

この記事では主に、いくつかの列の組み合わせに応じてデータをフィルタリングするパンダの方法を紹介します。必要な友達に参考にしてもらいましょう
。
A ファイル:
 たとえば、「設計井戸タイプ」、「生産井戸タイプ」、「現在の井戸タイプ」の 3 つの列のデータをフィルタリングして除外したいと考えています。結果は次のとおりです。
たとえば、「設計井戸タイプ」、「生産井戸タイプ」、「現在の井戸タイプ」の 3 つの列のデータをフィルタリングして除外したいと考えています。結果は次のとおりです。
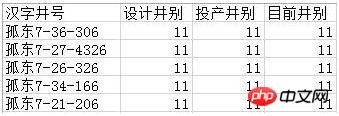 もちろん、ここでのフィルタリング条件はユーザーのニーズに応じて自由に調整できます。 コードは次のとおりです。
もちろん、ここでのフィルタリング条件はユーザーのニーズに応じて自由に調整できます。 コードは次のとおりです。
# -*- coding: utf-8 -*- """ Created on Wed Nov 29 10:46:31 2017 @author: wq """ import pandas as pd #input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 #这里的筛选条件可以根据用户需要进行修改 outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')] outfile.to_csv('outfile.csv', index=False, encoding='gbk')
場合によっては、逆の要件があり、削除する必要があることもあります。 「設計井戸カテゴリ」、「生産井戸カテゴリ」、および「現在の井戸カテゴリ」 データの 3 つの列がすべて 11 である行の場合、結果は次のようになります:

コードは次のとおりです。
#input.csv是那个大文件,有很多很多行 df1 = pd.read_csv(u'input.csv', encoding='gbk') df2 = pd.read_csv(u'outfile.csv', encoding='gbk') #加encoding=‘gbk'是因为文件中存在中文,不加可能出现乱码 index = ~df1[u'汉字井号'].isin(df2[u'汉字井号']) df4 = df1[index] df4.to_csv('outfile1.csv', index=False, encoding='gbk')
以上が複数の列の組み合わせに基づいてデータをフィルタリングする Pandas メソッドの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



