

デュアル システムのインストール中に関連する構成を実行する方法
この記事の内容は、デュアル システムのインストール中に関連する設定を実行する方法に関するものです。必要な方は参考にしていただければ幸いです。
この 1 週間の苦労を終えて、私自身の関連する設定体験を記録して皆さんと共有したいと思います。最初は VMware に Ubuntu と Centos をインストールしましたが、その後、ディープラーニングには GPU の助けが必要になり、CPU だけを使用すると非常に遅くなることがわかりました。たまたま、この期間中に、最初に仮想マシン上で Linux を学習し、その後、この期間中にデュアル システムをインストールすることに抵抗がなくなりました。
デュアル システムをインストールするステップ 1:
利用可能: ubuntu-16.04-desktop-amd64.iso システム イメージ、1 つの USB ディスク、書き込みシステムから U ディスクへのツール UltraISO、ブート ツールのセットアップ easyBCD
私の元の win10 システムは C ドライブ上の SSD で、Ubuntu 用に約 100g のスペースを空け、U ディスクを使用してインストールしましたUbuntu14.04 をインストールしましたが、インストール後にワイヤレス ドライバーも wlan0 もなく、更新する必要があるのはクライアントです。 wine のインストール時に別の問題が発生したため、クラスメートが最新の Ubuntu 16.04 をインストールしましたが、最終的には問題なくインストールが完了しました。

#1. もちろん、インストール プロセス中のこの手順は状況によって異なります。通常、ネットワークに接続していない場合は、選択する必要はありません。サードパーティ製ソフトウェアをインストールするには、クリックして続行してください。

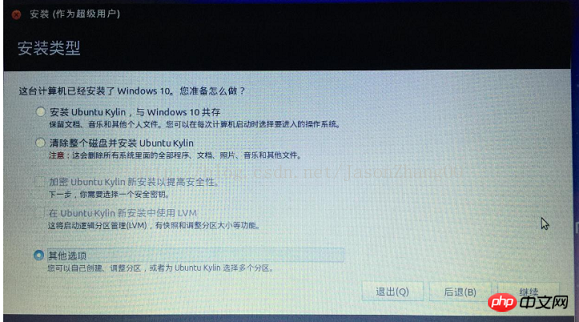
2. この手順は非常に重要です。元の Windows システムを紛失した場合は、必ず他のオプションをクリックしてください。 . 最初のものを選択しただけですよね?
3.ドライブ文字を割り当てるときは、空きディスクディスクを選択し、
最初に、新しいパーティションのタイプ: 論理パーティション
新しいパーティションの場所を設定します。 : スペースの開始位置、
は次の目的で使用されます。スワップ スペースは、インターネット上の物理メモリの 2 倍であると考えられています。実際には、2 g で十分です。ブート パーティションを設定します。 サイズ: 200MB (作成者は一時的に 200MB に設定します)
新しいパーティションの種類: 論理パーティション
の場所新しいパーティション: スペースの開始位置
使用対象: EXT4 ログ ファイル システム
「/」ルート パーティションを設定します。多くのデフォルト システム アプリケーションが後でここにインストールされます
サイズ:できるだけ大きい
新しいパーティションの種類: プライマリ パーティション
新しいパーティションの場所: スペースの開始位置
使用用途: EXT4 ログ ファイル システム
/home パーティションを設定します。これは、独自のものを保存するのと同じで、win d、e、f ディスクのパーティションに似ています。
サイズ: (表示されているすべての残りのスペース)
新しいパーティションの種類: 論理パーティション
新しいパーティションの場所: スペース開始位置
使用用途: EXT4 ログ ファイル システム
覚えておくことが重要です
を選択して /boot対応するドライブ文字は "ブートローダーをインストールするデバイスです"、一貫性を保つようにしてください: 4。インストール プロセスの最初と最後に注意してください。1 つは、次のことを忘れないことです。高度な起動でセキュア ブートをオフにしました。その後、コンピュータを直接再起動し、BIOS を入力してオフにしました (いずれにせよ、これは真実です)。コンピューターの電源を入れるたびに、win10 システムに直接アクセスします。ヒント: easybcd と UltraISO の新しいバージョンを選択することをお勧めします。インターネットで直接検索すると、古いバージョンのものもあり、問題が発生する可能性があります。
以上がデュアル システムのインストール中に関連する構成を実行する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7471
7471
 15
1377
52
77
11
19
30
15
1377
52
77
11
19
30

 この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
この記事では、SHAP: 機械学習のモデルの説明について説明します。
Jun 01, 2024 am 10:58 AM
機械学習とデータ サイエンスの分野では、モデルの解釈可能性が常に研究者や実務家に焦点を当ててきました。深層学習やアンサンブル手法などの複雑なモデルが広く適用されるようになったことで、モデルの意思決定プロセスを理解することが特に重要になってきました。 Explainable AI|XAI は、モデルの透明性を高めることで、機械学習モデルに対する信頼と自信を構築するのに役立ちます。モデルの透明性の向上は、複数の複雑なモデルの普及や、モデルを説明するための意思決定プロセスなどの方法によって実現できます。これらの方法には、特徴重要度分析、モデル予測間隔推定、ローカル解釈可能性アルゴリズムなどが含まれます。特徴重要度分析では、入力特徴に対するモデルの影響度を評価することで、モデルの意思決定プロセスを説明できます。モデルの予測間隔の推定
 ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
ORB-SLAM3を超えて! SL-SLAM: 低照度、重度のジッター、弱いテクスチャのシーンはすべて処理されます。
May 30, 2024 am 09:35 AM
以前に書きましたが、今日は、深層学習テクノロジーが複雑な環境におけるビジョンベースの SLAM (同時ローカリゼーションとマッピング) のパフォーマンスをどのように向上させることができるかについて説明します。ここでは、深部特徴抽出と深度マッチング手法を組み合わせることで、低照度条件、動的照明、テクスチャの弱い領域、激しいセックスなどの困難なシナリオでの適応を改善するように設計された多用途のハイブリッド ビジュアル SLAM システムを紹介します。当社のシステムは、拡張単眼、ステレオ、単眼慣性、ステレオ慣性構成を含む複数のモードをサポートしています。さらに、他の研究にインスピレーションを与えるために、ビジュアル SLAM と深層学習手法を組み合わせる方法も分析します。公開データセットと自己サンプリングデータに関する広範な実験を通じて、測位精度と追跡堅牢性の点で SL-SLAM の優位性を実証しました。
 学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
学習曲線を通じて過学習と過小学習を特定する
Apr 29, 2024 pm 06:50 PM
この記事では、学習曲線を通じて機械学習モデルの過学習と過小学習を効果的に特定する方法を紹介します。過小適合と過適合 1. 過適合 モデルがデータからノイズを学習するためにデータ上で過学習されている場合、そのモデルは過適合していると言われます。過学習モデルはすべての例を完璧に学習するため、未確認の新しい例を誤って分類してしまいます。過適合モデルの場合、完璧/ほぼ完璧なトレーニング セット スコアとひどい検証セット/テスト スコアが得られます。若干修正: 「過学習の原因: 複雑なモデルを使用して単純な問題を解決し、データからノイズを抽出します。トレーニング セットとしての小さなデータ セットはすべてのデータを正しく表現できない可能性があるため、2. 過学習の Heru。」
 宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
宇宙探査と人類居住工学における人工知能の進化
Apr 29, 2024 pm 03:25 PM
1950 年代に人工知能 (AI) が誕生しました。そのとき、研究者たちは、機械が思考などの人間と同じようなタスクを実行できることを発見しました。その後、1960 年代に米国国防総省は人工知能に資金を提供し、さらなる開発のために研究所を設立しました。研究者たちは、宇宙探査や極限環境での生存など、多くの分野で人工知能の応用を見出しています。宇宙探査は、地球を超えた宇宙全体を対象とする宇宙の研究です。宇宙は地球とは条件が異なるため、極限環境に分類されます。宇宙で生き残るためには、多くの要素を考慮し、予防策を講じる必要があります。科学者や研究者は、宇宙を探索し、あらゆるものの現状を理解することが、宇宙の仕組みを理解し、潜在的な環境危機に備えるのに役立つと信じています。
 C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ での機械学習アルゴリズムの実装: 一般的な課題と解決策
Jun 03, 2024 pm 01:25 PM
C++ の機械学習アルゴリズムが直面する一般的な課題には、メモリ管理、マルチスレッド、パフォーマンスの最適化、保守性などがあります。解決策には、スマート ポインター、最新のスレッド ライブラリ、SIMD 命令、サードパーティ ライブラリの使用、コーディング スタイル ガイドラインの遵守、自動化ツールの使用が含まれます。実践的な事例では、Eigen ライブラリを使用して線形回帰アルゴリズムを実装し、メモリを効果的に管理し、高性能の行列演算を使用する方法を示します。
 説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
説明可能な AI: 複雑な AI/ML モデルの説明
Jun 03, 2024 pm 10:08 PM
翻訳者 | Li Rui によるレビュー | 今日、人工知能 (AI) および機械学習 (ML) モデルはますます複雑になっており、これらのモデルによって生成される出力はブラックボックスになっており、関係者に説明することができません。 Explainable AI (XAI) は、利害関係者がこれらのモデルがどのように機能するかを理解できるようにし、これらのモデルが実際に意思決定を行う方法を確実に理解できるようにし、AI システムの透明性、信頼性、およびこの問題を解決するための説明責任を確保することで、この問題を解決することを目指しています。この記事では、さまざまな説明可能な人工知能 (XAI) 手法を検討して、その基礎となる原理を説明します。説明可能な AI が重要であるいくつかの理由 信頼と透明性: AI システムが広く受け入れられ、信頼されるためには、ユーザーは意思決定がどのように行われるかを理解する必要があります
 あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
あなたが知らない機械学習の 5 つの流派
Jun 05, 2024 pm 08:51 PM
機械学習は人工知能の重要な分野であり、明示的にプログラムしなくてもコンピューターにデータから学習して能力を向上させる機能を提供します。機械学習は、画像認識や自然言語処理から、レコメンデーションシステムや不正行為検出に至るまで、さまざまな分野で幅広く応用されており、私たちの生活様式を変えつつあります。機械学習の分野にはさまざまな手法や理論があり、その中で最も影響力のある 5 つの手法は「機械学習の 5 つの流派」と呼ばれています。 5 つの主要な学派は、象徴学派、コネクショニスト学派、進化学派、ベイジアン学派、およびアナロジー学派です。 1. 象徴主義は、象徴主義とも呼ばれ、論理的推論と知識の表現のためのシンボルの使用を強調します。この学派は、学習は既存の既存の要素を介した逆演繹のプロセスであると信じています。
 フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
フラッシュ アテンションは安定していますか?メタとハーバードは、モデルの重みの偏差が桁違いに変動していることを発見しました
May 30, 2024 pm 01:24 PM
MetaFAIR はハーバード大学と協力して、大規模な機械学習の実行時に生成されるデータの偏りを最適化するための新しい研究フレームワークを提供しました。大規模な言語モデルのトレーニングには数か月かかることが多く、数百、さらには数千の GPU を使用することが知られています。 LLaMA270B モデルを例にとると、そのトレーニングには合計 1,720,320 GPU 時間が必要です。大規模なモデルのトレーニングには、これらのワークロードの規模と複雑さにより、特有のシステム上の課題が生じます。最近、多くの機関が、SOTA 生成 AI モデルをトレーニングする際のトレーニング プロセスの不安定性を報告しています。これらは通常、損失スパイクの形で現れます。たとえば、Google の PaLM モデルでは、トレーニング プロセス中に最大 20 回の損失スパイクが発生しました。数値的なバイアスがこのトレーニングの不正確さの根本原因です。
