

マルチスレッド プログラミングの非常に重要な機能は、タスクを実行する方法がたくさんある理由です。以下では、ソケットプログラミングの機能を使用してリクエストを処理し、タスクを実行する各メソッドを分析します。
1.1 タスクのシリアル実行
Socket はクライアントが接続していることを監視すると、handleSocket メソッドを通じて各クライアント接続を順番に処理し、処理が完了するとリッスンを続けます。コードは次のとおりです:
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
handleSocket(socket);
}このメソッドの欠点は非常に明らかです: 複数のクライアント リクエストがある場合、サーバーが 1 つのリクエストを処理している間、他のリクエストは前のリクエストが処理されるまで待機する必要があります。これは、同時実行性が高い状況ではほとんど利用できません。
1.2 タスクごとにスレッドを作成する
上記の問題を最適化します。 メイン スレッドは、スレッドを作成するだけで、その後、クライアント リクエストの処理を続行します。 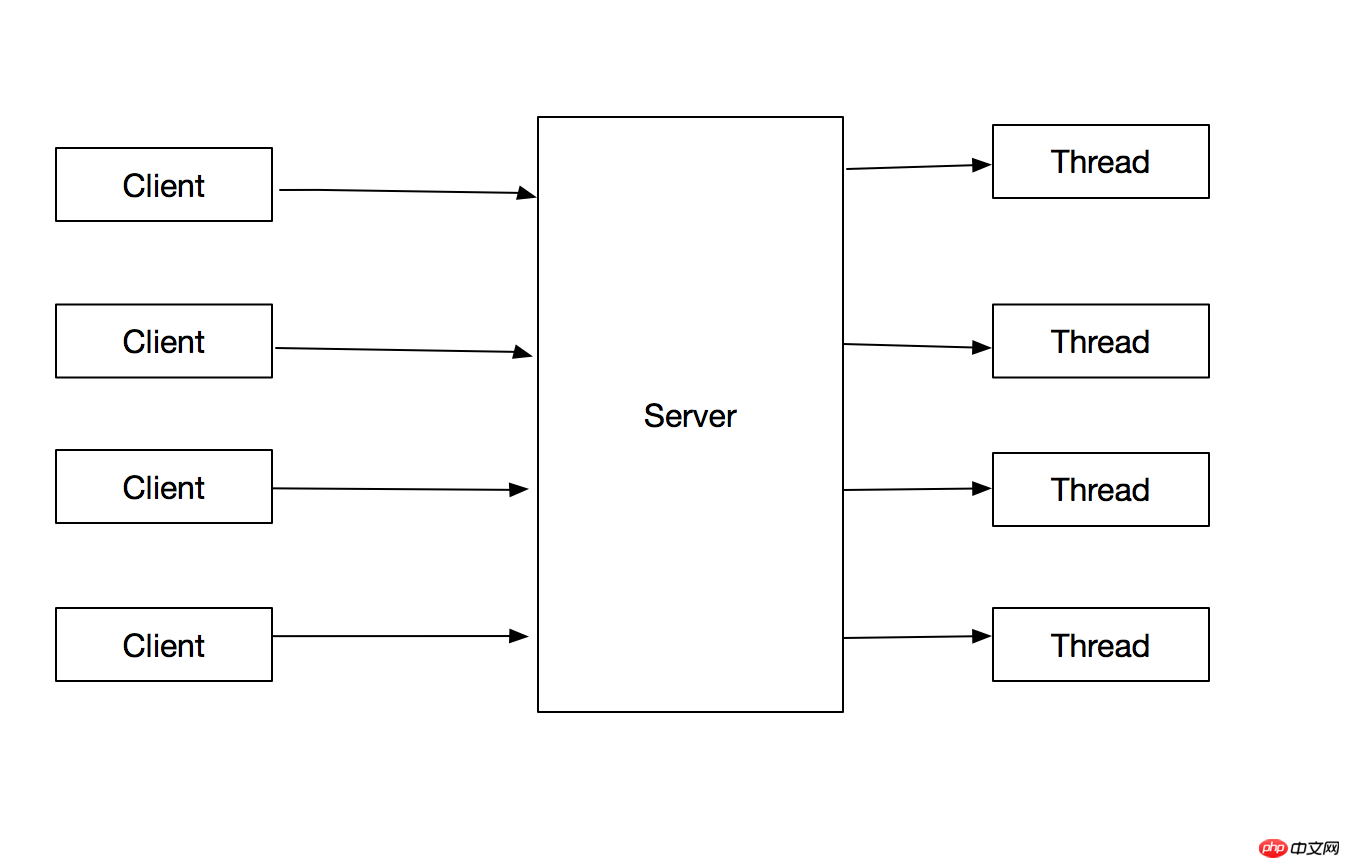
コードは次のとおりです:
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++).start();
}このメソッドには次の利点があります:
1.クライアント接続の処理操作をメインスレッドから分離するため、メインループは次のリクエストにより速く応答できます。 。
2. クライアント接続の処理操作は並列であるため、プログラムのスループットが向上します。
しかし、この方法には次のような欠点があります:
1. リクエストを処理するスレッドはスレッドセーフでなければなりません
2. スレッドの作成と破棄には大量のオーバーヘッドが必要です。コンピューターのリソースが消費されます
3. 使用可能な CPU の数が実行可能なスレッドの数よりも少ない場合、余分なスレッドがメモリ リソースを占有し、ガベージ コレクションに負荷がかかり、大量のスレッドが発生すると大きな影響を及ぼします。スレッドは CPU リソースを求めて競合します
4. JVM で作成できるスレッド数には上限があります。この上限はプラットフォームによって異なり、起動パラメータなどの複数の要因によって制限されます。 JVM、各スレッドが占有するメモリ サイズなど、これらの制限を超えると、OOM 例外がスローされます。
1.3 スレッド プールを使用してクライアント リクエストを処理する
1.2 の問題に対する最善の解決策は、スレッド プールを使用してタスクを実行することです。これにより、作成されるスレッドの総数を制限し、1.2 の問題を回避できます。フローチャートは次のとおりです: 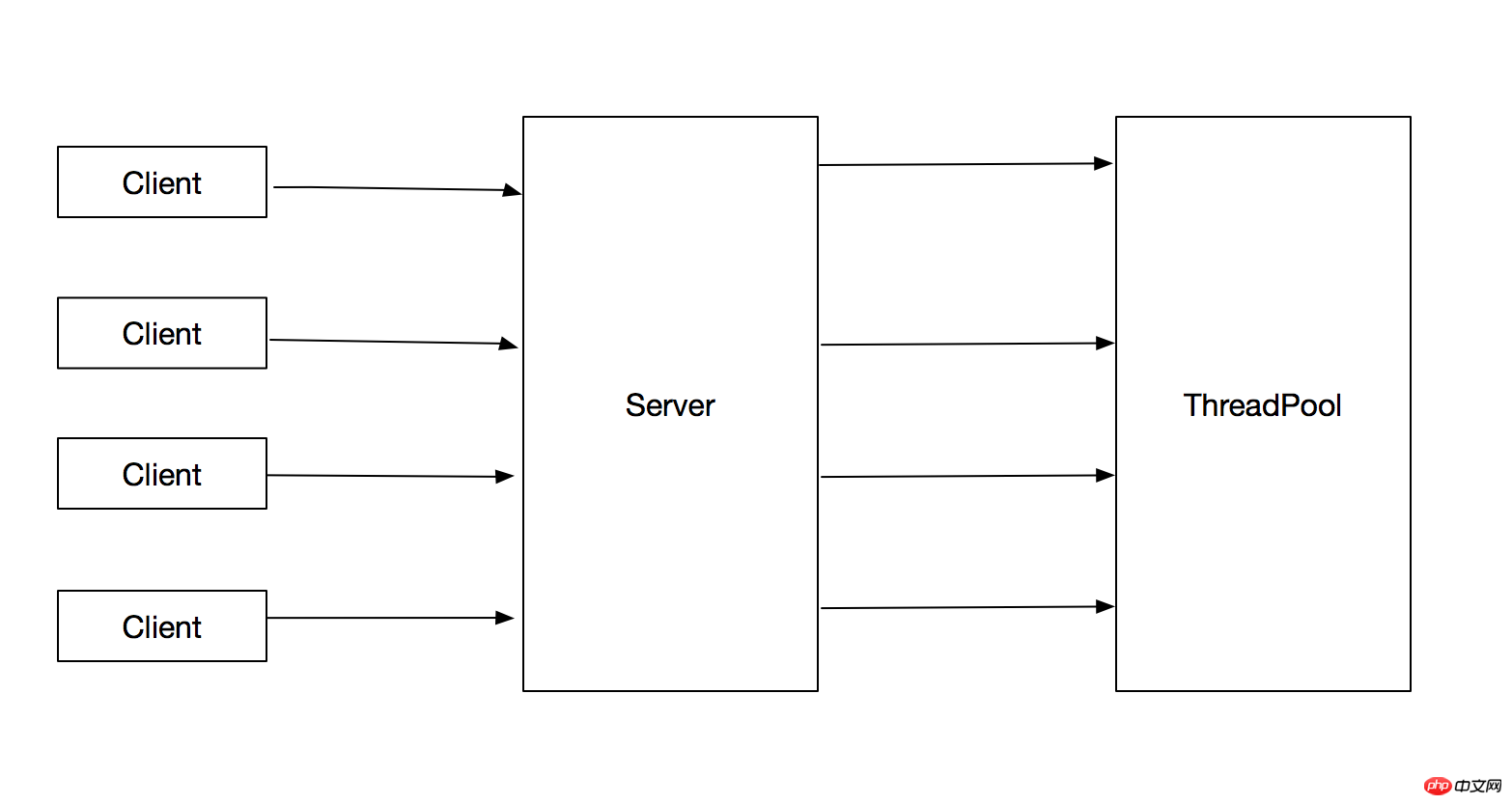
処理方法は次のとおりです:
ServerSocket serverSocket = new ServerSocket();
SocketAddress endpoint = new InetSocketAddress(host, port);
serverSocket.bind(endpoint,1023);
while (!isStop) {
Socket socket = serverSocket.accept();
executorService.execute(new SocketHandler(socket, THREAD_NAME_PREFIX + threadIndex++));
}この方法には次の利点があります:
1. タスクの送信とタスクの実行が分離されます
2. タスクを実行するスレッドは次のとおりです。再利用されるため、スレッドの作成と破棄のオーバーヘッドが削減されると同時に、タスクが到着したときに、作成されたスレッドを直接使用してタスクを実行できるため、プログラムの応答速度も向上します。
Java のスレッド プールの実装は、プロデューサー/コンシューマー モデルに基づいています。 スレッド プールの機能は、タスクの送信とタスクの実行のプロセスを分離します。はプロデューサー、タスクを実行するプロセスは消費プロセス です。具体的な分析については、「ソース コード分析」を参照してください。 Java スレッド プールのトップレベル インターフェイスは Executor です。ソース コードは次のとおりです:
public interface Executor {
void execute(Runnable command);
}このインターフェイスは、受け入れられるタスク タイプが Runnable 実装クラスであると規定しています。ただし、タスクの特定の実行ロジックはスレッド プールによって実装されます。例:
メイン スレッドを使用してタスクをシリアルに実行できます。
タスクごとに新しいスレッドを作成することもできます
または、事前にスレッドのセットを作成し、タスクが実行されるたびにスレッドのセットから描画するなど。
スレッド プールの実行戦略には主に次の側面が含まれます。
1.タスク
2. タスクを実行する順序 (FIFO、LIFO、優先度?)
3. はい 同時に実行できるタスクの数
4. キュー内で実行を待機できるタスクの最大数
5.待機キューが最大値に達した場合、新しく送信されたタスクを拒否する方法
6. タスクの実行前または実行後にどのような操作を行う必要がありますか?
特定のビジネスに応じて、異なる実行戦略を選択する必要があります。 Executors ツール クラスは、デフォルトの戦略スレッド プールを使用するために Java クラス ライブラリで提供されています。主に以下のインターフェースがあります:
public static ExecutorService newFixedThreadPool(int nThreads) 将会创建一个固定大小的线程池,每当有新任务提交的时候,当线程总数没有达到核心线程数的时候,为每个任务创建一个新线程,当线程的个数到达最大值后,重用之前创建的线程,当线程因为未知异常而停止时候,将会重现创建一个线程作为补充。 public static ExecutorService newCachedThreadPool() 根据需求创建线程的个数,当线程数大于任务数的时候,将会注销多余的线程 public static ExecutorService newSingleThreadExecutor() 创建一个单线程的线程池 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个可执行定时任务的线程池
上記の例では、スレッドプールにサブミットされた後は、サブミットされたすべてのタスクの実行ステータスが表示されません。つまり、メインスレッドは、サブミットされたタスクが実行を完了したか、実行が完了したかを知ることができません。結果。この問題に対処するために、Java はデータを返すことができるタスク インターフェイス Future インターフェイスと Callable インターフェイスを提供します。
Callable インターフェイスは、タスクからデータを返し、例外をスローする機能を提供し、次のように定義されます:
public interface Callable<V> {
V call() throws Exception;
}ExecutorService のすべての submit メソッドは Future オブジェクトを返し、そのインターフェイスは次のように定義されます:
public interface Future<V> {
取消任务执行,当mayInterruptIfRunning为true,interruptedthisthread
boolean cancel(boolean mayInterruptIfRunning);
返回此任务是否在执行完毕之前被取消执行
boolean isCancelled();
返回此任务是否已经完成,包括正常结束,异常结束以及被cancel
boolean isDone();
返回执行结果,当任务没有执行结束的时候,等待
V get() throws InterruptedException, ExecutionException;
}1.线程饥饿死锁
在单线程的Executor中,如果Executor中执行的一个任务中,再次提交任务到同一个Executor中,并且等待这个任务执行完毕,那么就会发生死锁问题。如下demo中所示:
public class ThreadDeadLock {
private static final ExecutorService EXECUTOR_SERVICE = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws Exception {
System.out.println("Main Thread start.");
EXECUTOR_SERVICE.submit(new DeadLockThread());
System.out.println("Main Thread finished.");
}
private static class DeadLockThread extends Thread{
@Override
public void run() {
try {
System.out.println("DeadLockThread start.");
Future future = EXECUTOR_SERVICE.submit(new DeadLockThread2());
future.get();
System.out.println("DeadLockThread finished.");
} catch (Exception e) {
}
}
}
private static class DeadLockThread2 extends Thread {
@Override
public void run() {
try {
System.out.println("DeadLockThread2 start.");
Thread.sleep(1000 * 10);
System.out.println("DeadLockThread2 finished.");
} catch (Exception e) {
}
}
}
}输出结果为:
Main Thread start. Main Thread finished. DeadLockThread start.
对于多个线程的线程池,如果所有正在执行的线程都因为等待处于工作队列中的任务执行而阻塞,那么就会发生线程饥饿死锁。
当往线程池中提交有依赖的任务时,应清楚的知道可能会出现的线程饥饿死锁风险。==应考虑是否将依赖的task提交到不同的线程池中==
或者使用无界的线程池。
==只有当任务相对独立时,设置线程池大小和工作队列的大小才是合理的,否则有可能会出现线程饥饿死锁==
2.任务运行时间过长
任务执行时间过长会影响线程池的响应时间,当运行时间长的任务远大于线程池线程的个数时,会出现所有线程都在执行运行时间长的任务,从而影响对其他任务的响应。
解决办法:
1.通过限定任务等待的时长,而不要无限期等待下去,当等待超时的时候,可以将任务标记为失败,或者重新放到线程池中。
2.当线程池中阻塞任务过多的时,应该考虑扩大线程池的大小
线程池的大小依赖于提交任务的类型以及服务器的可用资源,线程池的大小应该避免设置过大或者过小,当线程设置过打的时候可能会有资源耗尽的风险,线程池设置过小会有可用cpu空闲从而影响系统吞吐量。
影响线程池大小的资源有很多,比如CPU、内存、数据库链接池等,只需要计算资源可用总资源 / 每个任务需要的资源,取最小值,即可得出线程池的上限。
线程池的最小值应该大于可用的CPU数量。
ThreadPoolExecutor线程池是比较常用的一个线程池实现类,通过Executors工具类创建的线程池中,其具体实现类是ThreadPoolExecutor。首先我们可以看下ThreadPoolExecutor的构造函数如下:
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)下面分别对构造函数中的各个参数对应的策略进行分析:
1.线程的创建与销毁
首先构造函数中corePoolSize、maximumPoolSize、keepAliveTime和unit参数影响线程的创建和销毁。其中corePoolSize为核心线程数,当第一次提交任务的时候如果正在执行的线程数小于corePoolSize,则新建一个线程执行task,如果已经超过corePoolSize,则将任务放到任务队列中等待执行。当任务队列的个数到达上限的时候,并且工作线程数量小于maximumPoolSize,则继续创建线程执行工作队列中的任务。当任务的个数小于maximumPoolSize的时候,将会把空闲的线程标记为可回收的垃圾线程。对于以下代码段测试此功能:
public class ThreadPoolTest {
private static ThreadPoolExecutor executorService = new ThreadPoolExecutor(3, 6,100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3));
public static void main(String[] args) throws Exception {
for (int i = 0; i< 9; i++) {
executorService.submit(new Task());
System.out.println("Active thread:" + executorService.getActiveCount() + ".Task count:" + executorService.getTaskCount() + ".TaskQueue size:" + executorService.getQueue().size());
}
}
private static class Task extends Thread {
@Override
public void run() {
try {
Thread.sleep(1000 * 100);
} catch (Exception e) {
}
}
}
}输出结果为:
Active thread:1.Task count:1.TaskQueue size:0 Active thread:2.Task count:2.TaskQueue size:0 Active thread:3.Task count:3.TaskQueue size:0 Active thread:3.Task count:4.TaskQueue size:1 Active thread:3.Task count:5.TaskQueue size:2 Active thread:3.Task count:6.TaskQueue size:3 Active thread:4.Task count:7.TaskQueue size:3 Active thread:5.Task count:8.TaskQueue size:3 Active thread:6.Task count:9.TaskQueue size:3
2.任务队列
在ThreadPoolExecutor的构造函数中可以传入保存任务的队列,当新提交的任务没有空闲线程执行时候,会将task保存到此队列中。保存的顺序是根据插入的顺序或者Comparator来排序的。
3.饱和策略
ThreadPoolExecutor.AbortPolicy 抛出RejectedExecutionException ThreadPoolExecutor.CallerRunsPolicy 将任务的执行交给调用者,即将本该异步执行的任务变成同步执行。
4.线程工厂
当线程池需要创建线程的时候,默认是使用线程工厂方法来创建线程的,通常情况下我们通过指定线程工厂的方式来为线程命名,便于出现线程安全问题时候来定位问题。
1.项目中所有的线程应该都有线程池来提供,不允许自行创建线程
2.尽量不要用Executors来创建线程,而是使用ThreadPoolExecutor来创建
Executors有以下问题:
1)FixedThreadPool 和 SingleThreadPool: 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。 2)CachedThreadPool 和 ScheduledThreadPool: 允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
以上がJDK スレッド プールの分析と使用方法を理解するのに役立つ記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



