

pytorch + visdom 独自に構築した画像データセットを処理する CNN 方法

この記事では主に、自作の画像データセットを処理するための pytorch + visdom CNN の方法を紹介します。必要な友達はそれを参照できるようにしました
。システム: win10
cpu: i7-6700HQgpu: gtx965mpython: 3.6pytorch: 0.3 データのダウンロードSasank Chilamkurthy のチュートリアルから出典データ: ダウンロードリンク。
ダウンロードして解凍し、プロジェクトのルート ディレクトリに置きます:
 このデータ セットは、アリとミツバチを分類するために使用されます。各クラスには約 120 個のトレーニング画像と 75 個の検証画像があります。
このデータ セットは、アリとミツバチを分類するために使用されます。各クラスには約 120 個のトレーニング画像と 75 個の検証画像があります。
データインポート
torchvision.datasets.ImageFolder(root,transforms) モジュールを使用して、イメージをテンソルに変換できます。
最初に変換を定義します:
ata_transforms = {
'train': transforms.Compose([
# 随机切成224x224 大小图片 统一图片格式
transforms.RandomResizedCrop(224),
# 图像翻转
transforms.RandomHorizontalFlip(),
# totensor 归一化(0,255) >> (0,1) normalize channel=(channel-mean)/std
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
"val" : transforms.Compose([
# 图片大小缩放 统一图片格式
transforms.Resize(256),
# 以中心裁剪
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}data_dir = './hymenoptera_data'
# trans data
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in ['train', 'val']}
# load data
data_loaders = {x: DataLoader(image_datasets[x], batch_size=BATCH_SIZE, shuffle=True) for x in ['train', 'val']}
data_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
print(data_sizes, class_names){'train': 244, 'val': 153} ['ants', 'bees']inputs, classes = next(iter(data_loaders['val'])) out = torchvision.utils.make_grid(inputs) inp = torch.transpose(out, 0, 2) mean = torch.FloatTensor([0.485, 0.456, 0.406]) std = torch.FloatTensor([0.229, 0.224, 0.225]) inp = std * inp + mean inp = torch.transpose(inp, 0, 2) viz.images(inp)
 処理に基づいて CNN
処理に基づいて CNN
ネットを作成します。前回の記事の cifar10 の仕様を変更しました:
class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
self.cnn = nn.Sequential(
nn.BatchNorm2d(in_dim),
nn.ReLU(True),
nn.Conv2d(in_dim, 16, 7), # 224 >> 218
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2), # 218 >> 109
nn.ReLU(True),
nn.Conv2d(16, 32, 5), # 105
nn.BatchNorm2d(32),
nn.ReLU(True),
nn.Conv2d(32, 64, 5), # 101
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(2, 2), # 101 >> 50
nn.Conv2d(64, 128, 3, 1, 1), #
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(3), # 50 >> 16
)
self.fc = nn.Sequential(
nn.Linear(128*16*16, 120),
nn.BatchNorm1d(120),
nn.ReLU(True),
nn.Linear(120, n_class))
def forward(self, x):
out = self.cnn(x)
out = self.fc(out.view(-1, 128*16*16))
return out
# 输入3层rgb ,输出 分类 2
model = CNN(3, 2)line = viz.line(Y=np.arange(10)) loss_f = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=LR, momentum=0.9) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
BATCH_SIZE = 4 LR = 0.001 EPOCHS = 10
りー
Run 20 見てください: 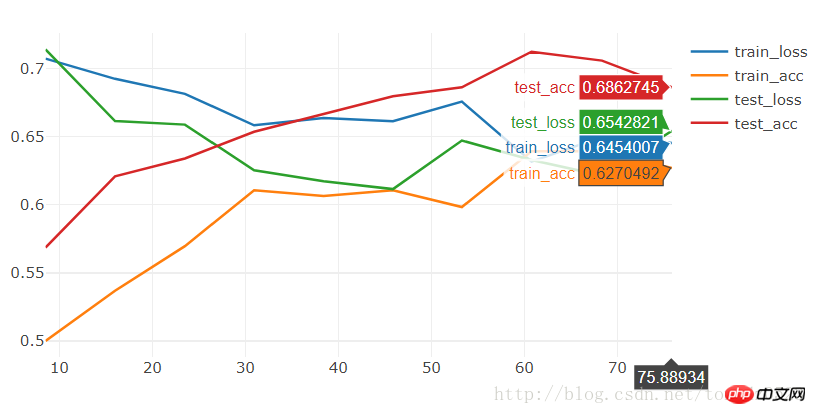
[9/10] train_loss:0.650|train_acc:0.639|test_loss:0.621|test_acc0.706 [10/10] train_loss:0.645|train_acc:0.627|test_loss:0.654|test_acc0.686 Training complete in 1m 16s Best val Acc: 0.712418
精度は比較的低く、わずか 74.5% です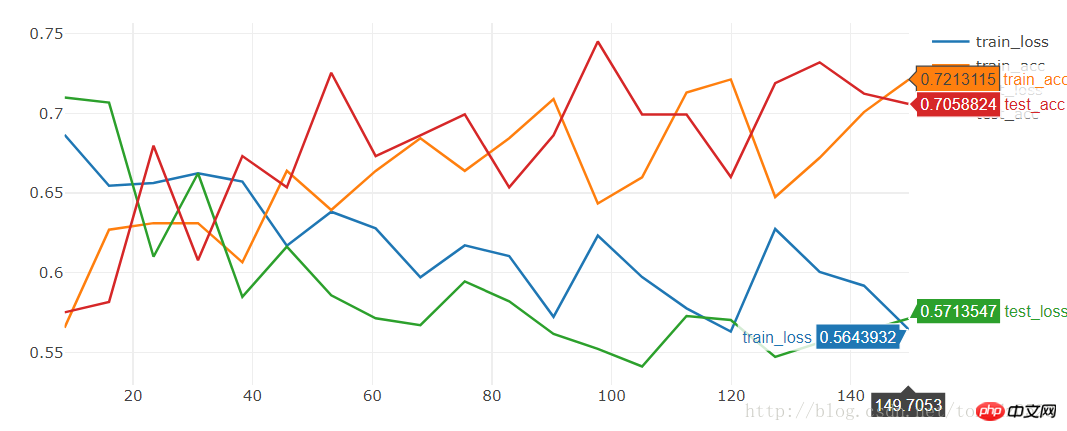
[19/20] train_loss:0.592|train_acc:0.701|test_loss:0.563|test_acc0.712 [20/20] train_loss:0.564|train_acc:0.721|test_loss:0.571|test_acc0.706 Training complete in 2m 30s Best val Acc: 0.745098
model = torchvision.models.resnet18(True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
[9/10] train_loss:0.621|train_acc:0.652|test_loss:0.588|test_acc0.667 [10/10] train_loss:0.610|train_acc:0.680|test_loss:0.561|test_acc0.667 Training complete in 1m 24s Best val Acc: 0.686275
model = torchvision.models.resnet18(pretrained=True) num_ftrs = model.fc.in_features model.fc = nn.Linear(num_ftrs, 2)
関連する推奨事項: 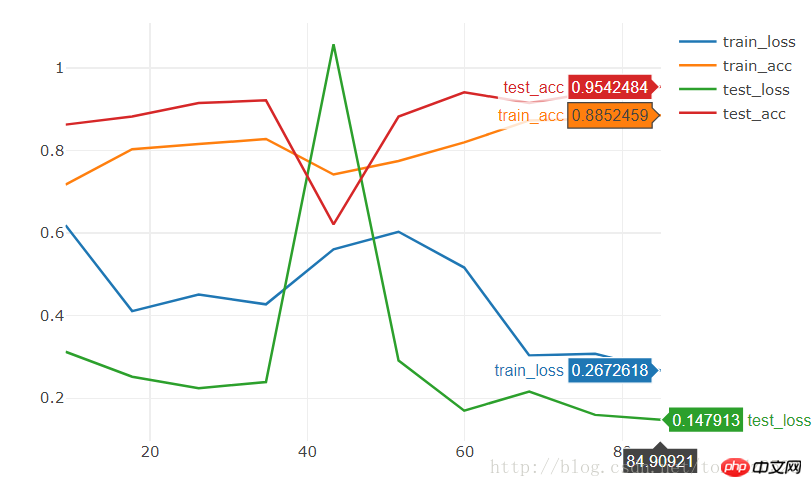
pytorch + visdom は簡単な分類問題を処理します
以上がpytorch + visdom 独自に構築した画像データセットを処理する CNN 方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7683
7683
 15
1639
14
1393
52
1286
25
1229
29
15
1639
14
1393
52
1286
25
1229
29

 小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか?投稿時に自動保存された画像はどこにありますか?
Mar 22, 2024 am 08:06 AM
小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか?投稿時に自動保存された画像はどこにありますか?
Mar 22, 2024 am 08:06 AM
ソーシャルメディアの継続的な発展に伴い、Xiaohongshu はますます多くの若者が自分たちの生活を共有し、美しいものを発見するためのプラットフォームとなっています。多くのユーザーは、画像を投稿する際の自動保存の問題に悩まされています。では、この問題をどうやって解決すればよいでしょうか? 1.小紅書で公開するときに写真が自動的に保存される問題を解決するにはどうすればよいですか? 1. キャッシュをクリアする まず、Xiaohongshu のキャッシュ データをクリアしてみます。手順は次のとおりです: (1) 小紅書を開いて右下隅の「マイ」ボタンをクリックします。 (2) 個人センター ページで「設定」を見つけてクリックします。 (3) 下にスクロールして「」を見つけます。 「キャッシュをクリア」オプションを選択し、「OK」をクリックします。キャッシュをクリアした後、Xiaohongshu を再起動し、写真を投稿して、自動保存の問題が解決されるかどうかを確認します。 2. 小紅書バージョンを更新して、小紅書が正しく動作することを確認します。
 TikTokのコメントに写真を投稿するにはどうすればよいですか?コメント欄の写真への入り口はどこですか?
Mar 21, 2024 pm 09:12 PM
TikTokのコメントに写真を投稿するにはどうすればよいですか?コメント欄の写真への入り口はどこですか?
Mar 21, 2024 pm 09:12 PM
Douyin のショートビデオの人気により、コメント エリアでのユーザーのやり取りがより多彩になりました。ユーザーの中には、自分の意見や感情をよりよく表現するために、コメントで画像を共有したいと考えている人もいます。では、TikTokのコメントに写真を投稿するにはどうすればよいでしょうか?この記事では、この質問に詳しく答え、関連するヒントと注意事項をいくつか紹介します。 1.Douyinのコメントに写真を投稿するにはどうすればよいですか? 1. Douyinを開く: まず、Douyin APPを開いてアカウントにログインする必要があります。 2. コメントエリアを見つける:短いビデオを閲覧または投稿するときに、コメントしたい場所を見つけて「コメント」ボタンをクリックします。 3. コメントの内容を入力します: コメント領域にコメントの内容を入力します。 4. 写真の送信を選択します。コメント内容を入力するインターフェースに「写真」ボタンまたは「+」ボタンが表示されます。
 PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm と PyTorch の完璧な組み合わせ: 詳細なインストールと構成手順
Feb 21, 2024 pm 12:00 PM
PyCharm は強力な統合開発環境 (IDE) であり、PyTorch はディープ ラーニングの分野で人気のあるオープン ソース フレームワークです。機械学習とディープラーニングの分野では、開発に PyCharm と PyTorch を使用すると、開発効率とコード品質が大幅に向上します。この記事では、PyCharm に PyTorch をインストールして構成する方法を詳しく紹介し、読者がこれら 2 つの強力な機能をより効果的に活用できるように、具体的なコード例を添付します。ステップ 1: PyCharm と Python をインストールする
 iPhone で写真をより鮮明にする 6 つの方法
Mar 04, 2024 pm 06:25 PM
iPhone で写真をより鮮明にする 6 つの方法
Mar 04, 2024 pm 06:25 PM
Apple の最近の iPhone は、鮮明なディテール、彩度、明るさで思い出を捉えます。ただし、場合によっては、画像が鮮明に見えなくなる問題が発生することがあります。 iPhone カメラのオートフォーカスは大きく進歩し、写真をすばやく撮影できるようになりましたが、状況によってはカメラが誤って間違った被写体に焦点を合わせ、不要な領域で写真がぼやけてしまうことがあります。 iPhone 上の写真の焦点が合っていない場合、または全体的に鮮明さが欠けている場合は、次の投稿を参照して写真を鮮明にすることができます。 iPhone で写真を鮮明にする方法 [6 つの方法] ネイティブの写真アプリを使用して写真をクリーンアップしてみることができます。さらに多くの機能やオプションが必要な場合
 PPT画像を1枚ずつ表示させる方法
Mar 25, 2024 pm 04:00 PM
PPT画像を1枚ずつ表示させる方法
Mar 25, 2024 pm 04:00 PM
PowerPoint では、画像を 1 枚ずつ表示するのが一般的な手法ですが、これはアニメーション効果を設定することで実現できます。このガイドでは、基本的なセットアップ、画像の挿入、アニメーションの追加、アニメーションの順序とタイミングの調整など、この手法を実装する手順について詳しく説明します。さらに、トリガーの使用、アニメーションの速度と順序の調整、アニメーション効果のプレビューなど、高度な設定と調整が提供されます。これらの手順とヒントに従うことで、ユーザーは PowerPoint で次々に表示される画像を簡単に設定できるため、プレゼンテーションの視覚的な効果が高まり、聴衆の注意を引くことができます。
 Web ページ上の画像を読み込めない場合はどうすればよいですか? 6つのソリューション
Mar 15, 2024 am 10:30 AM
Web ページ上の画像を読み込めない場合はどうすればよいですか? 6つのソリューション
Mar 15, 2024 am 10:30 AM
一部のネチズンは、ブラウザの Web ページを開いたときに、Web ページ上の画像が長時間読み込めないことに気づきました。何が起こったのでしょうか?ネットワークは正常であることを確認しましたが、どこに問題があるのでしょうか?以下のエディタでは、Web ページの画像が読み込めない問題に対する 6 つの解決策を紹介します。 Web ページの画像を読み込めない: 1. インターネット速度の問題 Web ページに画像が表示されません。これは、コンピュータのインターネット速度が比較的遅く、コンピュータ上で開いているソフトウェアが多いためと考えられます。また、アクセスする画像が比較的大きいため、読み込みタイムアウトが原因である可能性があります。その結果、画像が表示されません。ネットワーク速度をより多く消費するソフトウェアをオフにすることができます。タスク マネージャーに移動して確認できます。 2. 訪問者が多すぎる Web ページに写真が表示されない場合は、訪問した Web ページが同時に訪問されたことが原因である可能性があります。
 HTML、CSS、jQuery を使用して画像の結合と表示の高度な機能を実装する方法
Oct 27, 2023 pm 04:36 PM
HTML、CSS、jQuery を使用して画像の結合と表示の高度な機能を実装する方法
Oct 27, 2023 pm 04:36 PM
HTML、CSS、jQuery を使用して画像結合表示を実装する方法の高度な機能の概要: Web デザインにおいて、画像表示は重要なリンクであり、画像結合表示はページの読み込み速度を向上させ、ユーザー エクスペリエンスを向上させるための一般的な手法の 1 つです。この記事では、HTML、CSS、jQuery を使用して画像の結合と表示の高度な機能を実装する方法と、具体的なコード例を紹介します。 1. HTML レイアウト: まず、結合された画像を表示するコンテナを HTML で作成する必要があります。ディを使用できます
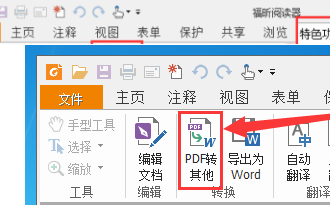 Foxit PDF Reader で PDF ドキュメントを jpg 画像に変換する方法 - Foxit PDF Reader で PDF ドキュメントを jpg 画像に変換する方法
Mar 04, 2024 pm 05:49 PM
Foxit PDF Reader で PDF ドキュメントを jpg 画像に変換する方法 - Foxit PDF Reader で PDF ドキュメントを jpg 画像に変換する方法
Mar 04, 2024 pm 05:49 PM
Foxit PDF Reader ソフトウェアも使用していますか? Foxit PDF Reader が PDF ドキュメントを jpg 画像に変換する方法をご存知ですか? 次の記事では、Foxit PDF Reader が PDF ドキュメントを jpg 画像に変換する方法について説明します。 jpg画像は以下からご覧ください。まずFoxit PDF Readerを起動し、上部のツールバーで「機能」を見つけ、「PDF to Others」機能を選択します。次に、「Foxit PDF Online Conversion」というWebページを開きます。ページ右上の「ログイン」ボタンをクリックしてログインし、「PDF to Image」機能をオンにしてください。次にアップロードボタンをクリックし、画像に変換したいPDFファイルを追加し、追加後「変換開始」をクリックします。
