

分散システムコアログの詳細紹介(画像とテキスト)

この記事では、分散システムのコア ログについて詳しく説明します (写真とテキスト)。必要な方は参考にしてください。
ログとは何ですか?
ログは、時系列に追加された完全に順序付けられた一連のレコードです。実際、このファイルは次のようなものです。ワードセクション配列であり、ここでのログはレコードデータですが、ファイルに比べて、ここでの各レコードは相対的な時間順に配置されており、最も単純な保存モデルと言え、一般的には読み取りが可能です。 from メッセージ キューなど、ログ ファイルは通常、左から右に線形に書き込まれ、コンシューマはオフセットから開始して順番に読み取ります。
ログ自体の固有の特性により、レコードは左から右に順番に挿入されます。これは、左側のレコードが右側のレコードよりも「古い」ことを意味します。システムクロックに依存する必要があるため、この機能は分散システムにとって非常に重要です。
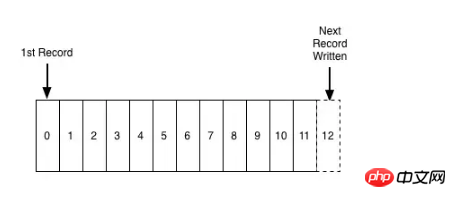
#ログの適用
データベースへのログの適用
ログはいつ現れるか分かりません。コンセプトが単純すぎるのかもしれません。データベース分野では、MySQL の REDO ログなど、システムがクラッシュしたときにデータとインデックスを同期するためにログがよく使用されます。REDO ログは、システムがハングしたときにデータの正確性と完全性を保証するために使用されます。たとえば、物事の実行中に、REDO ログが最初に書き込まれ、その後、システムがクラッシュ後に回復するときに実際の変更が適用されます。 REDO ログに基づいて再作成されます。元に戻してデータを復元します (初期化プロセス中、この時点ではクライアント接続はありません)。ログは、データベースのマスターとスレーブ間の同期にも使用できます。基本的に、データベースのすべての操作記録がログに書き込まれているため、ログをスレーブに同期し、それをスレーブで再生するだけでマスターを実現できます。 -スレーブ同期。REDO ログをサブスクライブすることで、データベース内のすべての変更を取得でき、監査やキャッシュ同期などのパーソナライズされたビジネス ロジックを実装できます。分散システムにおけるログのアプリケーション
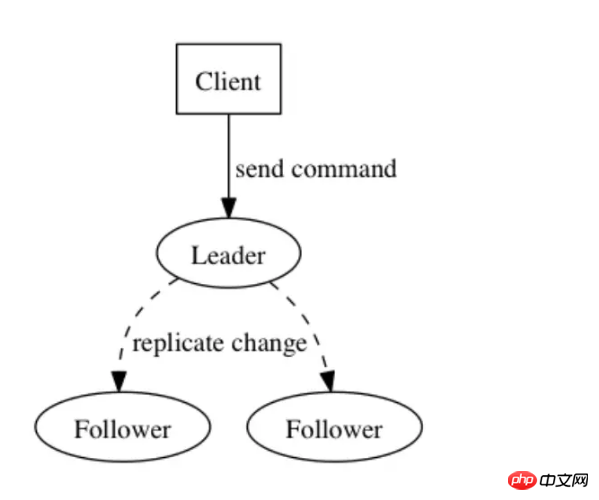
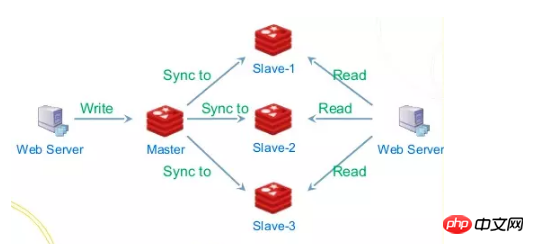
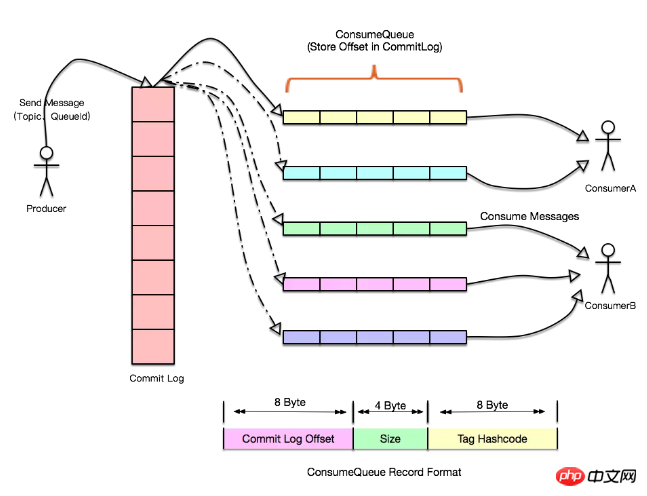
データベースの QPS は確実であり、上位層のアプリケーションは一般に水平方向に拡張できることがわかっています。この時点で、ダブル 11 のような突然のリクエスト シナリオが発生してデータベースが圧倒される場合、メッセージを導入できます。キューを作成し、各チームのデータベースを追加します。操作はログに書き込まれ、別のアプリケーションがこれらのログ レコードを使用してデータベースに適用する役割を果たします。データベースがハングした場合でも、回復時に最後のメッセージの位置から処理を続行できます。 (RocketMQ と Kafka はどちらも Exactly Once セマンティクスをサポートしています)、ここでは、プロデューサーの速度がコンシューマーの速度と異なっていても、ログはここにバッファーの役割を果たします。ログの書き込みがマスター ノードによって処理されるため、メッセージのバックログ容量が大幅に向上します。1 つは末尾読み取りであり、消費量が少なくなります。 1 つの種類の読み取りはキャッシュに直接送信でき、もう 1 つの種類の読み取りは書き込みリクエストに遅れてスレーブ ノードから読み取ることができるため、IO 分離とページキャッシュ、キャッシュ事前読み取りなど、オペレーティング システムに付属する一部のファイル ポリシーを使用すると、パフォーマンスが大幅に向上する可能性があります。
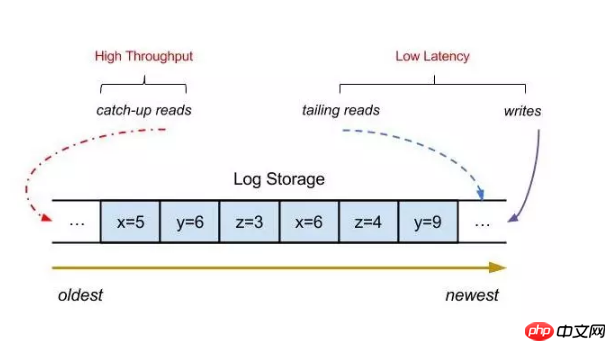
# 水平方向のスケーラビリティは、分散システムにおいて非常に重要な機能です。マシンを追加することで解決できる問題は問題ではありません。では、水平拡張を実現できるメッセージ キューを実装するにはどうすればよいでしょうか? スタンドアロンのメッセージ キューがある場合、トピックの数が増加するにつれて、IO、CPU、帯域幅などが徐々にボトルネックになり、パフォーマンスが徐々に低下します。パフォーマンスの最適化についてはどうすればよいでしょうか?
1.topic/log sharding 本質的に、トピックによって書き込まれるメッセージはログ レコードになります。書き込みの数が増えると、徐々にボトルネックになります。現時点では、1 つのトピックを複数のサブトピックに分割し、各トピックを別のマシンに割り当てることができます。このようにして、大量のメッセージを含むトピックはマシンを追加することで解決できますが、メッセージの量が少ないトピックもあります。マシンを追加することで解決できます。同じマシンに割り当てることも、分割しないこともできます。たとえば、Kafka のプロデューサー クライアントは、メッセージを書き込むときに、最初にローカル メモリ キューに書き込みます。次に、各パーティションとノードに従ってメッセージを書き込み、バッチで送信します。サーバー側またはブローカー側では、このメソッドを使用して最初にページキャッシュに書き込み、その後ディスクを定期的にフラッシュすることもできます。たとえば、金融サービスではディスクをブラッシングする方法が使用されます。
3. 無駄なデータのコピーを避ける
4.IO 分離
##結論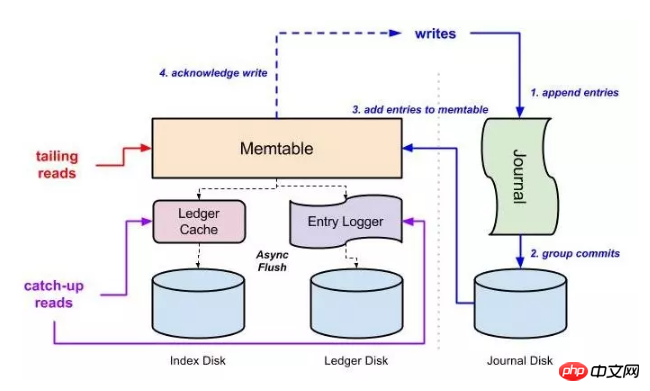
以上が分散システムコアログの詳細紹介(画像とテキスト)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7474
7474
 15
1377
52
77
11
19
31
15
1377
52
77
11
19
31

 win10のイベントID 6013とは何ですか?
Jan 09, 2024 am 10:09 AM
win10のイベントID 6013とは何ですか?
Jan 09, 2024 am 10:09 AM
win10 のログは、ユーザーがシステムの使用状況を詳細に把握するのに役立ちます。自分の管理ログを探しているときに、ログ 6013 に遭遇したことがあるユーザーは多いでしょう。では、このコードは何を意味するのでしょうか。以下にそれを紹介しましょう。 win10 ログ 6013 とは: 1. これは通常のログです。このログの情報は、コンピュータが再起動されたことを意味するものではなく、最後の起動からシステムが実行されている時間を示します。このログは、毎日 1 回、12 時ちょうどに表示されます。システムの稼働時間を確認するにはどうすればよいですか? cmd に systeminfo と入力できます。その中に一行あります。
 ロガーのバッファ サイズ ログの用途
Mar 13, 2023 pm 04:27 PM
ロガーのバッファ サイズ ログの用途
Mar 13, 2023 pm 04:27 PM
この機能は、開発時に使用される問題分析を容易にするために、使用情報と記録をエンジニアにフィードバックする機能であり、ユーザー自身がアップロード ログを生成することはほとんどないため、ユーザーにとっては役に立ちません。ロギング バッファは、ディスクに書き込まれる REDO ログの変更ベクトルを短期的に保存するために使用される小さな一時領域です。ディスクへのログ バッファーの書き込みは、複数のトランザクションからの変更ベクトルのバッチです。それでも、ログ バッファー内の変更ベクトルはほぼリアルタイムでディスクに書き込まれ、セッションが COMMIT ステートメントを発行すると、ログ バッファーの書き込み操作がリアルタイムで実行されます。
 Win10 でのイベント 7034 エラー ログの問題のトラブルシューティング
Jan 11, 2024 pm 02:06 PM
Win10 でのイベント 7034 エラー ログの問題のトラブルシューティング
Jan 11, 2024 pm 02:06 PM
win10 のログは、ユーザーがシステムの使用状況を詳細に把握するのに役立ちます。多くのユーザーは、自分の管理ログを探しているときに、多くのエラー ログを見たことがあるはずです。そこで、どのように解決すればよいでしょうか。以下を見てみましょう。 win10 ログ イベント 7034 を解決する方法: 1. [スタート] をクリックして [コントロール パネル] を開きます。 2. [管理ツール] を見つけます。 3. [サービス] をクリックします。 4. HDZBCommServiceForV2.0 を見つけて、右クリックして [サービスの停止] を変更します。 「手動開始」へ
 ThinkPHP6 でのログインの使用方法
Jun 20, 2023 am 08:37 AM
ThinkPHP6 でのログインの使用方法
Jun 20, 2023 am 08:37 AM
インターネットと Web アプリケーションの急速な発展に伴い、ログ管理の重要性がますます高まっています。 Web アプリケーションを開発する場合、問題を見つけて特定する方法は非常に重要な問題です。ログ システムは、これらのタスクを達成するのに役立つ非常に効果的なツールです。 ThinkPHP6 は、アプリケーション開発者がアプリケーション内で発生するイベントをより適切に管理および追跡できるようにする強力なログ システムを提供します。この記事では、ThinkPHP6 のロギングシステムの使い方とロギングシステムの活用方法を紹介します。
 iPhoneのヘルスケアアプリで薬の記録履歴を表示する方法
Nov 29, 2023 pm 08:46 PM
iPhoneのヘルスケアアプリで薬の記録履歴を表示する方法
Nov 29, 2023 pm 08:46 PM
iPhone では、ヘルスケア App に薬を追加して、毎日摂取する薬、ビタミン、サプリメントを追跡および管理できます。デバイスで通知を受信したときに、服用した薬またはスキップした薬を記録できます。薬を記録すると、どれくらいの頻度で薬を服用したか、または服用しなかったかを確認できるので、健康状態を追跡するのに役立ちます。この記事では、iPhone のヘルスケア アプリで選択した薬のログ履歴を表示する方法を説明します。ヘルスケア アプリで薬の記録履歴を表示する方法に関する短いガイド: ヘルスケア アプリ > 参照 > 薬 > 薬 > 薬の選択 > オプション&a に移動します。
 Linuxシステムのログ閲覧コマンドを詳しく解説!
Mar 06, 2024 pm 03:55 PM
Linuxシステムのログ閲覧コマンドを詳しく解説!
Mar 06, 2024 pm 03:55 PM
Linux システムでは、次のコマンドを使用してログ ファイルの内容を表示できます。 tail コマンド: tail コマンドは、ログ ファイルの末尾の内容を表示するために使用されます。最新のログ情報を表示するための一般的なコマンドです。 tail [オプション] [ファイル名] 一般的に使用されるオプションは次のとおりです。 -n: 表示する行数を指定します。デフォルトは 10 行です。 -f: ファイルの内容をリアルタイムで監視し、ファイルが更新されたときに新しい内容を自動的に表示します。例: tail-n20logfile.txt#logfile.txt ファイルの最後の 20 行を表示 tail-flogfile.txt#logfile.txt ファイルの更新された内容をリアルタイムで監視 head コマンド: head コマンドは先頭を表示するために使用されます。ログファイルの
 win10 ログのイベント ID455 の意味を理解する
Jan 12, 2024 pm 09:45 PM
win10 ログのイベント ID455 の意味を理解する
Jan 12, 2024 pm 09:45 PM
win10のログは内容が豊富で、自分の管理ログを探しているときにイベントID455の表示エラーを見たことがある人も多いと思いますが、これはどういう意味なのか見てみましょう。 win10 ログのイベント ID455 とは次のとおりです。 1. ID455 は、インフォメーション ストアがログ ファイルを開いたときに <file> で発生したエラー <error> です。
 Linux でログを表示する 3 つのコマンド
Jan 04, 2023 pm 02:00 PM
Linux でログを表示する 3 つのコマンド
Jan 04, 2023 pm 02:00 PM
Linux でログを表示するための 3 つのコマンドは、1. ファイル内容とログ ファイルの変更をリアルタイムで表示できる tail コマンド、2. 複数のログ ファイルを同時に監視できる multitail コマンド、3.less コマンドです。画面を煩雑にすることなく、ログへの変更をすばやく表示できます。
