

この記事では、主に Python 検証コード認識チュートリアルのグレースケール処理、二値化、ノイズ削減、tesserocr 識別について説明します。必要な友達に参考にしてください。
クローラーを書くときに避けられない問題は認証コードです。現在、認証コードのカテゴリーは
画像カテゴリー
クリックカテゴリー
の4種類あります。 type
今日は画像のタイプを見てみましょう。これらの確認コードのほとんどは数字と文字の組み合わせであり、中国では漢字も使用されています。これをベースに、ノイズ、干渉線、変形、重なり、文字の色の違いなどを加えて認識難易度を高めています。
グレースケール処理
コントラストを上げる(オプション)
二値化
ノイズ低減
傾き補正文字をセグメント化する
トレーニングライブラリを構築する
認識
実験的な性質のため、記事で使用されている検証コードはすべて、実際のWebサイト検証コードを一括ダウンロードするのではなく、プログラムで生成されています。利点は、明確な結果を含む多数のデータセットを取得できることです。
最も単純な純粋なデジタルの干渉のない検証コードを生成するには、まず、claptcha.py の 285 行目の _drawLine にいくつかの変更を加える必要があります。この関数に直接 None を返させてから、検証コードの生成を開始します。 :
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')
ここではubuntuのフォントパスに注意する必要があります。他のフォントをオンラインでダウンロードして使用することもできます。検証コードは以下のように生成されます。
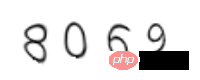 最初のインストール:
最初のインストール:
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev pip install tesserocr
次に、認識を開始します:
from PIL import Image import tesserocr p1 = Image.open('1.png') tesserocr.image_to_text(p1) '8069\n\n'
この単純な検証コードでは、基本的に何も行われないことがわかります。認識されました。率はすでに非常に高いです。興味のある友人は、より多くのデータを使用してテストできますが、ここでは詳しく説明しません。
次に、検証コードの背景にノイズを追加して確認します:c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')
検証コードは次のように生成されます:
p2 = Image.open('2.png') tesserocr.image_to_text(p2) '8069\n\n'

効果大丈夫。次に、英数字の組み合わせが生成されます:
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png')検証コードは次のように生成されます:
3 番目は小文字の o、4 番目は大文字の O、5 番目は大文字です。 1 つは数字の 0 です。6 番目は小文字の z、7 番目は大文字の Z、そして最後の 1 つは数字の 2 です。人間の目はもう跪いているって本当ですか!しかし、現在、一般的な検証コードは大文字と小文字を厳密に区別していません。自動認識がどのようなものかを見てみましょう:
p3 = Image.open('3.png') tesserocr.image_to_text(p3) 'AMOOZW\n\n'
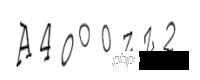 もちろん、人々をひざまずかせるようなコンピューターは役に立ちません。ただし、干渉が小さく、変形がそれほど大きくない場合には、tesserocr を使用するのが非常に簡単で便利です。次に、変更した clptcha.py _drawLine の 285 行目を復元して、干渉ラインが追加されているかどうかを確認します。
もちろん、人々をひざまずかせるようなコンピューターは役に立ちません。ただし、干渉が小さく、変形がそれほど大きくない場合には、tesserocr を使用するのが非常に簡単で便利です。次に、変更した clptcha.py _drawLine の 285 行目を復元して、干渉ラインが追加されているかどうかを確認します。
p4 = Image.open('4.png') tesserocr.image_to_text(p4) ''

def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
処理後の画像は以下の通りです:
次に、共通4の干渉線を除去してみます。 -近傍アルゴリズムおよび8近傍アルゴリズム。いわゆる X 近傍アルゴリズムは、携帯電話の 9 マスのグリッド入力方法を参照できます。ボタン 5 は上下左右を判定するピクセルであり、近傍 8 は判定します。周囲の8ピクセル。この 4 点または 8 点のうち 255 点の数が一定のしきい値より大きい場合、その点はノイズであると判断されます。しきい値は実際の状況に応じて変更できます。
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return img 加工した写真は以下の通りです
加工した写真は以下の通りです

好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:

再进行识别得到了结果:
p7 = Image.open('7.png') tesserocr.image_to_text(p7) '8069 ,,\n\n'
另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
相关推荐:
以上がPython 検証コード認識チュートリアル: グレースケール処理、二値化、ノイズ リダクション、および tesserocr 認識の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



