

この記事では、主にパンダのデータ処理の基本と、指定した行または指定した列のデータのフィルタリングに関する関連情報を紹介します。必要な友人は参照してください。
パンダの 2 つの主なデータ構造は次のとおりです。データ構造の列) ) および DataFrame (複数の行と列を持つ表形式のデータ構造に相当)。
理解を容易にするために、この記事では Excel または SQL の行または列の操作に例えて説明します
1. Reindex: reindex と ix
前の記事で紹介したように、データの後のデフォルトの行インデックス読み取り値は 0、1、2、3... のようなシーケンス番号です。列インデックスはフィールド名 (つまり、データの最初の行) に相当します。ここでのインデックスの再作成とは、デフォルトのインデックスを必要な値に再変更できることを意味します。
1.1 シリーズ
例: data=Series([4,5,6],index=['a','b','c'])、行インデックスは a,b,c です。
data.reindex(['a','c','d','e']) を使用してインデックスを変更すると、出力は次のようになります:
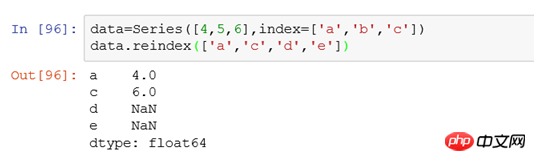
reindex を使用した後は次のようになります。インデックスに従って、インデックスを設定します。元のデータに移動して、対応する値と一致します。一致しない値は NaN です。
1.2 DataFrame
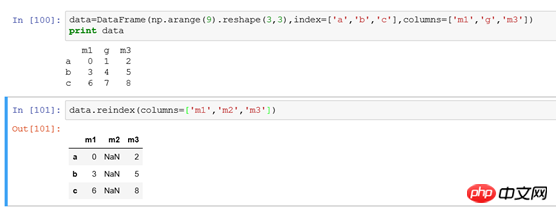
(1) 行インデックスの変更: DataFrame の行インデックスは Series
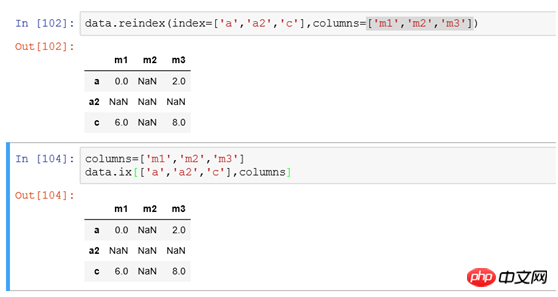
と同じです (2) 列インデックスの変更: 列インデックスは reindex(columns=['m1','m2','m3'] を使用します) )、パラメータ列を使用して列インデックスの変更を指定します。ロジックの変更は行インデックスと似ており、一致するデータがない場合は NaN を設定します。 (3) 行と列を変更します。インデックスを同時に使用するには、
2. 指定した軸上の列を削除します (平たく言えば、行または列を削除します)。drop
data.drop(['a ','c']) は、xid='a' または xid='c' のテーブル a を削除するのと同じですdata.drop ('m1',axis=1) は、yid='m1' のテーブル a を削除するのと同じです。
data.drop(['a','c']) 相当于delete table a where xid='a' or xid='c'
data.drop('m1',axis=1)相当于delete table a where yid='m1'
3.选取和过滤(通俗的说就是sql中按照条件筛选查询)
python中因为有行列索引,在做数据的筛选会比较方便
3.1 Series
(1)按照行索引进行选择如
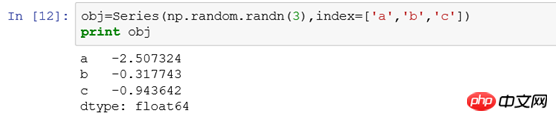
obj['b']相当于select * from tb where xid='b'obj['b','a','c']相当于select * from tb where xid in ('a','b','c')
Pythonには行と列のインデックスがあるので、データをフィルタリングするのがより便利です
3.1シリーズ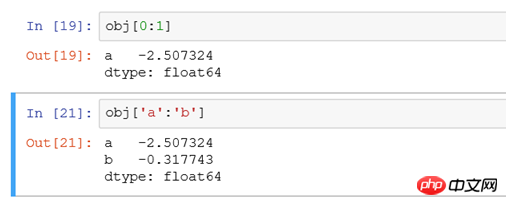
obj['b'] は select * from tb where xid= と同等です'b'obj['b','a','c'] は、 select * from tb where xid in ('a','b','c')と同等です。 > となり、b、a、cの順に結果が表示されます。これがsql obj[0:1]やobj['a':'b']との違いです。
#前者は末尾を含まず、後者は末尾を含みます
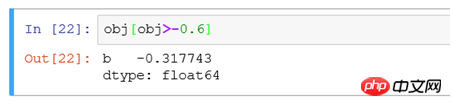
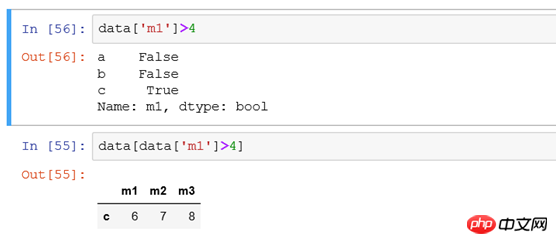
(2) フィルター obj[obj> -0.6] は、表示用の obj データ内で -0.6 より大きい値を持つレコードを検索することと同等です 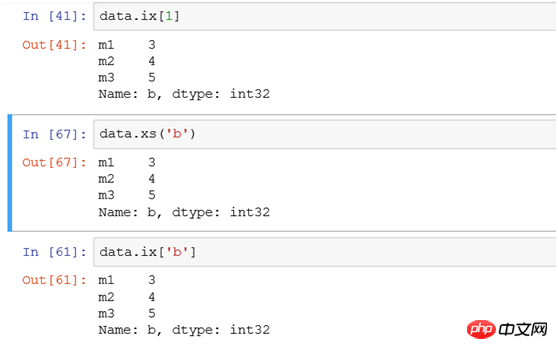
 たとえば、インデックス b で行をフィルターします。 記録するには、次の 3 つの方法が使用されます
たとえば、インデックス b で行をフィルターします。 記録するには、次の 3 つの方法が使用されます
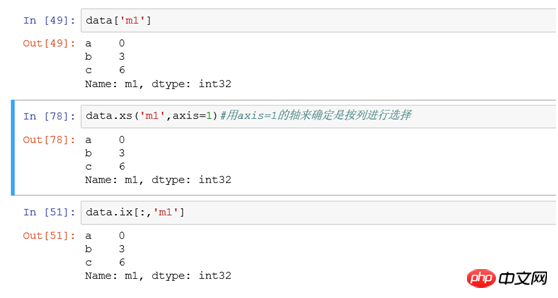
 たとえば、列値が 4 より大きいすべてのレコードをフィルタリングすることは、select * from tb where 列名 > 4 と同等です
たとえば、列値が 4 より大きいすべてのレコードをフィルタリングすることは、select * from tb where 列名 > 4 と同等です
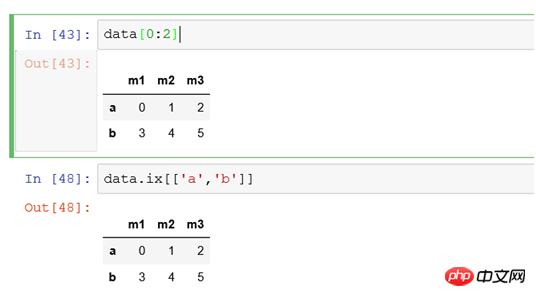
(6) 4 より大きい列値を持つすべてのレコードをフィルターし、一部の列のみを表示する必要がある場合
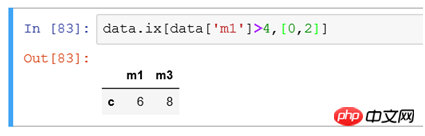
行は条件でフィルターされ、列は [0,2] でフィルターされて、最初の列と 3 番目の列のデータをフィルターします
関連する推奨事項:
python3 パンダによる MySQL データの読み取りと挿入
以上がPandas データ処理の基本: 指定した行または列のデータをフィルターするの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



