

PHP でのパックとアンパックの使用方法についての簡単な説明
今回は、PHPでのpackとunpackの使い方と、PHPでpackとunpackを使用する際の注意点について詳しく説明します。以下は実際的なケースです。
pack
string pack ( string $format [, mixed $args [, mixed $... ]] )
この関数は、対応するパラメータ ($args) をバイナリ string にパックするために使用されます。
最初のパラメータ $format には次のオプションがあります (オプションのパラメータが多数あり、後で説明するために一般的に使用されるパラメータをいくつか選択します): NUL 文字セクションは文字列を空白で埋めます
| 文字列を SPACE (スペース) で埋めます | |
|---|---|
| H | |
| c | |
| C | |
| s | |
| S | |
| n | |
| v | |
| i | |
| I | |
| l | |
| L | |
| N | |
| V | |
| q | |
| f | |
| (マシン依存のサイズ) | |
| 倍精度浮動小数点(マシン依存のサイズ) | |
| NULバイト | |
| @ | |
|
这么多参数看下来,我第一次是真心懵逼了,大部分说明都很好理解,但是其中的主机、大端、小端等字节序是什么鬼呢?接下里的内容比较枯燥,但必须理解才行,坚持吧。 字节序是什么? 就是字节的顺序,说白了就是多字节数据的存放顺序(一个字节显然不需要顺序)。 比如A和B分别对应的二进制表示为0100 0001、0100 0010。对于储存字符串AB,我们可以0100 0001 0100 0010也可以0100 0010 0100 0001,这个顺序就是所谓的字节序。 高/低位字节 比如字符串AB,左高右低(我们正常的阅读顺序),A为高字节,B为低字节 高/低地址 假设0x123456是按从高位到底位的顺序储存,内存中是这样存放的: 高地址 -> 低地址 大端字节序(网络字节序) 大端就是将高位字节放到内存的低地址端,低位字节放到高地址端。网络传输中(比如TCP/IP)低地址端(高位字节)放在流的开始,对于2个字节的字符串(AB),传输顺序为:A(0-7bit)、B(8-15bit)。 那么小端字节序自然和大端相反。 主机字节序 表示当年机器的字节序(也就是网络字节序是确定的,而主机字节序是依机器确定的),一般为小端字节序。 a和A(打包字符串,用NUL或者空格填充) $string = pack('a6', 'china');
var_dump($string); //输出结果: string(6) "china",最后一个字节是不可见的NUL
echo ord($string[5]); //输出结果: 0(ASCII码中0对应的就是nul)
//A同理
$string = pack('A6', 'china');
var_dump($string); //输出结果: string(6) "china ",最后一个字节是空格
echo ord($string[5]); //输出结果: 32(ASCII码中32对应的就是空格)ログイン後にコピー
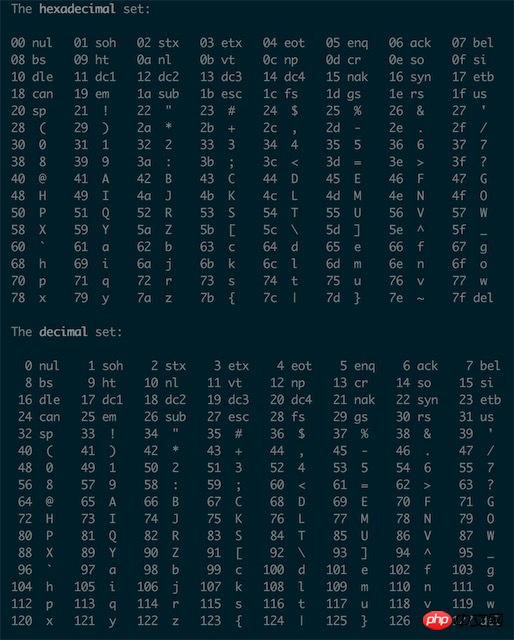
附赠ASCII表一张(linux/unix下可以使用man ascii查看) h和H $string = pack('H3', 281);
var_dump($string); //输出结果: string(2) "("
for($i=0;$i<strlen($string);$i++) {
echo ord($string[$i]) . PHP_EOL;
}
//输出结果: 40 16ログイン後にコピー h和H需要特殊说明一下,它们是将对应的参数看做十六进制字符然后打包。什么意思呢?比如上面的281,打包前会将281转换为0x281,因为十六进制的一位对应二进制的四位,上面的0x281只有1.5个字节,后面会默认补0变成0x2810,0x28对应的十进制为40((),0x10对应的十进制为16(dle不可见字符),懂了吧?不懂可以给我留言。。 c和C $string = pack('c3', 67, 68, -1);
var_dump($string); //输出:string(3) "CD�"
for($i=0;$i<strlen($string);$i++) {
echo ord($string[$i]) . PHP_EOL;
}
//输出: 67 68 225ログイン後にコピー 最后输出本能应该觉得是67 68 -1 ord获取的是字符的ASCII码(范围0-255),这时-1(0000 0001)对应的字符将以补码的形式输出也就是255(1111 1110 + 0000 0001 = 1111 1111) 整型相关 所有的整型类型使用方法完全一样,主要注意它们的位和字节序就可以了,下面以L作为例子展示 $string = pack('L', 123456789);
var_dump($string); //输出:string(4) "�["
for($i=0;$i<strlen($string);$i++) {
echo ord($string[$i]) . PHP_EOL;
}
//输出: 21 205 91 7ログイン後にコピー f和d $string = pack('f', 12345.123); var_dump($string); //输出:string(4) "~�@F" var_dump(unpack('f', $string)); //这里提前用到了unpack,后面会讲解 //输出:float(12345.123046875) ログイン後にコピー f和d是针对浮点数打包,至于为什么打包前是12345.123解包后是12345.123046875,这个和浮点数的储存有关系,后面可以单开一个文章讲解一下IEEE标准 x、X、Z、@ $string = pack('x'); //打包一个nul字符串 echo ord($string); //输出: 0 ログイン後にコピー 关于X(大写X),试了N次,没搞明白怎么用,有清楚的童鞋可以给我留言,多谢。 $string = pack('Z2', 'abc5'); //其实就是将从Z后面的数字位置开始,全部设置为nul
var_dump($string); //输出:string(2) "a"
for($i=0;$i<strlen($string);$i++) {
echo ord($string[$i]) . PHP_EOL;
}
//输出: 97 0ログイン後にコピー $string = pack('@4'); //我理解为填充N个nul
var_dump($string); //输出: string(4) ""
for($i=0;$i<strlen($string);$i++) {
echo ord($string[$i]) . PHP_EOL;
}
//输出: 0 0 0 0ログイン後にコピー unpack array unpack ( string $format , string $data ) ログイン後にコピー unpack的使用相当简单,就是讲pack打包的数据解包,打包的时候用的什么参数,就用什么参数解包,具体使用懒得说了,列几个小例子 $string = pack('L4', 1, 2, 3, 4);
var_dump(unpack('L4', $string));
//输出:
array(4) {
[1]=>
int(1)
[2]=>
int(2)
[3]=>
int(3)
[4]=>
int(4)
}
$string = pack('L4', 1, 2, 3, 4);
var_dump(unpack('Ll1/Ll2/Ll3/Ll4', $string)); //可以指定key,用/分割
//输出:
array(4) {
["l1"]=>
int(1)
["l2"]=>
int(2)
["l3"]=>
int(3)
["l4"]=>
int(4)
}ログイン後にコピー 这两个函数到底有啥用途
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章! 推荐阅读: |
以上がPHP でのパックとアンパックの使用方法についての簡単な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107

 DirectX修復ツールの使い方は? DirectX修復ツールの詳しい使い方
Mar 15, 2024 am 08:31 AM
DirectX修復ツールの使い方は? DirectX修復ツールの詳しい使い方
Mar 15, 2024 am 08:31 AM
DirectX 修復ツールは専門的なシステム ツールであり、その主な機能は現在のシステムの DirectX 状態を検出することであり、異常が見つかった場合は直接修復できます。 DirectX 修復ツールの使い方がわからないユーザーも多いと思いますので、以下の詳細なチュートリアルを見てみましょう。 1. 修復ツール ソフトウェアを使用して修復検出を実行します。 2. 修復の完了後、C++ コンポーネントに異常な問題があることを示すメッセージが表示された場合は、[キャンセル] ボタンをクリックし、[ツール] メニュー バーをクリックしてください。 3. [オプション] ボタンをクリックし、拡張機能を選択して、[拡張機能の開始] ボタンをクリックします。 4. 拡張が完了したら、再検出して修復します。 5. 修復ツールの操作が完了した後も問題が解決しない場合は、エラーを報告したプログラムをアンインストールして再インストールしてみてください。
 HTTP 525 ステータス コードの概要: その定義と応用を調べる
Feb 18, 2024 pm 10:12 PM
HTTP 525 ステータス コードの概要: その定義と応用を調べる
Feb 18, 2024 pm 10:12 PM
HTTP 525 ステータス コードの概要: その定義と使用法を理解する HTTP (HypertextTransferProtocol) 525 ステータス コードは、SSL ハンドシェイク中にサーバーでエラーが発生し、安全な接続を確立できないことを意味します。 Transport Layer Security (TLS) ハンドシェイク中にエラーが発生すると、サーバーはこのステータス コードを返します。このステータス コードはサーバー エラー カテゴリに分類され、通常はサーバーの構成またはセットアップの問題を示します。クライアントが HTTPS 経由でサーバーに接続しようとすると、サーバーには
 Baidu Netdisk の使用方法 - Baidu Netdisk の使用方法
Mar 04, 2024 pm 09:28 PM
Baidu Netdisk の使用方法 - Baidu Netdisk の使用方法
Mar 04, 2024 pm 09:28 PM
Baidu Netdisk の使い方をまだ知らない友人も多いので、以下では編集者が Baidu Netdisk の使い方を説明しますので、必要な場合は急いでご覧ください。ステップ 1: Baidu Netdisk をインストールした後、直接ログインします (図を参照); ステップ 2: 次に、ページのプロンプトに従って [マイ共有] と [転送リスト] を選択します (図を参照); ステップ 3: 「 「友達共有」では、写真やファイルを友達と直接共有できます (図を参照); ステップ 4: 次に、「共有」を選択し、コンピューター ファイルまたはネットワーク ディスク ファイルを選択します (図を参照); 5 番目のステップ 1:次に、友達を見つけることができます (写真に示すように); ステップ 6: 「機能宝箱」で必要な機能を見つけることもできます (写真に示すように)。以上、編集者の意見です
 素早くコピー&ペーストする方法を学ぶ
Feb 18, 2024 pm 03:25 PM
素早くコピー&ペーストする方法を学ぶ
Feb 18, 2024 pm 03:25 PM
コピー&ペーストのショートカットキーの使い方 コピー&ペーストは、毎日パソコンを使っていると頻繁に遭遇する操作です。作業効率を向上させるためには、コピー&ペーストのショートカットキーを使いこなすことが非常に重要です。この記事では、読者がコピー アンド ペースト操作をより便利に実行できるように、一般的に使用されるコピー アンド ペーストのショートカット キーをいくつか紹介します。コピーのショートカット キー: Ctrl+CCtrl+C はコピーのショートカット キーで、Ctrl キーを押しながら C キーを押すと、選択したテキスト、ファイル、画像などをクリップボードにコピーできます。このショートカットキーを使用するには、
 自動修復操作で win10 コマンド プロンプトを正しく使用する方法
Dec 30, 2023 pm 03:17 PM
自動修復操作で win10 コマンド プロンプトを正しく使用する方法
Dec 30, 2023 pm 03:17 PM
コンピューターは長く使用すると故障する可能性が高くなります。その場合、友人が独自の方法でコンピューターを修復する必要があります。では、最も簡単な方法は何でしょうか?今回はコマンドプロンプトを使って修復する方法を紹介します。 Win10 自動修復コマンド プロンプトの使用方法: 1. 「Win+R」を押して cmd と入力して「コマンド プロンプト」を開きます。 2. chkdsk と入力して修復コマンドを表示します。 3. 他の場所を表示する必要がある場合は、次のコマンドを追加することもできます。 「d」などの他のパーティション 4. 実行コマンド chkdskd:/F を入力します。 5. 変更プロセス中に占有されている場合は、Y を入力して続行できます。
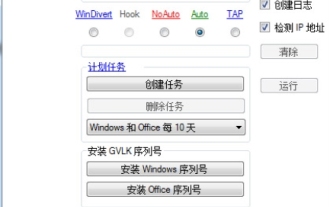 KMS アクティベーション ツールとは何ですか? KMS アクティベーション ツールの使用方法は? KMS アクティベーション ツールの使用方法は?
Mar 18, 2024 am 11:07 AM
KMS アクティベーション ツールとは何ですか? KMS アクティベーション ツールの使用方法は? KMS アクティベーション ツールの使用方法は?
Mar 18, 2024 am 11:07 AM
KMS ライセンス認証ツールは、Microsoft Windows および Office 製品のライセンス認証に使用されるソフトウェア ツールです。 KMS は KeyManagementService の略で、鍵管理サービスです。 KMS ライセンス認証ツールは、KMS サーバーの機能をシミュレートして、コンピューターが仮想 KMS サーバーに接続して Windows および Office 製品をライセンス認証できるようにします。 KMS ライセンス認証ツールは、サイズが小さく、機能が強力です。ワンクリックで永続的にライセンス認証できます。インターネットに接続せずに、あらゆるバージョンのウィンドウ システムとあらゆるバージョンの Office ソフトウェアをライセンス認証できます。現在、最も成功しているツールです。頻繁に更新される Windows ライセンス認証ツール 今日はそれを紹介します kms ライセンス認証作業を紹介します
 ショートカットキーを使ってセルを結合する方法
Feb 26, 2024 am 10:27 AM
ショートカットキーを使ってセルを結合する方法
Feb 26, 2024 am 10:27 AM
セルを結合するためのショートカット キーの使用方法 日常業務では、表の編集や書式設定が必要になることがよくあります。セルの結合は、表の美しさと情報の表示効果を向上させるために、隣接する複数のセルを 1 つのセルに結合する一般的な操作です。 Microsoft ExcelやGoogle Sheetsなどの主流の表計算ソフトでは、セルの結合操作は非常に簡単でショートカットキーで実現できます。この2つのソフトでセルを結合するショートカットキーの使い方を紹介します。存在する
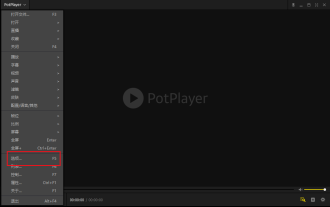 ポットプレイヤーの使い方 - ポットプレイヤーの使い方
Mar 04, 2024 pm 06:10 PM
ポットプレイヤーの使い方 - ポットプレイヤーの使い方
Mar 04, 2024 pm 06:10 PM
Potplayer は非常に強力なメディア プレーヤーですが、まだ Potplayer の使い方を知らない友達も多いので、今日は Potplayer の使い方を詳しく紹介して、皆さんのお役に立てればと思います。 1. PotPlayer のショートカット キー: PotPlayer プレーヤーのデフォルトの共通ショートカット キーは次のとおりです: (1) 再生/一時停止: スペース (2) 音量: マウス ホイール、上下の矢印キー (3) 進む/戻る: 左右の矢印キー (4) ブックマーク: P- ブックマークの追加、H-ビューブックマーク (5) フルスクリーン/復元: Enter (6) 複数の速度: C-加速、7) 前/次のフレーム: D/
