

この記事では、Python3+dlib が特定のコードと手順を通じて顔認識と感情分析を実装する方法について詳しく説明します。必要な友達はそれを参照してください。
1. はじめに
私がやりたいのは、顔認識に基づく表情(感情)分析です。インターネット上にはオープン ソース ライブラリが多数あり、開発に非常に便利です。私は、顔認識と機能キャリブレーションのために、現在より頻繁に使用されている dlib ライブラリを選択しました。 Python を使用すると、開発サイクルも短縮されます。
公式 Web サイトの dlib の紹介は次のとおりです: Dlib には幅広い機械学習アルゴリズムが含まれています。すべては高度にモジュール化され、高速に実行され、クリーンで最新の C++ API を介して非常に簡単に使用できるように設計されています。ロボット、組み込みデバイス、携帯電話、大規模な高性能コンピューティング環境など、さまざまなアプリケーションで使用されています。
アプリケーションは比較的ハイエンドですが、PC 上で小さな感情分析ソフトウェアを作成するのは非常に興味深いです。
あなたのアイデアやアイデアに従って識別方法を設計してください。こちらも今大人気のKerasですが、口の形の変化を感情分析の指標として利用しているようです。
私の考えは、口の開き具合、目の開き具合、眉の傾きの角度を感情分析の3つの指標として使うことです。ただし、人によって見た目の違いが大きく、顔の特徴も多岐にわたるため、私の計算方法も比較的簡単です。そのため、認識効率はあまり高くありません。
認識ルール:
1. 顔認識フレームの幅に対する口の開口距離の比率が大きいほど、感情はより興奮し、非常に幸せであるか、または非常に怒っている可能性があります。
2. 眉が上がっている 顔認識枠の上から17-21または22-26の特徴点と認識枠の高さの比率が小さいほど、眉が強く上がっていることを意味します。驚きと喜びを表現します。眉の傾きの角度 嬉しいときは眉が上がり、怒っているときは眉をさらに強く押し下げます。
3. 目を細める。人は笑っているときは無意識に目を細め、怒ったり驚いたりすると目を大きくします。
システムの欠点: 微妙な表情の変化を捉えることができず、喜び、怒り、驚き、自然さなど、人の感情を大まかに判断することしかできません。
システムの利点: シンプルな構造で使いやすい。
応用分野: スマイルキャプチャ、瞬間の美しさのキャプチャ、子供の自閉症の緩和、インタラクティブなゲーム開発。
人間の感情は複雑であるため、これらの表現は人の心の奥底にある感情の変動を完全に表現することはできず、判断の精度を高めるためには心拍数の検出や音声処理などの総合的な評価が必要です。
2. 開発環境のセットアップ:
1. dlib-19.10 の最新バージョンにはこのバージョンの vscode が必要なので、VS2015 をインストールします。
2. opencv をインストールします (whl のインストール): pythonlibs から必要なバージョンをダウンロードします。 whl ファイル (opencv_python?3.3.0+contrib?cp36?cp36m?win_amd64.whl)
3. dlib をインストールします (whl モードのインストール):
ここから dlib の whl ファイルのさまざまなバージョンをダウンロードし、ルート ディレクトリで cmd を開いてインストールします。直接それだけです。
しかし、dlib でさまざまな Python サンプル プログラムを使用する方法を学ぶには、dlib 圧縮パッケージをダウンロードする必要があります。
dlib 公式 Web サイトに直接アクセスしてダウンロードします: http://dlib.net/ml.html
dlib のさまざまなバージョンの whl ファイル: https://pypi.python.org/simple/dlib/
4顔モデルの特徴のキャリブレーションを使用する場合は、顔の形状予測子も必要です。これは、自分の写真でトレーニングすることも、dlib の作成者 (http://dlib.net/) が提供するトレーニング済みの予測子を使用することもできます。 files/shape_predictor_68_face_landmarks.dat.bz2
3. 実装のアイデア4. 具体的な手順
import cv2
import dlib
from skimage import io
# 使用特征提取器get_frontal_face_detector
detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 图片所在路径
img = io.imread("2.jpg")
# 生成dlib的图像窗口
win = dlib.image_window()
win.clear_overlay()
win.set_image(img)
# 特征提取器的实例化
dets = detector(img, 1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
print("第", k+1, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
width = d.right() - d.left()
heigth = d.bottom() - d.top()
print('人脸面积为:',(width*heigth)) # 利用预测器预测
shape = predictor(img, d)
# 标出68个点的位置
for i in range(68):
cv2.circle(img, (shape.part(i).x, shape.part(i).y), 4, (0, 255, 0), -1, 8)
cv2.putText(img, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
# 显示一下处理的图片,然后销毁窗口
cv2.imshow('face', img)
cv2.waitKey(0)上記の判断指標に基づいて、まず口の開き率を計算し、カメラからの人物の距離により顔認識枠の大きさが異なるため、その比率を選択します。判断指標。
指標の標準値を選択する前に、幸せな顔の複数の写真を分析します。幸せなときの平均的な口の開き率を計算します。 
# 眉毛
brow_sum = 0 # 高度之和
frown_sum = 0 # 两边眉毛距离之和
for j in range(17,21):
brow_sum+= (shape.part(j).y - d.top()) + (shape.part(j+5).y- d.top())
frown_sum+= shape.part(j+5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y)
self.excel_brow_hight.append(round((brow_sum/10)/self.face_width,3))
self.excel_brow_width.append(round((frown_sum/5)/self.face_width,3))
brow_hight[0]+= (brow_sum/10)/self.face_width # 眉毛高度占比
brow_width[0]+= (frown_sum/5)/self.face_width # 眉毛距离占比
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线
self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的我计算了25个人脸的开心表情的嘴巴张开比例、嘴巴宽度、眼睛张开程度、眉毛倾斜程度,导入excel表格生成折线图:

通过折线图能很明显的看出什么参数可以使用,什么参数的可信度不高,什么参数在那个范围内可以作为一个指标。
同样的方法,计算人愤怒、惊讶、自然时的数据折线图。
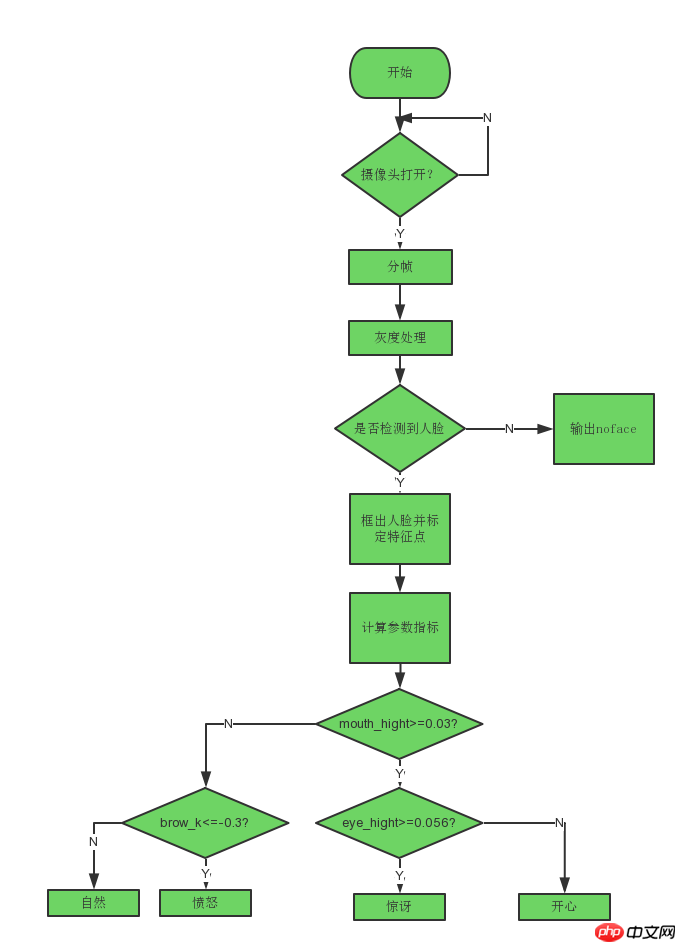
通过对多个不同表情数据的分析,得出每个指标的参考值,可以写出简单的表情分类标准:
# 分情况讨论
# 张嘴,可能是开心或者惊讶
if round(mouth_higth >= 0.03):
if eye_hight >= 0.056:
cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
# 没有张嘴,可能是正常和生气
else:
if self.brow_k <= -0.3:
cv2.putText(im_rd, "angry", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)五、实际运行效果:

识别之后:

以上がpython3+dlib は顔認識と感情分析を実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



