

javascript_javascript スキルでよく使用される古典的なアルゴリズムの例の詳細な説明

この記事の例では、JavaScript の一般的なアルゴリズムについて説明します。参考のために皆さんと共有してください。詳細は次のとおりです:
エントリーレベルのアルゴリズム - 線形探索 - 時間計算量 O(n) -- アルゴリズムの世界の HelloWorld
に相当
//线性搜索(入门HelloWorld)
//A为数组,x为要搜索的值
function linearSearch(A, x) {
for (var i = 0; i < A.length; i++) {
if (A[i] == x) {
return i;
}
}
return -1;
}
二分探索 (半探索とも呼ばれます) - ソートされた線形構造に適しています - 時間計算量 O(logN)
//二分搜索
//A为已按"升序排列"的数组,x为要查询的元素
//返回目标元素的下标
function binarySearch(A, x) {
var low = 0, high = A.length - 1;
while (low <= high) {
var mid = Math.floor((low + high) / 2); //下取整
if (x == A[mid]) {
return mid;
}
if (x < A[mid]) {
high = mid - 1;
}
else {
low = mid + 1;
}
}
return -1;
}
バブルソート -- 時間計算量 O(n^2)
//冒泡排序
function bubbleSort(A) {
for (var i = 0; i < A.length; i++) {
var sorted = true;
//注意:内循环是倒着来的
for (var j = A.length - 1; j > i; j--) {
if (A[j] < A[j - 1]) {
swap(A, j, j - 1);
sorted = false;
}
}
if (sorted) {
return;
}
}
}
選択ソート -- 時間計算量 O(n^2)
//选择排序
//思路:找到最小值的下标记下来,再交换
function selectionSort(A) {
for (var i = 0; i < A.length - 1; i++) {
var k = i;
for (var j = i + 1; j < A.length; j++) {
if (A[j] < A[k]) {
k = j;
}
}
if (k != i) {
var t = A[k];
A[k] = A[i];
A[i] = t;
println(A);
}
}
return A;
}
挿入ソート -- 時間計算量 O(n^2)
//插入排序
//假定当前元素之前的元素已经排好序,先把自己的位置空出来,
//然后前面比自己大的元素依次向后移,直到空出一个"坑",
//然后把目标元素插入"坑"中
function insertSort(A) {
for (var i = 1; i < A.length; i++) {
var x = A[i];
for (var j = i - 1; j >= 0 && A[j] > x; j--) {
A[j + 1] = A[j];
}
if (A[j + 1] != x) {
A[j + 1] = x;
println(A);
}
}
return A;
}
文字列反転 -- 時間計算量 O(logN)
//字符串反转(比如:ABC -> CBA)
function inverse(s) {
var arr = s.split('');
var i = 0, j = arr.length - 1;
while (i < j) {
var t = arr[i];
arr[i] = arr[j];
arr[j] = t;
i++;
j--;
}
return arr.join('');
}
安定性ランキングに関する結論:
比較に基づく単純な並べ替えアルゴリズム、つまり、時間計算量が O(N^2) の並べ替えアルゴリズムであり、通常は安定した並べ替えであると考えられます
マージ ソート、ヒープ ソート、バケット ソートなどの他の高度なソート アルゴリズム (通常、このようなアルゴリズムの時間計算量は n*LogN に最適化できます) は、通常、不安定なソートであると考えられます
単一リンクリスト実装
<script type="text/javascript">
function print(msg) {
document.write(msg);
}
function println(msg) {
print(msg + "<br/>");
}
//节点类
var Node = function (v) {
this.data = v; //节点值
this.next = null; //后继节点
}
//单链表
var SingleLink = function () {
this.head = new Node(null); //约定头节点仅占位,不存值
//插入节点
this.insert = function (v) {
var p = this.head;
while (p.next != null) {
p = p.next;
}
p.next = new Node(v);
}
//删除指定位置的节点
this.removeAt = function (n) {
if (n <= 0) {
return;
}
var preNode = this.getNodeByIndex(n - 1);
preNode.next = preNode.next.next;
}
//取第N个位置的节点(约定头节点为第0个位置)
//N大于链表元素个数时,返回最后一个元素
this.getNodeByIndex = function (n) {
var p = this.head;
var i = 0;
while (p.next != null && i < n) {
p = p.next;
i++;
}
return p;
}
//查询值为V的节点,
//如果链表中有多个相同值的节点,
//返回第一个找到的
this.getNodeByValue = function (v) {
var p = this.head;
while (p.next != null) {
p = p.next;
if (p.data == v) {
return p;
}
}
return null;
}
//打印输出所有节点
this.print = function () {
var p = this.head;
while (p.next != null) {
p = p.next;
print(p.data + " ");
}
println("");
}
}
//测试单链表L中是否有重复元素
function hasSameValueNode(singleLink) {
var i = singleLink.head;
while (i.next != null) {
i = i.next;
var j = i;
while (j.next != null) {
j = j.next;
if (i.data == j.data) {
return true;
}
}
}
return false;
}
//单链表元素反转
function reverseSingleLink(singleLink) {
var arr = new Array();
var p = singleLink.head;
//先跑一遍,把所有节点放入数组
while (p.next != null) {
p = p.next;
arr.push(p.data);
}
var newLink = new SingleLink();
//再从后向前遍历数组,加入新链表
for (var i = arr.length - 1; i >= 0; i--) {
newLink.insert(arr[i]);
}
return newLink;
}
var linkTest = new SingleLink();
linkTest.insert('A');
linkTest.insert('B');
linkTest.insert('C');
linkTest.insert('D');
linkTest.print();//A B C D
var newLink = reverseSingleLink(linkTest);
newLink.print();//D C B A
</script>
隣接行列と隣接リスト の選択について:
隣接行列と隣接リストはグラフの基本的な保存方法です。
スパース グラフ (つまり、エッジが頂点よりもはるかに小さい場合) の場合は、隣接リスト ストレージを使用する方が適しています (行列 N*N と比較して、隣接リストは値を持つエッジと頂点を保存し、Null 値を保存しません。より効率的なストレージ)
。
密グラフ (つまり、リモート頂点の場合) の場合は、隣接行列とともに保存する方が適しています (大量のデータがある場合は、それを走査する必要があります)。リンクされたリストを使用して保存すると、頻繁にジャンプする必要があり、効率が低下します)
ヒープ:
ほぼ完全な二分木: 一番右の位置にある 1 つまたは複数の葉が欠けている可能性があることを除いて、二分木 。物理ストレージの観点からは、A[j] の頂点に左右の子ノードがある場合、左側のノードは A[2j]、右側のノードは A[2j 1] となります。 A[j] の親頂点 A[j/2]
に格納ヒープ: 自体はほぼ完全な二分木であり、親ノードの値は子ノード の値以上です。アプリケーション シナリオ: 優先キュー、最大値または準最大値の検索、および優先キューへの新しい要素の挿入。
注: 以下で説明するすべてのヒープでは、インデックス 0 の要素のみが発生し、有効な要素は添え字 1 から始まることが合意されています
ヒープの定義に従って、次のコードを使用して配列がヒープであるかどうかをテストできます。
//测试数组H是否为堆
//(约定有效元素从下标1开始)
//时间复杂度O(n)
function isHeap(H) {
if (H.length <= 1) { return false; }
var half = Math.floor(H.length / 2); //根据堆的性质,循环上限只取一半就够了
for (var i = 1; i <= half; i++) {
//如果父节点,比任何一个子节点 小,即违反堆定义
if (H[i] < H[2 * i] || H[i] < H[2 * i + 1]) {
return false;
}
}
return true;
}
ノード調整シフトアップ
場合によっては、ヒープ内の要素の値が変更されると (たとえば、10,8,9,7 が 10,8,9,20 になった後、20 を上方に調整する必要がある)、条件を満たさなくなります。ヒープの定義を上方に調整する必要がある場合は、次のコードを使用して
を実現できます。
//堆中的节点上移
//(约定有效元素从下标1开始)
function siftUp(H, i) {
if (i <= 1) {
return;
}
for (var j = i; j > 1; j = Math.floor(j / 2)) {
var k = Math.floor(j / 2);
//发现 子节点 比 父节点大,则与父节点交换位置
if (H[j] > H[k]) {
var t = H[j];
H[j] = H[k];
H[k] = t;
}
else {
//说明已经符合堆定义,调整结束,退出
return;
}
}
}
siftDownでノードを下方向に調整します(上方向の調整があるので当然下方向の調整もあります)
//堆中的节点下移
//(约定有效元素从下标1开始)
//时间复杂度O(logN)
function siftDown(H, i) {
if (2 * i > H.length) { //叶子节点,就不用再向下移了
return;
}
for (var j = 2 * i; j < H.length; j = 2 * j) {
//将j定位到 二个子节点中较大的那个上(很巧妙的做法)
if (H[j + 1] > H[j]) {
j++;
}
var k = Math.floor(j / 2);
if (H[k] < H[j]) {
var t = H[k];
H[k] = H[j];
H[j] = t;
}
else {
return;
}
}
}
新しい要素をヒープに追加します
//向堆H中添加元素x
//时间复杂度O(logN)
function insert(H, x) {
//思路:先在数组最后加入目标元素x
H.push(x);
//然后向上推
siftUp(H, H.length - 1);
}
ヒープから要素を削除します
//删除堆H中指定位置i的元素
//时间复杂度O(logN)
function remove(H, i) {
//思路:先把位置i的元素与最后位置的元素n交换
//然后数据长度减1(这样就把i位置的元素给干掉了,但是整个堆就被破坏了)
//需要做一个决定:最后一个元素n需要向上调整,还是向下调整
//依据:比如比原来该位置的元素大,则向上调整,反之向下调整
var x = H[i]; //先把原来i位置的元素保护起来
//把最后一个元素放到i位置
//同时删除最后一个元素(js语言的优越性体现!)
H[i] = H.pop();
var n = H.length - 1;
if (i == n + 1) {
//如果去掉的正好是最后二个元素之一,
//无需再调整
return ;
}
if (H[i] > x) {
siftUp(H, i);
}
else {
siftDown(H, i);
}
}
//从堆中删除最大项
//返回最大值
//时间复杂度O(logN)
function deleteMax(H) {
var x = H[1];
remove(H, 1);
return x;
}
ヒープソート :
これは非常に賢いソートアルゴリズムであり、その本質はデータ構造「ヒープ」の特性を最大限に活用することにあり(最初の要素が最大である必要があります)、時間の再テストによって各要素を上下に移動できます。スペースの点では O(logN) のみなので、追加のストレージスペースを使用する必要はなく、配列自体内の要素を交換するだけです。
もの:
1. 最初に最初の要素 (つまり、最大の要素) を最後の要素と交換します。目的は、最大値を一番下に沈め、次のラウンドでは無視することです。
2. 1 の後、残りの要素は通常、ヒープではなくなります。このとき、siftDown を使用して新しい最初の要素を下方向に調整するだけです。調整後、新しい最大要素は自然に最初の要素の位置まで上昇します
。
3. 1 と 2 を繰り返すと、大きな要素が 1 つずつ下に沈み、最終的に配列全体が整います。
時間計算量分析: ヒープの作成には O(n) コストが必要で、各 siftDown コストは O(logN) で、最大 n-1 個の要素を調整できるため、総コストは O(N) (N-1)O( logN) 、最終的な時間計算量は O(NLogN)
//堆中的节点下移
//(约定有效元素从下标1开始)
//i为要调整的元素索引
//n为待处理的有效元素下标范围上限值
//时间复杂度O(logN)
function siftDown(H, i, n) {
if (n >= H.length) {
n = H.length;
}
if (2 * i > n) { //叶子节点,就不用再向下移了
return;
}
for (var j = 2 * i; j < n; j = 2 * j) {
//将j定位到 二个子节点中较大的那个上(很巧妙的做法)
if (H[j + 1] > H[j]) {
j++;
}
var k = Math.floor(j / 2);
if (H[k] < H[j]) {
var t = H[k];
H[k] = H[j];
H[j] = t;
}
else {
return;
}
}
}
//对数组的前n个元素进行创建堆的操作
function makeHeap(A, n) {
if (n >= A.length) {
n = A.length;
}
for (var i = Math.floor(n / 2); i >= 1; i--) {
siftDown(A, i, n);
}
}
//堆排序(非降序排列)
//时间复杂度O(nlogN)
function heapSort(H) {
//先建堆
makeHeap(H, H.length);
for (var j = H.length - 1; j >= 2; j--) {
//首元素必然是最大的
//将最大元素与最后一个元素互换,
//即将最大元素沉底,下一轮不再考虑
var x = H[1];
H[1] = H[j];
H[j] = x;
//互换后,剩下的元素不再满足堆定义,
//把新的首元素下调(以便继续维持堆的"形状")
//调整完后,剩下元素中的最大值必须又浮到了第一位
//进入下一轮循环
siftDown(H, 1, j - 1);
}
return H;
}
ヒープの構築に関しては、原理を理解していれば考え方を逆にして逆に行うことも可能です
function makeHeap2(A, n) {
if (n >= A.length) {
n = A.length;
}
for (var i = Math.floor(n / 2); i <= n; i++) {
siftUp(A, i);
}
}
素セットの検索とマージ
//定义节点Node类
var Node = function (v, p) {
this.value = v; //节点的值
this.parent = p; //节点的父节点
this.rank = 0; //节点的秩(默认为0)
}
//查找包含节点x的树根节点
var find = function (x) {
var y = x;
while (y.parent != null) {
y = y.parent;
}
var root = y;
y = x;
//沿x到根进行“路径压缩”
while (y.parent != null) {
//先把父节点保存起来,否则下一行调整后,就弄丢了
var w = y.parent;
//将目标节点挂到根下
y.parent = root;
//再将工作指针,还原到 目标节点原来的父节点上,
//继续向上逐层压缩
y = w
}
return root;
}
//合并节点x,y对应的两个树
//时间复杂度O(m) - m为待合并的子集合数量
var union = function (x, y) {
//先找到x所属集合的根
var u = find(x);
//再找到y所属集合的根
var v = find(y);
//把rank小的集合挂到rank大的集合上
if (u.rank <= v.rank) {
u.parent = v;
if (u.rank == v.rank) {
//二个集合的rank不分伯仲时
//给"胜"出方一点奖励,rank+1
v.rank += 1;
}
}
else {
v.parent = u;
}
}
誘導方法:
まず、並べ替えの 2 つの再帰実装を見てみましょう
//选择排序的递归实现
//调用示例: selectionSort([3,2,1],0)
function selectionSortRec(A, i) {
var n = A.length - 1;
if (i < n) {
var k = i;
for (var j = i + 1; j <= n; j++) {
if (A[j] < A[k]) {
k = j
}
}
if (k != i) {
var t = A[k];
A[k] = A[i];
A[i] = t;
}
selectionSortRec(A, i + 1);
}
}
//插入排序递归实现
//调用示例:insertSortRec([4,3,2,1],3);
function insertSortRec(A, i) {
if (i > 0) {
var x = A[i];
insertSortRec(A, i - 1);
var j = i - 1;
while (j >= 0 && A[j] > x) {
A[j + 1] = A[j];
j--;
}
A[j + 1] = x;
}
}
再帰的プログラムは通常、理解しやすく、コードの実装も簡単です。2 つの小さな例を見てみましょう。
配列から最大値を求める
//在数组中找最大值(递归实现)
function findMax(A, i) {
if (i == 0) {
return A[0];
}
var y = findMax(A, i - 1);
var x = A[i - 1];
return y > x ? y : x;
}
var A = [1,2,3,4,5,6,7,8,9];
var test = findMax(A,A.length);
alert(test);//返回9
昇順にソートされた配列があり、配列内に 2 つの数値があり、それらの合計が正確に x であるかどうかを確認してください。
//5.33 递归实现
//A为[1..n]已经排好序的数组
//x为要测试的和
//如果存在二个数的和为x,则返回true,否则返回false
function sumX(A, i, j, x) {
if (i >= j) {
return false;
}
if (A[i] + A[j] == x) {
return true;
}
else if (A[i] + A[j] < x) {
//i后移
return sumX(A, i + 1, j, x);
}
else {
//j前移
return sumX(A, i, j - 1, x);
}
}
var A = [1, 2, 3, 4, 5, 6, 7, 8];
var test1 = sumX(A,0,A.length-1,9);
alert(test1); //返回true
递归程序虽然思路清晰,但通常效率不高,一般来讲,递归实现,都可以改写成非递归实现,上面的代码也可以写成:
//5.33 非递归实现
function sumX2(A, x) {
var i = 0, j = A.length - 1;
while (i < j) {
if (A[i] + A[j] == x) {
return true;
}
else if (A[i] + A[j] < x) {
//i后移
i++;
}
else {
//j前移
j--;
}
}
return false;
}
var A = [1, 2, 3, 4, 5, 6, 7, 8];
var test2 = sumX2(A,9);
alert(test2);//返回true
递归并不总代表低效率,有些场景中,递归的效率反而更高,比如计算x的m次幂,常规算法,需要m次乘法运算,下面的算法,却将时间复杂度降到了O(logn)
//计算x的m次幂(递归实现)
//时间复杂度O(logn)
function expRec(x, m) {
if (m == 0) {
return 1;
}
var y = expRec(x, Math.floor(m / 2));
y = y * y;
if (m % 2 != 0) {
y = x * y
}
return y;
}
当然,这其中并不光是递归的功劳,其效率的改进 主要依赖于一个数学常识: x^m = [x^(m/2)]^2,关于这个问题,还有一个思路很独特的非递归解法,巧妙的利用了二进制的特点
//将10进制数转化成2进制
function toBin(dec) {
var bits = [];
var dividend = dec;
var remainder = 0;
while (dividend >= 2) {
remainder = dividend % 2;
bits.push(remainder);
dividend = (dividend - remainder) / 2;
}
bits.push(dividend);
bits.reverse();
return bits.join("");
}
//计算x的m次幂(非递归实现)
//很独特的一种解法
function exp(x, m) {
var y = 1;
var bin = toBin(m).split('');
//先将m转化成2进制形式
for (var j = 0; j < bin.length; j++) {
y = y * 2;
//如果2进制的第j位是1,则再*x
if (bin[j] == "1") {
y = x * y
}
}
return y;
}
//println(expRec(2, 5));
//println(exp(2, 5));
再来看看经典的多项式求值问题:
给定一串实数An,An-1,...,A1,A0 和一个实数X,计算多项式Pn(x)的值
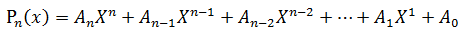
著名的Horner公式:
已经如何计算:
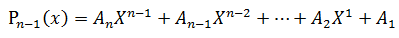
显然有:
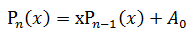
这样只需要 N次乘法+N次加法
//多项式求值
//N次乘法+N次加法搞定,伟大的改进!
function horner(A, x) {
var n = A.length - 1
var p = A[n];
for (var j = 0; j < n; j++) {
p = x * p + A[n - j - 1];
}
return p;
}
//计算: y(2) = 3x^3 + 2x^2 + x -1;
var A = [-1, 1, 2, 3];
var y = horner(A, 2);
alert(y);//33
多数问题:
一个元素个数为n的数组,希望快速找出其中大于出现次数>n/2的元素(该元素也称为多数元素)。通常可用于选票系统,快速判定某个候选人的票数是否过半。最优算法如下:
//找出数组A中“可能存在”的多数元素
function candidate(A, m) {
var count = 1, c = A[m], n = A.length - 1;
while (m < n && count > 0) {
m++;
if (A[m] == c) {
count++;
}
else {
count--;
}
}
if (m == n) {
return c;
}
else {
return candidate(A, m + 1);
}
}
//寻找多数元素
//时间复杂度O(n)
function majority(A) {
var c = candidate(A, 0);
var count = 0;
//找出的c,可能是多数元素,也可能不是,
//必须再数一遍,以确保结果正确
for (var i = 0; i < A.length; i++) {
if (A[i] == c) {
count++;
}
}
//如果过半,则确定为多数元素
if (count > Math.floor(A.length / 2)) {
return c;
}
return null;
}
var m = majority([3, 2, 3, 3, 4, 3]);
alert(m);
以上算法基于这样一个结论:在原序列中去除两个不同的元素后,那么在原序列中的多数元素在新序列中还是多数元素
证明如下:
如果原序列的元素个数为n,多数元素出现的次数为x,则 x/n > 1/2
去掉二个不同的元素后,
a)如果去掉的元素中不包括多数元素,则新序列中 ,原先的多数元素个数/新序列元素总数 = x/(n-2) ,因为x/n > 1/2 ,所以 x/(n-2) 也必然>1/2
b)如果去掉的元素中包含多数元素,则新序列中 ,原先的多数元素个数/新序列元素总数 = (x-1)/(n-2) ,因为x/n > 1/2 =》 x>n/2 代入 (x-1)/(n-2) 中,
有 (x-1)/(n-2) > (n/2 -1)/(n-2) = 2(n-2)/(n-2) = 1/2
下一个问题:全排列
function swap(A, i, j) {
var t = A[i];
A[i] = A[j];
A[j] = t;
}
function println(msg) {
document.write(msg + "<br/>");
}
//全排列算法
function perm(P, m) {
var n = P.length - 1;
if (m == n) {
//完成一个新排列时,输出
println(P);
return;
}
for (var j = m; j <= n; j++) {
//将起始元素与后面的每个元素交换
swap(P, j, m);
//在前m个元素已经排好的基础上
//再加一个元素进行新排列
perm(P, m + 1);
//把j与m换回来,恢复递归调用前的“现场",
//否则因为递归调用前,swap已经将原顺序破坏了,
//导致后面生成排序时,可能生成重复
swap(P, j, m);
}
}
perm([1, 2, 3], 0);
//1,2,3
//1,3,2
//2,1,3
//2,3,1
//3,2,1
//3,1,2
分治法:
要点:将问题划分成二个子问题时,尽量让子问题的规模大致相等。这样才能最大程度的体现一分为二,将问题规模以对数折半缩小的优势。
//打印输出(调试用)
function println(msg) {
document.write(msg + "<br/>");
}
//数组中i,j位置的元素交换(辅助函数)
function swap(A, i, j) {
var t = A[i];
A[i] = A[j];
A[j] = t;
}
//寻找数组A中的最大、最小值(分治法实现)
function findMinMaxDiv(A, low, high) {
//最小规模子问题的解
if (high - low == 1) {
if (A[low] < A[high]) {
return [A[low], A[high]];
}
else {
return [A[high], A[low]];
}
}
var mid = Math.floor((low + high) / 2);
//在前一半元素中寻找子问题的解
var r1 = findMinMaxDiv(A, low, mid);
//在后一半元素中寻找子问题的解
var r2 = findMinMaxDiv(A, mid + 1, high);
//把二部分的解合并
var x = r1[0] > r2[0] ? r2[0] : r1[0];
var y = r1[1] > r2[1] ? r1[1] : r2[1];
return [x, y];
}
var r = findMinMaxDiv([1, 2, 3, 4, 5, 6, 7, 8], 0, 7);
println(r); //1,8
//二分搜索(分治法实现)
//输入:A为已按非降序排列的数组
//x 为要搜索的值
//low,high搜索的起、止索引范围
//返回:如果找到,返回下标,否则返回-1
function binarySearchDiv(A, x, low, high) {
if (low > high) {
return -1;
}
var mid = Math.floor((low + high) / 2);
if (x == A[mid]) {
return mid;
}
else if (x < A[mid]) {
return binarySearchDiv(A, x, low, mid - 1);
}
else {
return binarySearchDiv(A, x, mid + 1, high);
}
}
var f = binarySearchDiv([1, 2, 3, 4, 5, 6, 7], 4, 0, 6);
println(f); //3
//将数组A,以low位置的元素为界,划分为前后二半
//n为待处理的索引范围上限
function split(A, low, n) {
if (n >= A.length - 1) {
n = A.length - 1;
}
var i = low;
var x = A[low];
//二个指针一前一后“跟随”,
//最前面的指针发现有元素比分界元素小时,换到前半部
//后面的指针再紧跟上,“夫唱妇随”一路到头
for (var j = low + 1; j <= n; j++) {
if (A[j] <= x) {
i++;
if (i != j) {
swap(A, i, j);
}
}
}
//经过上面的折腾后,除low元素外,其它的元素均以就位
//最后需要把low与最后一个比low位置小的元素交换,
//以便把low放在分水岭位置上
swap(A, low, i);
return [A, i];
}
var A = [5, 1, 2, 6, 3];
var b = split(A, 0, A.length - 1);
println(b[0]); //3,1,2,5,6
//快速排序
function quickSort(A, low, high) {
var w = high;
if (low < high) {
var t = split(A, low, w); //分治思路,先分成二半
w = t[1];
//在前一半求解
quickSort(A, low, w - 1);
//在后一半求解
quickSort(A, w + 1, high);
}
}
var A = [5, 6, 4, 7, 3];
quickSort(A, 0, A.length - 1);
println(A); //3,4,5,6,7
split算法的思想应用:
设A[1..n]是一个整数集,给出一算法重排数组A中元素,使得所有的负整数放到所有非负整数的左边,你的算法的运行时间应当为Θ(n)
function sort1(A) {
var i = 0, j = A.length - 1;
while (i < j) {
if (A[i] >= 0 && A[j] >= 0) {
j--;
}
else if (A[i] < 0 && A[j] < 0) {
i++;
}
else if (A[i] > 0 && A[j] < 0) {
swap(A, i, j);
i++;
j--;
}
else {
i++;
j--;
}
}
}
function sort2(A) {
if (A.length <= 1) { return; }
var i = 0;
for (var j = i + 1; j < A.length; j++) {
if (A[j] < 0 && A[i] >= 0) {
swap(A, i, j);
i++;
}
}
}
var a = [1, -2, 3, -4, 5, -6, 0];
sort1(a);
println(a);//-6,-2,-4,3,5,1,0
var b = [1, -2, 3, -4, 5, -6, 0];
sort2(b);
println(b);//-2,-4,-6,1,5,3,0
希望本文所述对大家JavaScript程序设计有所帮助。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7442
7442
 15
1371
52
76
11
7
6
15
1371
52
76
11
7
6

 CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: BEVFormer 構造を明示的に監視して、ロングテール検出パフォーマンスを向上させます。
Mar 26, 2024 pm 12:41 PM
上記および筆者の個人的な理解: 現在、自動運転システム全体において、認識モジュールが重要な役割を果たしている。道路を走行する自動運転車は、認識モジュールを通じてのみ正確な認識結果を得ることができる。下流の規制および制御モジュール自動運転システムでは、タイムリーかつ正確な判断と行動決定が行われます。現在、自動運転機能を備えた自動車には通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなどのさまざまなデータ情報センサーが搭載されており、さまざまなモダリティで情報を収集して正確な認識タスクを実現しています。純粋な視覚に基づく BEV 認識アルゴリズムは、ハードウェア コストが低く導入が容易であるため、業界で好まれており、その出力結果はさまざまな下流タスクに簡単に適用できます。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の基礎となる原則とアルゴリズムの選択を調べる
Apr 02, 2024 pm 05:36 PM
C++sort 関数の最下層はマージ ソートを使用し、その複雑さは O(nlogn) で、クイック ソート、ヒープ ソート、安定したソートなど、さまざまなソート アルゴリズムの選択肢を提供します。
 人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能は犯罪を予測できるのか? CrimeGPT の機能を調べる
Mar 22, 2024 pm 10:10 PM
人工知能 (AI) と法執行機関の融合により、犯罪の予防と検出の新たな可能性が開かれます。人工知能の予測機能は、犯罪行為を予測するためにCrimeGPT (犯罪予測技術) などのシステムで広く使用されています。この記事では、犯罪予測における人工知能の可能性、その現在の応用、人工知能が直面する課題、およびこの技術の倫理的影響について考察します。人工知能と犯罪予測: 基本 CrimeGPT は、機械学習アルゴリズムを使用して大規模なデータセットを分析し、犯罪がいつどこで発生する可能性があるかを予測できるパターンを特定します。これらのデータセットには、過去の犯罪統計、人口統計情報、経済指標、気象パターンなどが含まれます。人間のアナリストが見逃す可能性のある傾向を特定することで、人工知能は法執行機関に力を与えることができます
 改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
改良された検出アルゴリズム: 高解像度の光学式リモートセンシング画像でのターゲット検出用
Jun 06, 2024 pm 12:33 PM
01 今後の概要 現時点では、検出効率と検出結果の適切なバランスを実現することが困難です。我々は、光学リモートセンシング画像におけるターゲット検出ネットワークの効果を向上させるために、多層特徴ピラミッド、マルチ検出ヘッド戦略、およびハイブリッドアテンションモジュールを使用して、高解像度光学リモートセンシング画像におけるターゲット検出のための強化されたYOLOv5アルゴリズムを開発しました。 SIMD データセットによると、新しいアルゴリズムの mAP は YOLOv5 より 2.2%、YOLOX より 8.48% 優れており、検出結果と速度のバランスがより優れています。 02 背景と動機 リモート センシング技術の急速な発展に伴い、航空機、自動車、建物など、地表上の多くの物体を記述するために高解像度の光学式リモート センシング画像が使用されています。リモートセンシング画像の判読における物体検出
 簡単な JavaScript チュートリアル: HTTP ステータス コードを取得する方法
Jan 05, 2024 pm 06:08 PM
簡単な JavaScript チュートリアル: HTTP ステータス コードを取得する方法
Jan 05, 2024 pm 06:08 PM
JavaScript チュートリアル: HTTP ステータス コードを取得する方法、特定のコード例が必要です 序文: Web 開発では、サーバーとのデータ対話が頻繁に発生します。サーバーと通信するとき、多くの場合、返された HTTP ステータス コードを取得して操作が成功したかどうかを判断し、さまざまなステータス コードに基づいて対応する処理を実行する必要があります。この記事では、JavaScript を使用して HTTP ステータス コードを取得する方法を説明し、いくつかの実用的なコード例を示します。 XMLHttpRequestの使用
 58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
58 ポートレート プラットフォームの構築におけるアルゴリズムの適用
May 09, 2024 am 09:01 AM
1. 58 Portraits プラットフォーム構築の背景 まず、58 Portraits プラットフォーム構築の背景についてお話ししたいと思います。 1. 従来のプロファイリング プラットフォームの従来の考え方ではもはや十分ではありません。ユーザー プロファイリング プラットフォームを構築するには、複数のビジネス分野からのデータを統合して、ユーザーの行動や関心を理解するためのデータ マイニングも必要です。最後に、ユーザー プロファイル データを効率的に保存、クエリ、共有し、プロファイル サービスを提供するためのデータ プラットフォーム機能も必要です。自社構築のビジネス プロファイリング プラットフォームとミドルオフィス プロファイリング プラットフォームの主な違いは、自社構築のプロファイリング プラットフォームは単一のビジネス ラインにサービスを提供し、オンデマンドでカスタマイズできることです。ミッドオフィス プラットフォームは複数のビジネス ラインにサービスを提供し、複雑な機能を備えていることです。モデリングを提供し、より一般的な機能を提供します。 2.58 中間プラットフォームのポートレート構築の背景のユーザーのポートレート 58
 SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
SOTA をリアルタイムで追加すると、大幅に増加します。 FastOcc: より高速な推論と展開に適した Occ アルゴリズムが登場しました。
Mar 14, 2024 pm 11:50 PM
上記と著者の個人的な理解は、自動運転システムにおいて、認識タスクは自動運転システム全体の重要な要素であるということです。認識タスクの主な目的は、自動運転車が道路を走行する車両、路側の歩行者、運転中に遭遇する障害物、道路上の交通標識などの周囲の環境要素を理解して認識できるようにすることで、それによって下流のシステムを支援できるようにすることです。モジュール 正しく合理的な決定と行動を行います。自動運転機能を備えた車両には、通常、サラウンドビューカメラセンサー、ライダーセンサー、ミリ波レーダーセンサーなど、さまざまな種類の情報収集センサーが装備されており、自動運転車が正確に認識し、認識できるようにします。周囲の環境要素を理解することで、自動運転車が自動運転中に正しい判断を下せるようになります。頭
