

PyTorch 上で回帰と分類を実装するための単純なニューラル ネットワークを構築する例

この記事では主に、回帰と分類を実装するために PyTorch 上で単純なニューラル ネットワークを構築する例を紹介します。ぜひ一緒に見てください
この記事では、PyTorch で回帰と分類を実装するための簡単なニューラル ネットワークを構築する例を紹介します。詳細は次のとおりです。 . PyTorch を始めましょう

1. インストール方法PyTorch 公式 Web サイト http://pytorch.org にログインすると、次のインターフェイスが表示されます:
オプションをクリックします。 Linux で conda コマンドを取得するには、上の図を参照してください:
conda install pytorch torchvision -c soumith
2. Numpy と Torch
torch_data = torch.from_numpy(np_data) は numpy (配列) 形式を torch (tensor) 形式に変換できます; torch_data.numpy() は torch の tensor 形式を numpy の配列形式に変換できます。 Torch の Tensor と numpy の配列はストレージ領域を共有し、一方を変更すると他方も変更されることに注意してください。 1 次元 (1-D) データの場合、numpy は行ベクトルの形式で出力を出力し、torch は列ベクトルの形式で出力を出力します。sin、cos、abs、meanなどのnumpyの他の関数もtorchで同じように使用できます。 numpy の np.matmul(data, data) と data.dot(data) の行列乗算は同じ結果をもたらすことに注意してください。torch の torch.mm(tensor, tensor) は行列乗算メソッドであり、次のようになります。行列 、 tensor.dot(tensor) は、テンソルを 1 次元のテンソルに変換し、それを要素ごとに乗算し、合計して実数を取得します。
関連コード:
import torch import numpy as np np_data = np.arange(6).reshape((2, 3)) torch_data = torch.from_numpy(np_data) # 将numpy(array)格式转换为torch(tensor)格式 tensor2array = torch_data.numpy() print( '\nnumpy array:\n', np_data, '\ntorch tensor:', torch_data, '\ntensor to array:\n', tensor2array, ) # torch数据格式在print的时候前后自动添加换行符 # abs data = [-1, -2, 2, 2] tensor = torch.FloatTensor(data) print( '\nabs', '\nnumpy: \n', np.abs(data), '\ntorch: ', torch.abs(tensor) ) # 1维的数据,numpy是行向量形式显示,torch是列向量形式显示 # sin print( '\nsin', '\nnumpy: \n', np.sin(data), '\ntorch: ', torch.sin(tensor) ) # mean print( '\nmean', '\nnumpy: ', np.mean(data), '\ntorch: ', torch.mean(tensor) ) # 矩阵相乘 data = [[1,2], [3,4]] tensor = torch.FloatTensor(data) print( '\nmatrix multiplication (matmul)', '\nnumpy: \n', np.matmul(data, data), '\ntorch: ', torch.mm(tensor, tensor) ) data = np.array(data) print( '\nmatrix multiplication (dot)', '\nnumpy: \n', data.dot(data), '\ntorch: ', tensor.dot(tensor) )
3. 変数
PyTorch のニューラル ネットワークは、Tensor のすべての操作に自動導出メソッドを提供する autograd パッケージから来ています。 autograd.Variable これは、このパッケージのコアクラスです。変数は、Tensor をラップし、Tensor 上で定義されたほぼすべての操作をサポートする、Tensor を含むコンテナーとして理解できます。操作が完了すると、.backward() を呼び出してすべての勾配を自動的に計算できます。つまり、テンソルをVariableに置くだけで、逆転送や自動導出などの演算をニューラルネットワークに実装することができます。元のテンソルには .data 属性を通じてアクセスでき、この変数の勾配は .grad 属性を通じて表示できます。
関連コード:
import torch from torch.autograd import Variable tensor = torch.FloatTensor([[1,2],[3,4]]) variable = Variable(tensor, requires_grad=True) # 打印展示Variable类型 print(tensor) print(variable) t_out = torch.mean(tensor*tensor) # 每个元素的^ 2 v_out = torch.mean(variable*variable) print(t_out) print(v_out) v_out.backward() # Variable的误差反向传递 # 比较Variable的原型和grad属性、data属性及相应的numpy形式 print('variable:\n', variable) # v_out = 1/4 * sum(variable*variable) 这是计算图中的 v_out 计算步骤 # 针对于 v_out 的梯度就是, d(v_out)/d(variable) = 1/4*2*variable = variable/2 print('variable.grad:\n', variable.grad) # Variable的梯度 print('variable.data:\n', variable.data) # Variable的数据 print(variable.data.numpy()) #Variable的数据的numpy形式
部分的な出力結果:
変数:
含まれる変数:1 2 3 4 [torch.FloatTensor of size ]
変数.grad:含まれる変数:0.5000 1.0000
1.5000 2.0000
[サイズ 2x2 の torch.FloatTensor]
variable.data:
1 2
3 4
[サイズ 2x2 の torch.FloatTensor]
[[ 1.]
[3. 4.]]
4. 励起関数活性化関数
Torch の活性化関数はすべて torch.nn.function、relu、sigmoid、tanh、softplus に含まれており、すべて一般的に使用される活性化関数です。
関連コード:
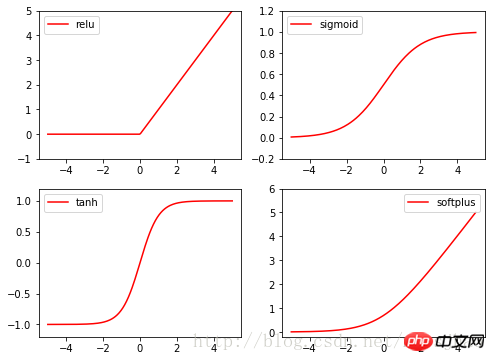
import torch import torch.nn.functional as F from torch.autograd import Variable import matplotlib.pyplot as plt x = torch.linspace(-5, 5, 200) x_variable = Variable(x) #将x放入Variable x_np = x_variable.data.numpy() # 经过4种不同的激励函数得到的numpy形式的数据结果 y_relu = F.relu(x_variable).data.numpy() y_sigmoid = F.sigmoid(x_variable).data.numpy() y_tanh = F.tanh(x_variable).data.numpy() y_softplus = F.softplus(x_variable).data.numpy() plt.figure(1, figsize=(8, 6)) plt.subplot(221) plt.plot(x_np, y_relu, c='red', label='relu') plt.ylim((-1, 5)) plt.legend(loc='best') plt.subplot(222) plt.plot(x_np, y_sigmoid, c='red', label='sigmoid') plt.ylim((-0.2, 1.2)) plt.legend(loc='best') plt.subplot(223) plt.plot(x_np, y_tanh, c='red', label='tanh') plt.ylim((-1.2, 1.2)) plt.legend(loc='best') plt.subplot(224) plt.plot(x_np, y_softplus, c='red', label='softplus') plt.ylim((-0.2, 6)) plt.legend(loc='best') plt.show()
2. PyTorch は回帰を実装します
まず完全なコードを見てください:
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # 将1维的数据转换为2维数据
y = x.pow(2) + 0.2 * torch.rand(x.size())
# 将tensor置入Variable中
x, y = Variable(x), Variable(y)
#plt.scatter(x.data.numpy(), y.data.numpy())
#plt.show()
# 定义一个构建神经网络的类
class Net(torch.nn.Module): # 继承torch.nn.Module类
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__() # 获得Net类的超类(父类)的构造方法
# 定义神经网络的每层结构形式
# 各个层的信息都是Net类对象的属性
self.hidden = torch.nn.Linear(n_feature, n_hidden) # 隐藏层线性输出
self.predict = torch.nn.Linear(n_hidden, n_output) # 输出层线性输出
# 将各层的神经元搭建成完整的神经网络的前向通路
def forward(self, x):
x = F.relu(self.hidden(x)) # 对隐藏层的输出进行relu激活
x = self.predict(x)
return x
# 定义神经网络
net = Net(1, 10, 1)
print(net) # 打印输出net的结构
# 定义优化器和损失函数
optimizer = torch.optim.SGD(net.parameters(), lr=0.5) # 传入网络参数和学习率
loss_function = torch.nn.MSELoss() # 最小均方误差
# 神经网络训练过程
plt.ion() # 动态学习过程展示
plt.show()
for t in range(300):
prediction = net(x) # 把数据x喂给net,输出预测值
loss = loss_function(prediction, y) # 计算两者的误差,要注意两个参数的顺序
optimizer.zero_grad() # 清空上一步的更新参数值
loss.backward() # 误差反相传播,计算新的更新参数值
optimizer.step() # 将计算得到的更新值赋给net.parameters()
# 可视化训练过程
if (t+1) % 10 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'L=%.4f' % loss.data[0], fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)まず、次のセットを作成しますnoisy データを 2 次関数でフィッティングし、Variable に配置します。 torch.nn.Module クラスを継承して、ニューラル ネットワークを構築するためのクラス Net を定義します。入力ニューロン、隠れ層ニューロン、出力ニューロンの数のパラメータは、Net クラスの構築メソッドで定義されます。Net 親クラスの構築メソッドは super() メソッドによって取得され、それぞれの構造形式が得られます。ネットの層は属性の形式で定義されます。定義 Net の forward() メソッドは、各層のニューロンを完全なニューラル ネットワークのフォワード パスに構築します。
Net クラスを定義した後、ニューラル ネットワークのインスタンスを定義します。Net クラスのインスタンスは、ニューラル ネットワークの構造情報を直接出力できます。次に、ニューラル ネットワークのオプティマイザーと損失関数を定義します。これらを定義したら、トレーニングを開始できます。 optimizer.zero_grad()、loss.backward()、および optimizer.step() はそれぞれ、前のステップの更新パラメーター値をクリアし、誤差の逆伝播を実行して新しい更新パラメーター値を計算し、計算された更新値をnet .parameters()。ループ反復トレーニング プロセス。実行結果:
Net (
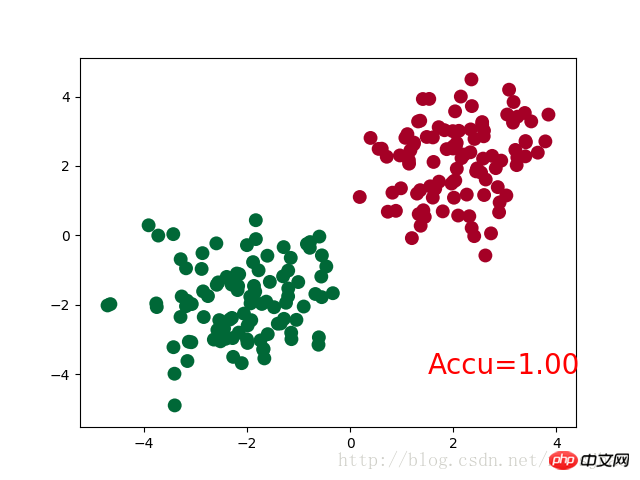
(非表示): Linear (1 -> 10) (predict): Linear (10 -> 1) ) 三、PyTorch实现简单分类 完整代码: 神经网络结构部分的Net类与前文的回归部分的结构相同。 需要注意的是,在循环迭代训练部分,out定义为神经网络的输出结果,计算误差loss时不是使用one-hot形式的,loss是定义在out与y上的torch.nn.CrossEntropyLoss(),而预测值prediction定义为out经过Softmax后(将结果转化为概率值)的结果。 运行结果: Net ( (hidden): Linear (2 -> 10) (out):Linear (10 -> 2) ) 四、补充知识 1. super()函数 在定义Net类的构造方法的时候,使用了super(Net,self).__init__()语句,当前的类和对象作为super函数的参数使用,这条语句的功能是使Net类的构造方法获得其超类(父类)的构造方法,不影响对Net类单独定义构造方法,且不必关注Net类的父类到底是什么,若需要修改Net类的父类时只需修改class语句中的内容即可。 2. torch.normal() torch.normal()可分为三种情况:(1)torch.normal(means,std, out=None)中means和std都是Tensor,两者的形状可以不必相同,但Tensor内的元素数量必须相同,一一对应的元素作为输出的各元素的均值和标准差;(2)torch.normal(mean=0.0, std, out=None)中mean是一个可定义的float,各个元素共享该均值;(3)torch.normal(means,std=1.0, out=None)中std是一个可定义的float,各个元素共享该标准差。 3. torch.cat(seq, dim=0) torch.cat可以将若干个Tensor组装连接起来,dim指定在哪个维度上进行组装。 4. torch.max() (1)torch.max(input)→ float input是tensor,返回input中的最大值float。 (2)torch.max(input,dim, keepdim=True, max=None, max_indices=None) -> (Tensor, LongTensor) 同时返回指定维度=dim上的最大值和该最大值在该维度上的索引值。 相关推荐: 以上がPyTorch 上で回帰と分類を実装するための単純なニューラル ネットワークを構築する例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。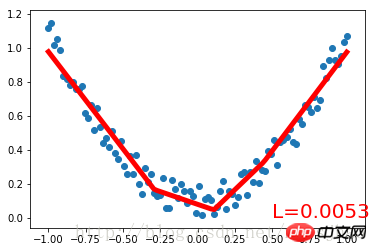
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
# 生成数据
# 分别生成2组各100个数据点,增加正态噪声,后标记以y0=0 y1=1两类标签,最后cat连接到一起
n_data = torch.ones(100,2)
# torch.normal(means, std=1.0, out=None)
x0 = torch.normal(2*n_data, 1) # 以tensor的形式给出输出tensor各元素的均值,共享标准差
y0 = torch.zeros(100)
x1 = torch.normal(-2*n_data, 1)
y1 = torch.ones(100)
x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # 组装(连接)
y = torch.cat((y0, y1), 0).type(torch.LongTensor)
# 置入Variable中
x, y = Variable(x), Variable(y)
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.out = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.out(x)
return x
net = Net(n_feature=2, n_hidden=10, n_output=2)
print(net)
optimizer = torch.optim.SGD(net.parameters(), lr=0.012)
loss_func = torch.nn.CrossEntropyLoss()
plt.ion()
plt.show()
for t in range(100):
out = net(x)
loss = loss_func(out, y) # loss是定义为神经网络的输出与样本标签y的差别,故取softmax前的值
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 2 == 0:
plt.cla()
# 过了一道 softmax 的激励函数后的最大概率才是预测值
# torch.max既返回某个维度上的最大值,同时返回该最大值的索引值
prediction = torch.max(F.softmax(out), 1)[1] # 在第1维度取最大值并返回索引值
pred_y = prediction.data.numpy().squeeze()
target_y = y.data.numpy()
plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn')
accuracy = sum(pred_y == target_y)/200 # 预测中有多少和真实值一样
plt.text(1.5, -4, 'Accu=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
plt.ioff()
plt.show()

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7467
7467
 15
1376
52
77
11
19
22
15
1376
52
77
11
19
22

 PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm は強力な統合開発環境 (IDE) であり、PyTorch はディープ ラーニングの分野で人気のあるオープン ソース フレームワークです。機械学習とディープラーニングの分野では、開発に PyCharm と PyTorch を使用すると、開発効率とコード品質が大幅に向上します。この記事では、PyCharm に PyTorch をインストールして構成する方法を詳しく紹介し、読者がこれら 2 つの強力な機能をより効果的に活用できるように、具体的なコード例を添付します。ステップ 1: PyCharm と Python をインストールする
 YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
YOLOは不滅です! YOLOv9 がリリースされました: パフォーマンスとスピード SOTA~
Feb 26, 2024 am 11:31 AM
現在の深層学習手法は、モデルの予測結果が実際の状況に最も近くなるように、最適な目的関数を設計することに重点を置いています。同時に、予測に十分な情報を取得するには、適切なアーキテクチャを設計する必要があります。既存の方法は、入力データがレイヤーごとの特徴抽出と空間変換を受けると、大量の情報が失われるという事実を無視しています。この記事では、ディープネットワークを介してデータを送信する際の重要な問題、つまり情報のボトルネックと可逆機能について詳しく説明します。これに基づいて、深層ネットワークが複数の目的を達成するために必要なさまざまな変化に対処するために、プログラマブル勾配情報 (PGI) の概念が提案されています。 PGI は、目的関数を計算するためのターゲット タスクに完全な入力情報を提供することで、ネットワークの重みを更新するための信頼できる勾配情報を取得できます。さらに、新しい軽量ネットワーク フレームワークが設計されています。
 Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?ソーシャルメディアの台頭により、WeChatは人々の日常生活に欠かせないコミュニケーションツールの1つになりました。ただし、多くの人は、同じ携帯電話で同時に複数の WeChat アカウントにログインするという問題に遭遇する可能性があります。 Huawei 社の携帯電話ユーザーにとって、WeChat の二重ログインを実現することは難しくありませんが、この記事では Huawei 社の携帯電話で WeChat の二重ログインを実現する方法を紹介します。まず第一に、ファーウェイの携帯電話に付属するEMUIシステムは、デュアルアプリケーションを開くという非常に便利な機能を提供します。アプリケーションのデュアルオープン機能により、ユーザーは同時に
 自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクにおいて、サンプリング法は生成モデルからテキスト出力を取得する手法です。この記事では、5 つの一般的なメソッドについて説明し、PyTorch を使用してそれらを実装します。 1. 貪欲復号 貪欲復号では、生成モデルは入力シーケンスに基づいて出力シーケンスの単語を時間ごとに予測します。各タイム ステップで、モデルは各単語の条件付き確率分布を計算し、最も高い条件付き確率を持つ単語を現在のタイム ステップの出力として選択します。このワードは次のタイム ステップへの入力となり、指定された長さのシーケンスや特別な終了マーカーなど、何らかの終了条件が満たされるまで生成プロセスが続行されます。 GreedyDecoding の特徴は、毎回現在の条件付き確率が最良になることです。
 PyTorch を使用した PyCharm のインストールに関するチュートリアル
Feb 24, 2024 am 10:09 AM
PyTorch を使用した PyCharm のインストールに関するチュートリアル
Feb 24, 2024 am 10:09 AM
PyTorch は、強力な深層学習フレームワークとして、さまざまな機械学習プロジェクトで広く使用されています。強力な Python 統合開発環境として、PyCharm はディープ ラーニング タスクを実装するときに優れたサポートも提供します。この記事では、PyTorch を PyCharm にインストールする方法を詳しく紹介し、読者が深層学習タスクに PyTorch をすぐに使い始めるのに役立つ具体的なコード例を示します。ステップ 1: PyCharm をインストールする まず、PyCharm がインストールされていることを確認する必要があります。
 PHP プログラミング ガイド: フィボナッチ数列を実装する方法
Mar 20, 2024 pm 04:54 PM
PHP プログラミング ガイド: フィボナッチ数列を実装する方法
Mar 20, 2024 pm 04:54 PM
プログラミング言語 PHP は、さまざまなプログラミング ロジックやアルゴリズムをサポートできる、Web 開発用の強力なツールです。その中でも、フィボナッチ数列の実装は、一般的で古典的なプログラミングの問題です。この記事では、PHP プログラミング言語を使用してフィボナッチ数列を実装する方法を、具体的なコード例を添付して紹介します。フィボナッチ数列は、次のように定義される数学的数列です。数列の最初と 2 番目の要素は 1 で、3 番目の要素以降、各要素の値は前の 2 つの要素の合計に等しくなります。シーケンスの最初のいくつかの要素
 非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
皆さん、こんにちは。私は Kite です。2 年前には、オーディオ ファイルとビデオ ファイルをテキスト コンテンツに変換する必要性を実現するのは困難でしたが、今ではわずか数分で簡単に解決できるようになりました。一部の企業では、トレーニングデータを取得するために、DouyinやKuaishouなどのショートビデオプラットフォーム上のビデオをフルクロールし、ビデオから音声を抽出してテキスト形式に変換し、ビッグデータのトレーニングコーパスとして使用していると言われていますモデル。ビデオまたはオーディオ ファイルをテキストに変換する必要がある場合は、現在利用可能なこのオープン ソース ソリューションを試すことができます。たとえば、映画やテレビ番組のセリフが登場する特定の時点を検索できます。早速、本題に入りましょう。 Whisper は OpenAI のオープンソース Whisper で、もちろん Python で書かれており、必要なのはいくつかの簡単なインストール パッケージだけです。
 1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
1.3ミリ秒には1.3ミリ秒かかります。清華社の最新オープンソース モバイル ニューラル ネットワーク アーキテクチャ RepViT
Mar 11, 2024 pm 12:07 PM
論文のアドレス: https://arxiv.org/abs/2307.09283 コードのアドレス: https://github.com/THU-MIG/RepViTRepViT は、モバイル ViT アーキテクチャで優れたパフォーマンスを発揮し、大きな利点を示します。次に、この研究の貢献を検討します。記事では、主にモデルがグローバル表現を学習できるようにするマルチヘッド セルフ アテンション モジュール (MSHA) のおかげで、軽量 ViT は一般的に視覚タスクにおいて軽量 CNN よりも優れたパフォーマンスを発揮すると述べられています。ただし、軽量 ViT と軽量 CNN のアーキテクチャの違いは十分に研究されていません。この研究では、著者らは軽量の ViT を効果的なシステムに統合しました。
