

ノードを操作し、async を使用して同時実行性を制御する方法
今回は、asyncを使用してノードを操作する際の同時実行性を制御する方法と、asyncを使用して同時実行性を制御するノードを操作する場合の注意事項について説明します。以下は実際的なケースです。
目標
lesson5 プロジェクトを作成し、そこにコードを記述します。 コードのエントリ ポイントは app.js です。ノード app.js が呼び出されると、CNode のコミュニティ ホームページ (https://cnodejs.org) 上のすべてのトピックのタイトル、リンク、最初のコメントが出力されます。 /)。
注: 前のレッスンとは異なり、同時接続の数は 5 に制御する必要があります。 出力例:[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵"
},
{
"title": "发布一款 Sublime Text 下的 JavaScript 语法高亮插件",
"href": "http://cnodejs.org/topic/54207e2efffeb6de3d61f68f",
"comment1": "沙发!"
}
]知識ポイント
async の使用方法を学びます (https://github.com/caolan/async)。詳細な非同期デモは次のとおりです: https://github.com/alotang/async_demo async を使用して同時接続数を制御する方法を学びます。コースの内容
lesson4 のコードは実際には完璧ではありません。このように言う理由は、レッスン 4 で一度に 40 件のリクエストを送信したためです。CNode を除く他の Web サイトでは、送信する同時接続数が多すぎるため、悪意のあるリクエストとして扱われ、IP がブロックされる可能性があることを知っておく必要があります。 。 クローラーを作成するとき、クロールするリンクが 1,000 ある場合、同時に 1,000 のリンクを送信することは不可能ですよね。同時実行数 (たとえば、10 同時実行) を制御し、これらの 1,000 リンクをゆっくりとキャプチャする必要があります。 これを非同期で行うのは簡単です。 今回は、async のmapLimit(arr, limit, iterator, callback) インターフェイスを紹介します。さらに、同時接続数を制御するためによく使用される別のインターフェイス、queue(worker, concurrency) があります。 https://github.com/caolan/async#queueworker-concurrency にアクセスできます。指示のために。 mapLimit(arr, limit, iterator, callback) 接口。另外,还有个常用的控制并发连接数的接口是 queue(worker, concurrency),大家可以去 https://github.com/caolan/async#queueworker-concurrency 看看说明。
这回我就不带大家爬网站了,我们来专注知识点:并发连接数控制。
对了,还有个问题是,什么时候用 eventproxy,什么时候使用 async 呢?它们不都是用来做异步流程控制的吗?
我的答案是:
当你需要去多个源(一般是小于 10 个)汇总数据的时候,用 eventproxy 方便;当你需要用到队列,需要控制并发数,或者你喜欢函数式编程思维时,使用 async。大部分场景是前者,所以我个人大部分时间是用 eventproxy 的。
正题开始。
首先,我们伪造一个 fetchUrl(url, callback) 今回は Web サイトのクロールについては説明しません。同時接続数の制御という知識ポイントに焦点を当てましょう。
ところで、別の質問は、いつeventproxyを使用し、いつasyncを使用するかということです。これらはすべて非同期のプロセス制御
に使用されているのではありませんか? 私の答えは次のとおりです: 複数のソース (通常は 10 未満) にアクセスする必要がある場合 場合データを要約する場合は、eventproxy を使用すると便利です。キューを使用する必要がある場合、同時実行数を制御する必要がある場合、または関数型プログラミングの考え方が必要な場合は、async を使用します。ほとんどのシナリオは前者であるため、私は個人的にはほとんどの場合、eventproxy を使用します。 始めましょう。 まず、
まず、 fetchUrl(url, callback) 関数を作成します。この関数の機能は、
fetchUrl('http://www.baidu.com', function (err, content) {
// do something with `content`
});を通じて呼び出すと http://www.baidu.com を返すことです。ページのコンテンツが戻ります。
もちろん、ここでの返品内容は虚偽であり、返品の遅れはランダムです。呼び出されると、同時に呼び出されている場所の数が表示されます。
// 并发连接数的计数器
var concurrencyCount = 0;
var fetchUrl = function (url, callback) {
// delay 的值在 2000 以内,是个随机的整数
var delay = parseInt((Math.random() * 10000000) % 2000, 10);
concurrencyCount++;
console.log('现在的并发数是', concurrencyCount, ',正在抓取的是', url, ',耗时' + delay + '毫秒');
setTimeout(function () {
concurrencyCount--;
callback(null, url + ' html content');
}, delay);
};その後、リンクのセットを作成します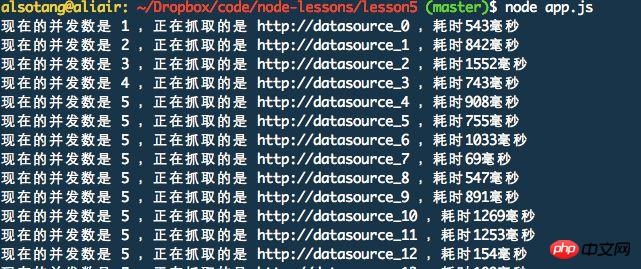
var urls = [];
for(var i = 0; i < 30; i++) {
urls.push('http://datasource_' + i);
}次に、async.mapLimit を使用して、クロールと結果の取得を同時に行います。 async.mapLimit(urls, 5, function (url, callback) {
fetchUrl(url, callback);
}, function (err, result) {
console.log('final:');
console.log(result);
});
この記事のケースを読んだ後は、この方法を習得したと思います。さらに興味深い情報については、PHP 中国語 Web サイトの他の関連記事に注目してください。
以上がノードを操作し、async を使用して同時実行性を制御する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7555
7555
 15
1384
52
83
11
28
96
15
1384
52
83
11
28
96

 PyCharm の使用法チュートリアル: 操作の実行方法を詳しく説明します
Feb 26, 2024 pm 05:51 PM
PyCharm の使用法チュートリアル: 操作の実行方法を詳しく説明します
Feb 26, 2024 pm 05:51 PM
PyCharm は非常に人気のある Python 統合開発環境 (IDE) であり、Python 開発をより効率的かつ便利にするための豊富な機能とツールを提供します。この記事では、PyCharm の基本的な操作方法を紹介し、読者がすぐに使い始めてツールの操作に習熟できるように、具体的なコード例を示します。 1. PyCharm をダウンロードしてインストールします。 まず、PyCharm 公式 Web サイト (https://www.jetbrains.com/pyc) にアクセスする必要があります。
 sudo とは何ですか?なぜ重要ですか?
Feb 21, 2024 pm 07:01 PM
sudo とは何ですか?なぜ重要ですか?
Feb 21, 2024 pm 07:01 PM
sudo (スーパーユーザー実行) は、一般ユーザーが root 権限で特定のコマンドを実行できるようにする、Linux および Unix システムの重要なコマンドです。 sudo の機能は主に次の側面に反映されています。 権限制御の提供: sudo は、ユーザーにスーパーユーザー権限を一時的に取得することを許可することで、システム リソースと機密性の高い操作を厳密に制御します。一般のユーザーは、必要な場合にのみ sudo を介して一時的な権限を取得できるため、常にスーパーユーザーとしてログインする必要はありません。セキュリティの向上: sudo を使用すると、日常的な操作中に root アカウントの使用を回避できます。すべての操作に root アカウントを使用すると、誤った操作や不注意な操作には完全な権限が与えられるため、予期しないシステムの損傷につながる可能性があります。そして
 Linux Deployの操作手順と注意事項
Mar 14, 2024 pm 03:03 PM
Linux Deployの操作手順と注意事項
Mar 14, 2024 pm 03:03 PM
LinuxDeploy の操作手順と注意事項 LinuxDeploy は、ユーザーが Android デバイスにさまざまな Linux ディストリビューションを迅速に展開できるようにする強力なツールで、ユーザーはモバイル デバイスで完全な Linux システムを体験できます。この記事では、LinuxDeploy の操作手順と注意事項を詳しく紹介し、読者がこのツールをより効果的に使用できるように、具体的なコード例を示します。操作手順: Linux のインストールDeploy: まず、インストールします
 Win10 起動パスワードの F2 キーを押すのを忘れた場合の対処方法
Feb 28, 2024 am 08:31 AM
Win10 起動パスワードの F2 キーを押すのを忘れた場合の対処方法
Feb 28, 2024 am 08:31 AM
おそらく多くのユーザーは、自宅に未使用のコンピュータを複数台持っており、長期間使用していなかったためにパワーオン パスワードを完全に忘れてしまったため、パスワードを忘れた場合の対処方法を知りたいと考えています。それでは、一緒に見てみましょう。 win10 起動パスワードの F2 キーを押し忘れた場合の対処方法 1. コンピューターの電源ボタンを押し、コンピューターの電源を入れるときに F2 キーを押します (コンピューターのブランドによって、BIOS に入るボタンが異なります)。 2. BIOS インターフェイスで、セキュリティ オプションを見つけます (コンピューターのブランドによって場所が異なる場合があります)。通常は上部の設定メニューにあります。 3. 次に、「SupervisorPassword」オプションを見つけてクリックします。 4. この時点で、ユーザーは自分のパスワードを確認できると同時に、その横にある [有効] を見つけて [無効] に切り替えることができます。
 PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
ピン張りのノードの詳細な説明とインストールガイドこの記事では、ピネットワークのエコシステムを詳細に紹介します - PIノードは、ピン系生態系における重要な役割であり、設置と構成の完全な手順を提供します。 Pinetworkブロックチェーンテストネットワークの発売後、PIノードは多くの先駆者の重要な部分になり、テストに積極的に参加し、今後のメインネットワークリリースの準備をしています。まだピン張りのものがわからない場合は、ピコインとは何かを参照してください。リストの価格はいくらですか? PIの使用、マイニング、セキュリティ分析。パインワークとは何ですか?ピン競技プロジェクトは2019年に開始され、独占的な暗号通貨PIコインを所有しています。このプロジェクトは、誰もが参加できるものを作成することを目指しています
 iPhone 15 Proおよび15 Pro Maxのアクションボタンを無効にする方法
Nov 07, 2023 am 11:17 AM
iPhone 15 Proおよび15 Pro Maxのアクションボタンを無効にする方法
Nov 07, 2023 am 11:17 AM
Apple は、iPhone 15 Pro と 15 Pro Max に Pro 専用のハードウェア機能をいくつか導入し、みんなの注目を集めました。チタン フレーム、洗練されたデザイン、新しい A17 Pro チップセット、エキサイティングな 5 倍望遠レンズなどについて話します。 iPhone 15 Proモデルに追加されたすべての付加機能の中で、アクションボタンは依然として際立って目立つ機能です。言うまでもなく、iPhone でアクションを起動するのに便利な機能です。ただし、誤ってアクション ボタンを押したままにして、誤って機能をトリガーしてしまう可能性があります。率直に言って、面倒です。これを回避するには、iPhone 15 Pro および 15 Pro Max のアクションボタンを無効にする必要があります。させて
 Huawei Mate60 Proのスクリーンショット操作手順の共有
Mar 23, 2024 am 11:15 AM
Huawei Mate60 Proのスクリーンショット操作手順の共有
Mar 23, 2024 am 11:15 AM
スマートフォンの普及に伴い、スクリーンショット機能は携帯電話を日常的に使用する上で必須のスキルの 1 つになりました。 Huaweiの主力携帯電話の1つであるHuawei Mate60Proのスクリーンショット機能は、当然のことながらユーザーの注目を集めています。今日は、誰もがより便利にスクリーンショットを撮れるように、Huawei Mate60Pro携帯電話のスクリーンショットの操作手順を共有します。まず、Huawei Mate60Pro携帯電話はさまざまなスクリーンショット方法を提供しており、個人の習慣に応じて自分に合った方法を選択できます。以下は、一般的に使用されるいくつかのインターセプトの詳細な紹介です。
 CSS Web ページのスクロール監視: Web ページのスクロール イベントを監視し、対応する操作を実行します。
Nov 18, 2023 am 10:35 AM
CSS Web ページのスクロール監視: Web ページのスクロール イベントを監視し、対応する操作を実行します。
Nov 18, 2023 am 10:35 AM
CSS Web ページのスクロール監視: Web ページのスクロール イベントを監視し、対応する操作を実行します。フロントエンド テクノロジの継続的な開発により、Web ページの効果とインタラクションはますます豊かかつ多様になってきています。その中でも、スクロールモニタリングは、ユーザーがWebページをスクロールするときに、スクロール位置に基づいて何らかの特殊効果や操作を実行できる一般的な技術です。一般に、スクロール監視は JavaScript を通じて実装できます。ただし、場合によっては、純粋な CSS を通じてスクロール監視の効果を実現することもできます。この記事では、CSSを使用してWebページのスクロールを実装する方法を紹介します。
