

この記事では主にphpのワード解析とドキュメント内の画像の取得について紹介していますが、これは一定の参考値があるので、みんなに共有します。困っている友達は参考にしてください。
私は少し前に、ネイティブ PHP を使用して Word でコンテンツを取得し、それを Web サイト システムにインポートする関数を作成していました。文書には数式や図、表などが含まれるため、書くのがさらに面倒になります。
一般的なアイデアは、まず Word で doc としてフォーマットされた文書を docx に変換し、次に前処理プログラムを使用して文書内の数式を docx に変換することです。 swf 画像形式。word を xml 形式に変換し、xml のコンテンツを json 形式に変換します。
1. xml の基本を理解する
xml は拡張可能なマークアップです。言語はインターネットでデータを送信するための重要なツールですが、XMLはプログラミング言語やOSに制限されることなく、クロスインターネットプラットフォームを実現することができ、インターネット上で最高レベルのパスを持つデータキャリアと言えます。
xml は、構造化文書情報の処理に使用されている現在のテクノロジーであり、サーバー間で構造化発行をやり取りするのに役立ち、開発者がデータの保存と送信をより便利に制御できるようになります。
xml は、使用されるマークアップ言語です。電子ドキュメントをマークして構造化します。データのマーク付けとデータ型の定義に使用できます。ユーザーが独自のマークアップ言語を定義できるソース言語です。これは標準の汎用言語のサブセットであり、Web 送信に適しています。
#2. Word の 2 つの異なる保存方法
Word ドキュメントの 2 つの保存形式: doc と docxdoc:従来は word と呼ばれていましたが、バイナリを使用してデータを保存します docx: つまり、word2007 は、xml を使用してデータを保存しますその後、サフィックスは明らかに docx 形式ですが、なぜ XML 形式なのでしょうか? test.docx を選択し、サフィックス名を .zip に変更して解凍し、次のディレクトリ構造を取得します。
3. DOM と PHP を理解する DOM XML 解析
DOM は HTML および XML ドキュメントを提供します Aオブジェクトの標準セットと、これらのドキュメントにアクセスして操作するための標準インターフェイスです。 XML DOM は、ドキュメントの標準を定義するオブジェクトのセットです。 PHP DOM 拡張機能を使用すると、DOM ツリーに対する一連の操作を PHP で実装できます。 PHP DOM を使用して XML ドキュメントを読み取ります: test.xml:<?xml version="1.0" encoding="utf-8"?><teststore><test> <name>php dom test</name> <author>test-one</author></test><test> <title>php dom test 2</title> <author>test-two</author></test></teststore>
<?php $doc = new DOMDocument();
$doc->load("test.xml"); //获取标签对象
$book=$doc->getElementsByTagName("test"); //输出第一个中的值
echo $book->item(0)->nodeValue;
echo "<br>----------------<br>";
$title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue;
echo "<br>----------------<br>"; //遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}
#4. Word における XML の定義形式
Word 内のデータはどのように定義されているのでしょうか。 ? 2 つのファイル/フォルダーのみを紹介します。 1 つのファイルは word/document.xml で、Word ドキュメント全体のコンテンツを定義します。 もう 1 つのフォルダーは word/media です。このフォルダーには文書のマルチメディア コンテンツが保存されます。つまり、文書内のすべての画像、オーディオ、ビデオがこのフォルダーに保存されます。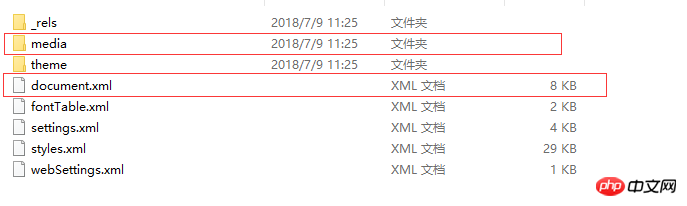
<w:document mc:ignorable="w14 w15 wp14" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpscustomdata="http://www.wps.cn/officeDocument/2013/wpsCustomData">
<w:body>
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr><w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
<w:spacing w:after="150" w:afterautospacing="0" w:before="150" w:beforeautospacing="0" w:line="378" w:linerule="atLeast">
</w:spacing>
<w:ind w:firstline="0" w:left="0" w:right="0">
</w:ind>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
</w:rpr>
</w:ppr>
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:t>
作者: Test </w:t>
</w:r>
</w:p><w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:drawing>
<wp:inline distb="0" distl="114300" distr="114300" distt="0">
<wp:extent cx="5543550" cy="5543550">
</wp:extent>
<wp:effectextent b="0" l="0" r="0" t="0">
</wp:effectextent>
<wp:docpr descr="IMG_256" id="1" name="Picture 1">
</wp:docpr>
<wp:cnvgraphicframepr>
<a:graphicframelocks nochangeaspect="1" xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
</a:graphicframelocks>
</wp:cnvgraphicframepr>
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
<a:graphicdata uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:nvpicpr>
<pic:cnvpr descr="IMG_256" id="1" name="Picture 1">
</pic:cnvpr>
<pic:cnvpicpr>
<a:piclocks nochangeaspect="1">
</a:piclocks>
</pic:cnvpicpr>
</pic:nvpicpr>
<pic:blipfill>
<a:blip r:embed="rId4">
</a:blip>
<a:stretch>
<a:fillrect>
</a:fillrect>
</a:stretch>
</pic:blipfill>
<pic:sppr>
<a:xfrm>
<a:off x="0" y="0">
</a:off>
<a:ext cx="5543550" cy="5543550">
</a:ext>
</a:xfrm>
<a:prstgeom prst="rect">
<a:avlst>
</a:avlst>
</a:prstgeom>
<a:nofill>
</a:nofill>
<a:ln w="9525">
<a:nofill>
</a:nofill>
</a:ln>
</pic:sppr>
</pic:pic>
</a:graphicdata>
</a:graphic>
</wp:inline>
</w:drawing>
</w:r><w:document> 定义整个文档的开始 <w:body> document的子节点,文档的主体内容 <w:p> body的子节点,一个段落,就是word文档中的段落 <w:r> p元素的子节点,一个Run定义了段落中具有相同格式的一段内容 <w:t> Run元素节点的子节点,就是文档的内容 <w:drawing> run元素的子节点,定义了一张图片 <w:inline> drawing子节点,具体应用没有研究 <a:graphic> 定义了图片内容 <pic:blipfill> graphic文档的子节点,定义了图片内容的索引.
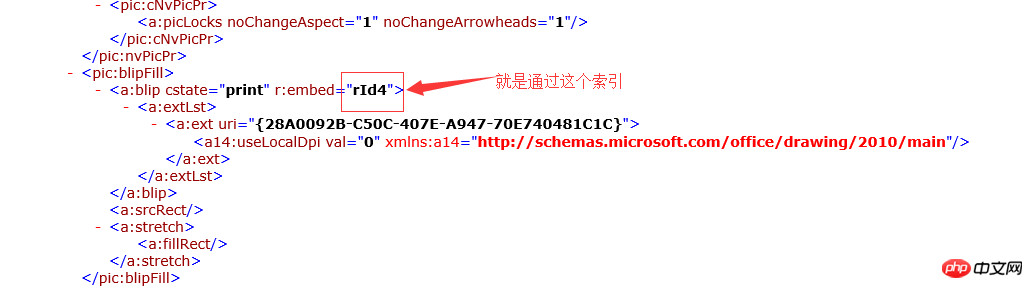
具体的なアイデア: PHP の組み込み DOMDocument インターフェイスを通じて docx ドキュメントの xml ノードを取得し、xml ノードを走査して、保存されているノード要素を見つけます。画像を検索し、画像ノードを下に移動して、r:embed インデックスの値を取得します。 docx ドキュメントは圧縮パッケージ形式であるため、docx ドキュメントは PHP 組み込みインターフェイス ZipArchive インターフェイスを介して走査され (基本的に .zip 圧縮パッケージを走査します)、対応するイメージがインデックスを通じて検索されます。 imgタグは画像データをbase64形式で表示します。
XML に変換: private $rels_xml;
private $doc_xml;
private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
$this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML();
$this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML();
}if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
} private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
} private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 < 10) ? mb_substr($file_name,mb_strlen($imgname,"utf-8"),1, 'utf-8') : '';
if($rIdIndex-8 < 10 && $a != '.') continue;
if ($enter_zp = zip_entry_open($zip, $zip_entry, "r")) { //读取包中文件
$ext = pathinfo(zip_entry_name ($zip_entry),PATHINFO_EXTENSION);//获取图片文件扩展名
$content = zip_entry_read($zip_entry,zip_entry_filesize($zip_entry));//读取文件二进制数据
return sprintf('<img src="data:image/%s;base64,%s">', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
以上がPHPを使用してドキュメント内の画像を解析する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



