

NetEase Cloud の音楽レビューのクロール
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
https://music.163」です。 .com /#/song?id=", "28815250"
3. リクエスト モジュールによって取得された HTML テキストは、json を使用して Python で読み取り可能な形式に変換する必要があります。それ以外の場合は、エラーが報告されます。 jupyter ノートブックではこのようなことは起こりません。 4. replace() 関数は文字列から要素を削除できます。この例では、改行文字が空に変更されます。 最終的な表示結果は次のとおりです。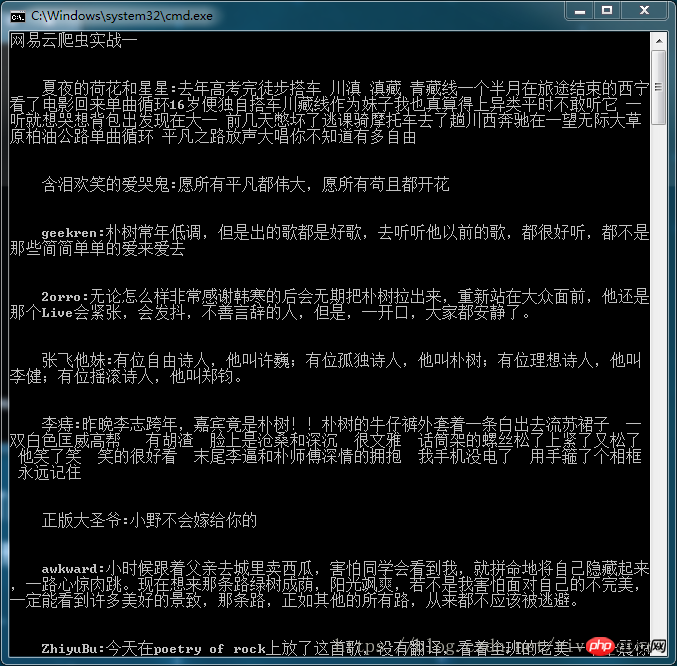
##この記事では、NetEase Cloud 音楽レビュー クロールの関連コンテンツを紹介します。 php中国語ウェブサイトに従ってください。
関連する推奨事項:
シンプルな PHP MySQL ページング クラス再帰なしの 2 つのツリー配列コンストラクターHTMLをExcelに変換し、印刷・ダウンロード機能を実現以上がNetEase Cloud の音楽レビューのクロールの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7663
7663
 15
1393
52
1205
24
91
11
15
1393
52
1205
24
91
11

 New York Times API を使用したメタデータのスクレイピング
Sep 02, 2023 pm 10:13 PM
New York Times API を使用したメタデータのスクレイピング
Sep 02, 2023 pm 10:13 PM
はじめに 先週、私はメタデータを収集するための Web ページのスクレイピングについての紹介を書き、ニューヨーク タイムズの Web サイトをスクレイピングすることは不可能であると述べました。ニューヨーク タイムズのペイウォールは、基本的なメタデータを収集しようとする試みをブロックします。しかし、New York Times API を使用してこの問題を解決する方法があります。最近、Yii プラットフォーム上でコミュニティ Web サイトを構築し始めました。これについては、今後のチュートリアルで公開する予定です。自分のサイトのコンテンツに関連するリンクを簡単に追加できるようにしたいと考えています。 URL をフォームに簡単に貼り付けることはできますが、タイトルやソース情報を提供するのは時間がかかります。そこで、今日のチュートリアルでは、最近書いたスクレイピング コードを拡張して、ニューヨーク タイムズ API を利用して、ニューヨーク タイムズ リンクを追加するときに見出しを収集します。覚えておいてください、私も関わっています
 PHP プロジェクトで API インターフェイスを呼び出してデータをクロールおよび処理するにはどうすればよいですか?
Sep 05, 2023 am 08:41 AM
PHP プロジェクトで API インターフェイスを呼び出してデータをクロールおよび処理するにはどうすればよいですか?
Sep 05, 2023 am 08:41 AM
PHP プロジェクトで API インターフェイスを呼び出してデータをクロールおよび処理するにはどうすればよいですか? 1. はじめに PHP プロジェクトでは、多くの場合、他の Web サイトからデータをクロールし、これらのデータを処理する必要があります。多くの Web サイトでは API インターフェイスが提供されており、これらのインターフェイスを呼び出すことでデータを取得できます。この記事では、PHP を使用して API インターフェイスを呼び出し、データをクロールおよび処理する方法を紹介します。 2. API インターフェースの URL とパラメーターを取得する 開始する前に、ターゲット API インターフェースの URL と必要なパラメーターを取得する必要があります。
 Vue 開発経験の概要: SEO と検索エンジン クロールを最適化するためのヒント
Nov 22, 2023 am 10:56 AM
Vue 開発経験の概要: SEO と検索エンジン クロールを最適化するためのヒント
Nov 22, 2023 am 10:56 AM
Vue 開発経験のまとめ: SEO と検索エンジン クロールを最適化するためのヒント インターネットの急速な発展に伴い、Web サイトの SEO (SearchEngineOptimization、検索エンジン最適化) の重要性がますます高まっています。 Vue を使用して開発された Web サイトの場合、SEO と検索エンジンのクロールを最適化することが重要です。この記事では、Vue の開発経験を要約し、SEO と検索エンジンのクロールを最適化するためのヒントを共有します。プリレンダリング技術 Vue の使用
 Scrapy を使用して Douban の書籍とその評価とコメントをクロールする方法は?
Jun 22, 2023 am 10:21 AM
Scrapy を使用して Douban の書籍とその評価とコメントをクロールする方法は?
Jun 22, 2023 am 10:21 AM
インターネットの発展に伴い、人々は情報を得るためにますますインターネットに依存するようになりました。本好きにとって、Douban Booksは欠かせないプラットフォームとなっています。さらに、Douban Books では、書籍の評価やレビューも豊富に提供されており、読者が書籍をより包括的に理解できるようになります。ただし、この情報を手動で取得することは、干し草の山から針を見つけることに似ており、現時点では、Scrapy ツールを使用してデータをクロールできます。 Scrapy は、Python をベースにしたオープンソースの Web クローラー フレームワークであり、効率的に役立ちます。
 Scrapy の動作: Baidu ニュース データのクロール
Jun 23, 2023 am 08:50 AM
Scrapy の動作: Baidu ニュース データのクロール
Jun 23, 2023 am 08:50 AM
Scrapy の動作: Baidu ニュース データのクロール インターネットの発展に伴い、人々が情報を入手する主な方法は従来のメディアからインターネットに移り、人々はニュース情報を入手するためにますますインターネットに依存するようになりました。研究者やアナリストにとって、分析や研究には大量のデータが必要です。そこで、この記事ではScrapyを使ってBaiduのニュースデータをクロールする方法を紹介します。 Scrapy は、Web サイトのデータを迅速かつ効率的にクロールできるオープンソースの Python クローラー フレームワークです。 Scrapy は強力な Web ページ解析およびクローリング機能を提供します
 Web クローリングとデータ抽出に PHP Goutte クラス ライブラリを使用するにはどうすればよいですか?
Aug 09, 2023 pm 02:16 PM
Web クローリングとデータ抽出に PHP Goutte クラス ライブラリを使用するにはどうすればよいですか?
Aug 09, 2023 pm 02:16 PM
Web クローリングとデータ抽出に PHPGoutte クラス ライブラリを使用するにはどうすればよいですか?概要: 日々の開発プロセスでは、映画のランキングや天気予報など、さまざまなデータをインターネットから取得する必要があることがよくあります。 Web クローリングは、このデータを取得する一般的な方法の 1 つです。 PHP 開発では、Goutte クラス ライブラリを使用して、Web クローリング機能とデータ抽出機能を実装できます。この記事では、PHPGoutte クラス ライブラリを使用して Web ページをクロールしてデータを抽出する方法を紹介し、コード例を添付します。痛風とは
 Scrapy の動作: Douban 映画データのクロールと評価人気ランキング
Jun 22, 2023 pm 01:49 PM
Scrapy の動作: Douban 映画データのクロールと評価人気ランキング
Jun 22, 2023 pm 01:49 PM
Scrapy は、データを迅速かつ効率的にスクレイピングするためのオープンソース Python フレームワークです。この記事では、Scrapy を使用して Douban 映画のデータと評価の人気をクロールします。準備 まず、Scrapyをインストールする必要があります。 Scrapy をインストールするには、コマンド ラインで次のコマンドを入力します。 pipinstallscrapy 次に、Scrapy プロジェクトを作成します。コマンドラインで次のコマンドを入力します:scrapystartproject
 Scrapy を使用して Kugou Music の曲をクロールする方法は?
Jun 22, 2023 pm 10:59 PM
Scrapy を使用して Kugou Music の曲をクロールする方法は?
Jun 22, 2023 pm 10:59 PM
インターネットの発展に伴い、インターネット上の情報量は増加しており、人々はさまざまなウェブサイトから情報をクローリングして、さまざまな分析やマイニングを行う必要があります。 Scrapy は、Web サイトのデータを自動的にクロールし、構造化された形式で出力できる、完全に機能する Python クローラー フレームワークです。 Kugou Music は最も人気のあるオンライン音楽プラットフォームの 1 つであり、以下では Scrapy を使用して Kugou Music の曲情報をクロールする方法を紹介します。 1. Scrapy をインストールするScrapy は Python 言語をベースにしたフレームワークです。
