

pytorch + visdom は単純な分類問題を処理します

この記事は主に pytorch + visdom が簡単な分類問題を処理する方法を紹介します。これには特定の参考値があります。必要な友達はそれを参照してください。
システム: win 10 グラフィック カード。 : gtx965m cpu: i7-6700HQ
python 3.61pytorch 0.3
パッケージリファレンス
import torch
from torch.autograd import Variable
import torch.nn.functional as F
import numpy as np
import visdom
import time
from torch import nn,optim
データ準備
use_gpu = True
ones = np.ones((500,2))
x1 = torch.normal(6*torch.from_numpy(ones),2)
y1 = torch.zeros(500)
x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2)
y2 = y1 +1
x3 = torch.normal(-6*torch.from_numpy(ones),2)
y3 = y1 +2
x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2)
y4 = y1 +3
x = torch.cat((x1, x2, x3 ,x4), 0).float()
y = torch.cat((y1, y2, y3, y4), ).long()
以下のビジュアライゼーションを見てください:
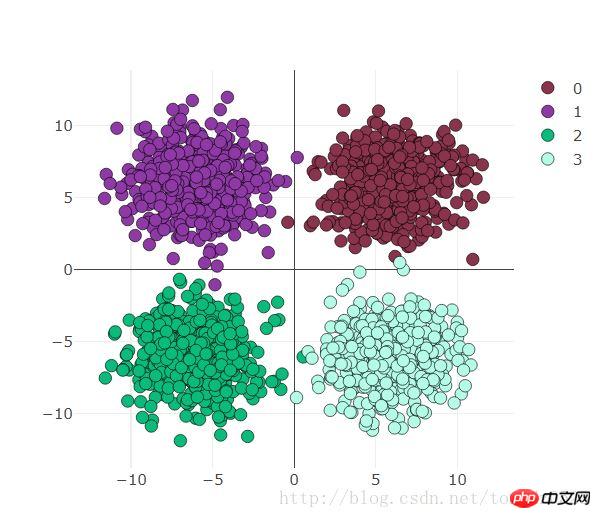 視覚化の準備
視覚化の準備
まず観察する必要があるウィンドウを作成します
viz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
)効果は次のとおりです:
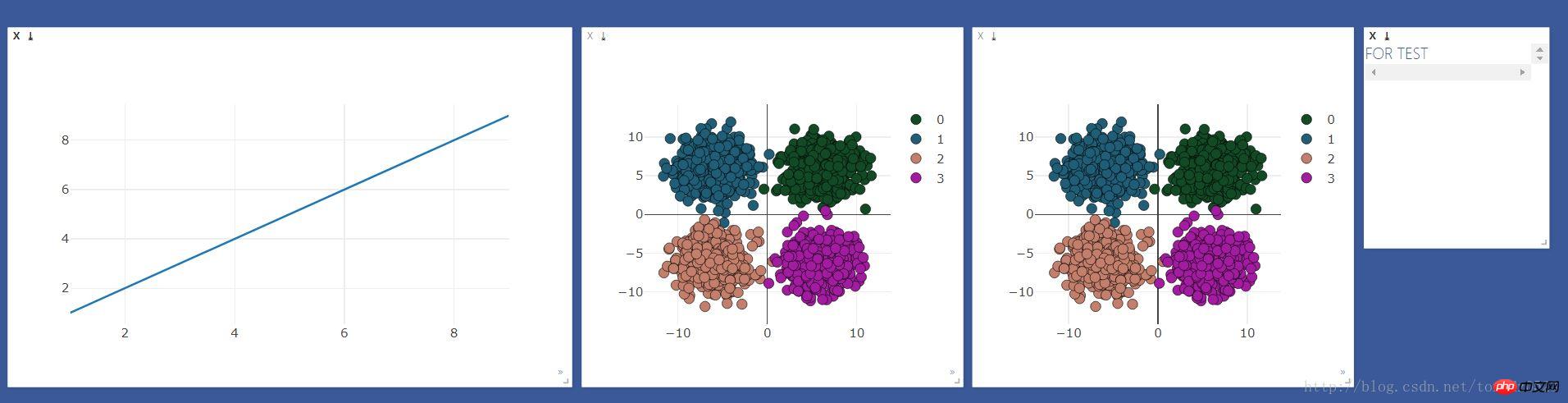 処理
処理
入力2、出力4
logstic = nn.Sequential( nn.Linear(2,4) )
GPUまたはCPUの選択:
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")オプティマイザと損失関数:
loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
2000回トレーニング:
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()トレーニングの観察と視覚化:
if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
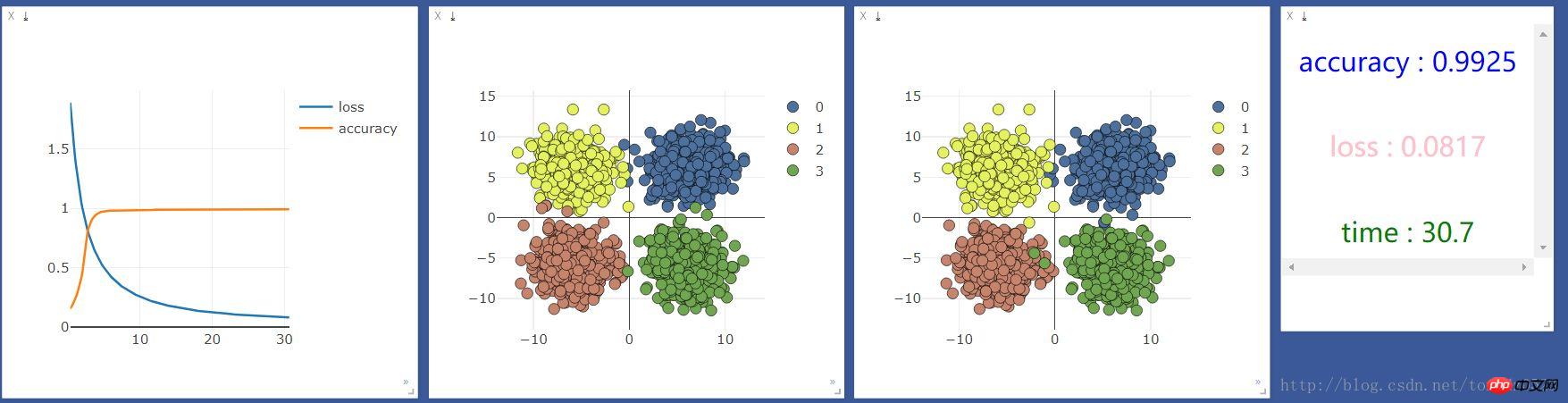
.format(accuracy,loss.data[0],time.time()-start_time),win =text)最初に CPU で実行した結果は次のようになります:
次に GPU で実行した結果は次のようになります: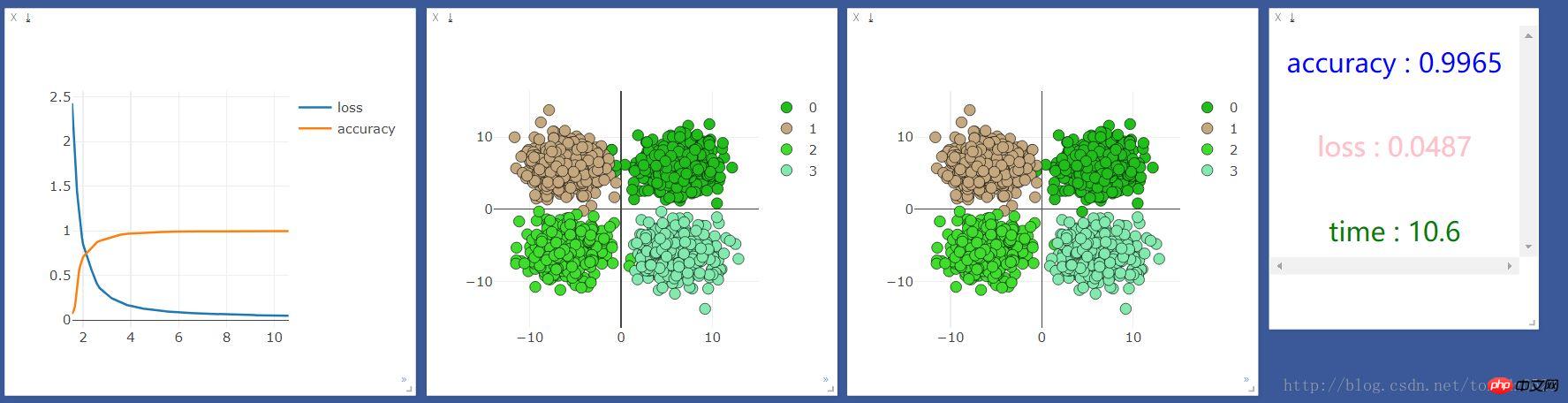
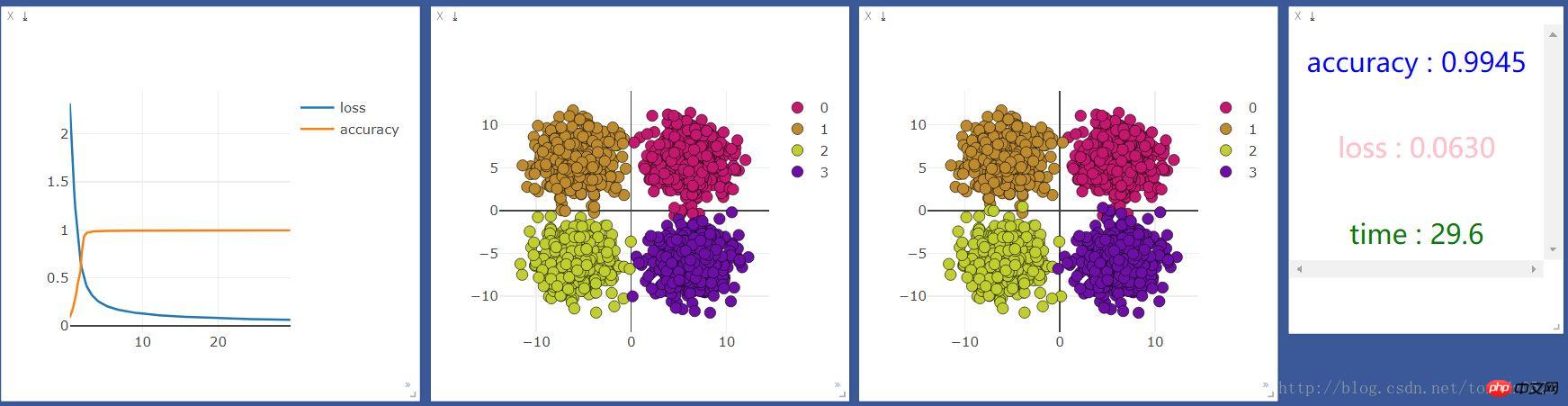

net = nn.Sequential(
nn.Linear(2, 10),
nn.ReLU(), #激活函数
nn.Linear(10, 4)
)
10 ユニットのニューラル層を追加し、効果が向上するかどうかを確認します:
CPU を使用する: GPU を使用する: 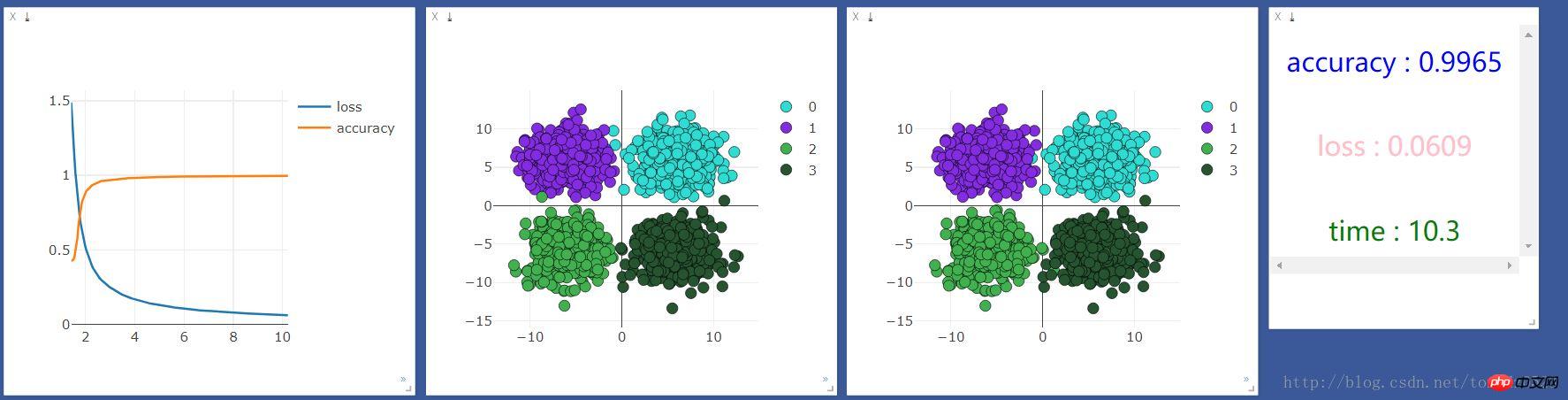
 関連する推奨事項:
関連する推奨事項:
回帰と分類を実装するために PyTorch で単純なニューラル ネットワークを構築する例
PyTorch のバッチ トレーニングとオプティマイザーの比較の詳細な説明
以上がpytorch + visdom は単純な分類問題を処理しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7909
7909
 15
1652
14
1411
52
1303
25
1248
29
15
1652
14
1411
52
1303
25
1248
29

 iFlytek: ファーウェイの Ascend 910B の機能は基本的に Nvidia の A100 に匹敵しており、我が国の汎用人工知能の新しい基盤を構築するために協力しています。
Oct 22, 2023 pm 06:13 PM
iFlytek: ファーウェイの Ascend 910B の機能は基本的に Nvidia の A100 に匹敵しており、我が国の汎用人工知能の新しい基盤を構築するために協力しています。
Oct 22, 2023 pm 06:13 PM
本サイトは10月22日、今年第3四半期にiFlytekの純利益は2579万元で、前年同期比81.86%減少し、最初の3四半期の純利益は9936万元で、過去最高を記録したと報じた。前年比76.36%減。 iFlytekのJiang Tao副社長は、第3四半期の業績説明会で、iFlytekが2023年初めにHuawei Shengtengとの特別研究プロジェクトを立ち上げ、中国の一般的な人工知能の新しい基盤を共同で構築するためにHuaweiと高性能オペレータライブラリを共同開発したことを明らかにした。独自の革新的なソフトウェアとハードウェアによるアーキテクチャを採用し、国内の大規模モデルの使用を可能にします。同氏は、ファーウェイのAscend 910Bの現在の機能は基本的にNvidiaのA100に匹敵すると指摘した。次回開催される iFlytek 1024 グローバル デベロッパー フェスティバルで、iFlytek と Huawei は人工知能コンピューティングのパワー ベースについてさらなる共同発表を行う予定です。彼はまた、次のようにも述べました。
 PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm は強力な統合開発環境 (IDE) であり、PyTorch はディープ ラーニングの分野で人気のあるオープン ソース フレームワークです。機械学習とディープラーニングの分野では、開発に PyCharm と PyTorch を使用すると、開発効率とコード品質が大幅に向上します。この記事では、PyCharm に PyTorch をインストールして構成する方法を詳しく紹介し、読者がこれら 2 つの強力な機能をより効果的に活用できるように、具体的なコード例を添付します。ステップ 1: PyCharm と Python をインストールする
 自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクと Pytorch コード実装における 5 つのサンプリング方法の紹介
Feb 20, 2024 am 08:50 AM
自然言語生成タスクにおいて、サンプリング法は生成モデルからテキスト出力を取得する手法です。この記事では、5 つの一般的なメソッドについて説明し、PyTorch を使用してそれらを実装します。 1. 貪欲復号 貪欲復号では、生成モデルは入力シーケンスに基づいて出力シーケンスの単語を時間ごとに予測します。各タイム ステップで、モデルは各単語の条件付き確率分布を計算し、最も高い条件付き確率を持つ単語を現在のタイム ステップの出力として選択します。このワードは次のタイム ステップへの入力となり、指定された長さのシーケンスや特別な終了マーカーなど、何らかの終了条件が満たされるまで生成プロセスが続行されます。 GreedyDecoding の特徴は、毎回現在の条件付き確率が最良になることです。
 PyTorchを使用したノイズ除去拡散モデルの実装
Jan 14, 2024 pm 10:33 PM
PyTorchを使用したノイズ除去拡散モデルの実装
Jan 14, 2024 pm 10:33 PM
ノイズ除去拡散確率モデル (DDPM) の動作原理を詳細に理解する前に、まず、DDPM の基礎研究の 1 つである生成人工知能の開発の一部を理解しましょう。 VAEVAE は、エンコーダー、確率的潜在空間、およびデコーダーを使用します。トレーニング中に、エンコーダーは各画像の平均と分散を予測し、ガウス分布からこれらの値をサンプリングします。サンプリングの結果はデコーダに渡され、入力画像が出力画像と同様の形式に変換されます。 KL ダイバージェンスは損失の計算に使用されます。 VAE の大きな利点は、多様な画像を生成できることです。サンプリング段階では、ガウス分布から直接サンプリングし、デコーダを通じて新しい画像を生成できます。 GAN は、わずか 1 年で変分オートエンコーダ (VAE) において大きな進歩を遂げました。
 PyTorch を使用した PyCharm のインストールに関するチュートリアル
Feb 24, 2024 am 10:09 AM
PyTorch を使用した PyCharm のインストールに関するチュートリアル
Feb 24, 2024 am 10:09 AM
PyTorch は、強力な深層学習フレームワークとして、さまざまな機械学習プロジェクトで広く使用されています。強力な Python 統合開発環境として、PyCharm はディープ ラーニング タスクを実装するときに優れたサポートも提供します。この記事では、PyTorch を PyCharm にインストールする方法を詳しく紹介し、読者が深層学習タスクに PyTorch をすぐに使い始めるのに役立つ具体的なコード例を示します。ステップ 1: PyCharm をインストールする まず、PyCharm がインストールされていることを確認する必要があります。
 非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
非常に高速! 10 行未満のコードを使用して、わずか数分でビデオ音声を認識してテキストに変換します
Feb 27, 2024 pm 01:55 PM
皆さん、こんにちは。私は Kite です。2 年前には、オーディオ ファイルとビデオ ファイルをテキスト コンテンツに変換する必要性を実現するのは困難でしたが、今ではわずか数分で簡単に解決できるようになりました。一部の企業では、トレーニングデータを取得するために、DouyinやKuaishouなどのショートビデオプラットフォーム上のビデオをフルクロールし、ビデオから音声を抽出してテキスト形式に変換し、ビッグデータのトレーニングコーパスとして使用していると言われていますモデル。ビデオまたはオーディオ ファイルをテキストに変換する必要がある場合は、現在利用可能なこのオープン ソース ソリューションを試すことができます。たとえば、映画やテレビ番組のセリフが登場する特定の時点を検索できます。早速、本題に入りましょう。 Whisper は OpenAI のオープンソース Whisper で、もちろん Python で書かれており、必要なのはいくつかの簡単なインストール パッケージだけです。
 PHP と PyTorch によるディープラーニング
Jun 19, 2023 pm 02:43 PM
PHP と PyTorch によるディープラーニング
Jun 19, 2023 pm 02:43 PM
ディープラーニングは人工知能分野の重要な分野であり、近年ますます注目を集めています。深層学習の研究と応用を実施できるようにするには、多くの場合、それを達成するためにいくつかの深層学習フレームワークを使用する必要があります。この記事では、PHPとPyTorchを使ってディープラーニングを行う方法を紹介します。 1. PyTorch とは何ですか? PyTorch は Facebook が開発したオープンソースの機械学習フレームワークで、深層学習モデルを迅速に作成してトレーニングするのに役立ちます。 PyTorc
 GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
GQA、大規模モデルで一般的に使用されるアテンション メカニズム、および Pytorch コードの実装の詳細な説明
Apr 03, 2024 pm 05:40 PM
グループ化クエリ アテンション (GroupedQueryAttendant) は、大規模言語モデルにおけるマルチクエリ アテンション メソッドであり、その目標は、MQA の速度を維持しながら MHA の品質を達成することです。 GroupedQueryAttendant はクエリをグループ化し、各グループ内のクエリは同じアテンションの重みを共有するため、計算の複雑さが軽減され、推論速度が向上します。この記事では、GQAの考え方とそれをコードに変換する方法について説明します。 GQA は論文「GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint」に掲載されています
