

基本的なjsメソッドのデータ型

非常に基本的な知識ポイント。この記事では主に JavaScript で基本的なデータ型と参照データ型がどのように格納されているかを紹介します。
私は野良プログラマーなので、勉強したばかりです。私はプログラミングを学び始めた頃、メモリの基礎知識をあまり意識していなかったので、「スタックに何が格納されるか、参照のみがスタックに格納される」というといつも混乱してしまいました。 。
その後、記憶に関する知識を少しずつ学んできましたが、この部分は今でも理解しておく必要があります。
基本的なデータ構造
スタック
スタックは、セクション内での挿入または削除操作のみを許可する線形テーブルです。 、ラストアウトシステム。
Heap
Heap は、ハッシュ アルゴリズムに基づいたデータ構造です。
Queue
Queue は先入れ先出し (FIFO) データ構造です。
JavaScript におけるデータ型の格納
JavaScript のデータ型は、基本データ型と参照データ型に分けられます。それらの違いの 1 つは、格納場所が異なることです。
#基本データ型
JavaScript の基本データ型は次のとおりであることは誰もが知っています:- String
- 数値
- ブール値
- 未定義
- Null
- シンボル (今は無視してください)
#参照データ型
JavaScript の参照データ型は次のとおりです:- #Array
- ##Object
- 参照データ型はヒープ メモリに格納され、次にヒープ メモリ内の実際のオブジェクトへの参照がスタック メモリに格納されます。したがって、JavaScript での参照データ型の操作は、実際のオブジェクトではなくオブジェクトへの参照に対して行われます。
図
次に、いくつかの変数を宣言してみましょう:
var name="axuebin";
var age=25;
var job;
var arr=[1,2,3];
var obj={age:25};現時点では、3 つの基本データ型 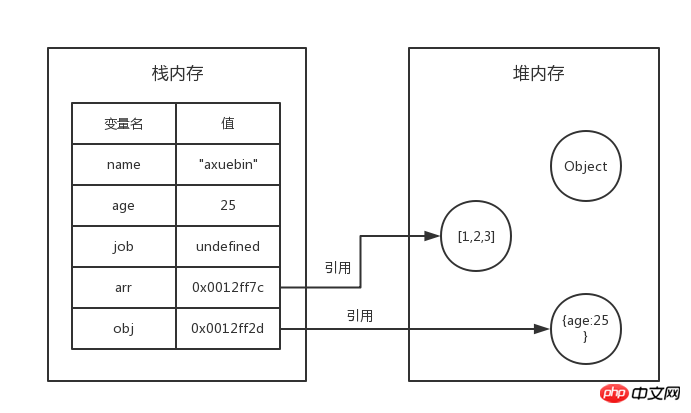 name
name
age、jobメモリ内では、arr、obj はスタックに直接格納され、ヒープ メモリへの参照を表すスタック メモリ内のアドレスのみが格納されます。 コピー
基本データ型
基本データ型の場合、コピーすると、システムによって新しい変数が自動的に作成されます。スタック メモリに新しい値を割り当てることは理解しやすいです。
参照データ型
配列やオブジェクトなどの参照データ型の場合、コピー時に相違点が生じます:
システムは自動的に割り当ても行います。新しい変数のスタック メモリ内の値ですが、この値は単なるアドレスです。つまり、コピーされた変数は元の変数と同じアドレス値を持ち、ヒープ メモリ内の同じオブジェクトを指します。表示されている場合、var objCopy=obj の実行後、obj と objCopy は同じアドレス値を持ち、ヒープ メモリ内の同じ実際のオブジェクトを実行します。 
なぜ基本データ型はスタック上に存在するのに、参照データ型はヒープ上に存在するのでしょうか?
ヒープはスタックより大きいため、スタックの比較は高速になります。
- 基本的なデータ型は比較的安定しており、使用するメモリは比較的少なくなります。
- #参照データ型のサイズは動的で無制限です。
- ヒープ メモリは順序付けされていないストレージであり、参照に基づいて直接取得できます。
- #参考記事
- js のメモリ割り当てを理解する
元の値と参考値
ECMAScript では、変数にはプリミティブ値と参照値の 2 種類の値を格納できます。 元の値とは、元のデータ型 (基本データ型) を表す値、つまり Unknown、Null、Number、String、Boolean 型で表される値を指します。 参照値は、複合データ型の値、つまりオブジェクト、関数、配列、カスタム オブジェクトなどを指します。
スタックとヒープ
元の値と参照値に対応するメモリの構造は 2 つあります。つまり、スタックとヒープです。JavaScript では、スタックは後入れ先出しのデータ構造です。スタックの動作をシミュレートするために使用できます。
プリミティブ値はスタックに保存される単純なデータです。つまり、その値は変数によってアクセスされる場所に直接保存されます。
ヒープはハッシュアルゴリズムに基づいたデータ構造であり、JavaScriptでは参照値がヒープに格納されます。 参照値はヒープに格納されているオブジェクトです。つまり、変数に格納されている値 (つまり、スタックに格納されているオブジェクトを指す変数) は、格納されている実際のオブジェクトを指すポインタです。ヒープ内。
例:var obj = new Object(); obj存储在栈中它指向于new Object()这个对象,而new Object()是存放在堆中的。
那为什么引用值要放在堆中,而原始值要放在栈中,不都是在内存中吗,为什么不放在一起呢?那接下来,让我们来探索问题的答案!
首先,我们来看一下代码:
function Person(id,name,age){
this.id = id;
this.name = name;
this.age = age;
}
var num = 10;
var bol = true;
var str = "abc";
var obj = new Object();
var arr = ['a','b','c'];
var person = new Person(100,"笨蛋的座右铭",25);然后我们来看一下内存分析图:
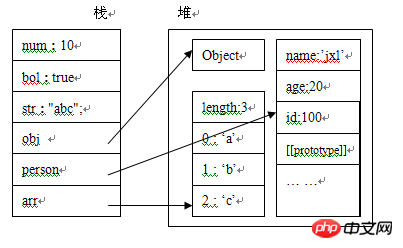
变量num,bol,str为基本数据类型,它们的值,直接存放在栈中,obj,person,arr为复合数据类型,他们的引用变量存储在栈中,指向于存储在堆中的实际对象。
由上图可知,我们无法直接操纵堆中的数据,也就是说我们无法直接操纵对象,但我们可以通过栈中对对象的引用来操作对象,就像我们通过遥控机操作电视机一样,区别在于这个电视机本身并没有控制按钮。
现在让我们来回答为什么引用值要放在堆中,而原始值要放在栈中的问题:
记住一句话:能量是守衡的,无非是时间换空间,空间换时间的问题
堆比栈大,栈比堆的运算速度快,对象是一个复杂的结构,并且可以自由扩展,如:数组可以无限扩充,对象可以自由添加属性。将他们放在堆中是为了不影响栈的效率。而是通过引用的方式查找到堆中的实际对象再进行操作。相对于简单数据类型而言,简单数据类型就比较稳定,并且它只占据很小的内存。不将简单数据类型放在堆是因为通过引用到堆中查找实际对象是要花费时间的,而这个综合成本远大于直接从栈中取得实际值的成本。所以简单数据类型的值直接存放在栈中。
总结:以上就是本篇文的全部内容,希望能对大家的学习有所帮助。更多相关教程请访问JavaScript视频教程!
相关推荐:
以上が基本的なjsメソッドのデータ型の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7517
7517
 15
1378
52
79
11
21
66
15
1378
52
79
11
21
66

 独自のJavaScriptライブラリを作成および公開するにはどうすればよいですか?
Mar 18, 2025 pm 03:12 PM
独自のJavaScriptライブラリを作成および公開するにはどうすればよいですか?
Mar 18, 2025 pm 03:12 PM
記事では、JavaScriptライブラリの作成、公開、および維持について説明し、計画、開発、テスト、ドキュメント、およびプロモーション戦略に焦点を当てています。
 ブラウザでのパフォーマンスのためにJavaScriptコードを最適化するにはどうすればよいですか?
Mar 18, 2025 pm 03:14 PM
ブラウザでのパフォーマンスのためにJavaScriptコードを最適化するにはどうすればよいですか?
Mar 18, 2025 pm 03:14 PM
この記事では、ブラウザでJavaScriptのパフォーマンスを最適化するための戦略について説明し、実行時間の短縮、ページの負荷速度への影響を最小限に抑えることに焦点を当てています。
 フロントエンドのサーマルペーパーレシートのために文字化けしたコード印刷に遭遇した場合はどうすればよいですか?
Apr 04, 2025 pm 02:42 PM
フロントエンドのサーマルペーパーレシートのために文字化けしたコード印刷に遭遇した場合はどうすればよいですか?
Apr 04, 2025 pm 02:42 PM
フロントエンドのサーマルペーパーチケット印刷のためのよくある質問とソリューションフロントエンド開発におけるチケット印刷は、一般的な要件です。しかし、多くの開発者が実装しています...
 ブラウザ開発者ツールを使用してJavaScriptコードを効果的にデバッグするにはどうすればよいですか?
Mar 18, 2025 pm 03:16 PM
ブラウザ開発者ツールを使用してJavaScriptコードを効果的にデバッグするにはどうすればよいですか?
Mar 18, 2025 pm 03:16 PM
この記事では、ブラウザ開発者ツールを使用した効果的なJavaScriptデバッグについて説明し、ブレークポイントの設定、コンソールの使用、パフォーマンスの分析に焦点を当てています。
 誰がより多くのPythonまたはJavaScriptを支払われますか?
Apr 04, 2025 am 12:09 AM
誰がより多くのPythonまたはJavaScriptを支払われますか?
Apr 04, 2025 am 12:09 AM
スキルや業界のニーズに応じて、PythonおよびJavaScript開発者には絶対的な給与はありません。 1. Pythonは、データサイエンスと機械学習でさらに支払われる場合があります。 2。JavaScriptは、フロントエンドとフルスタックの開発に大きな需要があり、その給与もかなりです。 3。影響要因には、経験、地理的位置、会社の規模、特定のスキルが含まれます。
 ソースマップを使用して、マイナイドJavaScriptコードをデバッグするにはどうすればよいですか?
Mar 18, 2025 pm 03:17 PM
ソースマップを使用して、マイナイドJavaScriptコードをデバッグするにはどうすればよいですか?
Mar 18, 2025 pm 03:17 PM
この記事では、ソースマップを使用して、元のコードにマッピングすることにより、Minified JavaScriptをデバッグする方法について説明します。ソースマップの有効化、ブレークポイントの設定、Chrome DevtoolsやWebpackなどのツールの使用について説明します。
 chart.js:パイ、ドーナツ、バブルチャートを始めます
Mar 15, 2025 am 09:19 AM
chart.js:パイ、ドーナツ、バブルチャートを始めます
Mar 15, 2025 am 09:19 AM
このチュートリアルでは、chart.jsを使用してパイ、リング、およびバブルチャートを作成する方法について説明します。以前は、4つのチャートタイプのchart.js:ラインチャートとバーチャート(チュートリアル2)、およびレーダーチャートと極地域チャート(チュートリアル3)を学びました。 パイとリングチャートを作成します パイチャートとリングチャートは、さまざまな部分に分かれている全体の割合を示すのに理想的です。たとえば、パイチャートを使用して、サファリの男性ライオン、女性ライオン、若いライオンの割合、または異なる候補者が選挙で受け取る票の割合を示すことができます。 パイチャートは、単一のパラメーターまたはデータセットの比較にのみ適しています。パイチャートのファンの角度はデータポイントの数値サイズに依存するため、パイチャートは値のあるエンティティをゼロ値で描画できないことに注意してください。これは、割合がゼロのエンティティを意味します
 Console.log出力の違い結果:なぜ2つの呼び出しが異なるのですか?
Apr 04, 2025 pm 05:12 PM
Console.log出力の違い結果:なぜ2つの呼び出しが異なるのですか?
Apr 04, 2025 pm 05:12 PM
Console.log出力の違いの根本原因に関する詳細な議論。この記事では、Console.log関数の出力結果の違いをコードの一部で分析し、その背後にある理由を説明します。 �...
