

PyTorchのバッチトレーニングとオプティマイザーの比較の詳細な説明

この記事では、主に PyTorch バッチ トレーニングとオプティマイザーの比較について詳しく紹介します。必要な友人は参考にしてください。 PyTorch バッチ トレーニング
1. 概要
PyTorch は、バッチ トレーニング用にデータをパッケージ化するツール、DataLoader を提供します。これを使用する場合、最初にデータを torch のテンソル形式に変換し、次に torch が認識できるデータセット形式に変換して、そのデータセットを DataLoader に入れるだけです。
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
TensorDataset クラスは、サンプルとそのラベルをトーチにパッケージ化するために使用されます。 Dataset、data_tensor、および target_tensor はすべてテンソルです。
3. DataLoader コードをコピーします
コードは次のとおりです:
classtorch.utils.data.DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,num_workers=0, Collate_fn=
2. PyTorch のオプティマイザー
この実験では、最初にデータセットのセットを構築し、後で使用できるように形式を変換して DataLoader に配置します。固定構造のデフォルトのニューラル ネットワークを定義し、各オプティマイザーのニューラル ネットワークを構築します。各ニューラル ネットワークの違いはオプティマイザーのみです。学習過程での損失値を記録することで、最終的に各オプティマイザーの最適化過程を画像上に表現します。 コード実装:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()実験結果:
実験結果から、SGD の最適化効果は最悪で、SGD の改良版としては速度が非常に遅いことがわかります。 , Momentum は、RMSprop や Adam と比べてパフォーマンスが非常に優れており、最適化速度が非常に優れています。実験では、さまざまな最適化問題について、どのオプティマイザーを使用するかを決定する前に、さまざまなオプティマイザーの効果が比較されました。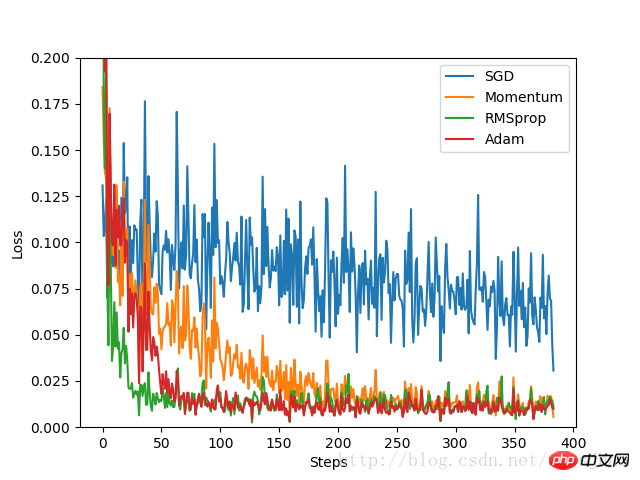
3. その他の補足
1. Pythonのzip関数
zip関数は、パラメータとして任意の数(0と1を含む)を受け取り、タプルリストを返します。
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
関連する推奨事項:
Pytorch を始めるための mnist 分類の例以上がPyTorchのバッチトレーニングとオプティマイザーの比較の詳細な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7532
7532
 15
1379
52
82
11
21
83
15
1379
52
82
11
21
83

 Xiaomi Mi 14 ProでNFC機能を有効にする方法は?
Mar 19, 2024 pm 02:28 PM
Xiaomi Mi 14 ProでNFC機能を有効にする方法は?
Mar 19, 2024 pm 02:28 PM
現在、携帯電話の高性能化・高機能化が進み、ほとんどの携帯電話にはモバイル決済や本人認証などに便利なNFC機能が搭載されています。ただし、一部の Xiaomi 14Pro ユーザーは、NFC 機能を有効にする方法がわからないかもしれません。次に詳しくご紹介していきます。 Xiaomi 14ProでNFC機能を有効にする方法は?ステップ 1: 携帯電話の設定メニューを開きます。ステップ 2: 「接続と共有」または「ワイヤレスとネットワーク」オプションを見つけてクリックします。ステップ 3: [接続と共有] または [ワイヤレスとネットワーク] メニューで、[NFC と支払い] を見つけてクリックします。ステップ 4: 「NFC スイッチ」を見つけてクリックします。通常、デフォルトはオフです。ステップ 5: NFC スイッチ ページで、スイッチ ボタンをクリックしてオンに切り替えます。
 Huawei Pocket2でTikTokをリモートで使用するにはどうすればよいですか?
Mar 18, 2024 pm 03:00 PM
Huawei Pocket2でTikTokをリモートで使用するにはどうすればよいですか?
Mar 18, 2024 pm 03:00 PM
画面の空中スライドは、Huawei mate60シリーズで高く評価されているHuaweiの機能であり、この機能は、携帯電話のレーザーセンサーとフロントカメラの3D深度カメラを使用して、画面を必要としない一連の機能を完了します。画面をタッチする機能は、たとえば、離れた場所から TikTok を使用することですが、Huawei Pocket 2 では、離れた場所から TikTok をどのように使用すればよいでしょうか? Huawei Pocket2で空中からスクリーンショットを撮るにはどうすればよいですか? 1. Huawei Pocket2 の設定を開きます。 2. [アクセシビリティ] を選択します。 3. クリックして [Smart Perception] を開きます。 4. [Air Swipe Screen]、[Air Screenshot]、[Air Press] スイッチをオンにするだけです。 5.使用するときは、画面から20〜40CM離れて立ち、手のひらを開いて、手のひらアイコンが画面に表示されるまで待つ必要があります。
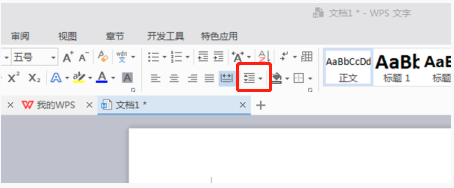 WPS Word で行間を設定して文書をきれいにする方法
Mar 20, 2024 pm 04:30 PM
WPS Word で行間を設定して文書をきれいにする方法
Mar 20, 2024 pm 04:30 PM
弊社でよく使っているオフィスソフトはWPSですが、長文の編集ではフォントが小さすぎて見づらい場合が多いので、フォントや文書全体を調整します。たとえば、文書の行間を調整すると、文書全体が非常に鮮明になります。友達全員にこの操作手順を覚えてもらうことをお勧めします。今日はそれを共有します。具体的な操作手順は次のとおりです。ぜひ見てください。調整したいWPSテキストファイルを開き、[スタート]メニューの段落設定ツールバーに小さな行間設定アイコン(図の赤丸部分)が表示されます。 2. 行間隔設定の右下隅にある小さな逆三角形をクリックすると、対応する行間隔の値が表示され、行間隔の 1 ~ 3 倍を選択できます (図の矢印で示すように)。 3. または、段落を右クリックすると、段落が表示されます。
 TrendX Research Institute: Merlin Chain プロジェクトの分析と生態学的インベントリ
Mar 24, 2024 am 09:01 AM
TrendX Research Institute: Merlin Chain プロジェクトの分析と生態学的インベントリ
Mar 24, 2024 am 09:01 AM
3月2日の統計によると、ビットコインの第2層ネットワークMerlinChainのTVL総額は30億米ドルに達した。このうち、ビットコイン環境資産は90.83%を占め、15億9600万米ドル相当のBTCと4億400万米ドル相当のBRC-20資産が含まれている。先月、マーリンチェーンの合計 TVL はステーキング活動の開始から 14 日以内に 19 億 7,000 万米ドルに達し、昨年 11 月に開始され、同じく最新で同様に目を引くブラストを上回りました。 2月26日、MerlinChainエコシステムにおけるNFTの総額は4億2,000万米ドルを超え、イーサリアムに次いでNFT市場価値が最も高いパブリックチェーンプロジェクトとなった。プロジェクトの紹介 MerlinChain は OKX サポートです
 C言語とPHPの違いと比較分析
Mar 20, 2024 am 08:54 AM
C言語とPHPの違いと比較分析
Mar 20, 2024 am 08:54 AM
C 言語と PHP の違いと比較分析 C 言語と PHP はどちらも一般的なプログラミング言語ですが、多くの点で明らかな違いがあります。この記事では、C 言語と PHP を比較分析し、具体的なコード例を通して両者の違いを説明します。 1. 構文と使用法: C 言語: C 言語はプロセス指向のプログラミング言語であり、主にシステムレベルのプログラミングと組み込み開発に使用されます。 C 言語の構文は比較的単純で低レベルであり、メモリを直接操作でき、効率的かつ柔軟です。 C言語はプログラマのプログラムの完全性を重視します
 GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
グループ化クエリ アテンション (GroupedQueryAttendant) は、大規模言語モデルにおけるマルチクエリ アテンション メソッドであり、その目標は、MQA の速度を維持しながら MHA の品質を達成することです。 GroupedQueryAttendant はクエリをグループ化し、各グループ内のクエリは同じアテンションの重みを共有するため、計算の複雑さが軽減され、推論速度が向上します。この記事では、GQAの考え方とそれをコードに変換する方法について説明します。 GQA は論文「GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint」に掲載されています
 C++ プログラムの最適化: 時間の複雑さを軽減する手法
Jun 01, 2024 am 11:19 AM
C++ プログラムの最適化: 時間の複雑さを軽減する手法
Jun 01, 2024 am 11:19 AM
時間計算量は、入力のサイズに対するアルゴリズムの実行時間を測定します。 C++ プログラムの時間の複雑さを軽減するためのヒントには、適切なコンテナー (ベクター、リストなど) を選択して、データのストレージと管理を最適化することが含まれます。クイックソートなどの効率的なアルゴリズムを利用して計算時間を短縮します。複数の操作を排除して二重カウントを削減します。条件分岐を使用して、不必要な計算を回避します。二分探索などのより高速なアルゴリズムを使用して線形探索を最適化します。
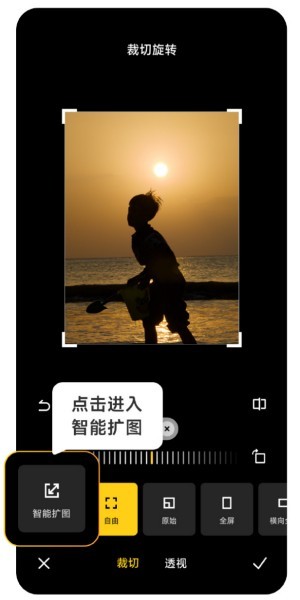 Xiaomi Mi 14 Ultra AIスマート画像拡張の使い方は?
Mar 16, 2024 pm 12:37 PM
Xiaomi Mi 14 Ultra AIスマート画像拡張の使い方は?
Mar 16, 2024 pm 12:37 PM
時代の進歩により、多くの人々の収入はますます高くなり、普段使用する携帯電話も頻繁に変更されますが、Xiaomi が最近発売した Xiaomi Mi 14 Ultra は、ユーザーにとって馴染みのあるものでしょう。快適でスムーズな体験を提供するために、新しい携帯電話には必然的に使用されない機能がたくさん出てきます。以下の使用法チュートリアルをご覧ください。 Xiaomi 14UltraAI スマート画像拡張の使用方法?まずXiaomi 14Ultraを開き、フォトアルバムに入り、拡大したい写真を選択して、フォトアルバム編集オプションに入ります。表示される選択範囲で [トリミング] [回転]、[トリミング] の順にクリックし、[スマート エキスパンド] をクリックします。最後に、自分のニーズに応じてイメージを拡張する方法を選択します。
