

20 mysqlの最適化まとめ

この記事の内容は、mysql の最適化に関する概要です。必要な方は参考にしていただければ幸いです。
まえがき
現在、特に Web アプリケーションでは、データベース操作がアプリケーション全体のパフォーマンスのボトルネックになっています。したがって、MySQL の最適化に関するいくつかの提案をまとめました。まとめられない場合は、ぜひ追加してください。
SQL 実行が遅い理由
ネットワーク速度の遅さ、メモリ不足、I/O スループットの低下、ディスク容量の不足、その他のハードウェアの問題
インデックスなしまたはインデックスの失敗
##データ テーブル内のデータ レコードが多すぎます- ##サーバーのチューニングとさまざまなパラメーターの設定
その他
EXPLAIN によって記述された SQL の効率にも影響する可能性があります。 SELECT クエリを分析する
多くの場合、EXPLAIN キーワードを使用すると、MySQL が SQL ステートメントをどのように処理するかを知ることができ、クエリ ステートメントの分析に役立ち、最適化をすぐに見つけることができる可能性があります。可能性のある方法と潜在的なパフォーマンスの問題。 EXPLAIN の具体的な使用方法と各パラメータの意味については、関連ドキュメントを参照してください。
2. SELECT クエリではフィールド名を指定する必要があります。
SELECT * クエリでは、同時に多くの不要な消費が発生します (CPU、I/O など)。 、カバリングインデックスの使用も増加する可能性があります。したがって、SELECTクエリを実行する場合は、最後にクエリ対象となる対応するフィールド名を直接指定する必要があります。
3. データの一部をクエリするときは、LIMIT 1
を使用して冗長なクエリを減らします。これは、制限 1 を指定すると、データの一部をクエリした後にクエリが続行されなくなり、 EXPLAIN の type 列 const 型に到達するには、クエリ ステートメントの方が適しています。
4. 検索された WHERE フィールドのインデックスを作成します
通常、テーブルごとに主キーを設定しますが、インデックスは必ずしも主キーである必要はありません。テーブル内に WHERE クエリと検索に常に使用するフィールドがあり、書き込みよりも読み取りの方が多い場合は、そのフィールドのインデックスを作成してください。インデックス作成の原則について詳しく知りたい場合は、「関連情報」を参照してください。見つけられた。
5. ORDER BY RAND() は絶対に使用しないでください。
データをランダムに取得したい場合は、最初のメソッドで乱数を使用するように直接指示されるかもしれません。この時点では Control を使用する必要があることを覚えておいてください。あなたの脳がこの方向に思考を続け、この恐ろしい考えを止めます。この種のクエリはデータベースのパフォーマンスに何のメリットもない (CPU を消費する) ためです。より良い解決策の 1 つは、最初にデータの数 N を見つけてから、
LIMIT N, 1を使用してこのようにクエリを実行することです。
6. 各テーブルに主キー ID があることを確認する新しいテーブルを作成するたびに、そのテーブルの ID フィールドを設計し、それを主キー、できれば INT タイプ (UUID を使用するものもあります) で、ID フィールドを AUTO_INCREMENT フラグに設定します。
8. できる限り NOT NULL を使用します。
NULL にはスペースが必要ないと考えないでください。おそらく、多くの人は気づいていませんが、NULL にも余分なスペースが必要です。 NULL フィールドが存在する場合、クエリと比較を行うとさらに面倒になります。もちろん、本当に NULL が必要な場合は問題なく使用できます。それ以外の場合は、NOT NULL を使用することをお勧めします。
8. 適切なストレージ エンジンを選択する
MySQL には MyISAM と InnoDB という 2 つのストレージ エンジンがあり、どちらにも独自の長所と短所があるため、2 つの違いを理解する必要があります。適切な選択を行ってください。たとえば、InnoDB はトランザクションをサポートしますが、MyISAM はサポートしません。MyISAM クエリは InnoDB よりも高速です。つまり、何を選択すればよいかわからない場合は、InnoDB を使用してください。
9. IP アドレスを UNSIGNED INT として保存する
IP アドレスを保存する必要がある場合、多くの人は最初に VARCHAR (15) 文字列タイプを保存することを考えるでしょう。 INT 整数型を使用して格納することは考えられません。整数型を使用して格納すれば、必要なバイト数は 4 バイトだけであり、固定長フィールドを使用できるため、クエリに利点が得られます。
10. WHERE クエリ中にフィールドの null 値を判断しないようにしてください
フィールドを null と判断すると、これが原因で速度が低下することは誰もが知っています。この判断により、エンジンは既存のすべてのインデックスの使用を放棄し、フル テーブル スキャン検索を実行します。
11. % プレフィックス付きの LIKE ファジー クエリは使用しないようにしてください。
ファジー クエリは日常の開発で頻繁に遭遇しますが、多くの人は直接
LIKE ' %key_word%' を使用すると思います。または
LIKE '%key_word' はこのように検索されます。これらの 2 つの検索方法ではインデックスが失敗し、フル テーブル スキャン検索が必要になります。上記のあいまいなクエリを解決したい場合、答えは「全文インデックスを使用する」です。具体的な使用方法に興味がある場合は、自分で情報を確認してください。 12. WHERE クエリ中にフィールドに対して式操作を実行しないでください。たとえば、クエリ ステートメント
などのクエリです。フィールド num に 2 を掛ける算術演算を実行すると、インデックスが失敗します。
14. 不必要なソートを減らす
ソート操作はより多くの CPU リソースを消費するため、キャッシュ ヒット率が高く、I/O 時間が十分である場合、不必要なソートを減らすと SQL パフォーマンスが低下する可能性があります。
14. サブクエリの代わりに JOIN を使用することをお勧めします。
JOIN のパフォーマンスはそれほど良くないという人もいますが、それでもサブクエリと比較するとパフォーマンスに大きな利点があります。具体的には、サブクエリの実行計画に関連する問題について学ぶことができます。
15. 暗黙的な型変換を避ける
型変換とは、主に、WHERE 句のフィールドの型が、渡されるパラメータの型と一致しない場合に発生する型変換を指します。渡したデータ型がフィールド型と一致しない場合、MySQL は渡したデータに対して型変換操作を実行するか、データを処理せずにストレージ エンジンに直接渡して処理する可能性があるためです。使用状況によっては、実行計画の問題が発生する可能性があります。
16. 複数テーブルのクエリで一貫性のないフィールド タイプを回避する
複数テーブルの結合クエリが必要になった場合は、テーブル構造を設計するときに、そのクエリに関連付けられたフィールドを維持するようにしてください。テーブルはテーブルと一致しており、インデックスを設定する必要があります。同時に、複数テーブル接続クエリを実行する場合は、結果セットが小さいテーブルを駆動テーブルとして使用するようにしてください。
17. クエリ キャッシュをオンにすることをお勧めします。
ほとんどの MySQL サーバーではクエリ キャッシュがオンになっているため、これはパフォーマンスを向上させる最も効果的な方法の 1 つです。同じクエリの多くが複数回実行されると、これらのクエリ結果はキャッシュに保存されるため、後続の同一のクエリはテーブルを操作する必要がなく、キャッシュされた結果に直接アクセスします。
18. 一時テーブルの代わりに UNION を使用する
UNION クエリは 2 つ以上の SELECT クエリの結果を 1 つのクエリにマージできるため、完了のために一時テーブルを作成する必要はありません。 UNION を使用するすべての SELECT ステートメント内のフィールドの数は同じである必要があることに注意してください。
19. IN クエリは注意して使用してください
IN クエリと NOT IN クエリはテーブル全体のスキャンにつながる可能性があるため、使用できる場合は使用しないでください。間。
20. 追加へようこそ。
結論
これは、主にクエリ、一部のサブテーブル、パーティション テクノロジ、および読み取り/書き込みの観点から最適化を検討するためのものです。分離; 上記の最適化 上記の点が適切でない場合は、MySQL を最適化できる箇所がたくさんあることをご理解ください。
以上が20 mysqlの最適化まとめの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7677
7677
 15
1393
52
1207
24
91
11
15
1393
52
1207
24
91
11

 Java での Synchronized の原理と使用シナリオ、および Callable インターフェイスの使用法と差異分析
Apr 21, 2023 am 08:04 AM
Java での Synchronized の原理と使用シナリオ、および Callable インターフェイスの使用法と差異分析
Apr 21, 2023 am 08:04 AM
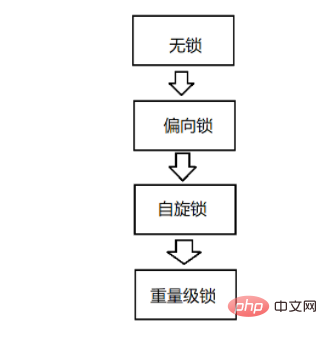
1. 基本機能 1. 楽観的ロックで開始し、ロック競合が多発する場合は悲観的ロックに変換する 2. 軽量なロック実装で開始し、長時間ロックを保持するとロックを解除する3. 軽量ロックを実装するときに最もよく使用されるスピン ロック戦略 4. 不公平なロックである 5. リエントラント ロックである 6. 読み取り/書き込みロックではない 2. JVMロック プロセスを同期します。 ロックは、ロックなし、バイアスされたロック、軽量ロック、および重量ロックの状態に分類されます。状況に応じて順次バージョンアップしていきます。偏ったロックは男主人公を鍵、女主人公をスレとするもので、このスレッドだけがこのロックを使用すれば、たとえ結婚証明書を取得しなくても男主人公と女主人公は永遠に幸せに暮らせる(高額回避) -コストオペレーション)しかし、女性のサポート役が登場します
 Javaキーワード同期原理とロック状態の分析例
May 11, 2023 pm 03:25 PM
Javaキーワード同期原理とロック状態の分析例
May 11, 2023 pm 03:25 PM
1. Java におけるロックの概念 Spin ロック: スレッドがロックを取得するとき、そのロックが別のスレッドによって取得されている場合、スレッドはループで待機し、ロックが正常に取得できるかどうかを判断し続けます。ロックが取得されると、ロックはループを終了します。楽観的ロック: 競合がないことを前提として、データを変更する際に以前に取得したデータと不整合が見つかった場合、最新のデータを読み込み、変更を再試行します。悲観的ロック: 同時実行性の競合が発生することを想定し、すべてのデータ関連操作を同期し、データが読み取られた時点からロックを開始します。排他的ロック (書き込み): リソースに書き込みロックを追加します。スレッドはリソースを変更できますが、他のスレッドはリソースを再度ロックすることはできません (単一書き込み)。共有ロック (読み取り): リソースに読み取りロックを追加した後、読み取りのみ可能ですが変更はできません。他のスレッドは読み取りロックのみを追加でき、書き込みロック (複数) を追加できません。 S として参照
 synchronized を使用して Java で同期メカニズムを実装するにはどうすればよいですか?
Apr 22, 2023 pm 02:46 PM
synchronized を使用して Java で同期メカニズムを実装するにはどうすればよいですか?
Apr 22, 2023 pm 02:46 PM
Java 1 での synchronized の使い方のまとめ。関数修飾子として synchronized を使用した場合のサンプルコードは次のようになります: Publicsynchronizedvoidmethod(){//….} これが同期メソッドですが、このときどのオブジェクトが同期ロックされているのでしょうか?彼がロックするのは、この同期されたメソッド オブジェクトを呼び出すことです。言い換えれば、オブジェクト P1 がこの同期メソッドを異なるスレッドで実行すると、同期効果を達成するために相互排他が形成されます。ただし、このオブジェクトが属するクラスが生成する別のオブジェクトP2は、synchronizedキーワードを付加してこのメソッドを任意に呼び出すことができる。上記のサンプルコードなど。
 Java の 3 つの同期方法とその使用方法は何ですか?
Apr 27, 2023 am 09:34 AM
Java の 3 つの同期方法とその使用方法は何ですか?
Apr 27, 2023 am 09:34 AM
1. 同期は最も一般的に使用される同期方法であり、これには主に 3 つの使用方法があることを説明します。 2. 例//一般的なクラス メソッドの同期 synchronizedpublidvoidinvoke(){}//クラスの静的メソッドの同期 synchronizedpublicstaticvoidinvoke(){}//コード ブロックの同期 synchronized(object){}これら 3 つのメソッドの違いは、同期されるオブジェクトが異なることです。通常のクラスはオブジェクト自体を同期し、静的メソッドはクラス自体を同期し、コード ブロックは括弧内のオブジェクトを同期します。 Javaにはどのようなコレクションがありますか?
 Java 同期ロックのアップグレードの原理とプロセスは何ですか?
Apr 19, 2023 pm 10:22 PM
Java 同期ロックのアップグレードの原理とプロセスは何ですか?
Apr 19, 2023 pm 10:22 PM
ツールの準備 同期の原理について正式に説明する前に、まずスピン ロックについて話しましょう。スピン ロックは同期の最適化に大きな役割を果たすためです。スピン ロックを理解するには、まずアトミック性とは何かを理解する必要があります。いわゆるアトミック性とは、単に各操作が行われないか完了することを意味します。すべてを行うということは、操作中に中断できないことを意味します。たとえば、変数データに 1 を追加するには、次の 3 つのステップがあります: メモリからレジスタにロードする。データの値に 1 を加算します。結果をメモリに書き込みます。原子性とは、スレッドがインクリメント操作を実行しているときに、他のスレッドによって中断できないことを意味し、このスレッドがこれら 3 つのプロセスを完了した場合にのみ実行されます。
 Java では、synchronized キーワードを使用するだけでなく、Lock を提供する必要があるのはなぜですか?
Apr 20, 2023 pm 05:01 PM
Java では、synchronized キーワードを使用するだけでなく、Lock を提供する必要があるのはなぜですか?
Apr 20, 2023 pm 05:01 PM
概要: synchronized キーワードは、1 つのスレッドのみが同期されたコード ブロックにアクセスできるようにするために Java で提供されています。 synchronized キーワードが提供されているのに、なぜ Lock インターフェースも Java SDK パッケージで提供されるのですか?これは不必要な車輪の再発明でしょうか?今日はこの問題について一緒に話し合います。 Java では synchronized キーワードが提供され、1 つのスレッドのみが同期されたコード ブロックにアクセスできるようにします。 synchronized キーワードが提供されているのに、なぜ Lock インターフェースも Java SDK パッケージで提供されるのですか?これは不必要な車輪の再発明でしょうか?今日は一緒にそれについて話し合いましょう
 Java同期とは
May 14, 2023 am 08:28 AM
Java同期とは
May 14, 2023 am 08:28 AM
Synchronized とは何ですか? Java 読者は synchronized キーワードに馴染みがありません。これはさまざまなミドルウェア ソース コードや JDK ソース コードで見ることができます。synchronized に詳しくない読者にとっては、synchronized キーワードは複数の言語で使用する必要があることだけを知っています。 -threading.synchronized によりスレッドの安全性を確保できます。これは、ミューテックス ロック (同時に 1 つのスレッドだけが実行でき、他のスレッドは待機します)、または悲観的ロック (同時に 1 つのスレッドだけが実行でき、他のスレッドは待機します) と呼ばれます。JVM 仮想マシンは、開発者は synchronized キーワードを使用するだけで済みます。使用する場合は、ロックのミューテックスとしてオブジェクトを使用する必要があります
 Java にはアクセス以外の修飾子がいくつありますか?
Aug 30, 2023 pm 06:01 PM
Java にはアクセス以外の修飾子がいくつありますか?
Aug 30, 2023 pm 06:01 PM
Java には、可視性を超えた機能を提供する他の修飾子がいくつか用意されています。これらの修飾子は非アクセス修飾子と呼ばれ、静的として宣言された静的メンバーはクラスのすべてのインスタンスに共通です。静的メンバーは、クラス メモリに格納されるクラス レベルのメンバーです。 Final この修飾子は、変数、メソッド、またはクラスへのさらなる変更を制限するために使用されます。 Final として宣言された変数の値は、その値を取得した後は変更できません。 Final メソッドをサブクラスでオーバーライドしたり、Final クラスのサブクラスを作成したりすることはできません。 Abstract この修飾子はクラスまたはメソッドで使用できます。この修飾子を変数やコンストラクターに適用することはできません。抽象として宣言されたメソッドはサブクラスで変更する必要があります。抽象宣言されたクラスをインスタンス化することはできません。同期 この修飾子は、複数のスレッドを制御するために使用されます。
