

Puppeteer 画像認識テクノロジーを使用して Baidu インデックス クローラーを実装する方法
この記事では、Node Puppeteer 画像認識を使用して Baidu インデックス クローラーを実装する例を主に紹介します。編集者はそれが非常に優れていると考えたので、参考として共有します。編集者をフォローして見てみましょう
以前、さまざまな大手メーカーのフロントエンドのクロール対策技術を紹介した啓発的な記事を読みましたが、この記事にあるように、100% のクロール対策方法はありません。記事 これらのフロントエンドのクローラー対策メソッドをすべてバイパスする簡単な方法を紹介します。
次のコードは Baidu Index を例にしています。コードは Baidu Index クローラー ノード ライブラリにパッケージ化されています: https://github.com/Coffcer/baidu-index-spider
注: クローラーを悪用しないでください。
Baidu Index のクローラー対策戦略
Baidu Index のインターフェイスを観察すると、特定の日にマウスを置くと、2 つのリクエストがトリガーされます。結果はフローティング ボックスに表示されます:
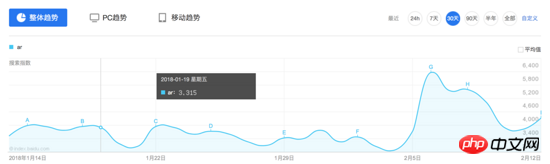
一般的な考え方に従って、まずこのリクエストの内容を見てみましょう:
リクエスト 1:
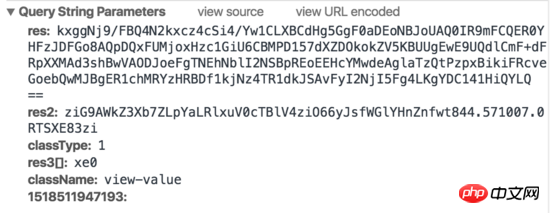
リクエスト 2:

Baidu Index が実際にフロントエンドのクローラー対策戦略に何らかの取り組みを行っていることがわかります。マウスがグラフ上に移動すると、2 つのリクエストがトリガーされ、1 つのリクエストは HTML を返し、もう 1 つのリクエストは生成された画像を返します。 html には実際の値は含まれていませんが、width と margin-left を設定することで、対応する文字が画像上に表示されます。さらに、リクエストパラメータには res や res1 など、シミュレート方法が不明なパラメータが含まれているため、従来のシミュレートされたリクエストや HTML クローリング方法を使用して Baidu Index データをクロールすることは困難です。
クローラーの考え
Baidu のクローラー対策方法を突破するにはどうすればよいでしょうか? それは実際には非常に簡単です。クローラー対策方法については気にしないでください。ユーザーの操作をシミュレートし、必要な値をスクリーンショットし、画像認識を行うだけで済みます。手順は大まかに:
ログインをシミュレートする
インデックスページを開く
指定した日付にマウスを移動する
リクエストが終了するのを待ち、数値部分の画像を傍受する
値を取得するための画像認識
-
ステップ 3 から 5 をループして、各日付に対応する値を取得します
このメソッドは理論的にはあらゆる Web サイトのコンテンツをクロールできます。 次に、次のようにクローラ ステップを実装します。次のライブラリが使用されます:
puppeteer ブラウザ操作をシミュレート
node-tesseract tesseractパッケージ、画像認識に使用されます
jimp 画像のトリミング
インストールPuppeteer 、ユーザー操作をシミュレートします
Puppeteer は、Google Chrome チームによって作成された Chrome 自動化ツールで、Chrome の実行コマンドを制御するために使用されます。ユーザー操作をシミュレートしたり、自動テストやクローラーなどを実行したりできます。使い方はとても簡単です。この記事を読めば使い方がわかると思います。
API ドキュメント: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
インストール:
npm install --save puppeteer
Puppeteer は、正常な動作を確保するために、インストール中に Chromium を自動的にダウンロードします。ただし、国内ネットワークでは Chromium を正常にダウンロードできない場合があります。ダウンロードに失敗した場合は、cnpm を使用してインストールするか、ダウンロード アドレスを Taobao ミラーに変更してからインストールすることができます:
npm config set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors npm install --save puppeteer
Chromium のダウンロードをスキップすることもできます。インストール中にコードを渡します 実行するネイティブ Chrome パスを指定します:
// npm
npm install --save puppeteer --ignore-scripts
// node
puppeteer.launch({ executablePath: '/path/to/Chrome' });implementation
レイアウトをきれいに保つために、セレクターに関係するコードの部分のみを以下に示します。完全なコードについては、記事の上部にある github リポジトリを参照してください。
Baidu Index ページを開いてログインをシミュレートします
ここで行うのは、ユーザーの操作、クリックと入力を段階的にシミュレートすることです。ログイン認証コードを処理する必要はありません。認証コードの処理は別のトピックです。Baidu にローカルでログインしている場合、通常は認証コードは必要ありません。
// 启动浏览器,
// headless参数如果设置为true,Puppeteer将在后台操作你Chromium,换言之你将看不到浏览器的操作过程
// 设为false则相反,会在你电脑上打开浏览器,显示浏览器每一操作。
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
// 打开百度指数
await page.goto(BAIDU_INDEX_URL);
// 模拟登陆
await page.click('...');
await page.waitForSelecto('...');
// 输入百度账号密码然后登录
await page.type('...','username');
await page.type('...','password');
await page.click('...');
await page.waitForNavigation();
console.log(':white_check_mark: 登录成功');マウスの移動をシミュレートして必要なデータを取得します
ページをトレンドチャート領域までスクロールし、マウスを特定の日付に移動し、リクエストが終了するまで待ちます。ツールチップに値が表示されます。そしてスクリーンショットを撮って画像を保存します。
// 获取chart第一天的坐标
const position = await page.evaluate(() => {
const $image = document.querySelector('...');
const $area = document.querySelector('...');
const areaRect = $area.getBoundingClientRect();
const imageRect = $image.getBoundingClientRect();
// 滚动到图表可视化区域
window.scrollBy(0, areaRect.top);
return { x: imageRect.x, y: 200 };
});
// 移动鼠标,触发tooltip
await page.mouse.move(position.x, position.y);
await page.waitForSelector('...');
// 获取tooltip信息
const tooltipInfo = await page.evaluate(() => {
const $tooltip = document.querySelector('...');
const $title = $tooltip.querySelector('...');
const $value = $tooltip.querySelector('...');
const valueRect = $value.getBoundingClientRect();
const padding = 5;
return {
title: $title.textContent.split(' ')[0],
x: valueRect.x - padding,
y: valueRect.y,
width: valueRect.width + padding * 2,
height: valueRect.height
}
});スクリーンショット
値の座標を計算し、スクリーンショットを撮り、jimp を使用して画像をトリミングします。
await page.screenshot({ path: imgPath });
// 对图片进行裁剪,只保留数字部分
const img = await jimp.read(imgPath);
await img.crop(tooltipInfo.x, tooltipInfo.y, tooltipInfo.width, tooltipInfo.height);
// 将图片放大一些,识别准确率会有提升
await img.scale(5);
await img.write(imgPath);画像認識
ここでは、画像認識に Tesseract を使用します。 Tesseracts は、画像内のテキストを識別するために使用され、トレーニングを通じて精度を向上させることができる、Google のオープンソース OCR ツールです。すでに github に単純なノード パッケージが存在します:node-tesseract。まず Tesseract をインストールし、環境変数に設定する必要があります。
Tesseract.process(imgPath, (err, val) => {
if (err || val == null) {
console.error(':x: 识别失败:' + imgPath);
return;
}
console.log(val);实际上未经训练的Tesseracts识别起来会有少数几个错误,比如把9开头的数字识别成`3,这里需要通过训练去提升Tesseracts的准确率,如果识别过程出现的问题都是一样的,也可以简单通过正则去修复这些问题。
封装
实现了以上几点后,只需组合起来就可以封装成一个百度指数爬虫node库。当然还有许多优化的方法,比如批量爬取,指定天数爬取等,只要在这个基础上实现都不难了。
const recognition = require('./src/recognition');
const Spider = require('./src/spider');
module.exports = {
async run (word, options, puppeteerOptions = { headless: true }) {
const spider = new Spider({
imgDir,
...options
}, puppeteerOptions);
// 抓取数据
await spider.run(word);
// 读取抓取到的截图,做图像识别
const wordDir = path.resolve(imgDir, word);
const imgNames = fs.readdirSync(wordDir);
const result = [];
imgNames = imgNames.filter(item => path.extname(item) === '.png');
for (let i = 0; i < imgNames.length; i++) {
const imgPath = path.resolve(wordDir, imgNames[i]);
const val = await recognition.run(imgPath);
result.push(val);
}
return result;
}
}反爬虫
最后,如何抵挡这种爬虫呢,个人认为通过判断鼠标移动轨迹可能是一种方法。当然前端没有100%的反爬虫手段,我们能做的只是给爬虫增加一点难度。
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
在Node.js中使用cheerio制作简单的网页爬虫(详细教程)
在React中使用Native如何实现自定义下拉刷新上拉加载的列表
以上がPuppeteer 画像認識テクノロジーを使用して Baidu インデックス クローラーを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7529
7529
 15
1378
52
81
11
21
75
15
1378
52
81
11
21
75

 Express を使用してノード プロジェクトでファイルのアップロードを処理する方法
Mar 28, 2023 pm 07:28 PM
Express を使用してノード プロジェクトでファイルのアップロードを処理する方法
Mar 28, 2023 pm 07:28 PM
ファイルのアップロードをどのように処理するか?次の記事では、Express を使用してノード プロジェクトでファイルのアップロードを処理する方法を紹介します。
 Java 開発: 画像認識と処理を実装する方法
Sep 21, 2023 am 08:39 AM
Java 開発: 画像認識と処理を実装する方法
Sep 21, 2023 am 08:39 AM
Java 開発: 画像認識と処理の実践ガイド 要約: コンピューター ビジョンと人工知能の急速な発展に伴い、画像認識と画像処理はさまざまな分野で重要な役割を果たしています。この記事では、Java 言語を使用して画像認識と処理を実装する方法と、具体的なコード例を紹介します。 1. 画像認識の基本原理 画像認識とは、コンピューター技術を使用して画像を分析および理解し、画像内のオブジェクト、特徴、またはコンテンツを識別することを指します。画像認識を実行する前に、図に示すように、いくつかの基本的な画像処理技術を理解する必要があります。
 Nodeのプロセス管理ツール「pm2」を徹底分析
Apr 03, 2023 pm 06:02 PM
Nodeのプロセス管理ツール「pm2」を徹底分析
Apr 03, 2023 pm 06:02 PM
この記事では、Node のプロセス管理ツール「pm2」について説明し、pm2 が必要な理由、pm2 のインストール方法と使用方法について説明します。皆様のお役に立てれば幸いです。
 PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
PIノードティーチング:PIノードとは何ですか? PIノードをインストールしてセットアップする方法は?
Mar 05, 2025 pm 05:57 PM
ピン張りのノードの詳細な説明とインストールガイドこの記事では、ピネットワークのエコシステムを詳細に紹介します - PIノードは、ピン系生態系における重要な役割であり、設置と構成の完全な手順を提供します。 Pinetworkブロックチェーンテストネットワークの発売後、PIノードは多くの先駆者の重要な部分になり、テストに積極的に参加し、今後のメインネットワークリリースの準備をしています。まだピン張りのものがわからない場合は、ピコインとは何かを参照してください。リストの価格はいくらですか? PIの使用、マイニング、セキュリティ分析。パインワークとは何ですか?ピン競技プロジェクトは2019年に開始され、独占的な暗号通貨PIコインを所有しています。このプロジェクトは、誰もが参加できるものを作成することを目指しています
 Python プログラミングを使用して、Baidu 画像認識インターフェイスのドッキングを実現し、画像認識機能を実現する方法を説明します。
Aug 25, 2023 pm 03:10 PM
Python プログラミングを使用して、Baidu 画像認識インターフェイスのドッキングを実現し、画像認識機能を実現する方法を説明します。
Aug 25, 2023 pm 03:10 PM
Python プログラミングを使用して、Baidu の画像認識インターフェイスのドッキングを実装し、画像認識機能を実現する方法を説明します。コンピューター ビジョンの分野において、画像認識技術は非常に重要な技術です。 Baidu は、画像の分類、ラベル付け、顔認識、その他の機能を簡単に実装できる強力な画像認識インターフェイスを提供します。この記事では、Python プログラミング言語を使用して、Baidu 画像認識インターフェイスに接続して画像認識機能を実現する方法を説明します。まず、Baidu Developer Platform でアプリケーションを作成し、
 画像認識に Python 正規表現を使用する方法
Jun 23, 2023 am 10:36 AM
画像認識に Python 正規表現を使用する方法
Jun 23, 2023 am 10:36 AM
コンピューターサイエンスにおいて、画像認識は常に重要な分野です。画像認識を使用すると、コンピューターに画像内の内容を認識および分析させ、処理させることができます。 Python は、画像認識を含むさまざまな分野で使用できる非常に人気のあるプログラミング言語です。この記事ではPythonの正規表現を使って画像認識を行う方法を紹介します。正規表現は、特定のパターンに一致するテキストを検索するために使用されるテキスト パターン マッチング ツールです。 Python には正規表現用の "re" モジュールが組み込まれています
 Pythonで画像処理と認識を行う方法
Oct 20, 2023 pm 12:10 PM
Pythonで画像処理と認識を行う方法
Oct 20, 2023 pm 12:10 PM
Python で画像処理と認識を行う方法 概要: 最新のテクノロジーにより、画像処理と認識が多くの分野で重要なツールになりました。 Python は、豊富な画像処理および認識ライブラリを備えた、習得と使用が簡単なプログラミング言語です。この記事では、Python を使用して画像処理と認識を行う方法と、具体的なコード例を紹介します。画像処理: 画像処理は、画質を向上させたり、画像から情報を抽出したりするために、画像にさまざまな操作や変換を実行するプロセスです。 Python の PIL ライブラリ (Pi
 Go と Goroutines を使用した高度な同時実行画像認識システムの実装
Jul 22, 2023 am 10:58 AM
Go と Goroutines を使用した高度な同時実行画像認識システムの実装
Jul 22, 2023 am 10:58 AM
Go と Goroutines を使用した高度な同時実行画像認識システムの実装 はじめに: 今日のデジタル世界では、画像認識は重要なテクノロジーになっています。画像認識により、画像内の物体、顔、風景などの情報をデジタルデータに変換できます。しかし、大規模な画像データの認識では、速度が課題となることがよくあります。この問題を解決するために、この記事では Go 言語とゴルーチンを使用して同時実行性の高い画像認識システムを実装する方法を紹介します。背景: Go 言語
