

この記事では主に Pandas のデータ型変換に関するいくつかのテクニックを紹介しますので、必要な方は参考にしてください
Pandas は Python データ分析において重要です。ツールを使用してデータ分析に Pandas を使用する場合、正しいデータ型が使用されていることを確認することが非常に重要です。そうしないと、予期しないエラーが発生する可能性があります。 Pandas のデータ型: データ型は本質的に、プログラミング言語がデータの保存方法と操作方法を理解するために使用する内部構造です。たとえば、プログラムは、5 + 10 で 15 になるなど、2 つの数値を加算できることを理解する必要があります。または、「cat」と「hat」などの 2 つの文字列の場合は、それらを連結 (加算) して「cathat」を取得できます。 Shangxuetang・Baizhan のプログラマーである Chen 先生は、Pandas のデータ型に関して混乱を招く可能性がある点の 1 つは、Pandas、Python、および numpy のデータ型の間に一部の重複があることだと指摘しました。
ほとんどの場合、pandas 型を対応する NumPy 型に明示的にキャストする必要があるかどうかについて心配する必要はありません。一般に、Pandas のデフォルトの int64 と float64 を使用できます。この表を含める唯一の理由は、コード行間または独自の分析中に Numpy 型が表示される可能性があるためです。データ型は、エラーや予期しない結果が発生するまでは気にしないものの 1 つです。ただし、これは、さらなる分析のために新しいデータを Pandas にロードするときに最初に確認する必要があることでもあります。
Pandas、Numpy、Python でそれぞれサポートされているデータ型
上記の表から、Pandas が最も豊富なデータ型をサポートしていることがわかります。場合によっては、Numpy のデータ型が次のとおりです。 Pandas のライブラリと同様にデータ型を相互に変換できます。 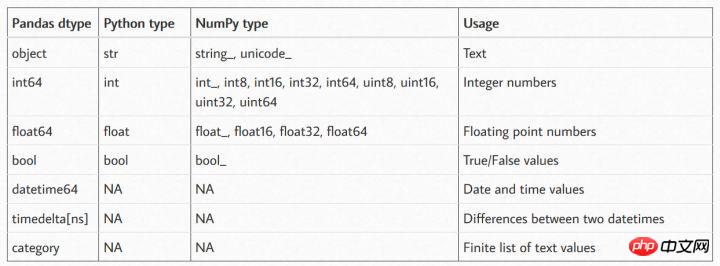
実際の分析データの紹介
データ型は、間違った結果が得られるまではあまり気にしないものなので、ここでは理解を深めるために実際のデータ分析の例を紹介します。
import numpy as np import pandas as pd data = pd.read_csv('data.csv', encoding='gbk') #因为数据中含有中文数据 data
データ列 2016 と 2017 の対応する項目を追加するなど、データに対していくつかの操作を実行する場合は、データがロードされます。 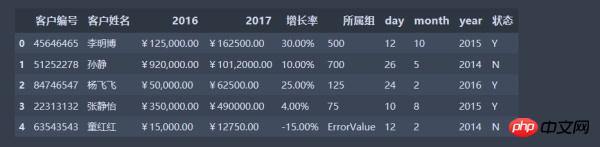
結果から言うと、 のオブジェクトが期待通りに加算されていないためです。 Pandas の型の追加は、Python の文字列の追加に相当します。 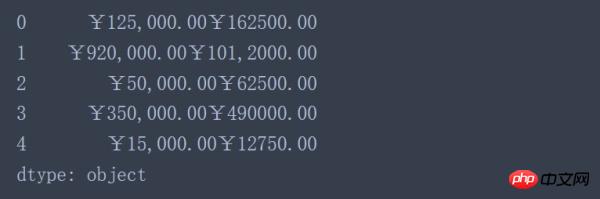
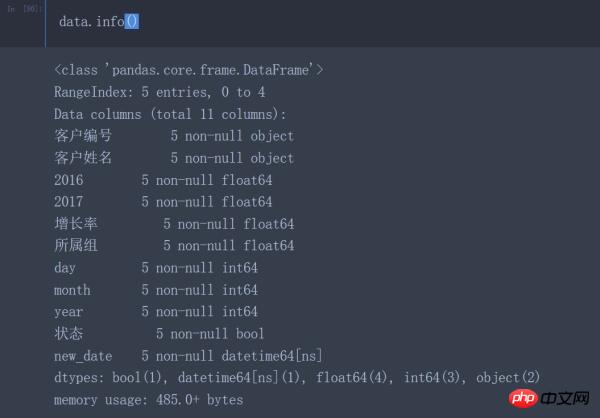
ロードされたデータの関連情報を確認すると、次の問題が見つかります。 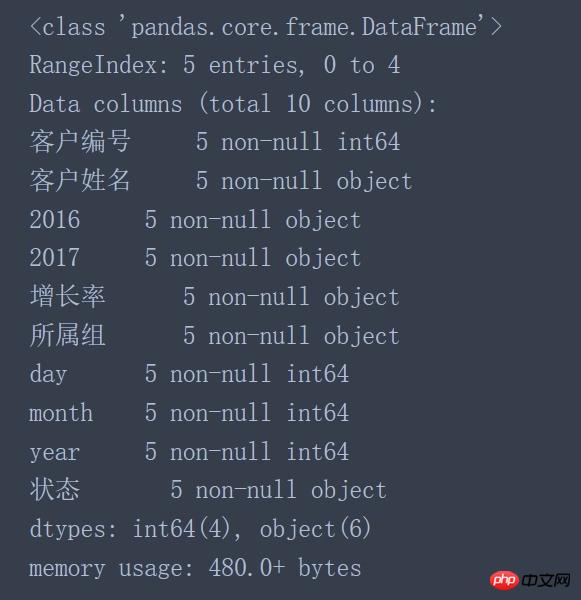
顧客番号のデータ型はオブジェクト型ではなくint64です
2016と2017の列のデータ型は数値型(int64、float64)ではなくオブジェクトです
増加率のデータ型とグループはオブジェクト型ではなく数値型である必要があります
年、月、日のデータ型はオブジェクト型ではなく datetime64 型である必要があります
Pandas でのデータ型変換には 3 つの基本的な方法があります:
astype() 関数で型変換を強制します
データ型変換のカスタム関数
to_numeric()、to_datetime() などの Pandas が提供する関数を使用します
データ列へのデータ型変換を実行する最も簡単な方法は、astype() 関数を使用することです
data['客户编号'].astype('object') data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列
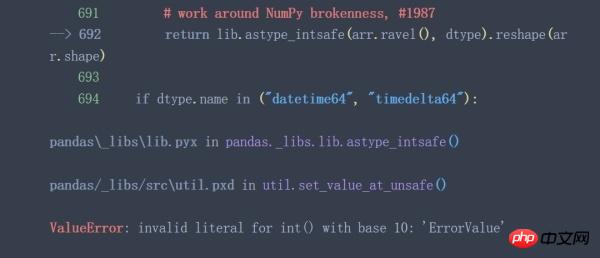
从上面两个例子可以看出,当待转换列中含有不能转换的特殊值时(例子中¥,ErrorValue等)astype()函数将失效。有些时候astype()函数执行成功了也并不一定代表着执行结果符合预期(神坑!)
data['状态'].astype('bool')
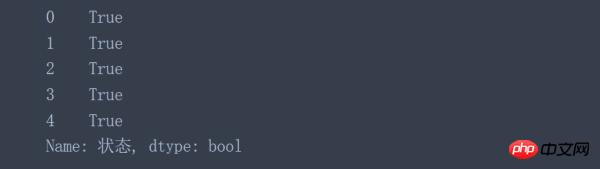
乍一看,结果看起来不错,但仔细观察后,会发现一个大问题。那就是所有的值都被替换为True了,但是该列中包含好几个N标志,所以astype()函数在该列也是失效的。
总结一下astype()函数有效的情形:
数据列中的每一个单位都能简单的解释为数字(2, 2.12等)
数据列中的每一个单位都是数值类型且向字符串object类型转换
如果数据中含有缺失值、特殊字符astype()函数可能失效。
使用自定义函数进行数据类型转换
该方法特别适用于待转换数据列的数据较为复杂的情形,可以通过构建一个函数应用于数据列的每一个数据,并将其转换为适合的数据类型。
对于上述数据中的货币,需要将它转换为float类型,因此可以写一个转换函数:
def convert_currency(value): """ 转换字符串数字为float类型 - 移除 ¥ , - 转化为float类型 """ new_value = value.replace(',', '').replace('¥', '') return np.float(new_value)
现在可以使用Pandas的apply函数通过covert_currency函数应用于2016列中的所有数据中。
data['2016'].apply(convert_currency)
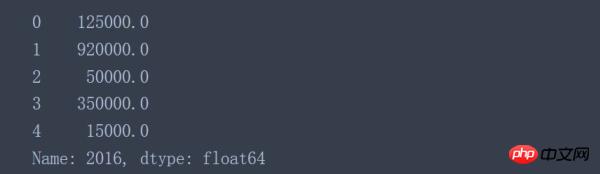
该列所有的数据都转换成对应的数值类型了,因此可以对该列数据进行常见的数学操作了。如果利用lambda表达式改写一下代码,可能会比较简洁但是对新手不太友好。
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
当函数需要重复应用于多个列时,个人推荐使用第一种方法,先定义函数还有一个好处就是可以搭配read_csv()函数使用(后面介绍)。
#2016、2017列完整的转换代码 data['2016'] = data['2016'].apply(convert_currency) data['2017'] = data['2017'].apply(convert_currency)
同样的方法运用于增长率,首先构建自定义函数
def convert_percent(value): """ 转换字符串百分数为float类型小数 - 移除 % - 除以100转换为小数 """ new_value = value.replace('%', '') return float(new_value) / 100
使用Pandas的apply函数通过covert_percent函数应用于增长率列中的所有数据中。
data['增长率'].apply(convert_percent)
使用lambda表达式:
data['增长率'].apply(lambda x: x.replace('%', '')).astype('float') / 100
结果都相同:
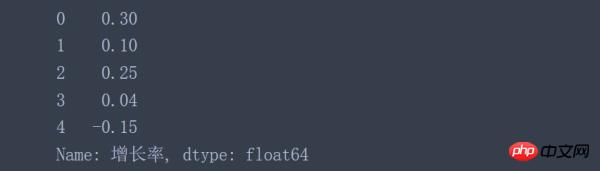
为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
data['状态'] = np.where(data['状态'] == 'Y', True, False)
同样的你也可以使用自定义函数或者使用lambda表达式,这些方法都可以完美的解决这个问题,这里只是多提供一种思路。
利用Pandas的一些辅助函数进行类型转换
Pandas的astype()函数和复杂的自定函数之间有一个中间段,那就是Pandas的一些辅助函数。这些辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())。所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)

可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
pandas.to_numeric - pandas 0.22.0 documentation
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
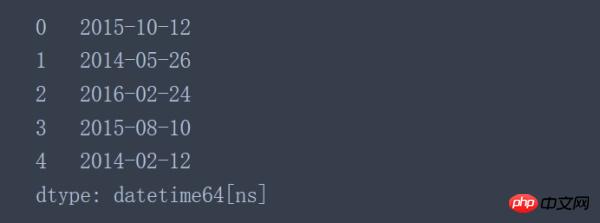
完成数据列的替换
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新产生的一列数据 data['所属组'] = pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
到这里所有的数据列都转换完毕,最终的数据显示:
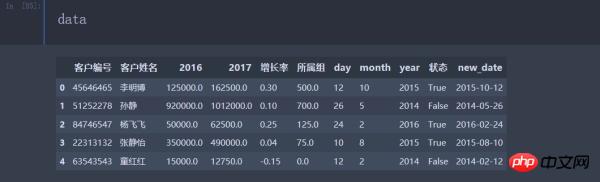
在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')在这里也体现了使用自定义函数比lambda表达式要方便很多。(大部分情况下lambda还是很简洁的,笔者自己也很喜欢使用)
概要
データセットを操作するための最初のステップは、正しいデータ型が設定されていることを確認することで、その後、データ分析、視覚化、その他の操作を実行できるようになります。関数を使用すると、データを分析するのに非常に便利になります。
関連する推奨事項:
pandas は、特定のインデックスでの行の選択を実装します
以上がPandas でデータ型変換を実装するためのヒントの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



