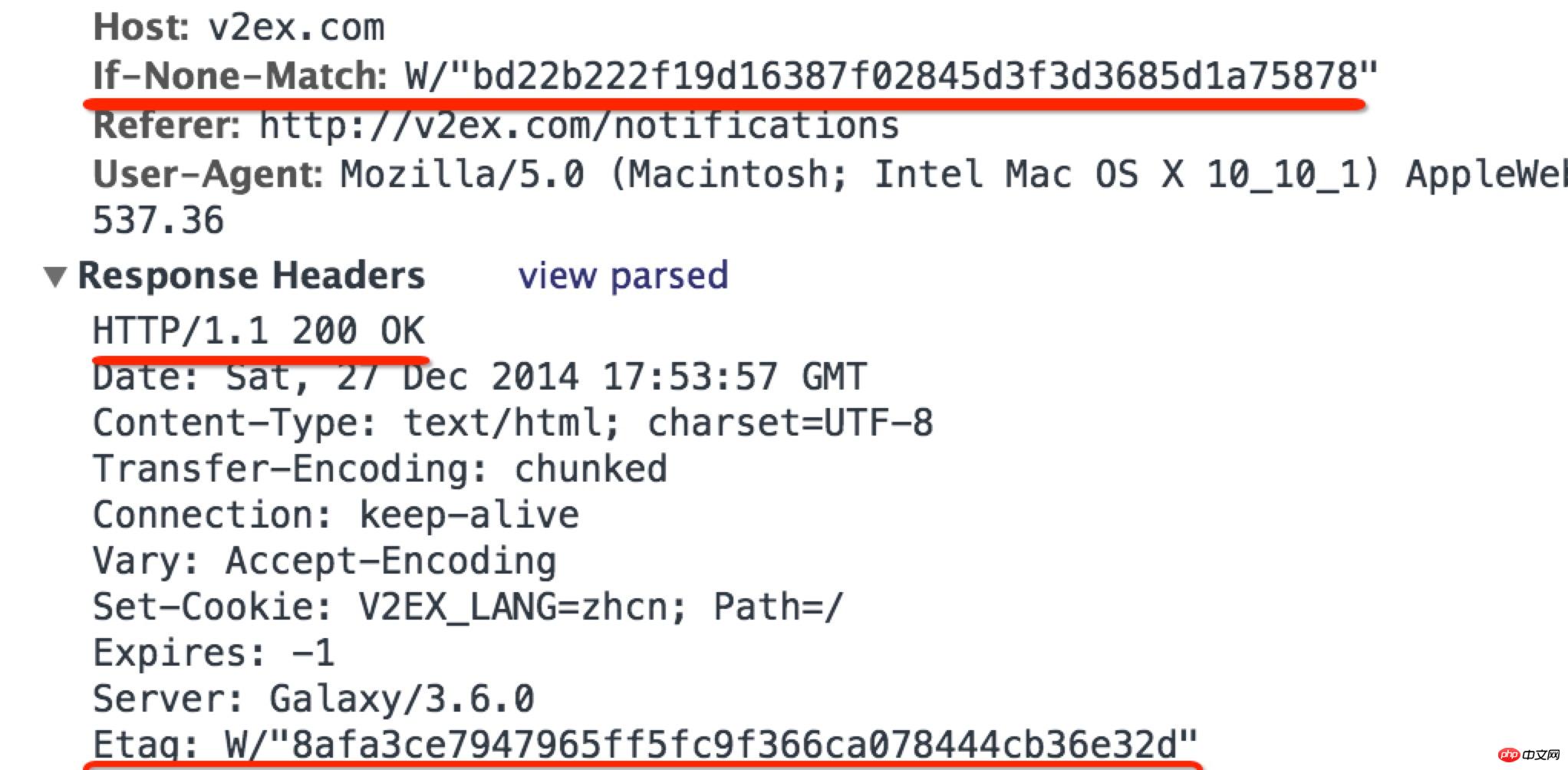
2.1.2 性能
2.2 彻底消灭请求
2.2.1 Expires 标记
Expires标记,告诉浏览器该内容何时过期,在内容过期前不需要再询问服务器,直接使用本地缓存即可。2.2.2 请求页面方式
最終更新日 有効期限 Ctrl + F5 無効 無効 F5 有効 無効 有効 有効に移動 2.2.3 适应过期时间
max-age 指定缓存过期的相对时间,单位是秒,相对时间指相对浏览器本地时间。目前,当 HTTP 响应中同时含有 Expires 和 Cache-Control 时,浏览器会优先使用 Cache-Control。2.3 总结
3. Web 服务器缓存
3.1 简介
Expires 标记,如果希望不缓存某个动态内容,那么最简单的办法就是使用:header("Expires: 0");Last-Modified来实现,具体方法不再叙述。3.2 取代动态内容缓存
3.3 缓存文件描述符
4. 反向代理缓存
4.1 反向代理简介
4.2 リバース プロキシ キャッシュ
4.2.1 キャッシュ ルールを変更する
4.2.2 キャッシュのクリア
5. 分散キャッシュ
5.1 memcached
5.2 読み取りおよび書き込みキャッシュ
5.3 キャッシュ監視
同時処理能力、キャッシュスペース容量などが限界に達する可能性があり、拡張は避けられません。 14. コンテンツの流用、CMS の静的化
1. なぜ静的なのか?
情報が同期していません。情報の同期を保つには、HTML ページを再生成する必要があります。
PHP の静的化の簡単な理解は、Web サイトで生成されたページを静的な形式で訪問者の前に表示することです。 HTML 、PHP 静的は、純粋静的
に分けられます。この 2 つの違いは、PHP が静的ページを生成するための異なる処理メカニズムにあります。
を使用する Web サイトの場合、Web サーバーの数を増やして Web サイトの同時アクセス容量を効果的に増やすことは困難です。たとえば、タオバオやJD.comなどです。 静的ソリューション: CDNコンテンツ配信ネットワーク技術[ネットワーク伝送の効率は距離に関係しており、最も近い静的サーバーノードであるという原理アルゴリズム]
利点:15. スピリットCSS 大きいほど良いですか?
いつ使用するか: リクエスト量が特に大きく、リクエストデータが小さい場合、画像が比較的大きい場合は、複数の小さな画像を 1 つの大きな画像に集約して、位置決めによって実装できます。リソースを削減するためにグラフの切断が実装されており、複数のリクエストが 1 つにマージされ、ネットワーク リソースの消費が減り、フロントエンド アクセスが最適化されます。 <br/>

<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>制作一幅扑克牌--黑桃10</title>
<style type="text/css"><!--
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
/*中间图片通用设置*/
span{display:block;width:20px;height:21px; position:absolute;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;}
/*小图片通用设置*/
b{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat; overflow:hidden;}
/*数字通用设置*/
em{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;overflow:hidden;}
/*各坐标点位置*/
.N1{left:1px;top:8px;}
.First{left:5px;top:20px;}
.A1{left:20px;top:20px;}
.A2{left:20px;top:57px;}
.A3{left:20px;top:94px;}
.A4{left:20px;top:131px;}
.B1{left:54px;top:38px;}
.B2{left:54px;top:117px;}
.C1{left:86px;top:20px;}
.C2{left:86px;top:57px;}
.C3{left:86px;top:94px;}
.C4{left:86px;top:131px;}
.Last{bottom:20px;right:0px;}
.N2{bottom:8px;right:5px;
}
/*大图标黑红梅方四种图片-上方向*/
.up1{background-position:0 1px;}/*黑桃*/
/*大图标黑红梅方四种图片-下方向*/
.down1{background-position:0 -19px;}/*黑桃*/
/*小图标黑红梅方四种图片-上方向*/
.small_up1{background-position:0 -40px;}/*黑桃*/
/*小图标黑红梅方四种图片-下方向*/
.small_down1{background-position:0 -51px;}/*黑桃*/
/*A~k数字图片-左上角*/
.n10{background-position:-191px 0px;left:-4px;width:21px;}
/*A~k数字图片-右下角*/
.n10_h{background-position:-191px -22px;right:3px;width:21px;}
/*A~k数字图片-左上角红色字*/
.n10_red{background-position:-191px 0px;}
/*A~k数字图片-右下角红色字*/
.n10_h_red{background-position:-191px -33px;}
-->
</style>
</head>
<body>
<!--10字符-->
<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
</body>
</html>16. 反向代理/正向代理
正向代理与反向代理【总结】

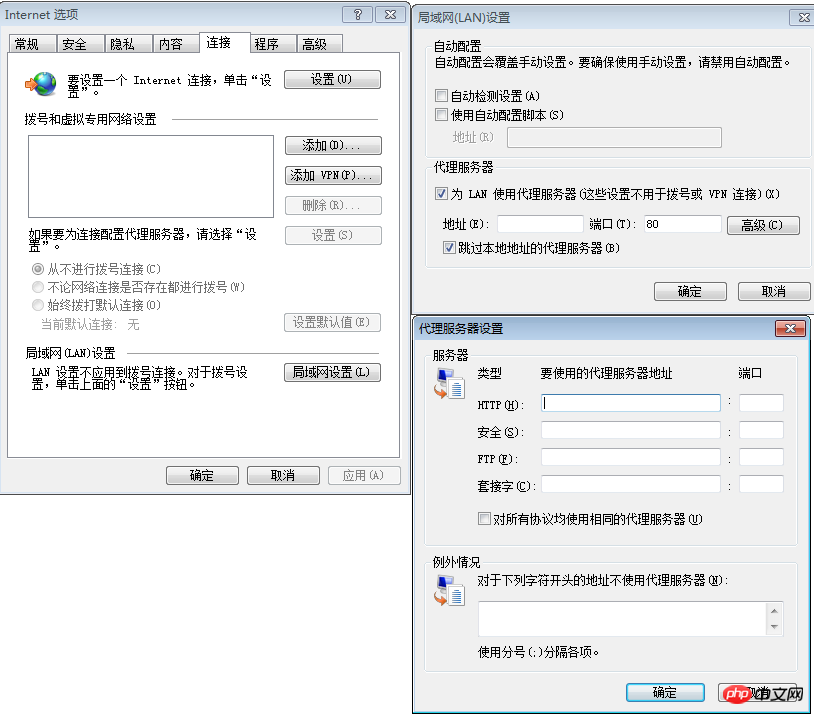

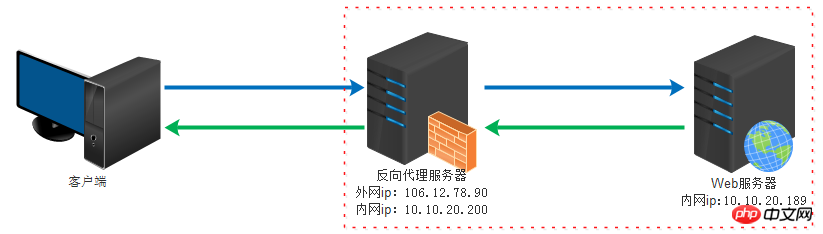
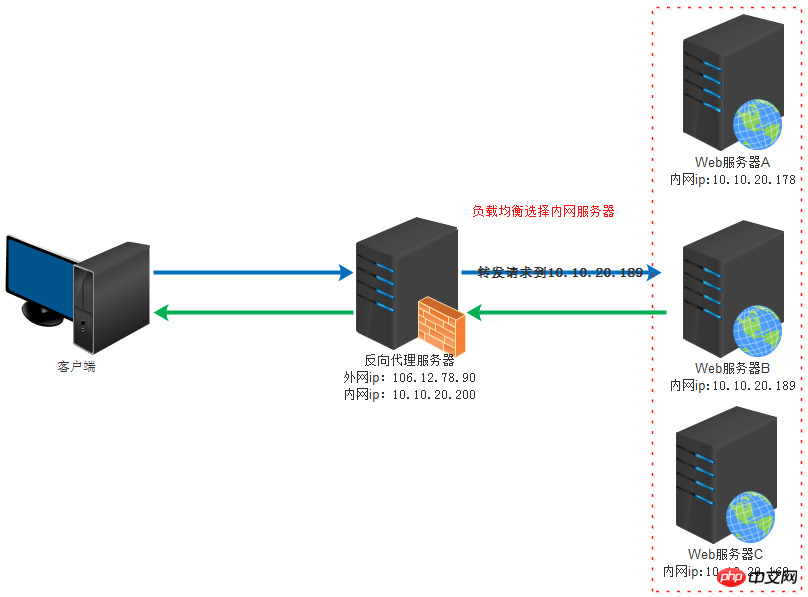
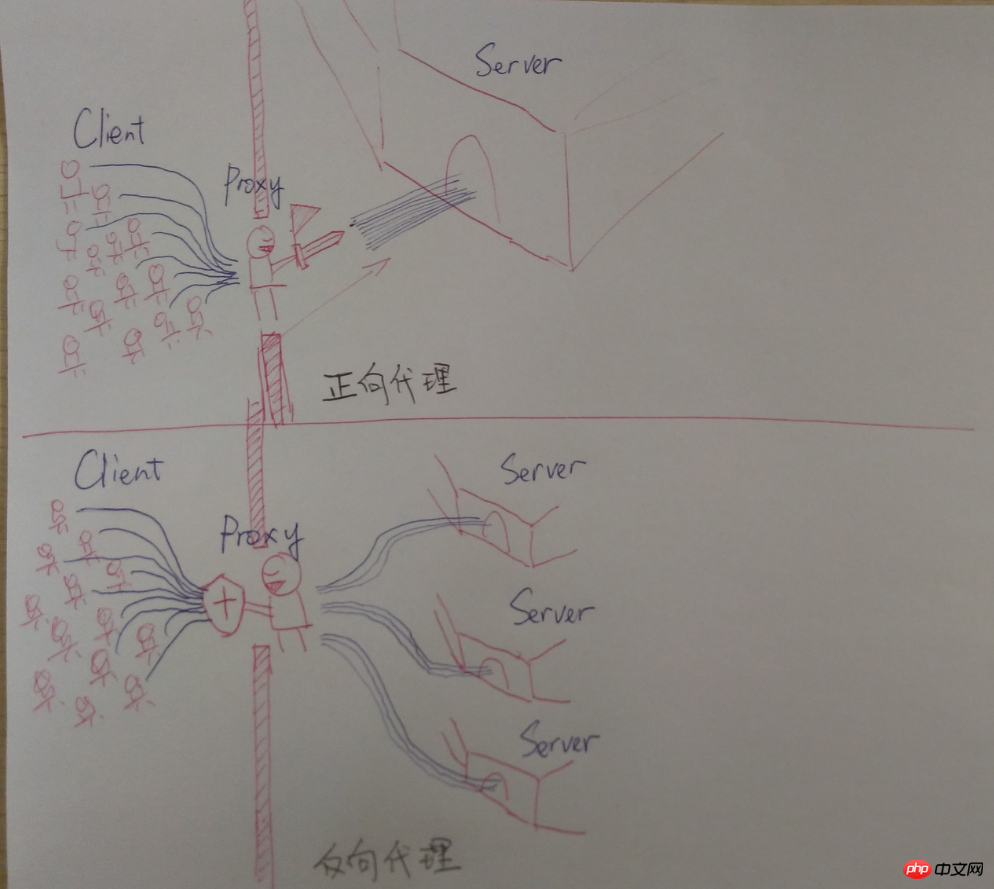
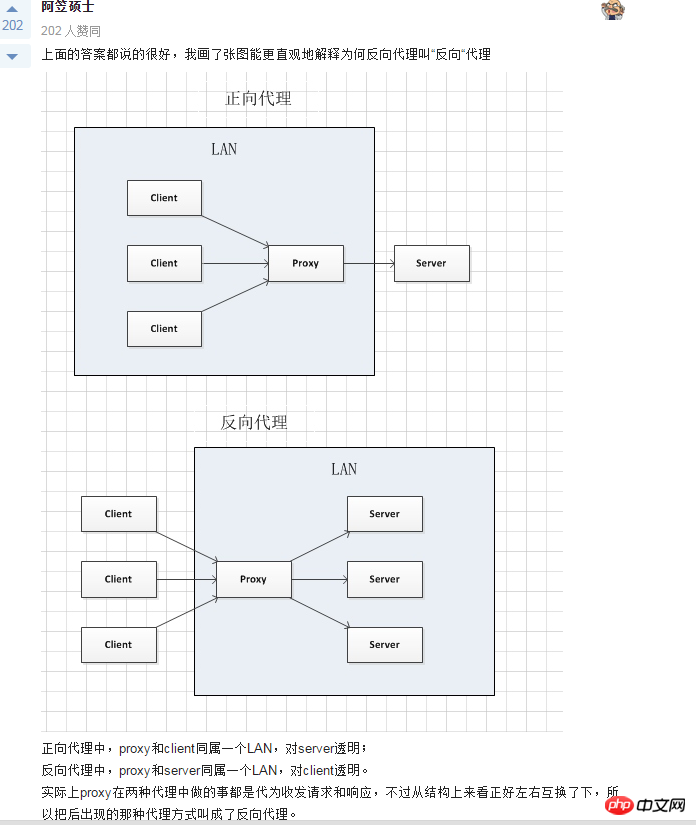
フォワードプロキシ
。通常のリクエストを送信すると、リバース プロキシはリクエストを元のサーバーに転送し、取得したコンテンツを元のコンテンツであるかのようにクライアントに返します。独自の簡単に説明すると、プロキシサーバーはターゲットサーバーに代わってそれを受け取り、クライアントのリクエストを返します (
一般的な使用法は、ファイアウォール内の LAN クライアントにインターネットへのアクセスを提供することです。 バッファリング機能を使用してネットワーク使用量を削減します。 通常の使用法は、ファイアウォールの背後にあるサーバーへのアクセスをインターネット ユーザーに提供することです。
バックエンド上の複数のサーバーに負荷分散を提供するか、バックエンドが遅いサーバーにバッファリング サービスを提供します。
を使用すると、クライアントはそれを介して任意のWebサイトにアクセスでき、クライアント自体が隠蔽されるため、許可されたクライアントのみがサービスを提供できるようにセキュリティ対策を講じる必要があります。 リバースプロキシ
で、ユーザーのリクエストをバックエンド サーバー に転送します。
CDNはリバースプロキシの技術原理を使用しており、その最も重要なコア技術はスマートDNSなどです。 17. mysql マスター/スレーブ、最適化
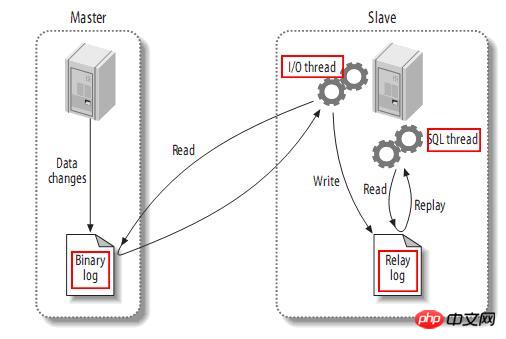
18。
20. memcached と redis の違い
21. apache と nginx の違い
1. 定義:
1. サーバーは、広範囲のほぼすべてのサーバーで実行できるモジュラーサーバーです。
はアプリケーション(
2. Nginx と Apache の比較
1) nginx apache
2) apache nginxに対する利点
Apache 3
よりも速く静的リクエストを処理します。
詳細については、ここをクリックしてください: http://www.findme.wang/blog/detail/id/1.htmlCPU を表示
top コマンドはLinux 一般的に使用されるパフォーマンス分析ツールでは、システム内の各プロセスのリソース使用状況をリアルタイムで表示できます。Windows タスク マネージャーと同様に、top コマンドを直接使用して %MEM の内容を表示できます。 oracle ユーザーのプロセス メモリ使用量を表示する場合は、次のコマンドを使用できます。  <br/><br/><br/>
<br/><br/><br/>23. 性能优化
分布式缓存
缓存的基本原理
缓存是指将数据存储在相对较高访问速度的存储介质中。
(1)访问速度快,减少数据访问时间;
(2)如果缓存的数据进过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用。
缓存的本质是一个内存Hash表,以一对Key、Value的形式存储在内存Hash表中,读写时间复杂度为O(1)。
合理使用缓存
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1以上,缓存才有意义。
没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
缓存可用性
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。
这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。
实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。
但这种设计有违缓存的初衷,**缓存根本就不应该当做一个可靠的数据源来使用**。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。
当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
缓存预热
缓存中的热点数据利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。
那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。
**一个简单的对策是将不存在的数据也缓存起来(其value为null)** 。分布式缓存架构
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以Memcached为代表的不互相通信的分布式缓存。 JBoss Cache在集群中所有服务器中保存相同的缓存数据,当某台服务器有缓存数据更新,就会通知其他机器更新或清除缓存数据。 它通常将应用程序和缓存部署在同一台服务器上,但受限于单一服务器的内存空间;当集群规模较大的时候,缓存更新需要同步到所有机器,代价惊人。因此这种方案多见于企业应用系统中。 Memcached采用一种集中式的缓存集群管理(互不通信的分布式架构方式)。缓存与应用分离部署,缓存系统部署在一组专门的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问数据,缓存服务器之间不通信,集群规模可以很容易地实现扩容,具有良好的伸缩性。 (1)简单的通信协议。Memcached使用TCP协议(UDP也支持)通信; (2)丰富的客户端程序。 (3)高性能的网络通信。Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库,具有稳定的长连接。 (4)高效的内存管理。 (5)互不通信的服务器集群架构。
异步操作
使用消息队列将调用异步化(生产者--消费者模式),可改善网站的扩展性,还可以改善系统的性能。
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大压力,使得响应延迟加剧。
在使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程独立部署在专门的服务器集群上)从消息队列中获取数据,
异步写入数据库。由于消息队列服务器处理速度远快于服务器(消息队列服务器也比数据库具有更好的伸缩性)。
消息队列具有很好的削峰作用--通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。
需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,
需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完后,
甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
使用集群
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理。
代码优化
多线程
从资源利用的角度看,使用多线程的原因主要有两个:IO阻塞与多CPU。
当前线程进行IO处理的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作(不管是磁盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。
理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多线程IO阻塞与执行交替进行,可最大限度利用CPU资源。
使用多线程的另一个原因是服务器有多个CPU。
简化启动线程估算公式:
启动线程数 = [任务执行时间 / (任务执行时间 - IO等待时间)]*CPU内核数 多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。
所有的资源---对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有:
(1)将对象设计为无状态对象。
所谓无状态对象是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),不过从面向对象设计的角度看,无状态对象是一种不良设计。
(2)使用局部对象。
即在方法内部创建对象,这些对象会被每个进入该方法的线程创建,除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。
(3)并发访问资源时使用锁。
即多线程访问资源的时候,通过锁的方式使多线程并发操作转化为顺序操作,从而避免资源被并发修改。
资源复用
1系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。
2从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。
3单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也就自然而然了。
4对象池模式通过复用对象实例,减少对象创建和资源消耗。
5对于数据库连接对象,每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库连接,对数据库服务器是灾难性的,
同时频繁创建关闭连接也需要花费较长的时间。
6因此实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式,数据库连接对象创建好以后,
将连接对象放入对象池容器中,应用程序要连接的时候,就从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需要创建新的连接。
数据结构
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性不言而喻。
在不同场景中合理使用数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
垃圾回收
理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
24. 支付
手机网站支付接口
产品简介
申请条件
配置
查看PID

配置密钥
应用环境
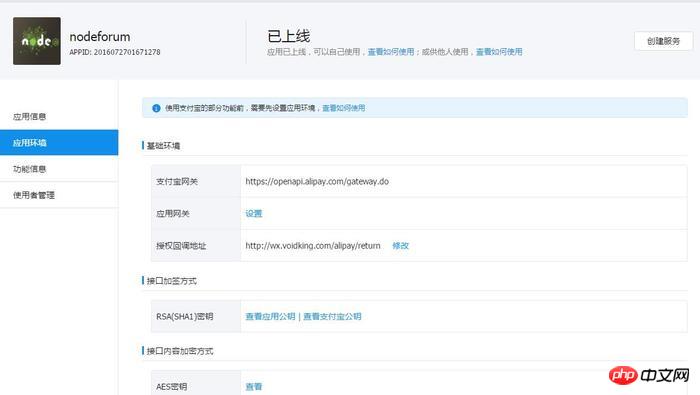 <br/>
<br/>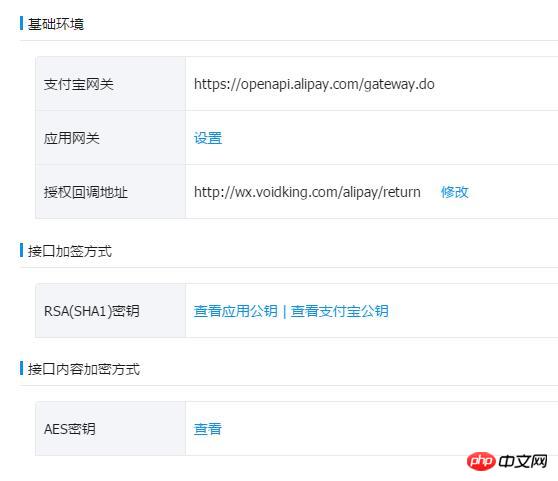 <br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
<br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。交互
Node端发起支付请求
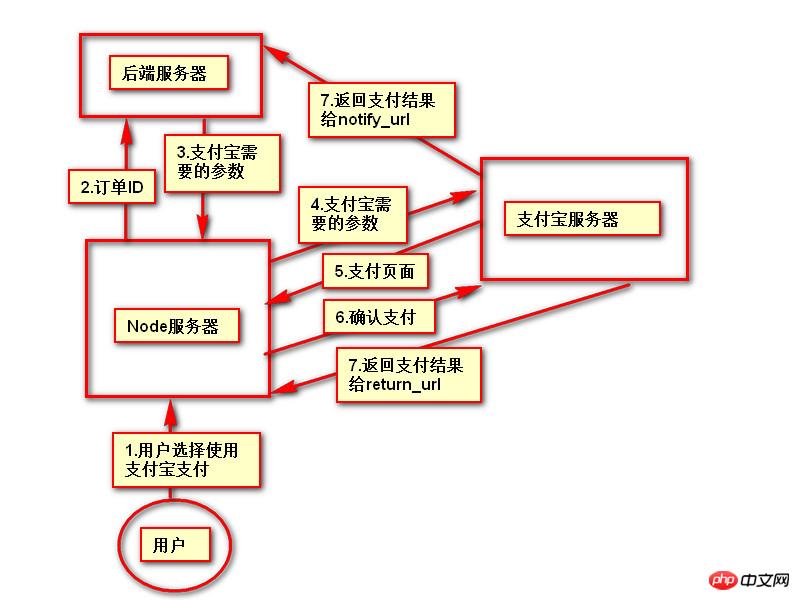 <br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
<br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。后端发起支付请求
 <br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
<br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。return_url和notify_url
Node端详解
request发起请求
// 通过orderId向后端请求获取支付宝支付参数alidata var alipayUrl = 'https://mapi.alipay.com/gateway.do?'+ alidata; request.get({url: alipayUrl},function(error, response, body){ res.send(response.body); });
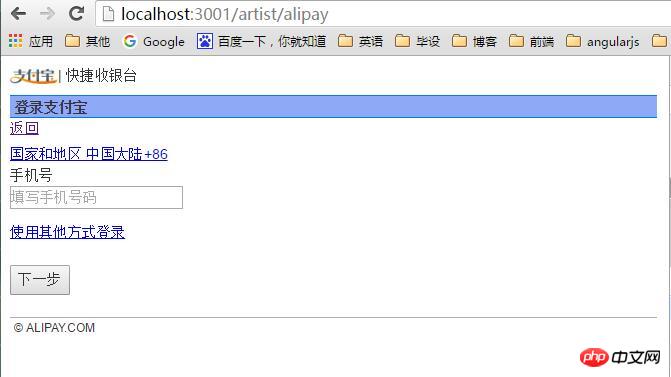
request.get({url: alipayUrl},function(error, response, body){
var str = response2.body;
str = str.replace(/gb2312/, "utf-8");
res.setHeader('content-type', 'text/html;charset=utf-8');
res.send(str);
});表单提交请求
Node端
// node端 // 通过orderId向后端请求获取支付宝支付参数alidata function getArg(str,arg) { var reg = new RegExp('(^|&)' + arg + '=([^&]*)(&|$)', 'i'); var r = str.match(reg); if (r != null) { return unescape(r[2]); } return null; } var alipayParam = { _input_charset: getArg(alidata,'_input_charset'), body: getArg(alidata,'body'), it_b_pay: getArg(alidata, 'it_b_pay'), notify_url: getArg(alidata, 'notify_url'), out_trade_no: getArg(alidata, 'out_trade_no'), partner: getArg(alidata, 'partner'), payment_type: getArg(alidata, 'payment_type'), return_url: getArg(alidata, 'return_url'), seller_id: getArg(alidata, 'seller_id'), service: getArg(alidata, 'service'), show_url: getArg(alidata, 'show_url'), subject: getArg(alidata, 'subject'), total_fee: getArg(alidata, 'total_fee'), sign_type: getArg(alidata, 'sign_type'), sign: getArg(alidata, 'sign'), app_pay: getArg(alidata, 'app_pay') }; res.render('artist/alipay',{ // 其他参数 alipayParam: alipayParam });html
<!--alipay.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>支付宝支付</title> </head> <body>
<form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get">
<input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>">
<input type="hidden" name="body" value="<%= alipayParam.body%>">
<input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>">
<input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>">
<input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>">
<input type="hidden" name="partner" value="<%= alipayParam.partner%>">
<input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>">
<input type="hidden" name="return_url" value="<%= alipayParam.return_url%>">
<input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>">
<input type="hidden" name="service" value="<%= alipayParam.service%>">
<input type="hidden" name="show_url" value="<%= alipayParam.show_url%>">
<input type="hidden" name="subject" value="<%= alipayParam.subject%>">
<input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>">
<input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>">
<input type="hidden" name="sign" value="<%= alipayParam.sign%>">
<input type="hidden" name="app_pay" value="<%= alipayParam.app_pay%>">
</form> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/alipay.js?v=2016052401"></script>
</body>
</html>
js
// alipay.js seajs.use(['zepto'],function($){
var index = {
init:function(){
var self = this;
this.bindEvent();
},
bindEvent:function(){
var self = this;
$('#ali-form').submit();
}
}
index.init();
});小结
 <br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
<br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。错误排查
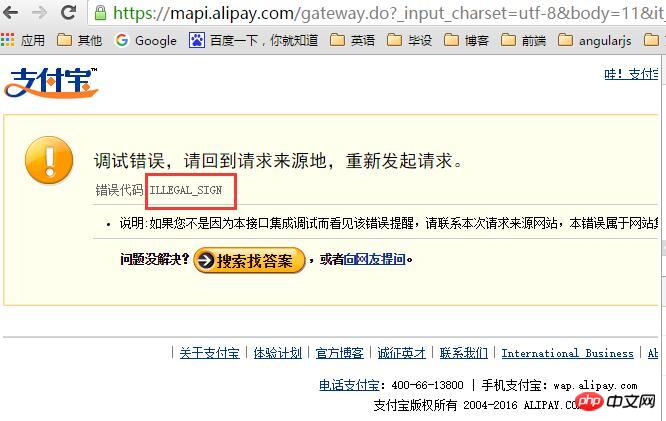 <br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
<br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。微信屏蔽支付宝
问题描述

完美解决办法
Node端
res.render('artist/alipay',{ alipayParam: alipayParam, param: urlencode(alidata) });html
<input type="hidden" id="param" value="<%= param%>"> <iframe id="payFrame" name="mainIframe" src="" frameborder="0" scrolling="auto" ></iframe>
js
var iframe = document.getElementById('payFrame'); var param = $('#param').val(); iframe.src='https://mapi.alipay.com/gateway.do?'+param;
报错
官方解决办法
html
<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <p class="wrapper buy-wrapper" style="max-width:90%"> <a href="javascript:void(0);" class="J-btn-submit btn mj-submit btn-strong btn-larger btn-block">确认支付</a> </p> </form> <input type="hidden" id="param" value="<%= param%>"> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/ap.js"></script> <script> var btn = document.querySelector(".J-btn-submit"); btn.addEventListener("click", function (e) { e.preventDefault(); e.stopPropagation(); e.stopImmediatePropagation(); var queryParam = ''; Array.prototype.slice.call(document.querySelectorAll("input[type=hidden]")).forEach(function (ele) { queryParam += ele.name + "=" + encodeURIComponent(ele.value) + '&'; }); var gotoUrl = document.querySelector("#ali-form").getAttribute('action') + '?' + queryParam; _AP.pay(gotoUrl); return false; }, false); btn.click(); </script> </body> </html>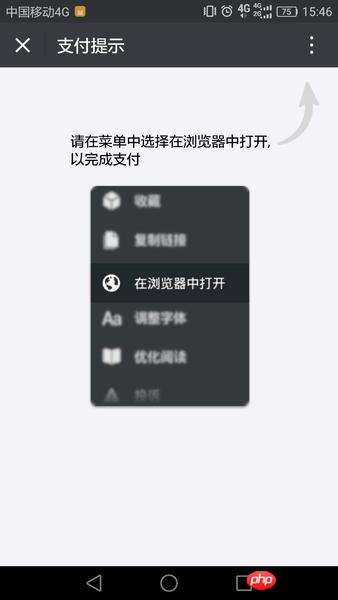
后记
ブックマーク
25. 高い同時実行性、大規模なトラフィック 今日のトラフィックの多い Web サイトでは、1 日に数千、さらには数億のトラフィックの問題を解決するにはどうすればよいでしょうか
<br/>
26. mysqlとnosqlの違い
NoSQL またはリレーショナル データベース
バックエンド構造のサービス化概要
構造化データ (つまり、データベースに格納される行データ) と比較して、実装されたデータは 2 次元のテーブル構造を使用して論理的に表現できます。 , データベース内の2次元の論理テーブルで表現できないデータは非構造化データと呼ばれ、オフィス文書、テキスト、画像、XML、HTML、各種レポート、画像、音声・映像情報などあらゆる形式が含まれます。 非構造化データベースとは、フィールド長が可変のデータベースを指し、各フィールドのレコードは反復可能または反復不可能なサブフィールドで構成でき、構造化データ (数値、記号、その他の情報など) を処理できるだけではありません。非構造化データ (全文テキスト、画像、音声、映画、ハイパーメディア、その他の情報) の処理に適しています。 非構造化WEBデータベースは、主に非構造化データを対象として生成されており、過去に普及していたリレーショナルデータベースと比較して、その最大の違いは、変更が容易ではないリレーショナルデータベースの構造定義の限界を突破し、データの固定長をサポートしていることです。連続情報(全文情報を含む)や非構造化情報(各種マルチメディアを含む)の処理において、繰り返しフィールド、サブフィールド、可変長フィールドを統合し、可変長データ、繰り返しフィールドの処理とデータ項目の可変長格納管理を実現します。 information) 従来のリレーショナル データベースにはない利点があります。 構造化データ: 2次元テーブル(リレーショナル)
半構造化データ: ツリー、グラフ データ分類
半構造化データ(半構造化データ)
構造化データ
非構造化データ
半構造化データ
储存方式
化解为结构化数据
用XML格式来组织并保存到CLOB字段中
28. 单链表翻转
单链表反转总结篇
1 定义
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}2 方法1:就地反转法
2.1 思路
2.2 解释
1初始状态
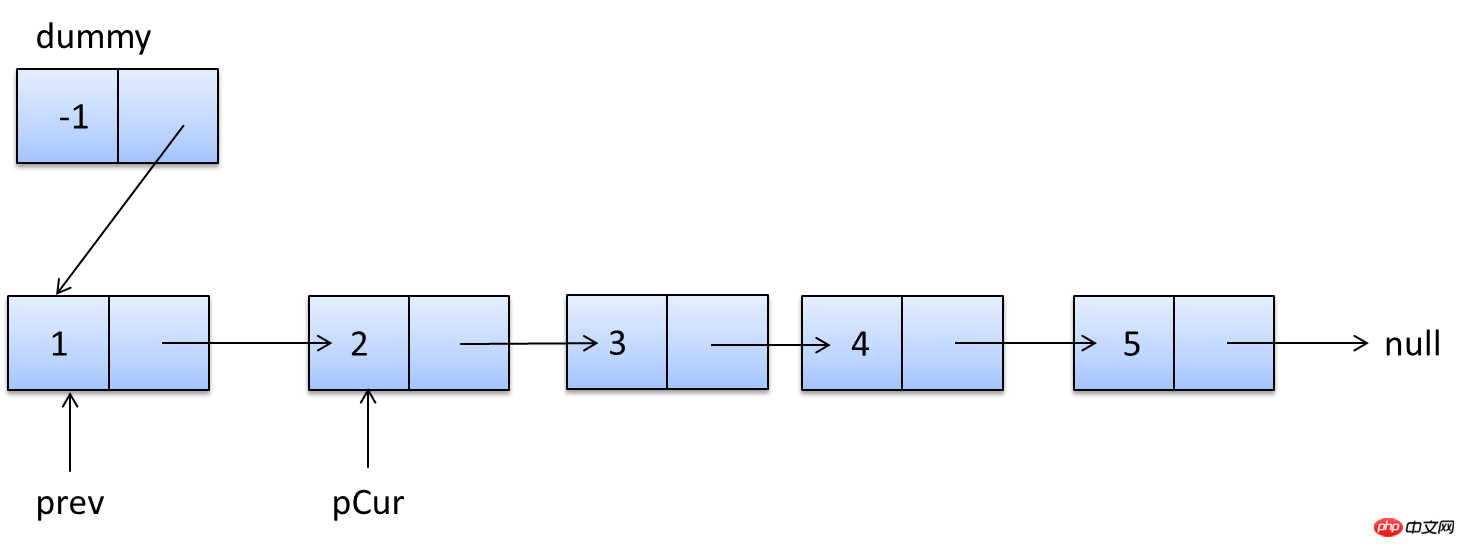
2 过程
1 prev.next = pCur.next;
2 pCur.next = dummy.next;
3 dummy.next = pCur;
4 pCur = prev.next;
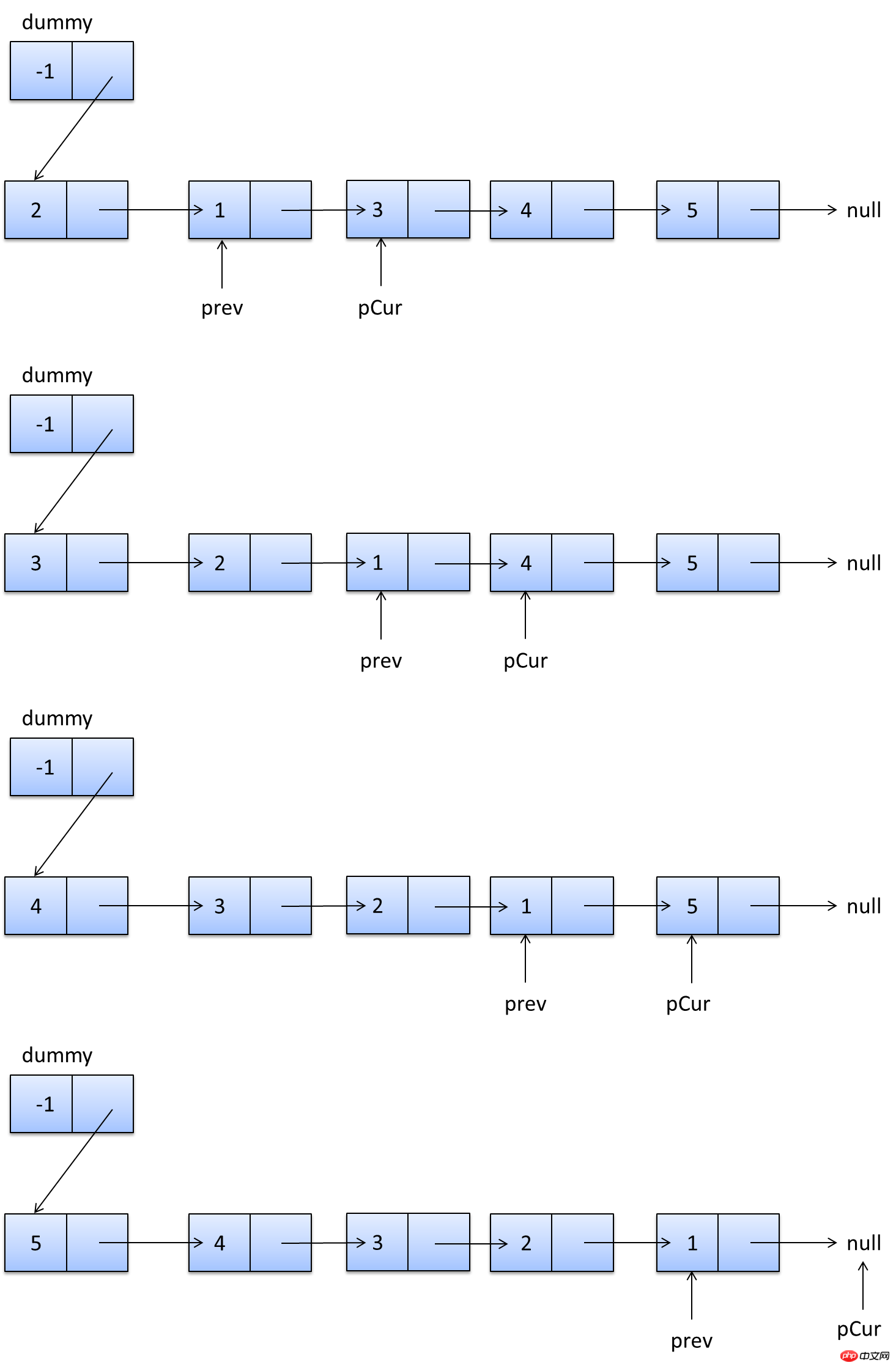
3 循环条件
pCur is not null
2.3 代码
1 // 1.就地反转法
2 public ListNode reverseList1(ListNode head) {
3 if (head == null)
4 return head;
5 ListNode dummy = new ListNode(-1);
6 dummy.next = head;
7 ListNode prev = dummy.next;
8 ListNode pCur = prev.next;
9 while (pCur != null) {
10 prev.next = pCur.next;
11 pCur.next = dummy.next;
12 dummy.next = pCur;
13 pCur = prev.next;
14 }
15 return dummy.next;
16 }2.4 总结
3 方法2:新建链表,头节点插入法
3.1 思路
3.2 解释
1 初始状态
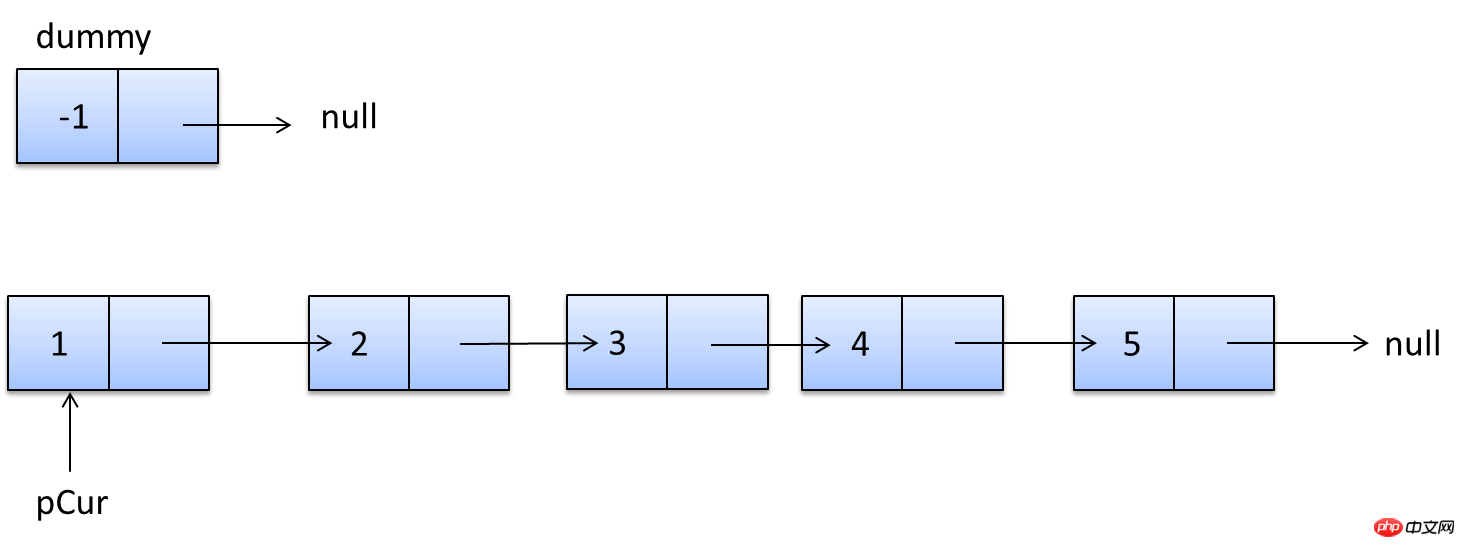
2 过程
1 pNex = pCur.next
2 pCur.next = dummy.next
3 dummy.next = pCur
4 pCur = pNex
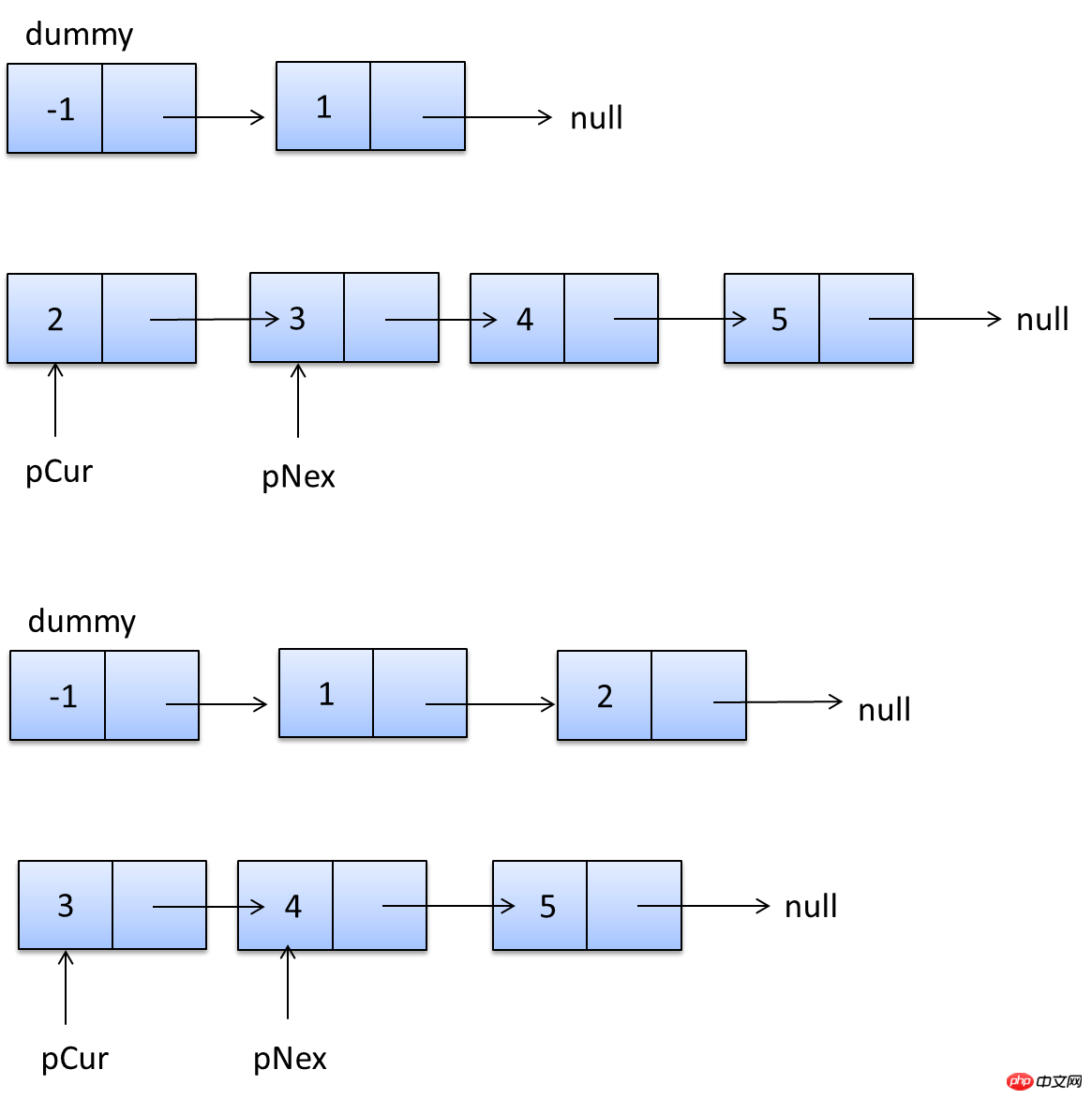
3 循环条件
pCur is not null
3.3 代码
1 // 2.新建链表,头节点插入法
2 public ListNode reverseList2(ListNode head) {
3 ListNode dummy = new ListNode(-1);
4 ListNode pCur = head;
5 while (pCur != null) {
6 ListNode pNex = pCur.next;
7 pCur.next = dummy.next;
8 dummy.next = pCur;
9 pCur = pNex;
10 }
11 return dummy.next;
12 }<br/>29. 最擅长的php
30. 索引
MySQL索引优化
一、索引类型
CREATE TABLE index_table (
id BIGINT NOT NULL auto_increment COMMENT '主键',
NAME VARCHAR (10) COMMENT '姓名',
age INT COMMENT '年龄',
phoneNum CHAR (11) COMMENT '手机号',
PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
下图是Col2为索引列,记录与B树结构的对应图,仅供参考:
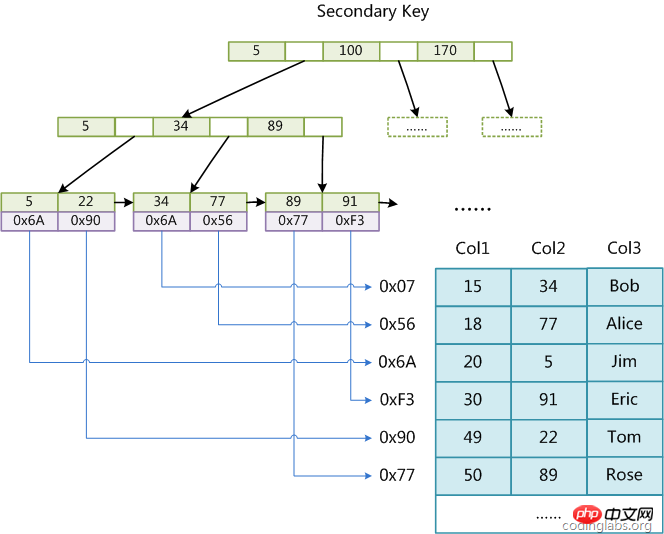
1、普通索引
------直接创建索引 create index index_name on index_table(name);
2、唯一索引
---------直接创建唯一索引 create UNIQUE index index_phoneNum on index_table(phoneNum);
3、主键
4、多列索引
-------直接创建组合索引 create index index_union on index_table(name,age,phoneNum);
二、索引优化
1、选择索引列
SELECT age----不使用索引 FROM index_union WHERE NAME = 'xiaoming'---考虑使用索引 AND phoneNum = '18668247687';---考虑使用索引
2、最左前缀原则
3、like的使用
4、不能使用索引说明
5、order by
1 select test_index where id = 3 order by id desc;1 select test_index where id = 3 order by name desc;31. モールの構造
1 電子商取引の事例が発生する理由
大規模なポータルは一般にニュース情報であり、CDN、静的化などを使用して最適化できます。Kaixin.com やその他の Web サイトはよりインタラクティブであり、より多くの NOSQL、分散キャッシュが導入され、高負荷の使用が行われる場合があります。 -speed パフォーマンス通信フレームワークなど。電子商取引 Web サイトには、上記 2 つのカテゴリの特徴があります。たとえば、商品の詳細は CDN を使用して静的にすることができますが、対話性の高い Web サイトでは NOSQL などのテクノロジを使用する必要があります。そこで、ECサイトを事例として分析します。 大型门户一般是新闻类信息,可以使用CDN,静态化等方式优化,开心网等交互性比较多,可能会引入更多的NOSQL,分布式缓存,使用高性能的通信框架等。电商网站具备以上两类的特点,比如产品详情可以采用CDN,静态化,交互性高的需要采用NOSQL等技术。因此,我们采用电商网站作为案例,进行分析。2 电商网站需求
推荐大家使用需求功能矩阵,进行需求描述。

3 网站初级架构

一般都会采用集群的方式,进行高可用设计
顧客のニーズ:
製品を受け取った後、ユーザーは製品を評価して評価できます。
要件関数マトリックスを使用して要件を記述することをお勧めします。 🎜🎜この電子商取引 Web サイトの需要マトリックスは次のとおりです: 🎜🎜🎜🎜🎜🎜上記は、電子商取引 Web サイトの要件の簡単な例です。目的は、(1) 要件を分析する際には、包括的である必要があること、および大規模な分散システムは、非機能要件に焦点を当てる必要があります。(2) 誰もが分析と設計の次のステップの基礎を持てるように、簡単な電子商取引の需要シナリオを説明します。 🎜🎜3 主要な Web サイト構造 🎜🎜一般的な Web サイトの最初のアプローチは、アプリケーションの展開に 1 台、データベースの展開に 1 台、NFS ファイル システムの展開に 1 台の 3 台のサーバーを使用することです。これは、ここ数年で比較的伝統的なアプローチであり、100,000 人以上の会員がいる、縦型の衣類デザイン ポータルと多数の写真を見た Web サイトを見てきました。サーバーは、アプリケーション、データベース、イメージ ストレージの展開に使用されます。パフォーマンス上の問題がたくさんありました。以下に示すように: 🎜🎜🎜🎜しかし、現在主流のウェブサイトのアーキテクチャは、地球を揺るがす変化を遂げています。 一般に、クラスタは高可用性設計に使用されます。少なくともこれは以下のようになります。 🎜🎜🎜🎜🎜🎜 (1) クラスターを使用してアプリケーションサーバーを冗長化し、高可用性を実現します (負荷分散装置をアプリケーションと一緒に導入できます) 🎜🎜🎜🎜 (2) データベースのマスタースタンバイモードを使用してデータのバックアップと高可用性; 🎜🎜🎜🎜4 システム容量の推定🎜🎜🎜🎜 推定手順: 🎜🎜🎜🎜🎜🎜 登録ユーザー数 - 日次平均 UV 量 - 日次同時実行量 🎜
Web サーバーによると、1 秒あたり 300 の同時計算をサポートします。通常は 10 台のサーバーが必要です (Tomcat のデフォルト構成は 150 です)
通常は約 70% のレベルを維持し、ピーク時には 90% のレベルに達します。リソースを無駄にせず、比較的安定しています。メモリとIOは似ています。 5 Web サイトのアーキテクチャ分析
系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的。内存,IO类似。5 网站架构分析
6 网站架构优化
6.1 业务拆分
根据业务属性进行垂直切分,划分为产品子系统,购物子系统,支付子系统,评论子系统,客服子系统,接口子系统(对接如进销存,短信等外部系统)。根据业务子系统进行等级定义,可分为核心系统和非核心系统。核心系统:产品子系统,购物子系统,支付子系统;非核心:评论子系统,客服子系统,接口子系统。业务拆分作用:提升为子系统可由专门的团队和部门负责,专业的人做专业的事,解决模块之间耦合以及扩展性问题;每个子系统单独部署,避免集中部署导致一个应用挂了,全部应用不可用的问题。等级定义作用:用于流量突发时,对关键应用进行保护,实现优雅降级;保护关键应用不受到影响。

6.2 应用集群部署(分布式,集群,负载均衡)
分布式部署:将业务拆分后的应用单独部署,应用直接通过RPC进行远程通信;集群部署:电商网站的高可用要求,每个应用至少部署两台服务器进行集群部署;负载均衡: 上記の見積もりに基づくと、いくつかの問題があります。 6 ウェブサイト アーキテクチャの最適化
6.1 事業分割
🎜事業属性に基づく垂直分割、製品サブシステム、ショッピング サブシステム、支払いサブシステムに分割、サブシステム システム、顧客サービス サブシステム、インターフェイス サブシステム (購買、販売、在庫、SMS などの外部システムとの接続) をレビューします。 🎜🎜ビジネス サブシステムに基づくレベル定義。コア システムと非コア システムに分けることができます。コア システム: 製品サブシステム、ショッピング サブシステム、支払いサブシステム、非コア システム: レビュー サブシステム、顧客サービス サブシステム、インターフェイス サブシステム。 🎜🎜ビジネス分割の役割: サブシステムへのアップグレードは専門のチームと部門によって処理され、各サブシステム間の結合とスケーラビリティの問題を解決します。集中展開の問題により、1 つのアプリケーションがクラッシュし、すべてのアプリケーションが使用できなくなる。 🎜🎜レベル定義の役割: トラフィックバースト中に主要なアプリケーションを保護し、影響を受けることから主要なアプリケーションを保護するために使用されます。 🎜🎜分割後のアーキテクチャ図: 🎜🎜🎜🎜参考展開計画 2: 🎜🎜🎜🎜(1) 各アプリケーションは上記のように個別にデプロイされます; 🎜🎜(2) コア システムと非コア システムは組み合わせてデプロイされます; 🎜< /blockquote >
6.2 アプリケーション クラスターのデプロイメント (分散、クラスター化、ロード バランシング)
🎜分散デプロイメント: 事業分割後のアプリケーションを個別にデプロイし、アプリケーションは RPC リモート通信を通じて直接実行されます。 ; 🎜🎜クラスター展開:電子商取引 Web サイトの高可用性要件。各アプリケーションはクラスター展開のために少なくとも 2 つのサーバーを展開します。🎜🎜負荷分散: は高可用性です。システムが負荷分散を通じて一般アプリケーションの高可用性を実現し、分散サービスで組み込みの負荷分散を通じて高可用性を実現し、リレーショナル データベースでアクティブおよびバックアップ方式によって高可用性を実現するために必要です。 🎜🎜クラスター展開後のアーキテクチャ図:🎜
6.3 マルチレベルキャッシュ
に応じて、ローカル キャッシュと分散キャッシュ の 2 つのタイプに分類できます。このケースでは、2次キャッシュ方式を使用してキャッシュを設計します。一次キャッシュはローカル キャッシュ、二次キャッシュは分散キャッシュです。 (より細分化されたページ キャッシュ、フラグメント キャッシュなどもあります) 一般可分为两类本地缓存和分布式缓存。本案例采用二级缓存的方式,进行缓存的设计。一级缓存为本地缓存,二级缓存为分布式缓存。(还有页面缓存,片段缓存等,那是更细粒度的划分)一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存。当一级缓存过期或不可用时,访问二级缓存的数据。如果二级缓存也没有,则访问数据库。
6.4 单点登录(分布式Session)
一般可采用Session同步,Cookies,分布式Session方式。电商网站一般采用分布式Session实现。
6.5 数据库集群(读写分离,分库分表)
高可用,高性能一般采用冗余的方式进行系统设计。一般有两种方式读写分离和分库分表。读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
6.6 服务化
将多个子系统公用的功能/模块,进行抽取,作为公用服务使用。比如本案例的会员子系统就可以抽取为公用的服务。
6.7 消息队列
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统レベル 1 キャッシュ、キャッシュ データ ディクショナリ、一般的に使用されるホットスポット データおよびその他の基本的に不変/定期的に変更される情報、レベル 2キャッシュ キャッシュ すべてのキャッシュが必要です。 1 次キャッシュの有効期限が切れたり、使用できなくなったりすると、2 次キャッシュ内のデータがアクセスされます。 2 次キャッシュがない場合は、データベースにアクセスします。 
一般に、セッション同期、Cookie、および分散セッション メソッドを使用できます。電子商取引 Web サイトは通常、分散セッションを使用して実装されます。 🎜🎜さらに一歩進んで、分散セッションに基づいた完全なシングル サインオンまたはアカウント管理システムを確立することができます。 🎜🎜🎜 🎜プロセスの説明: 🎜🎜🎜(1) ユーザーが初めてログインするとき、ユーザー ID をキーとして使用するなど、セッション情報 (ユーザー ID とユーザー情報) が分散セッション 🎜🎜 に書き込まれます。 (2) ユーザーは再度ログインします。ログイン時に、分散セッションを取得してセッション情報があるかどうかを確認します。ない場合は、ログイン ページに移動します。通常は、キャッシュ ミドルウェアを使用して実装されます。 Redis には、分散セッションのダウンタイムを容易にする永続化機能があります。その後、セッション情報を永続ストレージからロードできます。 (4) セッションを保存するときに、セッションの保持時間を設定できます。 🎜🎜🎜 キャッシュミドルウェアと組み合わせると、分散セッションはセッションセッションを非常にうまくシミュレートできます。 🎜🎜6.5 データベースクラスター (読み取りと書き込み、サブデータベースとサブテーブルの分離)🎜🎜 大規模な Web サイトでは、大規模なデータストレージ、高可用性、高パフォーマンスを実現するために、大量のデータを保存する必要があります。通常、冗長システム設計を使用します code>。 一般に、読み取りと書き込み、サブデータベースとテーブルを分離するには 2 つの方法があります。 🎜🎜読み取りと書き込みの分離: 一般に、読み取り率が書き込み率よりはるかに大きいシナリオを解決するには、1 つのプライマリと 1 つのスタンバイ、1 つのプライマリと複数のスタンバイ、または複数のプライマリと複数のスタンバイを使用できます。 。 🎜🎜このケースは、データベースとテーブルのサブデータベース、読み書きの分離と組み合わせた事業分割に基づいています。以下に示すように: 🎜🎜🎜🎜🎜 (1) 事業分割後: 各サブシステムには個別のライブラリが必要です。🎜🎜 (2) 個別のライブラリが大きすぎる場合は、商品分類ライブラリなど、事業特性に応じて再度ライブラリに分割できます。 、製品ライブラリ; 🎜🎜 (3) データベースを分割した後、テーブルに大量のデータがある場合、テーブルは ID や時間などに基づいて分割されます。高度な使用法は一貫しています ハッシュ) 🎜🎜( 4) サブライブラリとサブテーブルに基づいて読み取りと書き込みを分離します 🎜🎜🎜 関連するミドルウェアは Cobar (Alibaba、現在は保守されていません)、TDDL (Alibaba) を参照できます。 Atlas (Qihoo 360)、MyCat (Based on Cobar、中国には優秀な人材が多く、中国初のオープンソースプロジェクトとして知られています)。 🎜🎜データベースとテーブルのシャーディング後のシーケンスの問題、JOIN、トランザクションの問題は、シャーディング データベースとテーブルのテーマ共有で紹介されます。 🎜🎜6.6 サービス化🎜🎜複数のサブシステムに共通する機能/モジュールを抽出し、パブリックサービスとして使用します。たとえば、この場合のメンバーシップ サブシステムは公共サービスとして抽出できます。 🎜🎜🎜 🎜6.7 メッセージキュー🎜🎜メッセージキューは、サブシステム/モジュール間の結合を解決し、非同期、高可用性、高性能システムを実現できます。これは分散システムの標準構成です。この場合、メッセージ キューは主にショッピングと配送のリンクで使用されます。 🎜🎜🎜(1) ユーザーが注文すると、メッセージキューに書き込まれ、クライアントに直接返されます 🎜🎜(2) 在庫サブシステム: メッセージキュー情報を読み取り、在庫削減を完了します 🎜🎜(3)分散サブシステム: メッセージ キュー情報を読み取って配信します 🎜🎜🎜🎜🎜建议可以研究下Rabbit MQ。6.8 其他架构(技术)
应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。7 架构总结

32. app
34. AB
前沿
--PV(访问量):Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。 --UV(独立访客):Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。 --IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
安装
ab的基本参数
-c 并发的请求数 -n 要执行的请求总数 -k 启用keep-alive功能(开启的话,请求会快一些) -H 一个使用冒号分隔的head报文头的附加信息 -t 执行这次测试所用的时间
ab基本语法
ab -c 5 -n 60 -H "Referer: http://baidu.com" -H "Connection: close" http://blog.csdn.net /XXXXXX/article/details/XXXXXXX
ab -c 100 -n 100 -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:3 8.0) Gecko/20100101 Firefox/38.0" -e "E:\ab.csv" http://blog.csdn.net/uxxxxx/artic le/details/xxxx
ab执行结果分析

总结
linux 下ab压力测试
 <br/>
<br/>35. スロークエリ
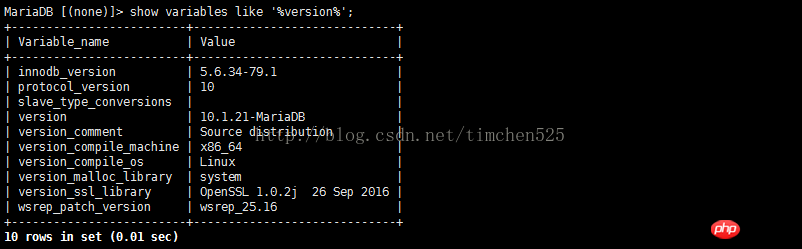 <br/>
<br/> <br/>
<br/> <br/>
<br/> <br/>
<br/>  <br/>
<br/>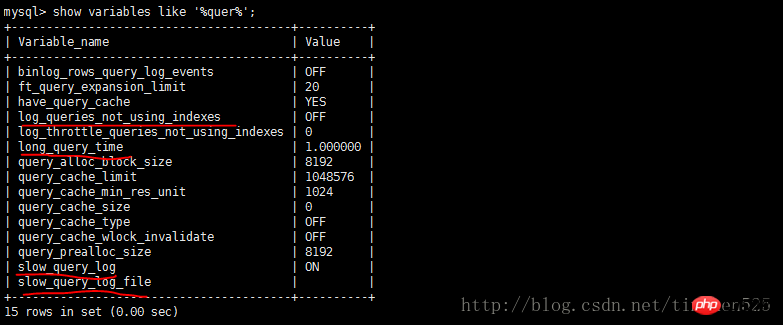 の値は、ファイルに記録されるスロー クエリ ログです (<br/>注:
の値は、ファイルに記録されるスロー クエリ ログです (<br/>注:  <br/>
<br/> <br/>
<br/>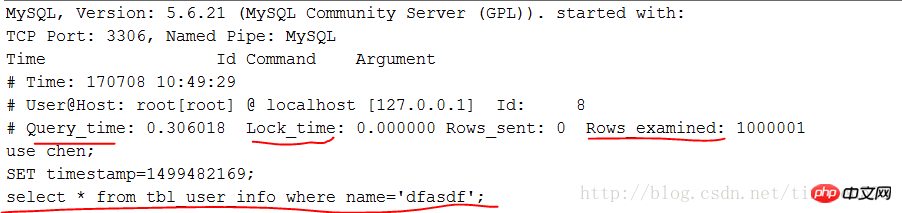 <br/>
<br/>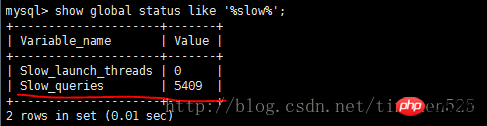 <br/>
<br/> <br/>上記のパラメータは次の意味を持ちます:
<br/>上記のパラメータは次の意味を持ちます: フレームワークオープンソースフレームワーク(TP、CI、Laravel、Yii)
2017年7月10日 13時36分47秒
37. 命名空间
PHP命名空间 namespace 及导入 use 的用法
<?php
echo 111;
//由于namespace前有代码而报错
namespace Teacher;
class Person{
function __construct(){
echo 'Please study!';
}
}<?php
namespace Newer;
require_once './1.php';
new Person();
//报错,找不到Person;
new \Person();
//输出 I am tow!;
<?php
namespace New;
require_once './2.php';
new Person();
//报错,(当前空间)找不到
Person; new \Person();
//报错,(公共空间)找不到
Person; new \Two\Person();
//输出 I am tow!;
namespace School\Parents;
class Man{
function __construct(){
echo 'Listen to teachers!<br/>';
}
}
namespace School\Teacher;
class Person{
function __construct(){
echo 'Please study!<br/>';
}
}
namespace School\Student;
class Person{
function __construct(){
echo 'I want to play!<br/>';
}
}
new Person();
//输出I want to play!
new \School\Teacher\Person();
//输出Please study!
new Teacher\Person();
//报错 ----------
use School\Teacher;
new Teacher\Person();
//输出Please study! ----------
use School\Teacher as Tc;
new Tc\Person();
//输出Please study! ----------
use \School\Teacher\Person;
new Person();
//报错 ----------
use \School\Parent\Man;
new Man();
//报错
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



