

ノード+非同期は同時実行制御を実装します
今回は同時実行性を制御するためのnode+asyncについて説明します。node+asyncを使用して同時実行性を制御するための注意事項を紹介します。
目標
lesson5 プロジェクトを作成し、そこにコードを記述します。
コードのエントリ ポイントは app.js です。ノード app.js が呼び出されると、CNode のコミュニティ ホームページ (https://cnodejs.org) 上のすべてのトピックのタイトル、リンク、最初のコメントが出力されます。 /)。
注: 前のレッスンとは異なり、同時接続の数は 5 に制御する必要があります。
出力例:
[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵"
},
{
"title": "发布一款 Sublime Text 下的 JavaScript 语法高亮插件",
"href": "http://cnodejs.org/topic/54207e2efffeb6de3d61f68f",
"comment1": "沙发!"
}
]知識ポイント
async の使用方法を学びます (https://github.com/caolan/async)。詳細な非同期デモは次のとおりです: https://github.com/alotang/async_demo
async を使用して同時接続数を制御する方法を学びます。
コースの内容
lesson4 のコードは実際には完璧ではありません。このように言う理由は、レッスン 4 で一度に 40 件のリクエストを送信したためです。CNode を除く他の Web サイトでは、送信する同時接続数が多すぎるため、悪意のあるリクエストとして扱われ、IP がブロックされる可能性があることを知っておく必要があります。 。
クローラーを作成するとき、クロールするリンクが 1,000 ある場合、同時に 1,000 のリンクを送信することは不可能ですよね。同時実行数 (たとえば、10 同時実行) を制御し、これらの 1,000 リンクをゆっくりとキャプチャする必要があります。
これを非同期で行うのは簡単です。
今回は、async の mapLimit(arr, limit, iterator, callback) インターフェイスを紹介します。さらに、同時接続数を制御するためによく使用される別のインターフェイス、queue(worker, concurrency) があります。 https://github.com/caolan/async#queueworker-concurrency にアクセスできます。指示のために。 mapLimit(arr, limit, iterator, callback) 接口。另外,还有个常用的控制并发连接数的接口是 queue(worker, concurrency),大家可以去 https://github.com/caolan/async#queueworker-concurrency 看看说明。
这回我就不带大家爬网站了,我们来专注知识点:并发连接数控制。
对了,还有个问题是,什么时候用 eventproxy,什么时候使用 async 呢?它们不都是用来做异步流程控制的吗?
我的答案是:
当你需要去多个源(一般是小于 10 个)汇总数据的时候,用 eventproxy 方便;当你需要用到队列,需要控制并发数,或者你喜欢函数式编程思维时,使用 async。大部分场景是前者,所以我个人大部分时间是用 eventproxy 的。
正题开始。
首先,我们伪造一个 fetchUrl(url, callback)
に使用されているのではありませんか?
私の答えは次のとおりです:
複数のソース (通常は 10 未満) にアクセスする必要がある場合 場合データを要約する場合は、eventproxy を使用すると便利です。キューを使用する必要がある場合、同時実行数を制御する必要がある場合、または関数型プログラミングの考え方が必要な場合は、async を使用します。ほとんどのシナリオは前者であるため、私は個人的にはほとんどの場合、eventproxy を使用します。
始めましょう。 
fetchUrl(url, callback) 関数を作成します。この関数の機能は、
fetchUrl('http://www.baidu.com', function (err, content) {
// do something with `content`
});// 并发连接数的计数器
var concurrencyCount = 0;
var fetchUrl = function (url, callback) {
// delay 的值在 2000 以内,是个随机的整数
var delay = parseInt((Math.random() * 10000000) % 2000, 10);
concurrencyCount++;
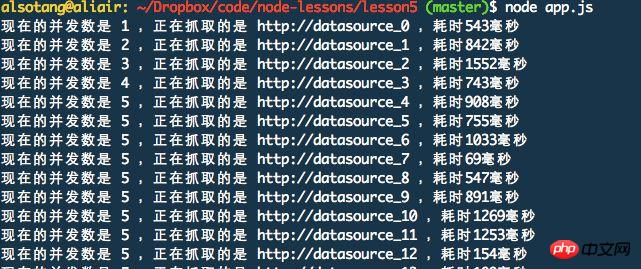
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒');
setTimeout(function () {
concurrencyCount--;
callback(null, url + ' html content');
}, delay);
}; その後、リンクのセットを作成します
その後、リンクのセットを作成しますvar urls = [];
for(var i = 0; i < 30; i++) {
urls.push('http://datasource_' + i);
}このリンクのセットは次のようになります:
次に、async.mapLimit を使用して、クロールと結果の取得を同時に行います。async.mapLimit(urls, 5, function (url, callback) {
fetchUrl(url, callback);
}, function (err, result) {
console.log('final:');
console.log(result);
}); 最初は、同時リンクの数が 1 から増加し始め、5 に増加すると増加が停止することがわかります。いずれかのタスクが完了したら、フェッチを続行します。同時接続数は常に 5 に制限されます。
この記事の事例を読んだ後は、この方法を習得したと思います。さらに興味深い情報については、php 中国語 Web サイトの他の関連記事に注目してください。
以上がノード+非同期は同時実行制御を実装しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?
Mar 24, 2024 am 11:27 AM
Huawei 携帯電話にデュアル WeChat ログインを実装するにはどうすればよいですか?ソーシャルメディアの台頭により、WeChatは人々の日常生活に欠かせないコミュニケーションツールの1つになりました。ただし、多くの人は、同じ携帯電話で同時に複数の WeChat アカウントにログインするという問題に遭遇する可能性があります。 Huawei 社の携帯電話ユーザーにとって、WeChat の二重ログインを実現することは難しくありませんが、この記事では Huawei 社の携帯電話で WeChat の二重ログインを実現する方法を紹介します。まず第一に、ファーウェイの携帯電話に付属するEMUIシステムは、デュアルアプリケーションを開くという非常に便利な機能を提供します。アプリケーションのデュアルオープン機能により、ユーザーは同時に
 Huawei携帯電話にWeChatクローン機能を実装する方法
Mar 24, 2024 pm 06:03 PM
Huawei携帯電話にWeChatクローン機能を実装する方法
Mar 24, 2024 pm 06:03 PM
Huawei 携帯電話に WeChat クローン機能を実装する方法 ソーシャル ソフトウェアの人気と人々のプライバシーとセキュリティの重視に伴い、WeChat クローン機能は徐々に人々の注目を集めるようになりました。 WeChat クローン機能を使用すると、ユーザーは同じ携帯電話で複数の WeChat アカウントに同時にログインできるため、管理と使用が容易になります。 Huawei携帯電話にWeChatクローン機能を実装するのは難しくなく、次の手順に従うだけです。ステップ 1: 携帯電話システムのバージョンと WeChat のバージョンが要件を満たしていることを確認する まず、Huawei 携帯電話システムのバージョンと WeChat アプリが最新バージョンに更新されていることを確認します。
 Java 関数の同時実行性とマルチスレッド化によってパフォーマンスはどのように向上するのでしょうか?
Apr 26, 2024 pm 04:15 PM
Java 関数の同時実行性とマルチスレッド化によってパフォーマンスはどのように向上するのでしょうか?
Apr 26, 2024 pm 04:15 PM
Java 関数を使用した同時実行およびマルチスレッド技術により、次の手順を含むアプリケーションのパフォーマンスを向上させることができます。 同時実行およびマルチスレッドの概念を理解する。 Java の同時実行性と、ExecutorService や Callable などのマルチスレッド ライブラリを活用します。マルチスレッドの行列乗算などのケースを練習して、実行時間を大幅に短縮します。同時実行性とマルチスレッドによってもたらされる、アプリケーションの応答速度の向上と最適化された処理効率の利点をお楽しみください。
 Golang API 設計における同時実行性とコルーチンの適用
May 07, 2024 pm 06:51 PM
Golang API 設計における同時実行性とコルーチンの適用
May 07, 2024 pm 06:51 PM
同時実行性とコルーチンは、GoAPI 設計で次の目的で使用されます。 高パフォーマンス処理: 複数のリクエストを同時に処理してパフォーマンスを向上させます。非同期処理: コルーチンを使用してタスク (電子メールの送信など) を非同期に処理し、メインスレッドを解放します。ストリーム処理: コルーチンを使用して、データ ストリーム (データベース読み取りなど) を効率的に処理します。
 Java データベース接続はトランザクションと同時実行をどのように処理しますか?
Apr 16, 2024 am 11:42 AM
Java データベース接続はトランザクションと同時実行をどのように処理しますか?
Apr 16, 2024 am 11:42 AM
トランザクションは、原子性、一貫性、分離性、耐久性などのデータベース データの整合性を保証します。 JDBC は、Connection インターフェイスを使用してトランザクション制御 (setAutoCommit、コミット、ロールバック) を提供します。同時実行制御メカニズムは、ロックまたはオプティミスティック/ペシミスティック同時実行制御を使用して同時操作を調整し、トランザクションの分離を実現してデータの不整合を防ぎます。
 Go 同時関数の単体テストのガイド
May 03, 2024 am 10:54 AM
Go 同時関数の単体テストのガイド
May 03, 2024 am 10:54 AM
並行関数の単体テストは、同時環境での正しい動作を確認するのに役立つため、非常に重要です。同時実行機能をテストするときは、相互排他、同期、分離などの基本原則を考慮する必要があります。並行機能は、シミュレーション、競合状態のテスト、および結果の検証によって単体テストできます。
 Java 関数の同時実行性とマルチスレッドでアトミック クラスを使用するにはどうすればよいですか?
Apr 28, 2024 pm 04:12 PM
Java 関数の同時実行性とマルチスレッドでアトミック クラスを使用するにはどうすればよいですか?
Apr 28, 2024 pm 04:12 PM
アトミック クラスは、中断のない操作を提供する Java のスレッドセーフ クラスであり、同時環境でのデータの整合性を確保するために重要です。 Java は、次のアトミック クラスを提供します。 AtomicIntegerAtomicLongAtomicReferenceAtomicBoolean これらのクラスは、操作がアトミックであり、スレッドによって中断されないことを保証するために、値を取得、設定、および比較するためのメソッドを提供します。アトミック クラスは、共有データを操作する場合や、共有カウンタへの同時アクセスを維持するなど、データの破損を防ぐ場合に役立ちます。
 Java 関数の同時実行性とマルチスレッドによるデッドロックを回避するにはどうすればよいですか?
Apr 26, 2024 pm 06:09 PM
Java 関数の同時実行性とマルチスレッドによるデッドロックを回避するにはどうすればよいですか?
Apr 26, 2024 pm 06:09 PM
マルチスレッド環境におけるデッドロックの問題は、固定のロック順序を定義し、ロックを順番に取得することで防止できます。指定した時間内にロックを取得できない場合に待機を諦めるタイムアウト機構を設定します。デッドロック検出アルゴリズムを使用してスレッドのデッドロック状態を検出し、回復措置を講じます。実際の場合、リソース管理システムはすべてのリソースに対してグローバルなロック順序を定義し、デッドロックを回避するためにスレッドに必要なロックを強制的に取得させます。
