

Python の Requests パッケージを使用してシミュレートされたログインを実装する方法

この記事では、主に Python の Requests パッケージを使ってログインをシミュレートする方法を詳しく紹介します。興味のある方は参考にしてください。少し前に、私は Python を使っていくつかのページを取得するのが好きでしたが、基本的に、それらはすべて get を使用していくつかのページをリクエストし、通常のルールに従ってそれらをフィルタリングします。
今日試して、個人ウェブサイトへのログインをシミュレートしました。発見も比較的簡単です。この記事を読むには、http プロトコルと http セッションについてある程度の理解が必要です。
注: シミュレートされたログインは私の個人 Web サイトであるため、次のコードは個人 Web サイトとアカウントのパスワードを処理します。
ウェブサイト分析クローラーにとって重要な最初のステップは、ターゲットのウェブサイトを分析することです。ここでは、分析に Google Chrome の開発者ツールを使用します。
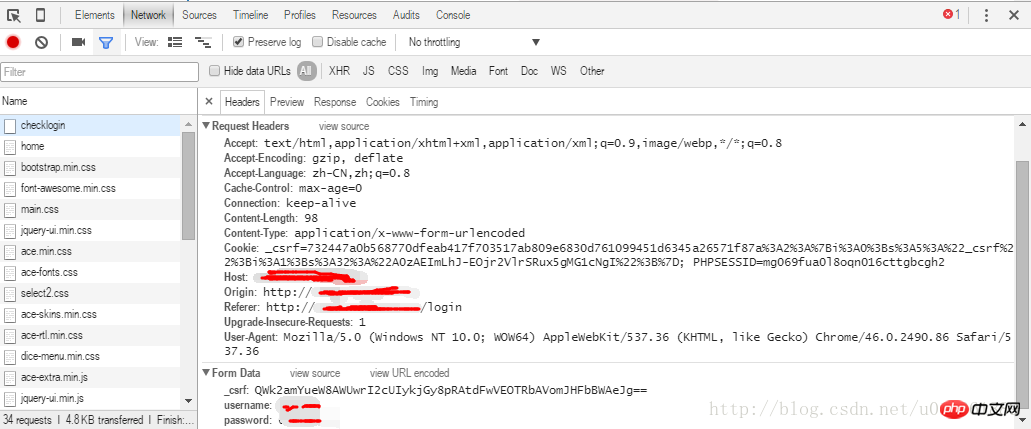
ログインをクロールすると、そのようなリクエストが見つかりました。
上の部分はリクエストヘッダー、下の部分はリクエストによって渡されるパラメータです。図からわかるように、ページはフォームを通じて 3 つのパラメーターを送信します。それぞれ _csrf、usermane、password です。
csrf は、クロスドメインのスクリプト偽造を防ぐためのものです。原理は非常に単純です。つまり、リクエストごとにサーバーが暗号化された文字列を生成します。非表示の入力フォームに配置します。別のリクエストを行う場合は、この文字列を一緒に渡して、同じユーザーからのリクエストであるかどうかを確認します。
 それで、私たちのコードロジックはそこにあります。まず、ログイン ページをリクエストします。次に、ページを分析して csrf 文字列を取得します。最後に、この文字列とアカウントのパスワードがログインのためにサーバーに渡されます。
それで、私たちのコードロジックはそこにあります。まず、ログイン ページをリクエストします。次に、ページを分析して csrf 文字列を取得します。最後に、この文字列とアカウントのパスワードがログインのためにサーバーに渡されます。
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = requests.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
page = requests.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)コードには問題ないようです。しかし、実行中にエラーが発生しました。確認すると、エラーの原因は csrf 検証に失敗したためです。
取得したcsrfとログインに要求したcsrf文字列がOKであることを何度も確認した後、問題を思いつきました。
エラーの原因がまだわからない場合は、ここで一時停止して問題について考えることができます。 「サーバーは、csrf を取得するための最初のリクエストと、ログイン後の 2 番目のリクエストが同じユーザーからのものであることをどのようにして知るのでしょうか?」
この時点で、正常にログインしたい場合は、その方法を解決する必要があることが明らかです。 2 つのリクエストが同じユーザーからのものであるとサービスに認識させるためです。ここでは http セッションを使用する必要があります (よくわからない場合は、Baidu を自分で使用できます。ここで簡単に説明します)。
http プロトコルはステートレス プロトコルです。これをステートレスにするために、セッションが導入されました。簡単に言うと、セッションを通じてこのステータスを記録します。ユーザーが初めて Web サービスをリクエストすると、サーバーはユーザーの情報を保存するためのセッションを生成します。同時に、ユーザーに戻るときに、セッション ID が Cookie に保存されます。ユーザーが再度リクエストすると、ブラウザはこの Cookie を一緒に持ち込んでくれます。したがって、サーバーは複数のリクエストが同じユーザーに対するものであるかどうかを知ることができます。
したがって、最初のリクエストを行うときに、コードはこのセッション ID を取得する必要があります。このセッション ID を 2 番目のリクエストと一緒に渡します。リクエストの優れた点は、このセッション オブジェクトを単純な request.Session() で使用できることです。
2 番目のコード#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
import requests
import re
# 头部信息
headers = {
'Host':"localhost",
'Accept-Language':"zh-CN,zh;q=0.8",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Connection':"keep-alive",
'Referer':"http://localhost/login",
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36"
}
# 登陆方法
def login(url,csrf,r_session):
data = {
"_csrf" : csrf,
"username": "xiedj",
"password": "***"
}
response = r_session.post(url, data=data, headers=headers)
return response.content
# 第一次访问获取csrf值
def get_login_web(url):
r_session = requests.Session()
page = r_session.get('http://localhost/login')
reg = r'<meta name="csrf-token" content="(.+)">'
csrf = re.findall(reg,page.content)[0]
login_page = login(url,csrf,r_session)
print login_page
if __name__ == "__main__":
url = "http://localhost/login/checklogin"
get_login_web(url)ログイン後にページを正常に取得します
 このコードから、requests.Session() がセッション オブジェクトを開始した後、2 番目のリクエストによってセッション オブジェクトが自動的に変更されることがわかります。前のもの セッションIDを一緒に渡します。関連する推奨事項:Pythonを使用してExcelチャートをエクスポートし、Picturesとしてエクスポートする方法Pythonのオープン関数を使用する場合のそのようなファイルやディールエラーの原因を解析する方法
このコードから、requests.Session() がセッション オブジェクトを開始した後、2 番目のリクエストによってセッション オブジェクトが自動的に変更されることがわかります。前のもの セッションIDを一緒に渡します。関連する推奨事項:Pythonを使用してExcelチャートをエクスポートし、Picturesとしてエクスポートする方法Pythonのオープン関数を使用する場合のそのようなファイルやディールエラーの原因を解析する方法
以上がPython の Requests パッケージを使用してシミュレートされたログインを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 1661
1661
 14
1418
52
1311
25
1261
29
1234
24
14
1418
52
1311
25
1261
29
1234
24

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
Sublime Code Pythonを実行する方法
Apr 16, 2025 am 08:48 AM
PythonコードをSublimeテキストで実行するには、最初にPythonプラグインをインストールし、次に.pyファイルを作成してコードを書き込み、Ctrl Bを押してコードを実行する必要があります。コードを実行すると、出力がコンソールに表示されます。
 vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
vscodeでコードを書く場所
Apr 15, 2025 pm 09:54 PM
Visual Studioコード(VSCODE)でコードを作成するのはシンプルで使いやすいです。 VSCODEをインストールし、プロジェクトの作成、言語の選択、ファイルの作成、コードの書き込み、保存して実行します。 VSCODEの利点には、クロスプラットフォーム、フリーおよびオープンソース、強力な機能、リッチエクステンション、軽量で高速が含まれます。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonを実行する方法
Apr 16, 2025 pm 07:33 PM
メモ帳でPythonコードを実行するには、Python実行可能ファイルとNPPEXECプラグインをインストールする必要があります。 Pythonをインストールしてパスを追加した後、nppexecプラグインでコマンド「python」とパラメーター "{current_directory} {file_name}"を構成して、メモ帳のショートカットキー「F6」を介してPythonコードを実行します。
