

図書館自習室の自動予約機能をPythonで実装

この記事では主にPythonの図書館自習室の自動予約機能について詳しく紹介しますので、興味のある方は参考にしてください
この記事はPythonの図書館自習室の自動予約機能を共有します。具体的なコードは次のとおりです。具体的な内容は次のとおりです
はじめに
現在、多くの学校は生徒に非常に優れた学習環境を提供しており、それは通常、自習教室の設備や設備に反映されています。ここで特筆すべきは、本校の図書館ですが、新図書館の建設に伴い、図書館内に複数の機能エリアがA、B、C、Dの4つのエリアに分かれて接続されました。南北の廊下がつながっており、1階から5階までは螺旋階段が通っています。エリアAは自習エリア、エリアBとCはコレクションと読書を統合した社会科学と自然科学の図書館、エリアDは映画とテレビのホール、デジタルメディアメーカー体験センター、スマートトレーニング教室などを含む特別な機能エリアです。クラウドデスクトップ電子閲覧室など、B・Cエリアの東西廊下に大小12室の学習室があり、南北廊下に読書スペースがあります。
上記の文章を図書館の公式ウェブサイトからコピーしましたが、学校図書館には本当に感謝しなければなりません。話は戻りますが、本校では教師と生徒に快適で質の高い設備の整った自習室を無料で提供しています。ただし、これらの自習室は毎日0時から翌日の予約が開始されるので、一定時間内(3時間)で予約をする必要があります。 「真夜中の油を燃やす」。もちろん、このプロセスでは手が速いことが大きな利点となります。夜早く寝て手のスピードが速くないと自習室の予約は基本的に取れません。私はたまたま最近、Python クローラーを少し学んだので、この困難なタスクを完了するためにクローラーを使用するつもりです。ハハハッハッハ! (ps: 悪意のあるアクセスを防ぐため、すべてのリンクは掲載されません)
Python実装アイデア
考えてみればアイデアは非常に単純で、アカウントにログインしてルームを検索するだけです。 、予約を送信します。それでは、試してみましょう:
アカウントにログインします
まず、自習室の予約のためのログイン インターフェースを開きます。リンクは次のとおりです: U2FsdGVkX19NdfJkghN54Msvy1zl7AucRur/ct0nz4orPI7uLkSDsvuFMgr0fGcO
rn9Z/f8h3bds9w==
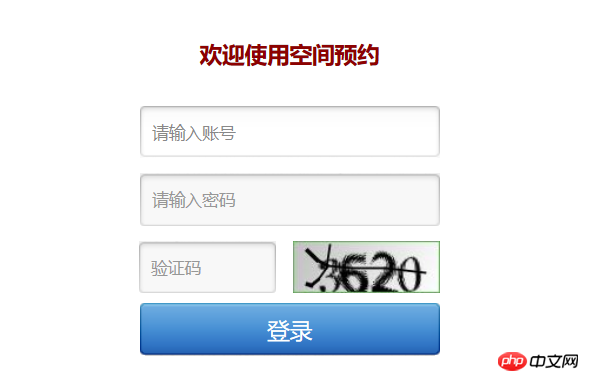
さて、最初のステップはアカウントにログインしてください。初心者の私にとっては試練ですが、臆病ではありません。他の大手が使用している方法を参考にすると、Firefox の Firebug を開いて (ctrl+shift+e) ネットワークの状況を確認し、この場合は通常のログインを実行します。

ここに投稿があることがわかり、Python で request.post メソッドを使用できるようになります。
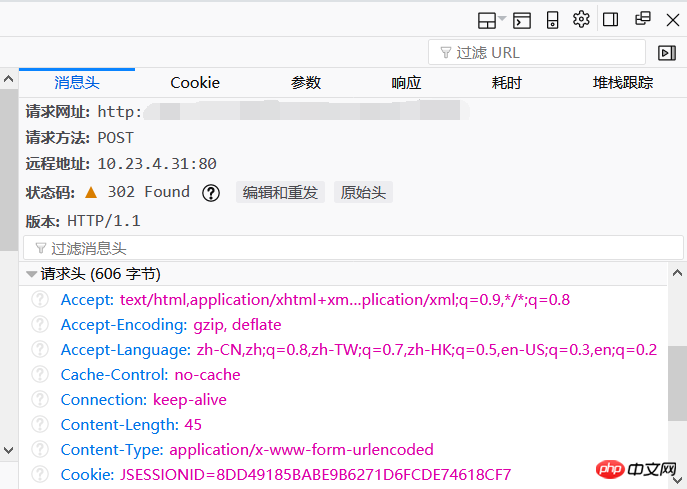
正常にログインするには、メッセージ ヘッダーで自分のアイデンティティを隠す必要があります。すべてのパラメーターをコピーして、独自のヘッダー = {…} を作成するだけです。サーバー。 。
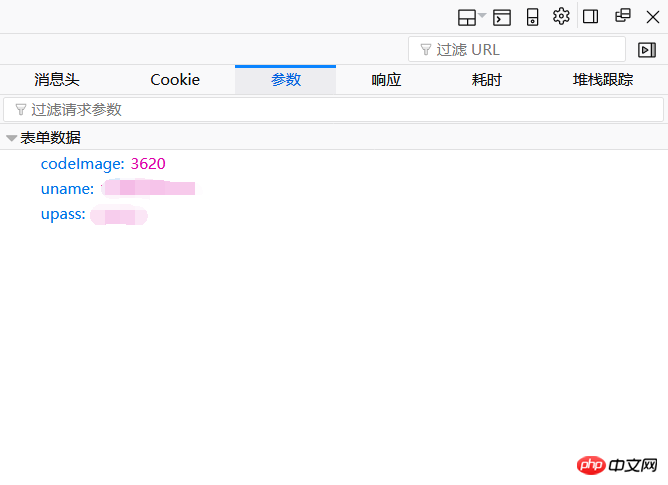
パラメータページを見てください。ここには確認コード、アカウント番号、パスワードに対応する 3 つのフォーム データしかありません。ここのパラメータをコピーしてデータ = {…} を形成します。注意が必要なのは、この検証コードが手動で認識できるか、機械によって自動的に認識されるかに関係なく、検証コードをローカル ファイルとして保存する必要があることです。その結果、サーバーにアクセスするたびに認証コードが変更されるという問題が発生します。ここで、慎重に考えてみましょう。まず、検証コードを取得してローカルに保存する必要があります。これには、最後に、ログインするためのパラメータを送信する必要があります。今回は、もう一度サーバーにアクセスします。検証 検証コードと当社が取得した検証コードは同じ検証コードではなくなりました。最初の試行では、2 つの確認コードが一致しなかったため、とにかくサーバーにログインできませんでした。初めて取得した認証コードと送信時の認証コードを一致させるにはどうすればよいですか?
ここでも同じ Cookie が必要です。上の写真では、Cookie 値があることがわかります。同期を確実に行うには、検証コードを取得したときの Cookie の値が、アカウントのパスワードを送信したときの Cookie の値と一致していることを確認する必要があります。したがって、私のプログラムでは、最初に Cookie 値を取得し、この Cookie 値をヘッダーのパラメーターとして使用します。これがログインの考え方です。ここで確認コードを手動で特定したことを付け加えておきます>﹏<。
お部屋を探す
このステップは実際には役に立たないステップですが、人間の予約習慣によれば、どのようなステップが生成されるのでしょうか? しかし、クローラーを使用すると、ログインに成功した後に予約フォームを直接送信できます。もちろん、自動予約プログラムをよりインテリジェントにしたい場合は、このステップを追加して、まだ予約できる部屋を確認し、ここにいくつかのカスタマイズされたルールを追加できます。スキップしただけです。 。 。
予約を送信する
ログインと同じように、ネットワーク状況を確認するために手動で送信することもできます。その後、Python を使用してこのプロセスをシミュレートできます。ここでは写真を使って説明しませんが、ここでも request.post メソッドを使用して送信します。ただし、ここでのヘッダーはログイン時のヘッダーとは異なるので、他の同様の予約プログラムを使用する場合は、別のコンテンツを投稿する際のヘッダーが異なるかどうかに注意してください。一貫性のある。ここでしばらく騙されました。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : 2018/4/10
# @Author : 圈圈烃
# @File : reservation_4.py
import requests
import re
import json
import datetime
import time
def get_cookies():
"""获得cookies"""
url = 'http://**************'
s = requests.session()
s.get(url)
ck_dict = requests.utils.dict_from_cookiejar(s.cookies) # 将jar格式转化为dict
ck = 'JSESSIONID=' + ck_dict['JSESSIONID'] # 重组cookies
"""获得二维码"""
path = './code.png'
get_cookies_headers = {
'user-anget': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Cookie': ck}
get_cookies_url = 'http://**************'
code_image = requests.get(get_cookies_url, headers=get_cookies_headers)
with open(path, 'wb') as fn:
fn.write(code_image.content)
fn.close()
print('验证码保存成功')
return ck
def login(cookies, hour, minute):
login_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '45',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
login_url = 'http://**************'
login_data = {
'codeImage': input('请输入验证码:'),
'uname': '**************',
'upass': '**************'
}
requests.post(login_url, data=login_data, headers=login_headers)
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
value_h = re.findall(reg_h, res.text)
"""定时"""
counter = 0
while (True):
now = datetime.datetime.now() # 获取当前系统时间
if now.hour == hour and now.minute == minute:
break
time.sleep(0.5)
# print(now)
counter = counter + 1
if counter == 240:
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
reg_t = r'(\d{4}-\d{2}-\d{2})' # 匹配可提供预约的日期
value_h = re.findall(reg_h, res.text)
value_t = re.findall(reg_t, res.text)
with open('./con_log.txt', 'a') as fjs:
fjs.write(eval(value_h[-1])+' '+value_t[-1]+' '+str(now)+' \n')
fjs.close()
print('保存成功')
counter = 0
return str(eval(value_h[-1]))
def reservation(day_hash, cookies, stime, etime):
reservation_data = {
'_etime': etime, # 结束时间11点,其值为11*60=660
'_roomid': '1285b3ca77594b3095c7b89d4922553c', # 房间Id
'_seatno': '',
'_stime': stime, # 开始时间8点,其值为8*60=480
'_subject': '学习', # 研讨主题
'_summary': '学习', # 研讨大纲
'ruleId': day_hash,
'usercount': 3, # 预约人数
'users': '**************', # 学号
'UUID': '**************'
}
reservation_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/json',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
reservation_js = json.dumps(reservation_data)
reservation_url = 'http://**************'
status = requests.post(reservation_url, data=reservation_js, headers=reservation_headers)
# print(stime, etime)
# print(status)
print(status.text)
def main():
"""预约策略一:11:20-20.40"""
full_stime = ['1060', '870', '680']
full_etime = ['1240', '1050', '860']
"""预约策略二:10:00-13:00;13:50-16:50;17:40-20:40"""
stime = ['1060', '830', '600']
etime = ['1240', '1010', '780']
cookies = get_cookies()
day_hash = login(cookies, 0, 0) # 设定定时时间
for i in range(0, 3):
reservation(day_hash, cookies, stime[i], etime[i])
if __name__ == '__main__':
main()結果を出す
私がPythonを学んでから、母は私が勉強部屋を確保できないことを心配する必要がなくなりました。プログラムに数行のタイミング手順を追加すると、00:00に私の自習室を自動的に予約できます。実験の結果、例えば4日から12日までの3時間帯では予約に7秒かかっていましたが、4日から13日はかなり予約が可能であることが分かりました。実際にかかった時間は 21 秒でした。ある時、私は他のクラスメートに誘われました。もちろん、「手の速さ」に完全勝利するには、このプログラムにはまだまだ改良が必要です。
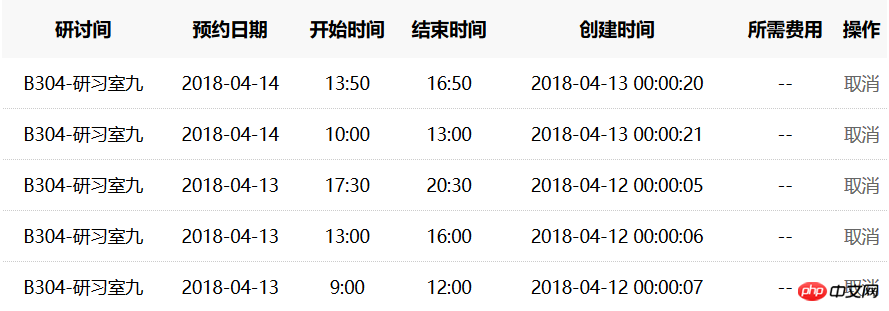
最後に追加してください
何か不足がある場合は、連絡を歓迎します。
関連する推奨事項:
Python でキャンパスネットワークへの自動ログインを実現
以上が図書館自習室の自動予約機能をPythonで実装の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
82
11
21
76
15
1378
52
82
11
21
76

 PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPおよびPython:コードの例と比較
Apr 15, 2025 am 12:07 AM
PHPとPythonには独自の利点と短所があり、選択はプロジェクトのニーズと個人的な好みに依存します。 1.PHPは、大規模なWebアプリケーションの迅速な開発とメンテナンスに適しています。 2。Pythonは、データサイエンスと機械学習の分野を支配しています。
 Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
Dockerの原則の詳細な説明
Apr 14, 2025 pm 11:57 PM
DockerはLinuxカーネル機能を使用して、効率的で孤立したアプリケーションランニング環境を提供します。その作業原則は次のとおりです。1。ミラーは、アプリケーションを実行するために必要なすべてを含む読み取り専用テンプレートとして使用されます。 2。ユニオンファイルシステム(UnionFS)は、違いを保存するだけで、スペースを節約し、高速化する複数のファイルシステムをスタックします。 3.デーモンはミラーとコンテナを管理し、クライアントはそれらをインタラクションに使用します。 4。名前空間とcgroupsは、コンテナの分離とリソースの制限を実装します。 5.複数のネットワークモードは、コンテナの相互接続をサポートします。これらのコア概念を理解することによってのみ、Dockerをよりよく利用できます。
 CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentosでPytorchモデルを訓練する方法
Apr 14, 2025 pm 03:03 PM
CentOSシステムでのPytorchモデルの効率的なトレーニングには手順が必要であり、この記事では詳細なガイドが提供されます。 1。環境の準備:Pythonおよび依存関係のインストール:Centosシステムは通常Pythonをプリインストールしますが、バージョンは古い場合があります。 YumまたはDNFを使用してPython 3をインストールし、PIP:sudoyumupdatepython3(またはsudodnfupdatepython3)、pip3install-upgradepipをアップグレードすることをお勧めします。 cuda and cudnn(GPU加速):nvidiagpuを使用する場合は、cudatoolをインストールする必要があります
 CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
CentosのPytorchのGPUサポートはどのようにサポートされていますか
Apr 14, 2025 pm 06:48 PM
Pytorch GPUアクセラレーションを有効にすることで、CentOSシステムでは、PytorchのCUDA、CUDNN、およびGPUバージョンのインストールが必要です。次の手順では、プロセスをガイドします。CUDAおよびCUDNNのインストールでは、CUDAバージョンの互換性が決定されます。NVIDIA-SMIコマンドを使用して、NVIDIAグラフィックスカードでサポートされているCUDAバージョンを表示します。たとえば、MX450グラフィックカードはCUDA11.1以上をサポートする場合があります。 cudatoolkitのダウンロードとインストール:nvidiacudatoolkitの公式Webサイトにアクセスし、グラフィックカードでサポートされている最高のCUDAバージョンに従って、対応するバージョンをダウンロードしてインストールします。 cudnnライブラリをインストールする:
 Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:コミュニティ、ライブラリ、リソース
Apr 15, 2025 am 12:16 AM
PythonとJavaScriptには、コミュニティ、ライブラリ、リソースの観点から、独自の利点と短所があります。 1)Pythonコミュニティはフレンドリーで初心者に適していますが、フロントエンドの開発リソースはJavaScriptほど豊富ではありません。 2)Pythonはデータサイエンスおよび機械学習ライブラリで強力ですが、JavaScriptはフロントエンド開発ライブラリとフレームワークで優れています。 3)どちらも豊富な学習リソースを持っていますが、Pythonは公式文書から始めるのに適していますが、JavaScriptはMDNWebDocsにより優れています。選択は、プロジェクトのニーズと個人的な関心に基づいている必要があります。
 Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
Centosの下でPytorchバージョンを選択する方法
Apr 14, 2025 pm 02:51 PM
CentOSでPytorchバージョンを選択する場合、次の重要な要素を考慮する必要があります。1。CUDAバージョンの互換性GPUサポート:NVIDIA GPUを使用してGPU加速度を活用したい場合は、対応するCUDAバージョンをサポートするPytorchを選択する必要があります。 NVIDIA-SMIコマンドを実行することでサポートされているCUDAバージョンを表示できます。 CPUバージョン:GPUをお持ちでない場合、またはGPUを使用したくない場合は、PytorchのCPUバージョンを選択できます。 2。PythonバージョンPytorch
 NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NginxをCentosにインストールする方法
Apr 14, 2025 pm 08:06 PM
NGINXのインストールをインストールするには、次の手順に従う必要があります。開発ツール、PCRE-Devel、OpenSSL-Develなどの依存関係のインストール。 nginxソースコードパッケージをダウンロードし、それを解凍してコンパイルしてインストールし、/usr/local/nginxとしてインストールパスを指定します。 nginxユーザーとユーザーグループを作成し、アクセス許可を設定します。構成ファイルnginx.confを変更し、リスニングポートとドメイン名/IPアドレスを構成します。 nginxサービスを開始します。依存関係の問題、ポート競合、構成ファイルエラーなど、一般的なエラーに注意する必要があります。パフォーマンスの最適化は、キャッシュをオンにしたり、ワーカープロセスの数を調整するなど、特定の状況に応じて調整する必要があります。
 CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentosでPytorchを使用してデータ前処理を行う方法
Apr 14, 2025 pm 02:15 PM
CentOSシステムのPytorchデータを効率的に処理するには、次の手順が必要です。依存関係のインストール:システムを最初に更新し、Python3とPIPをインストールします。仮想環境構成(推奨):Condaを使用して、新しい仮想環境を作成およびアクティブにします。例:Condacreate-N
