

Java アプリケーション分散アーキテクチャの進化プロセスに関する簡単な説明

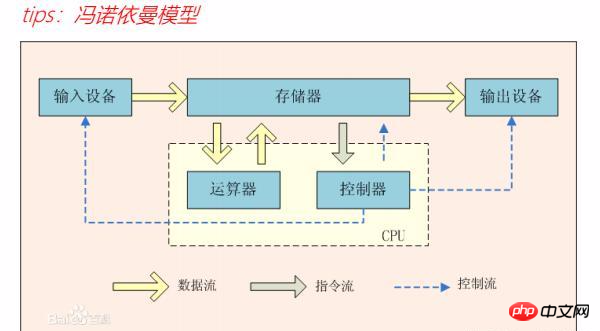
IOE は、IBM のミニコンピューター、Oracle のデータベース、EMC のハイエンド ストレージ デバイスを指します。2009 年の IOE からの移行は、Alipay の最後の IBM ミニコンピューターが 2003 年にオフラインになるまで続きました。
なぜIOEに行くのか
アリババは過去にデータベースにOracleを使用し、ミニコンピューターとハイエンドストレージデバイスを使用して高性能のデータ処理とストレージサービスを提供していました。企業のビジネス量が増加し、ユーザー数が増加し続けるにつれて、従来の集中型アーキテクチャの Oracle データベースは拡張のボトルネックに直面しています。従来の Oracle と比較すると、DB2 は主に集中型であり、集中型の拡張では水平方向の拡張ではなく、上向きの拡張が主となるため、これは遅かれ早かれシステムのボトルネックになります。
1. 分散アーキテクチャの共通概念
クラスター
この小さなレストランは、野菜を切り、野菜を洗い、食材を準備し、調理するシェフであることが判明しました。その後、客が増えたとき、厨房の一人のシェフが忙しすぎたので、二人のシェフが同じ料理を作ることができました。
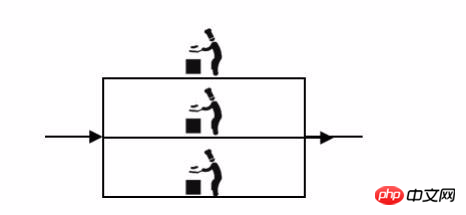
シェフが料理に集中して完璧な料理を作るために、野菜のカット、野菜の準備、材料の準備を担当するシェフが雇われています。シェフとシェフが分散していて、おかずシェフ一人でも多忙で、おかずシェフを雇うと二人のシェフの関係がクラスターになってしまう。したがって、分散アーキテクチャにはクラスターが存在する可能性がありますが、クラスターは分散を意味するものではありません。
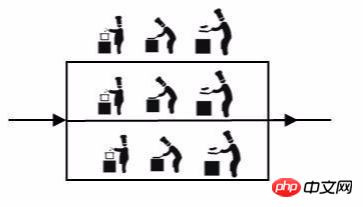
Node
Nodeとは、分散プロトコルに従って一連のロジックを独立して完了できる個別のプログラムを指します。特定のプロジェクトでは、ノードはオペレーティング システム上のプロセスを表します。
レプリカのメカニズム
レプリカとは、分散システム内のデータまたはサービスに冗長性を提供することを指します。
データのコピーとは、同じデータを別のノードに保持することを指し、特定のノード上のデータが失われた場合に、コピーからデータを読み取ることができます。データのコピーは、分散システムでデータ損失が発生する唯一の手段です。
サービスコピーとは、複数のノードが同じサービスを提供し、マスター/スレーブ関係を通じてサービスの高可用性ソリューションを実現することを意味します。
ミドルウェア
ミドルウェアは、オペレーティングシステムによって提供されるサービスに追加されるものであり、アプリケーションに属さず、開発者にとってアプリケーション層とシステム層の間の通信、入出力を便利に処理するソフトウェアの一種です。これにより、ユーザーはアプリケーションの一部を気にすることができます。
アーキテクチャの開発プロセス
成熟した大規模Webサイトシステムのアーキテクチャは、最初から完璧に設計されているわけではなく、最初から高性能、高可用性、セキュリティなどの機能を備えているわけではなく、ユーザー数の増加に伴い、ビジネス機能の拡張が徐々に改善されるにつれて、時間の経過とともに進化しました。この開発プロセスでは、開発モデルや技術アーキテクチャなどが大きく変化します。
システムが以下の機能を持っているとします:
ユーザーモジュール: ユーザーの登録と管理
商品モジュール: 商品の表示と管理
トランザクションモジュール: トランザクションの作成と支払い決済
フェーズ 1: 単一アプリケーション アーキテクチャ
システムの開始時には、アプリケーションとデータベースの両方が 1 つのサーバー上に配置されます。

フェーズ 2: アプリケーション サーバーとデータベース サーバーの分離
Web サイトのユーザー数が増加し、トラフィックが増加するにつれて、アプリケーション サーバーとデータベース サーバーを別々のデプロイメント マシンに配置すると、システムのパフォーマンスが向上し、パフォーマンスが向上します。アクセス効率が向上し、単一マシンの負荷容量と災害復旧機能が向上します。
フェーズ 3: アプリケーション サーバー クラスター - アプリケーション サーバー負荷アラーム
アクセス数とトラフィックが増加すると、データベースにボトルネックが発生しないと仮定して、アプリケーション サーバー クラスターを使用してリクエストをオフロードし、プログラムのパフォーマンスを向上させます。既存の問題: ユーザーのリクエストを誰が転送するか、およびセッションをどのように管理するか。
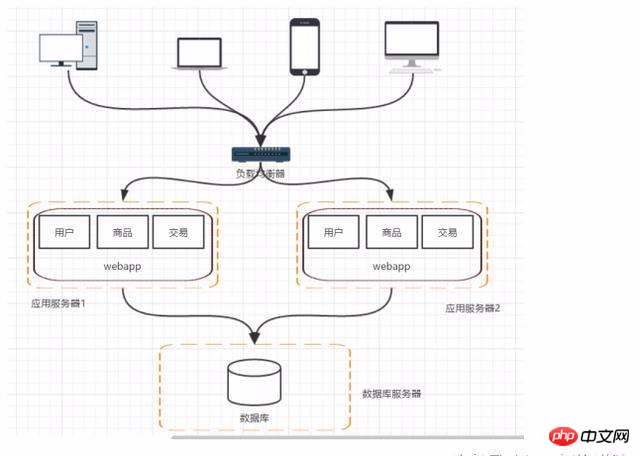
フェーズ 4: データベースの負荷が増加します - データベースの読み取りと書き込みの分離
読み取りと書き込みが分離されている場合、今後のリクエストとクエリリクエストはスレーブライブラリからデータを読み取り、書き込まれたデータをメインライブラリに送信できます。ただし、次のような問題が発生します:
1. マスター データベースとスレーブ データベース間のデータ同期: mysql に付属のマスター/スレーブ メソッドを使用して、マスター/スレーブ レプリケーションを実現できます。
2. 対応するデータ ソースの選択: を使用します。サードパーティのデータベースミドルウェア (mycat
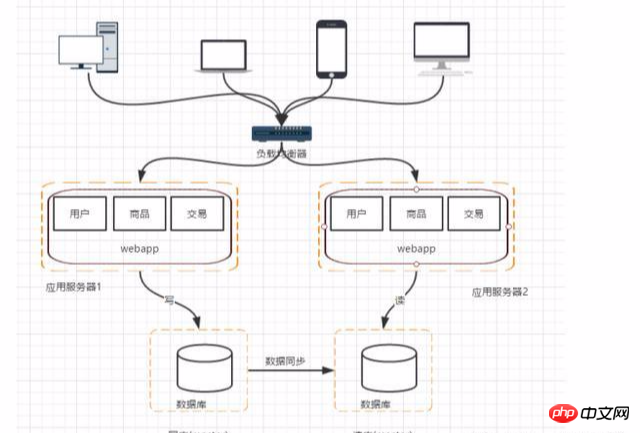
ステージ 5: 検索エンジンを使用して、データベースの読み取りの負担を軽減します
データベースの読み取りにデータベースを使用する場合、特に大規模なインターネット企業の場合、検索対象のモジュールのファジー クエリのパフォーマンスがあまり良くないことがよくあります。これにより、検索エンジンを使用できるようになり、クエリの速度が大幅に向上しますが、インデックスの構築などの問題も発生します。
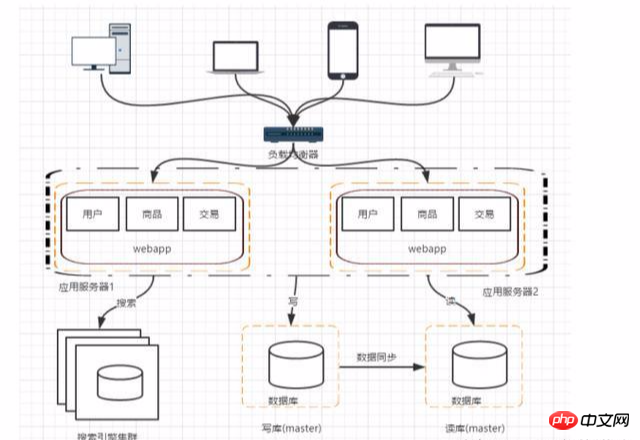
ステージ 6: データベースへの負荷を軽減するためのキャッシュ メカニズムを導入します
一部のホット データについては、アプリケーション層のキャッシュとして redis と memcache を使用できます。また、シナリオによっては、mongodb を使用して置き換えることもできます。保存するリレーショナル データベース。
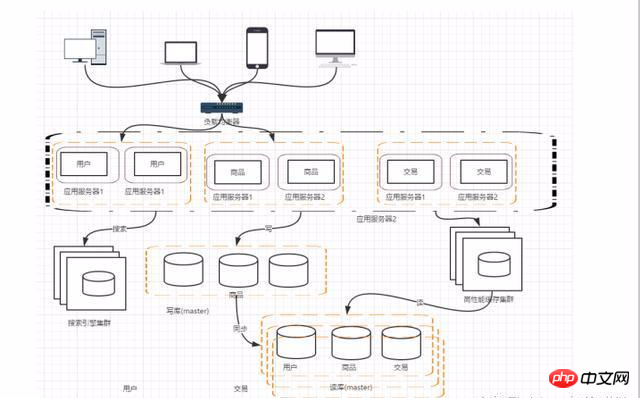
ステージ 7: データベースの水平/垂直分割
垂直分割: データベース内の異なるビジネス データを異なるデータベースに分割します。
水平分割: 同じテーブル内のデータを 2 つ以上のデータベースに分割します。水平分割の理由は、現時点で、大量のデータを扱う一部のビジネスが単一のデータベースのボトルネックに達しているためです。テーブルを複数のデータベースに分割します。

ステージ 8: アプリケーションの分割
ビジネスの発展に伴い、ビジネスの数はますます増え、アプリケーションに対するプレッシャーは増大しています。プロジェクトの規模もますます大きくなっています。現時点では、アプリケーションを分割し、ドメイン モデルに従ってユーザー、製品、トランザクションをサブシステムに分割することを検討できます。
このような分割後、ユーザーの操作や商品取引の問い合わせなど、いくつかの同一のコードが存在する可能性があり、これらすべてにより、各システムにユーザーの問い合わせとアクセス関連の操作が発生します。これらの同じコードとモジュールは抽象化する必要があります。これにより保守・管理が容易になります。
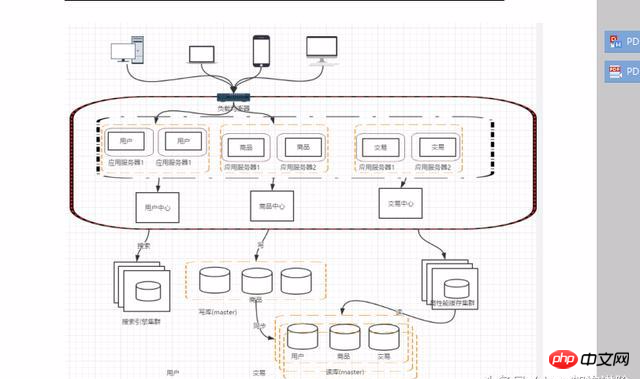
サービスが分割された後、サービス間の通信は RPC テクノロジーを介して行われます。代表的なものは、Web サービス、hession、http、RMI などです。
以上がJava アプリケーション分散アーキテクチャの進化プロセスに関する簡単な説明の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7518
7518
 15
1378
52
81
11
21
68
15
1378
52
81
11
21
68

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
未来を創る: まったくの初心者のための Java プログラミング
Oct 13, 2024 pm 01:32 PM
Java は、初心者と経験豊富な開発者の両方が学習できる人気のあるプログラミング言語です。このチュートリアルは基本的な概念から始まり、高度なトピックに進みます。 Java Development Kit をインストールしたら、簡単な「Hello, World!」プログラムを作成してプログラミングを練習できます。コードを理解したら、コマンド プロンプトを使用してプログラムをコンパイルして実行すると、コンソールに「Hello, World!」と出力されます。 Java の学習はプログラミングの旅の始まりであり、習熟が深まるにつれて、より複雑なアプリケーションを作成できるようになります。
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
 Java をシンプルに: プログラミング能力を高める初心者向けガイド
Oct 11, 2024 pm 06:30 PM
Java をシンプルに: プログラミング能力を高める初心者向けガイド
Oct 11, 2024 pm 06:30 PM
Java をシンプルに: プログラミング能力の初心者向けガイド はじめに Java は、モバイル アプリケーションからエンタープライズ レベルのシステムに至るまで、あらゆるもので使用される強力なプログラミング言語です。初心者にとって、Java の構文はシンプルで理解しやすいため、プログラミングの学習に最適です。基本構文 Java は、クラスベースのオブジェクト指向プログラミング パラダイムを使用します。クラスは、関連するデータと動作をまとめて編成するテンプレートです。簡単な Java クラスの例を次に示します。 publicclassperson{privateStringname;privateintage;
 javascriptの分解:それが何をするのか、なぜそれが重要なのか
Apr 09, 2025 am 12:07 AM
javascriptの分解:それが何をするのか、なぜそれが重要なのか
Apr 09, 2025 am 12:07 AM
JavaScriptは現代のWeb開発の基礎であり、その主な機能には、イベント駆動型のプログラミング、動的コンテンツ生成、非同期プログラミングが含まれます。 1)イベント駆動型プログラミングにより、Webページはユーザー操作に応じて動的に変更できます。 2)動的コンテンツ生成により、条件に応じてページコンテンツを調整できます。 3)非同期プログラミングにより、ユーザーインターフェイスがブロックされないようにします。 JavaScriptは、Webインタラクション、シングルページアプリケーション、サーバー側の開発で広く使用されており、ユーザーエクスペリエンスとクロスプラットフォーム開発の柔軟性を大幅に改善しています。
 スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックの下部に要素を挿入するJavaプログラム
Feb 07, 2025 am 11:59 AM
スタックは、LIFO(最後の、最初のアウト)の原則に従うデータ構造です。言い換えれば、スタックに最後に追加する要素は、削除される最初の要素です。要素をスタックに追加(またはプッシュ)すると、それらは上に配置されます。つまり、とりわけ
