

Pythonデータマイニングの詳細な分析 Json構造分析

この記事は、Python データマイニングと Json 構造分析の関連知識ポイントを例を通じて分析してまとめています。これに興味のある友人は参照してください。

jsonは、構成ファイル形式とも言える軽量のデータ交換形式です

この形式のファイルは、データ処理でよく遭遇するものです
pythonは、組み込みモジュールを提供しますjson は使用前にインポートするだけです
ヘルプ機能を使用して json のヘルプドキュメントを表示できます

json の一般的に使用されるメソッドには、load、loads、dump、dumps が含まれます。これらはすべて次のメソッドに属します。私はPythonの初心者なので、あまり説明しません
jsonはデータベースと組み合わせて使用でき、将来大量のデータを処理するときに非常に役立ちます
ここで、データマイニングを正式に使用して、 jsonファイルを処理します
現在、多くのWebサイトがAjaxを使用しているため、一般にXHRファイルが多いです
ここでは地図Webサイトを使用してデモンストレーションしたいと思います
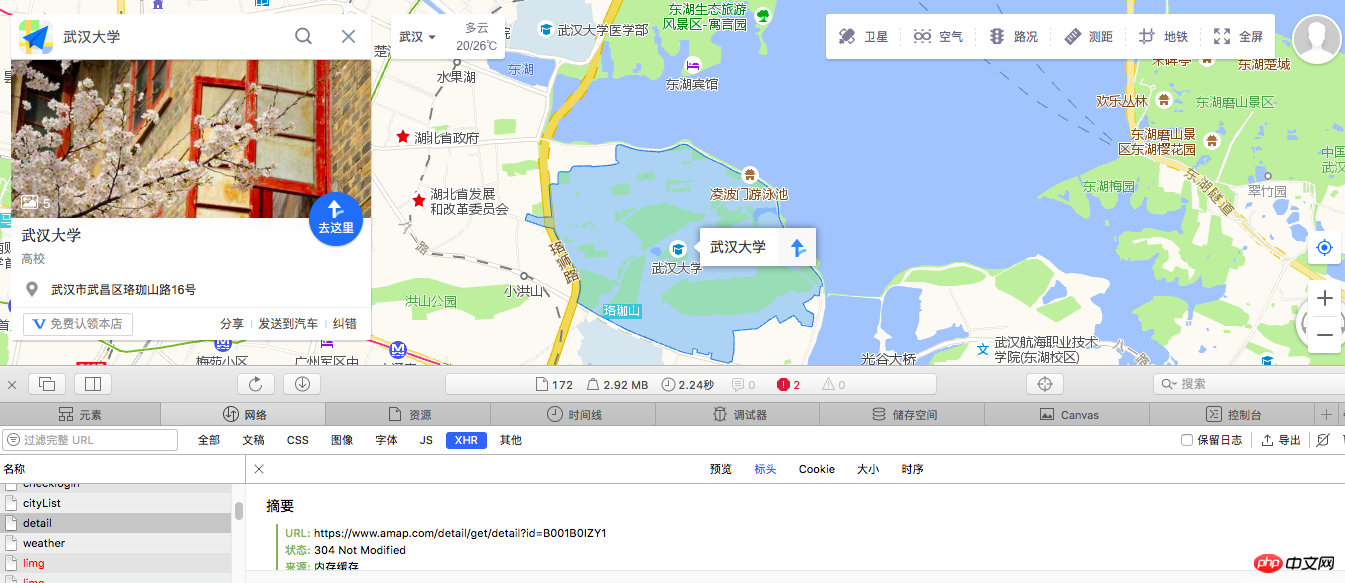
ブラウザのデバッグを通じて関連するURLを取得しました
https:/ /ditu.amap.com/service/ poiInfo?id=B001B0IZY1&query_type=IDQ
以下では、requests モジュールの get メソッドを使用して、ブラウザーによって発行された http リクエストをシミュレートし、結果オブジェクトを返します
コードは次のとおりです
# coding=utf-8 __Author__ = "susmote" import requests url = "https://ditu.amap.com/service/poiInfo?id=B001B0IZY1&query_type=IDQ" resp = requests.get(url) print(resp.text[0:200])
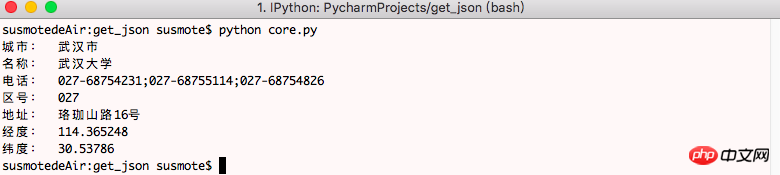
結果をターミナルで実行すると以下のようになります

データは取得できましたが、次にこのデータを利用するためにはjsonモジュールを使ってデータを解析する必要があります
コードは次のとおりです
import requests import json url = "https://ditu.amap.com/service/poiInfo?id=B001B0IZY1&query_type=IDQ" resp = requests.get(url) json_dict = json.loads(resp.text) print(type(json_dict)) print(json_dict.keys())
上記のコードについて簡単に説明します:
jsonモジュールをインポートし、loadsメソッドを呼び出し、返されたテキストをメソッドのパラメータとして渡します
ターミナルでの実行結果は以下の通りです

type (json_dict) は
オブジェクトは辞書であるため、ここで、keys メソッドを呼び出します
結果は、status、searcOpt、data という 3 つのキーを返します
data キーのデータを確認してみましょう
import requests import json url = "https://ditu.amap.com/service/poiInfo?id=B001B0IZY1&query_type=IDQ" resp = requests.get(url) json_dict = json.loads(resp.text) print(json_dict['data'])
このコードをターミナルで実行してください
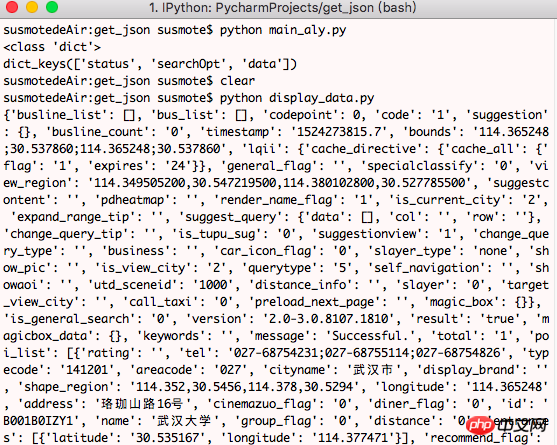
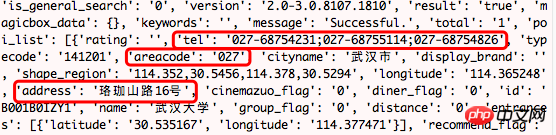
など、必要なデータがたくさんあることがわかります。データを 1 つずつマークするのではなく、Web ページに表示されているものと比較することで、どれが役立つかを知ることができます。
これで、コードを通じて有用な情報を取得し、それを明確に出力します
# coding=utf-8 __Author__ = "susmote" import requests import json url = "https://ditu.amap.com/service/poiInfo?id=B001B0IZY1&query_type=IDQ" resp = requests.get(url) json_dict = json.loads(resp.text) data_dict = json_dict['data'] data_list = data_dict['poi_list'] dis_data = data_list[0] print('城市: ', dis_data['cityname']) print('名称: ', dis_data['name']) print('电话: ', dis_data['tel']) print('区号: ', dis_data['areacode']) print('地址: ', dis_data['address']) print('经度: ', dis_data['longitude']) print('纬度: ', dis_data['latitude'])
ファイル構造の研究を通じて、辞書はリストでネストされているため、リストは辞書でネストされています。レイヤーごとのブロック解除を通じて、データは正常に取得されます
ここで手順を個別にリストしたので、より明確に確認できます
次に、ターミナルを通じてプログラムを実行して情報を取得します。とても簡単ですね
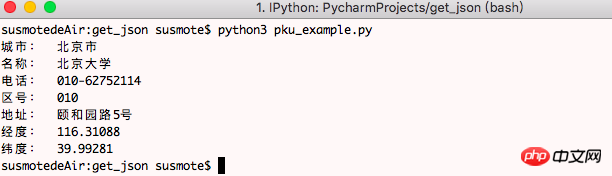
このプログラムは、他の場所から情報を取得するときに、URLを変更するだけで済みます
たとえば、次の例は北京大学です。
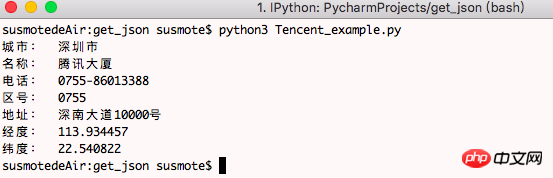
または Tencent Tower
 データマイニングに終わりはありません。皆さんがもっとデータを分析して、必要なデータを見つけられることを願っています
データマイニングに終わりはありません。皆さんがもっとデータを分析して、必要なデータを見つけられることを願っています
関連する推奨事項 :
numpy の処理方法。 Python データの中央値以上がPythonデータマイニングの詳細な分析 Json構造分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
 CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentOSシステムのPytorchデータを効率的に処理するには、次の手順が必要です。依存関係のインストール:システムを最初に更新し、Python3とPIPをインストールします。仮想環境構成(推奨):Condaを使用して、新しい仮想環境を作成およびアクティブにします。例:Condacreate-N
