

Webpack フロントエンドのパフォーマンスの最適化について (詳細なチュートリアル)
Webpack は最近最も人気のあるモジュールローダーおよびパッケージ化ツールで、JS (JSX を含む)、Coffee、スタイル (less/sass を含む)、画像などのさまざまなリソースをモジュールとして使用および処理できます。この記事は主に、Webpack 学習チュートリアルのフロントエンド パフォーマンスの最適化に関する関連情報を要約して紹介します。
まえがき
かつて、上記のようなJSリソースを紹介しましたが、今ではほとんど見られなくなったと思います。近年、Web フロントエンド開発の分野は標準化された開発に向けて進化しています。これは次の 2 つの点に反映されています:
1. MVC R&D アーキテクチャ。多くの利点 (明確なロジック、プログラムはデータとパフォーマンスの分離に重点を置いており、問題の回避とトラブルシューティングに役立つ強力な可読性...)
2. 無限の構築ツールがあります。多くの利点 (チームのコラボレーションとエンジニアリングの運用と保守の改善、些細で反復的な作業の手動処理の回避)
モジュラー開発
フロントエンドのパフォーマンス最適化理論の実装、コード圧縮、マージ、キャッシュ制御、パブリックコードの抽出待ってください
その他には、たとえば、ES 6 または CoffeeScript を使用してソース コードを記述し、ブラウザでサポートされる ES5 をビルドすることもできます
まだプロジェクトがあれば、フロントエンドはとても楽しいですフロントエンドとバックエンドを分離しないと、本当に保守的すぎます。
主流のビルド ツール
市場には、Grunt、Gulp、browserify などを含む多くのビルド ツールがあります。これらと WebPack はすべてパッケージ化ツールです。ただし、WebPack には次のような特徴もあります:
Grunt と比較して、WebPack には豊富なプラグイン セットがあるだけでなく、読み込み (ローダー) システムも備えています。 ES6、CommonJS、AMD など、Grunt や Gulp にはない複数の標準読み込み方法をサポートします。
コード難読化の観点から見ると、WebPack はさらに極端です
コードは (ファイルではなく) 処理単位に断片化され、ファイルの断片化がより柔軟になります。
追記:これは単純な比較であり、どちらが良いか悪いかは関係ありません。実際、ツールはニーズを満たすことができます。ツールの使用方法の背後にあるのは、フロントエンドのパフォーマンスの最適化を理解することです。
はじめに
最近、私はwebpackを使用して最初の画面の読み込みパフォーマンスを最適化しています。いくつかのプラグインを使用した後、オンラインになる前と後の速度が2倍になりました。まず、ここで簡単に共有します。最適化前後の最初の画面のレンダリング比較画像。

合計ダウンロード時間が 3800 ミリ秒から 1600 ミリ秒に短縮されていることがわかります。
webpack を使用するときは、通常、独自のソース コードをサードパーティのライブラリ コードから分離するために複数のエントリ ファイルを選択します。これは以前のコードです。
entry: {
entry: './src/main.js',
vendor: ['vue', 'vue-router', 'vuex', 'element-ui','echarts']
},
output: {
path: config.build.assetsRoot,
filename: utils.assetsPath('js/[name].[chunkhash].js'),
chunkFilename: utils.assetsPath('js/[id].[chunkhash].js')
}echarts は非常に大きいため、パッケージ化された Vendor.js は約 1.2MB (gzip 圧縮後) で、echarts はホームページでは使用されないため、後で外部を使用してサードパーティのコードをインポートしました。 library to cdn 紹介すると以下が最適化されたコードです
entry: {
entry: './src/main.js',
vendor: ['vue', 'vue-router', 'vuex', 'element-ui']
},
// 这里的output为base中的output,不是生产的output
output: {
path: config.build.assetsRoot,
filename: '[name].js',
libraryTarget: "umd",
publicPath: process.env.NODE_ENV === 'production' ?
config.build.assetsPublicPath : config.dev.assetsPublicPath
},
externals: {
echarts: 'echarts',
_: 'lodash'
},

最適化前後の比較です。
次に、HTML に移動して、スクリプト タグの形式で外部で cdn を引用する必要があります。その後、対応するファイルにインポートできます。その利点は、多くの vue ファイルで何度参照しても、すべてのトランクにパッケージ化されないことです (ここでの「トランク」とは、オンデマンドでロードされることを指します)。詳細は後で説明します)。これは、webpack-bundle-analyzer プラグインを使用して示される効果です。
var BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
new BundleAnalyzerPlugin({
// 可以是`server`,`static`或`disabled`。
// 在`server`模式下,分析器将启动HTTP服务器来显示软件包报告。
// 在“静态”模式下,会生成带有报告的单个HTML文件。
// 在`disabled`模式下,你可以使用这个插件来将`generateStatsFile`设置为`true`来生成Webpack Stats JSON文件。
analyzerMode: 'server',
// 将在“服务器”模式下使用的主机启动HTTP服务器。
analyzerHost: '127.0.0.1',
// 将在“服务器”模式下使用的端口启动HTTP服务器。
analyzerPort: 8888,
// 路径捆绑,将在`static`模式下生成的报告文件。
// 相对于捆绑输出目录。
reportFilename: 'report.html',
// 模块大小默认显示在报告中。
// 应该是`stat`,`parsed`或者`gzip`中的一个。
// 有关更多信息,请参见“定义”一节。
defaultSizes: 'parsed',
// 在默认浏览器中自动打开报告
openAnalyzer: true,
// 如果为true,则Webpack Stats JSON文件将在bundle输出目录中生成
generateStatsFile: false,
// 如果`generateStatsFile`为`true`,将会生成Webpack Stats JSON文件的名字。
// 相对于捆绑输出目录。
statsFilename: 'stats.json',
// stats.toJson()方法的选项。
// 例如,您可以使用`source:false`选项排除统计文件中模块的来源。
// 在这里查看更多选项:https: //github.com/webpack/webpack/blob/webpack-1/lib/Stats.js#L21
statsOptions: null,
logLevel: 'info' //日志级别。可以是'信息','警告','错误'或'沉默'。
})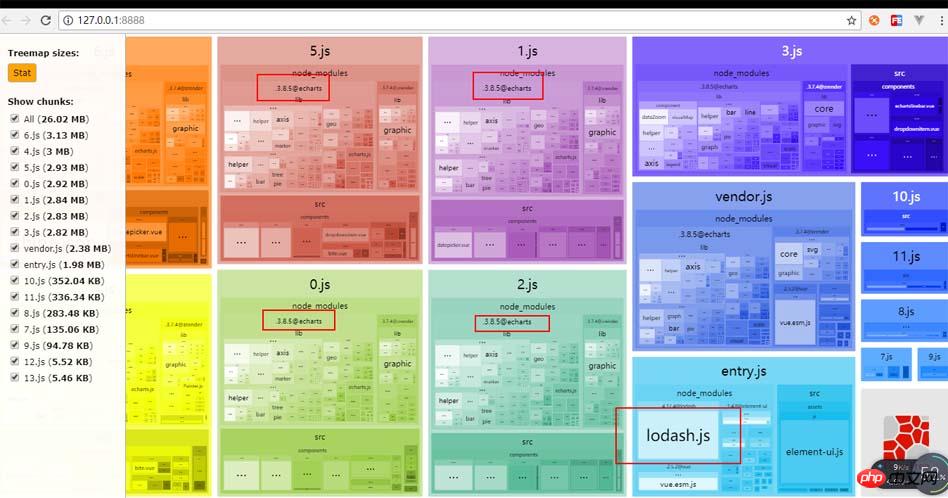

echarts や lodash のようなライブラリは、外部を使用しない場合、または外部を使用した後にすべての JS に表示されるわけではないことがわかります (10,000 回インポートしても、一度もパッケージ化されません。すごいですね~~ )。
externals についてさらに 2 つのポイント -
1. externals のキーは import で使用されます
import lodash from "_"; import echarts from "echarts";
2. externals の値はウィンドウ
で呼び出されます。次に、出力で trainhash が使用される理由について説明します。 、これは永続的なキャッシュ用です。 2 つの違いについて簡単に説明します -
trunk: 各ビルド後のバージョンは、ビルド後のすべてのファイルのハッシュ値が同じであることを意味します。たとえば、1 つのファイルのみを変更した場合、すべてのファイルのハッシュが同じになります。最終的には変更され、すべてのファイルがキャッシュされるため、キャッシュは無意味になります。
trunkhash: ファイルごとに異なるハッシュ値を生成し、ファイルが変更されるとハッシュが変更され、対応するファイルのみが変更されます。
然后我们肯定是要用到CommonsChunkPlugin,这个插件是用来抽取公共代码的,基本上99%的配置都是长这样子或者类似这样子用两个不同的commonschunkPlugin,但这从某方面来说并没有实现真正意义上的持久化缓存,这个一会我会通过webpack打包原理来详细解释其中的原因。。。。。。
new webpack.optimize.CommonsChunkPlugin({
names: ['vendor','manifest']
})在没用这个插件之前,我们的main.js和vendor.js会是这样子。。。

大家会看到我们这两个文件会有公共的部分,比如vue和element-ui,所以我们要抽取公共代码到vendor中,所以我们可以先这样配置
new webpack.optimize.CommonsChunkPlugin({
name: 'vendor',
}),但这样的话虽然可以提取公共代码,但我们会把runtime(webpack运行时的代码,一会在打包原理中会再次提到)也放到vendor中,这里面会维护一个trunk的文件列表,类似于这样,就是说我们改任意的代码,这个table里面的hash会变,所以vendor的hash也会变
,所以这没有实现真正的持久化缓存。这个hash table是按需缓存的打包出来的trunk包,一般都是通过require.ensure(就是vue-router中配置的page对应页面,按需加载)

所以我们就把name改为names,就是上面那个配置。因为使用这个插件,我们会把公共代码抽到第一个name中,把runtime放到最后一个name中,也就是我们所谓的“manifest”文件。
并且这个文件会比较小,通常都是2kb左右,所以build后会生成一个script标签,但这样的话就多了一个http请求,所以我们可以用另外一个插件(InlineManifestWebpackPlugin)将manifest.js内联进去。就会长这样子
再回到我们的CommonsChunkPlugin,现在我们随便改任何已存在的文件,vendor.js的hash都不会变,是的,貌似这就实现了持久化缓存。但是当我们新增一个模块,并且在入口文件中import一下,我们的vendor就会跟main一起变。很奇怪对吧,我们明明已经做了自己的源码跟第三方库分离,为什么vendor还会变(到现在应该没有任何一篇博客对此进行详细的说明)。下面我就详细的给大家解释下我的看法,如果大家发现有不对的地方还请指正。
再解释为什么之前,我们先简单了解下webpack的打包规则。
webpack一个entry对应一个bundle,这个bundle包括入口文件和其依赖的模块。其他按需加载的则打包成其他的bundle。还有一个比较重要的文件时manifest,它是最先加载的,负责打包其他的bundle并按需加载和执行。
manifest是一个自执行函数,熟悉angular的同学看第一行应该很了解,因为anguar1.3版本的源码中启动就是angular.bootstrap,对,这里也是一样。里面的modules变量就是对应模块函数,它是webpack处理的基本单位,就是说对应打包前的一个文件
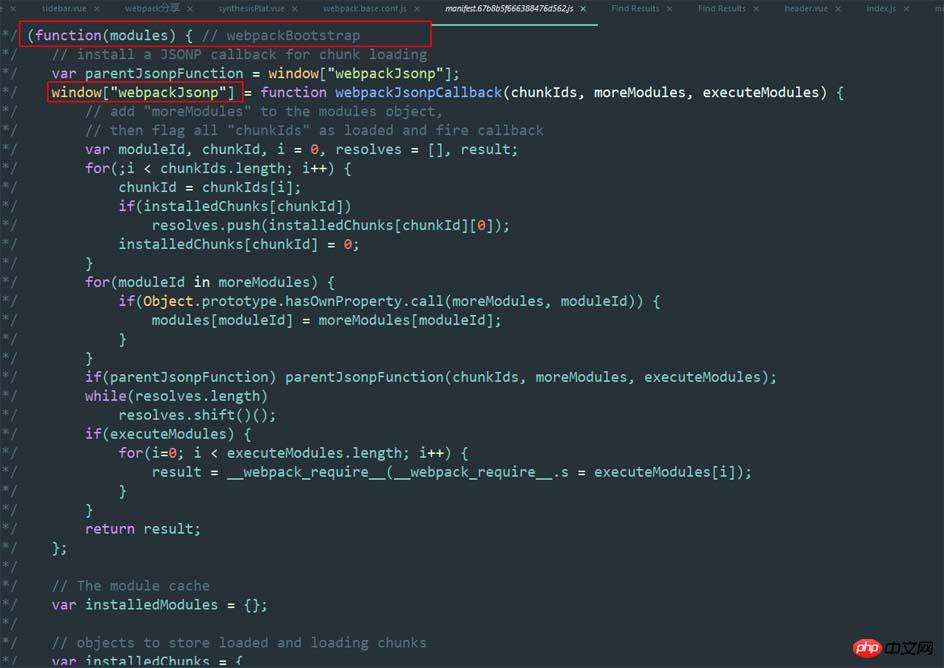
这是js源文件,
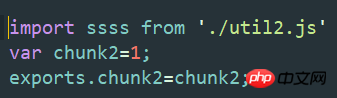
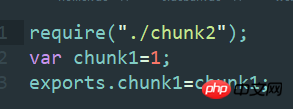
这是打包后的文件,
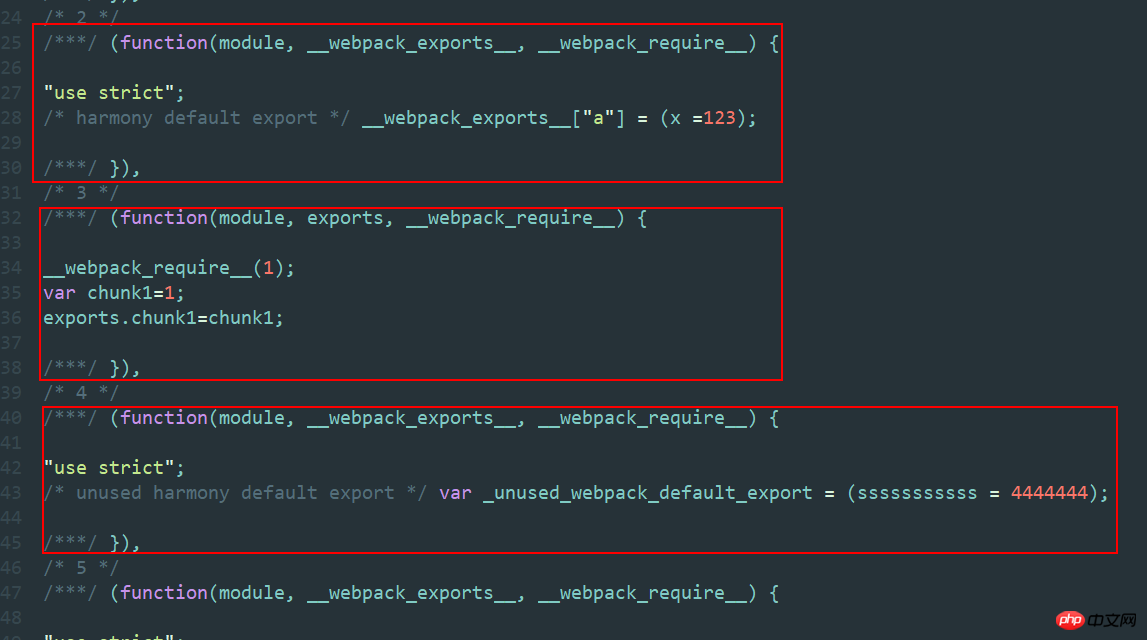
所有的模块函数索引都是连续的(每个js文件生成一个trunkid!!!!!),像这种 /* 4 */ 对应的就是js文件,他通过打包就变成了一个个trunkid,仔细看会看到咱们打包前js文件里的export和require依赖都会统一转换成webpack模块。咱们说的webpackJsonp就是除manifest之外打包其他的文件的函数体。
简单说下main吧,这个图的trunkid是连续的,为了在一张图上显示,我截掉了trunk3-7.
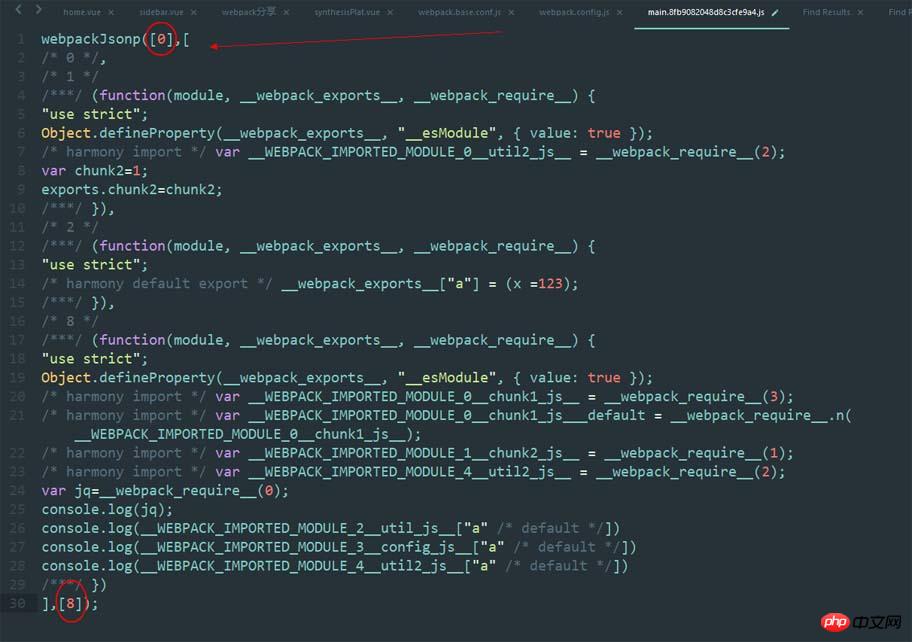
这里面一共有三个参数,第一个是我当前文件的trunkid,它是唯一标识符,就是指main的trunkid,第二个就是打包的所有文件的模块函数,第三个是我要立即执行的trunkid模块函数。
ok,介绍这些就足够了。
然后我们再回过头来看看为什么我们所谓的commonschunkPlugin会变。刚才说过,有几个js就有几个trunkid。
新しい js を追加してメイン エントリに導入すると、webpack がそれを再度パッケージ化し、メイン ファイルにもう 1 つのモジュール関数が追加されます。先ほど述べたように、trunkid は順次増加し、繰り返されません。したがって、対応するベンダーの ID は +1 になります。これは、ハッシュを変更する非常に微妙な変更です。
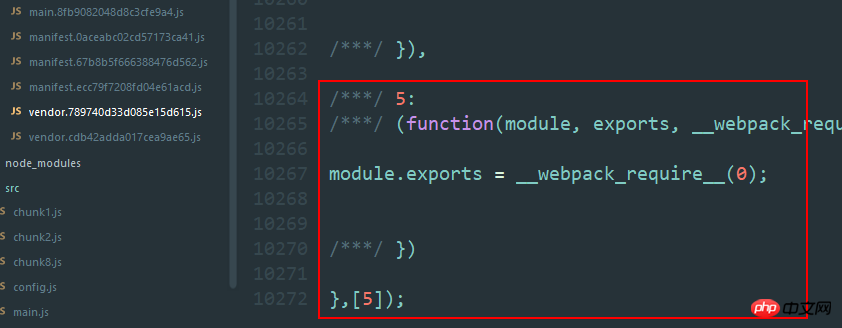
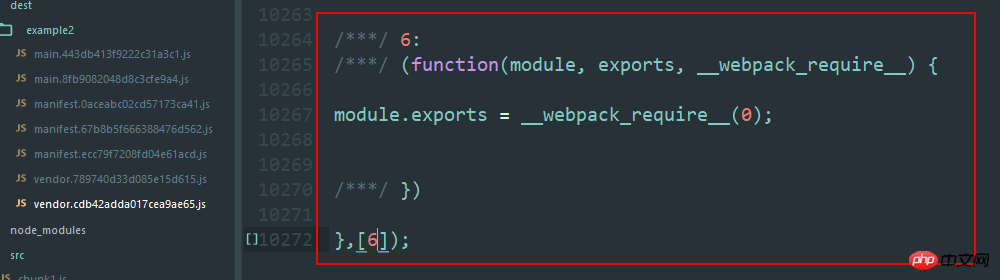
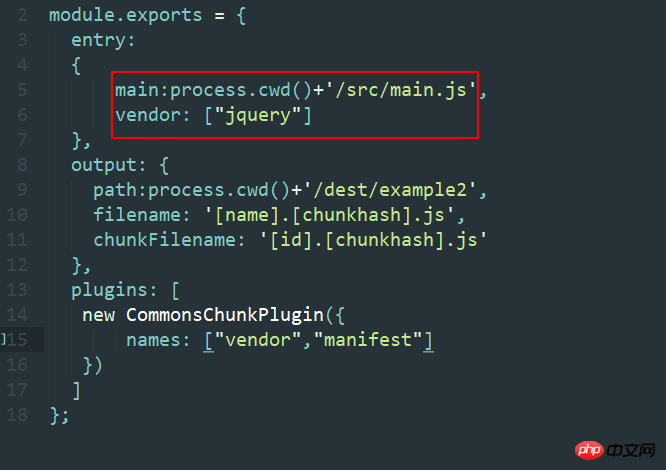
注意してください。どちらのベンダーも 10272 行あります。唯一の違いは、ここで jquery を自己実行したいため、このファイルには self である jquery のみが含まれていることです。 -実行中。trunkid+1 というモジュール関数が必要なので、ハッシュが変更されます。実際、これはこのプラグインの重要性を示しています。私はパブリック ライブラリを抽出したいだけですが、Webpack パッケージ化メカニズムにより、異なるファイルが生成されます。 、つまり、これは軟膏のハエです。通常、main.js を不用意に変更することはないので、別の観点から見ると、これは永続的なキャッシュの実装であることを思い出してください。しかし、ベンダーのハッシュを変更しないでおきたい場合はどうすればよいでしょうか?
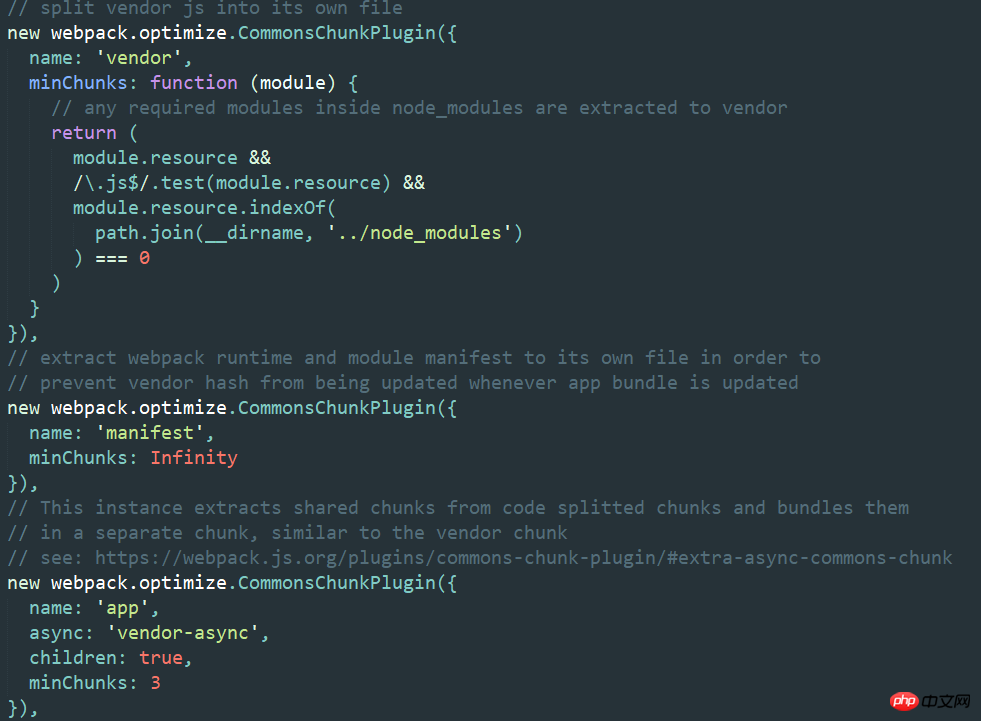
はい、vue-cli をよく知っている方であれば、これは vue-cli の公式デモです。なぜそれが可能なのかについては、後ほど説明します (実際にはできません)。書きません)。
最後に、とても便利なもの、CDNをご紹介します。私たちの現在の要求は、画像を CDN に送信し、js をオンラインにできるようにすることですが、公式の説明では、構成ファイルを変更して CDN を変更すると、すべての出力が CDN に送信され、すべての ajax リクエストが送信されます。クロスドメインです。

当初の私の解決策は、ソースファイルを 1 つずつ置き換えることでした。これでは時間がかかります。さらに重要なのは、将来イメージを置き換えるときに、cdn イメージにもハッシュ値が含まれることです。それに応じてハッシュ。彼が自動的にハッシュを取得できるようにする方法はありますか?
はい、js がオンライン パスにアクセスし、静的リソースが cdn を使用できるように、url ローダーで cdn を個別に設定する必要があります。この 2 つは相互に影響しません。
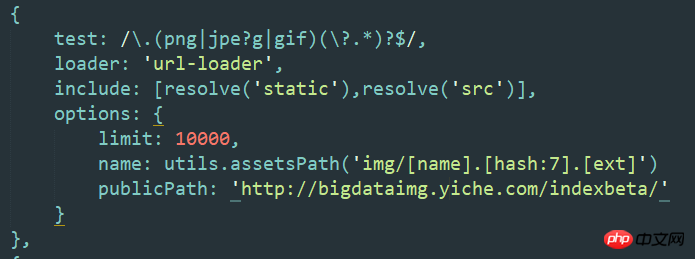
ちょっと注意してください、url-loader は js 内の背景を検出できないため、js で参照するアドレスは最初にこの画像を外部にインポートする必要があり、url-loader はそれを解析してパッケージ化します。
上記は私があなたのためにまとめたものです。
関連記事:
WeChatアプレットでビデオコンポーネントを使用してビデオを再生する方法
WeChatアプレットでオーディオコンポーネントを使用する方法
以上がWebpack フロントエンドのパフォーマンスの最適化について (詳細なチュートリアル)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
7
6
15
1371
52
76
11
7
6

 Goフレームワークのパフォーマンス最適化と水平拡張技術?
Jun 03, 2024 pm 07:27 PM
Goフレームワークのパフォーマンス最適化と水平拡張技術?
Jun 03, 2024 pm 07:27 PM
Go アプリケーションのパフォーマンスを向上させるために、次の最適化手段を講じることができます。 キャッシュ: キャッシュを使用して、基盤となるストレージへのアクセス数を減らし、パフォーマンスを向上させます。同時実行性: ゴルーチンとチャネルを使用して、長いタスクを並行して実行します。メモリ管理: メモリを手動で管理し (安全でないパッケージを使用)、パフォーマンスをさらに最適化します。アプリケーションをスケールアウトするには、次の手法を実装できます。 水平スケーリング (水平スケーリング): アプリケーション インスタンスを複数のサーバーまたはノードにデプロイします。負荷分散: ロード バランサーを使用して、リクエストを複数のアプリケーション インスタンスに分散します。データ シャーディング: 大規模なデータ セットを複数のデータベースまたはストレージ ノードに分散して、クエリのパフォーマンスとスケーラビリティを向上させます。
 C++ パフォーマンス最適化ガイド: コードをより効率的にする秘訣を発見します。
Jun 01, 2024 pm 05:13 PM
C++ パフォーマンス最適化ガイド: コードをより効率的にする秘訣を発見します。
Jun 01, 2024 pm 05:13 PM
C++ のパフォーマンスの最適化には、1. 動的割り当ての回避、2. コンパイラ最適化フラグの使用、4. アプリケーションのキャッシュ、5. 並列プログラミングなどのさまざまな手法が含まれます。最適化の実際のケースでは、整数配列内の最長の昇順サブシーケンスを見つけるときにこれらの手法を適用して、アルゴリズムの効率を O(n^2) から O(nlogn) に改善する方法を示します。
 C++ を使用したロケット エンジンのパフォーマンスの最適化
Jun 01, 2024 pm 04:14 PM
C++ を使用したロケット エンジンのパフォーマンスの最適化
Jun 01, 2024 pm 04:14 PM
C++ は、数学的モデルを構築し、シミュレーションを実行し、パラメーターを最適化することにより、ロケット エンジンのパフォーマンスを大幅に向上させることができます。ロケット エンジンの数学的モデルを構築し、その動作を記述します。エンジンのパフォーマンスをシミュレートし、推力や比推力などの主要なパラメーターを計算します。主要なパラメータを特定し、遺伝的アルゴリズムなどの最適化アルゴリズムを使用して最適な値を検索します。エンジンのパフォーマンスは最適化されたパラメータに基づいて再計算され、全体的な効率が向上します。
 最適化への道: Java フレームワークのパフォーマンス向上への道のりを探る
Jun 01, 2024 pm 07:07 PM
最適化への道: Java フレームワークのパフォーマンス向上への道のりを探る
Jun 01, 2024 pm 07:07 PM
Java フレームワークのパフォーマンスは、キャッシュ メカニズム、並列処理、データベースの最適化を実装し、メモリ消費を削減することによって向上できます。キャッシュ メカニズム: データベースまたは API リクエストの数を減らし、パフォーマンスを向上させます。並列処理: マルチコア CPU を利用してタスクを同時に実行し、スループットを向上させます。データベースの最適化: クエリの最適化、インデックスの使用、接続プールの構成、およびデータベースのパフォーマンスの向上。メモリ消費量を削減する: 軽量フレームワークを使用し、リークを回避し、分析ツールを使用してメモリ消費量を削減します。
 高度な C++ パフォーマンス最適化手法とは何ですか?
May 08, 2024 pm 09:18 PM
高度な C++ パフォーマンス最適化手法とは何ですか?
May 08, 2024 pm 09:18 PM
C++ のパフォーマンス最適化手法には次のものが含まれます。 ボトルネックを特定し、配列レイアウトのパフォーマンスを向上させるためのプロファイリング。メモリ管理では、スマート ポインタとメモリ プールを使用して、割り当てと解放の効率を向上させます。同時実行では、マルチスレッドとアトミック操作を活用して、大規模なアプリケーションのスループットを向上させます。データの局所性により、ストレージのレイアウトとアクセス パターンが最適化され、データ キャッシュのアクセス速度が向上します。コード生成とコンパイラの最適化では、インライン化やループ展開などのコンパイラ最適化手法を適用して、特定のプラットフォームとアルゴリズムに最適化されたコードを生成します。
 プログラムのパフォーマンスを最適化するための一般的な方法は何ですか?
May 09, 2024 am 09:57 AM
プログラムのパフォーマンスを最適化するための一般的な方法は何ですか?
May 09, 2024 am 09:57 AM
プログラムのパフォーマンスの最適化方法には、次のようなものがあります。 アルゴリズムの最適化: 時間の複雑さが低いアルゴリズムを選択し、ループと条件文を減らします。データ構造の選択: ルックアップ ツリーやハッシュ テーブルなどのデータ アクセス パターンに基づいて、適切なデータ構造を選択します。メモリの最適化: 不要なオブジェクトの作成を回避し、使用されなくなったメモリを解放し、メモリ プール テクノロジを使用します。スレッドの最適化: 並列化できるタスクを特定し、スレッド同期メカニズムを最適化します。データベースの最適化: インデックスを作成してデータの取得を高速化し、クエリ ステートメントを最適化し、キャッシュまたは NoSQL データベースを使用してパフォーマンスを向上させます。
 Java でプロファイリングを使用してパフォーマンスを最適化するにはどうすればよいですか?
Jun 01, 2024 pm 02:08 PM
Java でプロファイリングを使用してパフォーマンスを最適化するにはどうすればよいですか?
Jun 01, 2024 pm 02:08 PM
Java でのプロファイリングは、アプリケーション実行の時間とリソース消費を決定するために使用されます。 JavaVisualVM を使用してプロファイリングを実装する: JVM に接続してプロファイリングを有効にし、サンプリング間隔を設定し、アプリケーションを実行してプロファイリングを停止すると、分析結果に実行時間のツリー ビューが表示されます。パフォーマンスを最適化する方法には、ホットスポット削減方法の特定と最適化アルゴリズムの呼び出しが含まれます。
 Java マイクロサービス アーキテクチャにおけるパフォーマンスの最適化
Jun 04, 2024 pm 12:43 PM
Java マイクロサービス アーキテクチャにおけるパフォーマンスの最適化
Jun 04, 2024 pm 12:43 PM
Java マイクロサービス アーキテクチャのパフォーマンスの最適化には、次の手法が含まれます。 JVM チューニング ツールを使用してパフォーマンスのボトルネックを特定し、調整します。ガベージ コレクターを最適化し、アプリケーションのニーズに合った GC 戦略を選択して構成します。 Memcached や Redis などのキャッシュ サービスを使用して、応答時間を短縮し、データベースの負荷を軽減します。非同期プログラミングを採用して同時実行性と応答性を向上させます。マイクロサービスを分割し、大規模なモノリシック アプリケーションをより小さなサービスに分割して、スケーラビリティとパフォーマンスを向上させます。
