

MySQL マスター/スレーブ レプリケーションとは何ですか?実装を構成するにはどうすればよいですか?

この記事の内容は、MySql のマスター/スレーブ レプリケーションとは何なのかを紹介することです。実装を構成するにはどうすればよいですか?困っている友人は参考にしていただければ幸いです。
1. MySQL マスター/スレーブ レプリケーションとは
MySQL マスター/スレーブ レプリケーションは、MySQL の最も重要な機能の 1 つです。マスター/スレーブ レプリケーションとは、1 つのサーバーがマスター データベース サーバーとして機能し、別のサーバーまたは複数のサーバーがスレーブ データベース サーバーとして機能することを意味します。マスター サーバーのデータはスレーブ サーバーに自動的にコピーされます。マルチレベル レプリケーションの場合、データベース サーバーはマスターまたはスレーブのいずれかとして機能します。 MySQL のマスター/スレーブ レプリケーションの基本は、マスター サーバーがデータベース変更のバイナリ ログを記録し、スレーブ サーバーがマスター サーバーのバイナリ ログを通じて更新を自動的に実行することです。
2. Mysq マスター/スレーブ レプリケーションの種類
1. ステートメントベースのレプリケーション:
マスター サーバーで実行されたステートメントはスレーブ サーバーでも再度実行されます。 MySQL では、バージョン 3.23 以降でサポートされます。
既存の問題: 時刻が完全に同期されていないためにずれが発生する可能性があり、ステートメントを実行するユーザーも別のユーザーである可能性があります。
2. 行ベースのレプリケーション:
どのステートメントがコンテンツの変更を引き起こしたかを考慮せずに、調整されたコンテンツをメイン サーバーに直接コピーします。MySQL-5.0 では、今後のバージョンで導入されます。 。
既存の問題: たとえば、給与テーブルに 10,000 人のユーザーがいる場合、各ユーザーの給与を 1,000 に設定すると、行ベースのレプリケーションによって 10,000 行の内容がコピーされるため、比較的大きなオーバーヘッドが発生します。大規模なステートメントベースのレプリケーションに必要なステートメントは 1 つだけです。
3. 混合タイプのレプリケーション:
MySQL はデフォルトでステートメントベースのレプリケーションを使用します。ステートメントベースのレプリケーションで問題が発生した場合、MySQL は自動的に行ベースのレプリケーションを使用します。選択。
MySQL マスター/スレーブ レプリケーション アーキテクチャでは、読み取り操作はすべてのサーバーで実行できますが、書き込み操作はマスター サーバーでのみ実行できます。マスター/スレーブ レプリケーション アーキテクチャは読み取り操作の拡張を提供しますが、書き込み操作が増えると (複数のスレーブ サーバーがマスター サーバーからのデータを同期する必要がある)、シングル マスターのレプリケーションでは必然的にマスター サーバーがパフォーマンスのボトルネックになります。モデル。
3. MySQL マスター/スレーブ レプリケーションの動作原理
1、ステートメントベースのレプリケーション: マスター サーバーで実行されるステートメントは次のとおりです。スレーブサーバー上で再度実行します。MySQL-3.23 以降のバージョンでサポートされます。
既存の問題: 時刻が完全に同期されていないためにずれが発生する可能性があり、ステートメントを実行するユーザーも別のユーザーである可能性があります。
2、行ベースのレプリケーション: MySQL の後に導入された、どのステートメントがコンテンツの変更を引き起こしたかを気にせずに、調整されたコンテンツをメイン サーバーに直接コピーします。 -5.0バージョン。
既存の問題: たとえば、給与テーブルに 10,000 人のユーザーがいる場合、各ユーザーの給与を 1,000 に設定すると、行ベースのレプリケーションによって 10,000 行の内容がコピーされるため、比較的大きなオーバーヘッドが発生します。大規模なステートメントベースのレプリケーションに必要なステートメントは 1 つだけです。
3、混合タイプのレプリケーション: MySQL はデフォルトでステートメントベースのレプリケーションを使用します。ステートメントベースのレプリケーションで問題が発生した場合、行ベースのレプリケーションが使用されます。自動的に選択されます。
MySQL マスター/スレーブ レプリケーション アーキテクチャでは、読み取り操作はすべてのサーバーで実行できますが、書き込み操作はマスター サーバーでのみ実行できます。マスター/スレーブ レプリケーション アーキテクチャは読み取り操作の拡張を提供しますが、書き込み操作が増えると (複数のスレーブ サーバーがマスター サーバーからのデータを同期する必要がある)、シングル マスターのレプリケーションでは必然的にマスター サーバーがパフォーマンスのボトルネックになります。モデル。
MySQL の 3 つのマスター/スレーブ レプリケーションの動作原理
次の図に示すように:
メイン サーバー上の変更はすべて次のようになります。バイナリログに保存されます。 バイナリログでは、サーバー (実際にはメインサーバーのクライアントプロセス) から I/O スレッドが開始され、メインサーバーに接続してバイナリログの読み取りを要求し、読み取ったバイナリを書き込みます。ローカルにログを記録します 実際に内部にログインします。サーバーから SQL スレッドを開始して Realy ログを定期的に確認し、変更が見つかった場合は、変更された内容をローカル マシンですぐに実行します。
1 つのマスターと複数のスレーブがある場合、マスター ライブラリは、複数のスレーブ ライブラリに対するバイナリ ログの書き込みと提供の両方を担当します。このとき、若干の調整を行って、特定のスレーブにのみバイナリ ログを提供すると、このスレーブはバイナリ ログを有効にし、独自のバイナリ ログを他のスレーブに送信します。または、単純に、これは記録を行わず、バイナリ ログを他のスレーブに転送することだけを担当します。この方法では、アーキテクチャのパフォーマンスが大幅に向上し、データ間の遅延もわずかに改善されるはずです。動作原理図は次のとおりです。
実際、古いバージョンの MySQL マスター/スレーブ レプリケーションでは、スレーブ側は 2 つのプロセスではなく 1 つのプロセスで完了します。プロセス。ただし、これを行うと、主に次のような大きなリスクとパフォーマンス上の問題があることが後に判明しました。
まず、プロセスは、bin-log ログをコピーしてログを解析し、それを独自に実行するプロセスをシリアル プロセスにします。パフォーマンスには一定の制限があり、非同期レプリケーションの遅延も発生します。比較的長くなります。
さらに、スレーブ側はマスター側から bin-log を取得した後、ログの内容を解析して独自に実行する必要があります。このプロセス中に、マスター側で多数の変更が発生し、多数の新しいログが追加された可能性があります。この段階でマスターのストレージで修復不可能なエラーが発生した場合、この段階で行われたすべての変更は決して取得されません。スレーブに対する圧力が比較的高い場合、このプロセスにはさらに時間がかかることがあります。
レプリケーションのパフォーマンスを向上させ、既存のリスクを解決するために、MySQL の新しいバージョンでは、スレーブ側のレプリケーション アクションが 2 つのプロセスに転送されます。この改善案を提案したのは、Yahoo! のエンジニアである「Jeremy Zawodny」さんです。これにより、パフォーマンスの問題が解決されるだけでなく、非同期遅延時間が短縮され、起こり得るデータ損失の量も削減されます。
もちろん、現在の 2 スレッド処理に切り替えた後でも、このレプリケーションは非同期であるため、スレーブ データの遅延とデータ損失の可能性は依然としてあります。これらの問題は、データ変更が 1 つのトランザクション内で行われない限り存在します。これらの問題を完全に回避したい場合は、MySQL クラスターを使用して解決するしかありません。ただし、MySQL のクラスタはインメモリ データベース用のソリューションであり、すべてのデータをメモリにロードする必要があるため、非常に大きなメモリが必要となり、一般的なアプリケーションにはあまり実用的ではありません。
もう 1 つ言及しておきたいのは、MySQL のレプリケーション フィルターを使用すると、サーバー内のデータの一部のみをコピーできることです。レプリケーション フィルタリングには 2 つのタイプがあります。マスター上のバイナリ ログ内のイベントをフィルタリングするものと、スレーブ上のリレー ログ内のイベントをフィルタリングするものです。次のように:
マスターの my.cnf ファイルを設定します (キー設定)/etc/my.cnf
log-bin=mysql-bin server-id = 1 binlog-do-db=icinga binlog-do-db=DB2 //如果备份多个数据库,重复设置这个选项即可 binlog-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 binlog-ignore-db=mysql //被忽略的数据库 配置Slave的my.cnf文件(关键性的配置)/etc/my.cnf log-bin=mysql-bin server-id=2 master-host=10.1.68.110 master-user=backup master-password=1234qwer master-port=3306 replicate-do-db=icinga replicate-do-db=DB2 replicate-do-db=DB3 //需要同步的数据库,如果没有本行,即表示同步所有的数据库 replicate-ignore-db=mysql //被忽略的数据库
ネチズンは、replicate-do-db と言うかもしれません。使用中に問題が発生する可能性があります (http://blog.knowsky.com/19696...)。私自身はテストしていません。メインサーバーで binlog-do-db パラメータを使用して、バイナリログをフィルタリングすることにより、構成ファイルでのコピーが許可されていないデータベースをフィルタリングする、つまり、データを許可しない操作ログを書き込まないようにするために使用されていると思います。バイナリ ログにコピーされます。また、replicate-do -db は、リレー ログをフィルタリングすることによってコピーが許可されていないデータベースまたはテーブルをフィルタリングするためにサーバーから使用されます。つまり、リレー ログ内のアクションを実行するときに、許可されていない変更行為は実行されません。この場合、複数のスレーブ データベース サーバーの場合: 一部のスレーブ サーバーはマスター サーバーからデータをコピーするだけでなく、マスター サーバーとして機能して他のスレーブ サーバーにデータをコピーするため、binlog-do- が存在できるはずです。同時に、設定ファイル内の 2 つのパラメータ db と replicate-do-db は正しいです。すべては私自身の予測です。binlog-do-db と replicate-do-db の具体的な使用法については、実際の開発で少し検討する必要があります。
インターネットでは、レプリケーション中に特定のデータベースやテーブルを無視する操作は、マスター サーバーでは実行しないほうがよいと言われています。マスター サーバーがそれを無視すると、バイナリに書き込めなくなるからです。一部のデータベースは無視されますが、マスターサーバー上の操作情報はスレーブサーバー上の中継ログにコピーされますが、スレーブサーバー上では実行されません。これは、マスターサーバーの binlog-do-db ではなく、スレーブサーバーに replicate-do-db を設定することが推奨されることを意味すると思います。
さらに、ブラックリスト (binlog-ignore-db、replicate-ignore-db) であってもホワイトリスト (binlog-do-db、replicate-do-db) であっても、必要に応じて 1 つだけ記述します。同時に使用すると、ホワイトリストのみが有効になります。
4. MySQL マスター/スレーブ レプリケーションのプロセス
MySQL マスター/スレーブ レプリケーションには、同期レプリケーションと非同期レプリケーションの 2 つの状況があります。実際のレプリケーション アーキテクチャのほとんどは非同期です。レプリケーション。
レプリケーションの基本プロセスは次のとおりです。
スレーブ上の IO プロセスはマスターに接続し、指定された場所から指定されたログ ファイルを要求します。 (または最初からの)ログ)。
マスターがスレーブの IO プロセスからリクエストを受信した後、レプリケーションを担当する IO プロセスはリクエスト情報に従ってログの指定された位置以降のログ情報を読み取り、それを返します。スレーブの IO プロセスに送信します。ログに含まれる情報に加えて、返される情報には、bin ログ ファイルの名前と、返された情報がマスターに送信された bin ログの場所も含まれます。
スレーブの IO プロセスは情報を受信すると、受信したログの内容をスレーブ側のリレー ログ ファイルの末尾に追加し、bin ログを読み取ります。マスター側では、ログのファイル名と場所がマスター情報ファイルに記録されるため、次回ログを読み取るときに、マスターは「特定の bin ログのどの場所から開始する必要があるか」を明確に知ることができます。次のログの内容を送ってください。」
スレーブ SQL プロセスは、リレー ログに新しく追加されたコンテンツを検出すると、リレー ログのコンテンツをすぐに解析し、実際に実行されるときに実行可能なコンテンツになります。マスター側で実行します。
五、Mysql主从复制的具体配置
复制通常用来创建主节点的副本,通过添加冗余节点来保证高可用性,当然复制也可以用于其他用途,例如在从节点上进行数据读、分析等等。在横向扩展的业务中,复制很容易实施,主要表现在在利用主节点进行写操作,多个从节点进行读操作,MySQL复制的异步性是指:事物首先在主节点上提交,然后复制给从节点并在从节点上应用,这样意味着在同一个时间点主从上的数据可能不一致。异步复制的好处在于它比同步复制要快,如果对数据的一致性要求很高,还是采用同步复制较好。
最简单的复制模式就是一主一从的复制模式了,这样一个简单的架构只需要三个步骤即可完成:
(1)建立一个主节点,开启binlog,设置服务器id;
(2)建立一个从节点,设置服务器id;
(3)将从节点连接到主节点上。
下面我们开始操作,以MySQL 5.5为例,操作系统Ubuntu12.10,Master 10.1.6.159 Slave 10.1.6.191。
apt-get install mysql-server
Master机器
Master上面开启binlog日志,并且设置一个唯一的服务器id,在局域网内这个id必须唯一。二进制的binlog日志记录master上的所有数据库改变,这个日志会被复制到从节点上,并且在从节点上回放。修改my.cnf文件,在mysqld模块下修改如下内容:
[mysqld] server-id = 1 log_bin = /var/log/mysql/mysql-bin.log
log_bin设置二进制日志所产生文件的基本名称,二进制日志由一系列文件组成,log_bin的值是可选项,如果没有为log_bin设置值,则默认值是:主机名-bin。如果随便修改主机名,则binlog日志的名称也会被改变的。server-id是用来唯一标识一个服务器的,每个服务器的server-id都不一样。这样slave连接到master后,会请求master将所有的binlog传递给它,然后将这些binlog在slave上回放。为了防止权限混乱,一般都是建立一个单独用于复制的账户。
binlog是复制过程的关键,它记录了数据库的所有改变,通常即将执行完毕的语句会在binlog日志的末尾写入一条记录,binlog只记录改变数据库的语句,对于不改变数据库的语句则不进行记录。这种情况叫做基于语句的复制,前面提到过还有一种情况是基于行的复制,两种模式各有各的优缺点。
Slave机器
slave机器和master一样,需要一个唯一的server-id。
[mysqld] server-id = 2
连接Slave到Master
在Master和Slave都配置好后,只需要把slave只想master即可
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456'; start slave;
接下来在master上做一些针对改变数据库的操作,来观察slave的变化情况。在修改完my.cnf配置重启数据库后,就开始记录binlog了。可以在/var/log/mysql目录下看到一个mysql-bin.000001文件,而且还有一个mysql-bin.index文件,这个mysql-bin.index文件是什么?这个文件保存了所有的binlog文件列表,但是我们在配置文件中并没有设置改值,这个可以通过log_bin_index进行设置,如果没有设置改值,则默认值和log_bin一样。在master上执行show binlog events命令,可以看到第一个binlog文件的内容。
注意:上面的sql语句是从头开始复制第一个binlog,如果想从某个位置开始复制binlog,就需要在change master to时指定要开始的binlog文件名和语句在文件中的起点位置,参数如下:master_log_file和master_log_pos。
mysql> show binlog events\G *************************** 1. row *************************** Log_name: mysql-bin.000001 Pos: 4 Event_type: Format_desc Server_id: 1 End_log_pos: 107 Info: Server ver: 5.5.28-0ubuntu0.12.10.2-log, Binlog ver: 4 *************************** 2. row *************************** Log_name: mysql-bin.000001 Pos: 107 Event_type: Query Server_id: 1 End_log_pos: 181 Info: create user rep *************************** 3. row *************************** Log_name: mysql-bin.000001 Pos: 181 Event_type: Query Server_id: 1 End_log_pos: 316 Info: grant replication slave on *.* to rep identified by '123456' 3 rows in set (0.00 sec)
Log_name 是二进制日志文件的名称,一个事件不能横跨两个文件
Pos 这是该事件在文件中的开始位置
Event_type 事件的类型,事件类型是给slave传递信息的基本方法,每个新的binlog都已Format_desc类型开始,以Rotate类型结束
Server_id 创建该事件的服务器id
End_log_pos 该事件的结束位置,也是下一个事件的开始位置,因此事件范围为Pos~End_log_pos-1
Info 事件信息的可读文本,不同的事件有不同的信息
示例
在master的test库中创建一个rep表,并插入一条记录。
create table rep(name var);
insert into rep values ("guol");
flush logs;flush logs命令强制轮转日志,生成一个新的二进制日志,可以通过show binlog events in 'xxx'来查看该二进制日志。可以通过show master status查看当前正在写入的binlog文件。这样就会在slave上执行相应的改变操作。
上面就是最简单的主从复制模式,不过有时候随着时间的推进,binlog会变得非常庞大,如果新增加一台slave,从头开始复制master的binlog文件是非常耗时的,所以我们可以从一个指定的位置开始复制binlog日志,可以通过其他方法把以前的binlog文件进行快速复制,例如copy物理文件。在change master to中有两个参数可以实现该功能,master_log_file和master_log_pos,通过这两个参数指定binlog文件及其位置。我们可以从master上复制也可以从slave上复制,假如我们是从master上复制,具体操作过程如下:
(1)为了防止在操作过程中数据更新,导致数据不一致,所以需要先刷新数据并锁定数据库:flush tables with read lock。
(2)检查当前的binlog文件及其位置:show master status。
mysql> show master status\G *************************** 1. row *************************** File: mysql-bin.000003 Position: 107 Binlog_Do_DB: Binlog_Ignore_DB: 1 row in set (0.00 sec)
(3)通过mysqldump命令创建数据库的逻辑备分:mysqldump --all-databases -hlocalhost -p >back.sql。
(4)有了master的逻辑备份后,对数据库进行解锁:unlock tables。
(5)把back.sql复制到新的slave上,执行:mysql -hlocalhost -p 把master的逻辑备份插入slave的数据库中。
(6)现在可以把新的slave连接到master上了,只需要在change master to中多设置两个参数master_log_file='mysql-bin.000003'和master_log_pos='107'即可,然后启动slave:start slave,这样slave就可以接着107的位置进行复制了。
change master to master_host='10.1.6.159',master_port=3306,master_user='rep', master_password='123456',master_log_file='mysql-bin.000003',master_log_pos='107'; start slave;
有时候master并不能让你锁住表进行复制,因为可能跑一些不间断的服务,如果这时master已经有了一个slave,我们则可以通过这个slave进行再次扩展一个新的slave。原理同在master上进行复制差不多,关键在于找到binlog的位置,你在复制的同时可能该slave也在和master进行同步,操作如下:
(1)为了防止数据变动,还是需要停止slave的同步:stop slave。
(2)然后刷新表,并用mysqldump逻辑备份数据库。
(3)使用show slave status查看slave的相关信息,记录下两个字段的值Relay_Master_Log_File和Exec_Master_Log_Pos,这个用来确定从后面哪里开始复制。
(4)对slave解锁,把备份的逻辑数据库导入新的slave的数据库中,然后设置change master to,这一步和复制master一样。
六、深入了解Mysql主从配置
1、一主多从
由一个master和一个slave组成复制系统是最简单的情况。Slave之间并不相互通信,只能与master进行通信。在实际应用场景中,MySQL复制90%以上都是一个Master复制到一个或者多个Slave的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。
在上图中,是我们开始时提到的一主多从的情况,这时主库既要负责写又要负责为几个从库提供二进制日志。这种情况将二进制日志只给某一从,这一从再开启二进制日志并将自己的二进制日志再发给其它从,或者是干脆这个从不记录只负责将二进制日志转发给其它从,这样架构起来性能可能要好得多,而且数据之间的延时应该也稍微要好一些。PS:这些前面都写过了,又复制了一遍。
2、主主复制
上图中,Master-Master复制的两台服务器,既是master,又是另一台服务器的slave。这样,任何一方所做的变更,都会通过复制应用到另外一方的数据库中。在这种复制架构中,各自上运行的不是同一db,比如左边的是db1,右边的是db2,db1的从在右边反之db2的从在左边,两者互为主从,再辅助一些监控的服务还可以实现一定程度上的高可以用。
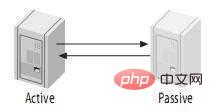
3、主动—被动模式的Master-Master(Master-Master in Active-Passive Mode)
上图中,这是由master-master结构变化而来的,它避免了M-M的缺点,实际上,这是一种具有容错和高可用性的系统。它的不同点在于其中只有一个节点在提供读写服务,另外一个节点时刻准备着,当主节点一旦故障马上接替服务。比如通过corosync+pacemaker+drbd+MySQL就可以提供这样一组高可用服务,主备模式下再跟着slave服务器,也可以实现读写分离。
4、带从服务器的Master-Master结构(Master-Master with Slaves)

この構造の利点は、冗長性が提供されることです。地理的に分散されたレプリケーション構造では、単一ノード障害の問題は発生せず、読み取り集中型のリクエストもスレーブに配置できます。
5. MySQL-5.5 は半同期レプリケーションをサポートします
以前の MySQL レプリケーションは非同期実装に基づいてのみ実装できました。MySQL-5.5 からは、半自動レプリケーションがサポートされます。以前の非同期レプリケーションでは、メイン データベースは、いくつかのトランザクションの実行後にスタンバイ データベースの進行状況を制御しませんでした。スタンバイ・データベースが遅れていて、運悪くメイン・データベースがクラッシュした場合(ダウンタイムなど)、スタンバイ・データベース内のデータは不完全になります。つまり、メイン データベースに障害が発生すると、スタンバイ データベースを使用してデータ整合性のあるサービスを提供し続けることができなくなります。準同期レプリケーション (準同期レプリケーション) は、送信されたトランザクションが少なくとも 1 つのスタンバイ データベースに送信されたことをある程度保証します。準同期では、トランザクションがスタンバイ データベースに配信されたことだけが保証され、スタンバイ データベースでトランザクションが完了したことは保証されません。
さらに、プライマリ データとセカンダリ データの不一致を引き起こす可能性のある別の状況があります。セッションでは、トランザクションがメイン データベースに送信された後、トランザクションが少なくとも 1 つのスタンバイ データベースに転送されるまで待機します。この待機プロセス中にメイン データベースがクラッシュした場合、スタンバイ データベースとメイン データベースが不整合になる可能性があります。 、これは非常に致命的です。アクティブおよびスタンバイのネットワークに障害が発生した場合、またはスタンバイ データベースが停止した場合、プライマリ データベースはトランザクションの送信後、続行する前に 10 秒 (rpl_semi_sync_master_timeout のデフォルト値) 待機します。この時点で、メイン ライブラリは元の非同期状態に戻ります。
MySQL が半同期プラグインをロードして有効にした後、各トランザクションはスタンバイ データベースがログを受信するまで待機してから、ログをクライアントに返す必要があります。小規模なトランザクションを実行していて、2 つのホスト間の遅延が小さい場合、半同期はパフォーマンスの損失をほとんど抑えながら、データ損失をゼロにすることができます。
以上がこの記事の全内容です、皆様の学習のお役に立てれば幸いです。さらにエキサイティングなコンテンツについては、PHP 中国語 Web サイトの関連チュートリアルのコラムに注目してください。 ! !
以上がMySQL マスター/スレーブ レプリケーションとは何ですか?実装を構成するにはどうすればよいですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7509
7509
 15
1378
52
78
11
19
60
15
1378
52
78
11
19
60

 MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQL:初心者向けのデータ管理の容易さ
Apr 09, 2025 am 12:07 AM
MySQLは、インストールが簡単で、強力で管理しやすいため、初心者に適しています。 1.さまざまなオペレーティングシステムに適した、単純なインストールと構成。 2。データベースとテーブルの作成、挿入、クエリ、更新、削除などの基本操作をサポートします。 3.参加オペレーションやサブクエリなどの高度な機能を提供します。 4.インデックス、クエリの最適化、テーブルパーティション化により、パフォーマンスを改善できます。 5。データのセキュリティと一貫性を確保するために、バックアップ、リカバリ、セキュリティ対策をサポートします。
 MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQL:簡単な学習のためのシンプルな概念
Apr 10, 2025 am 09:29 AM
MySQLは、オープンソースのリレーショナルデータベース管理システムです。 1)データベースとテーブルの作成:createdatabaseおよびcreateTableコマンドを使用します。 2)基本操作:挿入、更新、削除、選択。 3)高度な操作:参加、サブクエリ、トランザクション処理。 4)デバッグスキル:構文、データ型、およびアクセス許可を確認します。 5)最適化の提案:インデックスを使用し、選択*を避け、トランザクションを使用します。
 phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
phpmyadminを開く方法
Apr 10, 2025 pm 10:51 PM
次の手順でphpmyadminを開くことができます。1。ウェブサイトコントロールパネルにログインします。 2。phpmyadminアイコンを見つけてクリックします。 3。MySQL資格情報を入力します。 4.「ログイン」をクリックします。
 Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
Navicatプレミアムの作成方法
Apr 09, 2025 am 07:09 AM
NAVICATプレミアムを使用してデータベースを作成します。データベースサーバーに接続し、接続パラメーターを入力します。サーバーを右クリックして、[データベースの作成]を選択します。新しいデータベースの名前と指定された文字セットと照合を入力します。新しいデータベースに接続し、オブジェクトブラウザにテーブルを作成します。テーブルを右クリックして、データを挿入してデータを挿入します。
 MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLおよびSQL:開発者にとって不可欠なスキル
Apr 10, 2025 am 09:30 AM
MySQLとSQLは、開発者にとって不可欠なスキルです。 1.MYSQLはオープンソースのリレーショナルデータベース管理システムであり、SQLはデータベースの管理と操作に使用される標準言語です。 2.MYSQLは、効率的なデータストレージと検索機能を介して複数のストレージエンジンをサポートし、SQLは簡単なステートメントを通じて複雑なデータ操作を完了します。 3.使用の例には、条件によるフィルタリングやソートなどの基本的なクエリと高度なクエリが含まれます。 4.一般的なエラーには、SQLステートメントをチェックして説明コマンドを使用することで最適化できる構文エラーとパフォーマンスの問題が含まれます。 5.パフォーマンス最適化手法には、インデックスの使用、フルテーブルスキャンの回避、参加操作の最適化、コードの読み取り可能性の向上が含まれます。
 NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
NavicatでMySQLへの新しい接続を作成する方法
Apr 09, 2025 am 07:21 AM
手順に従って、NAVICATで新しいMySQL接続を作成できます。アプリケーションを開き、新しい接続(CTRL N)を選択します。接続タイプとして「mysql」を選択します。ホスト名/IPアドレス、ポート、ユーザー名、およびパスワードを入力します。 (オプション)Advanced Optionsを構成します。接続を保存して、接続名を入力します。
 SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
SQLが行を削除した後にデータを回復する方法
Apr 09, 2025 pm 12:21 PM
データベースから直接削除された行を直接回復することは、バックアップまたはトランザクションロールバックメカニズムがない限り、通常不可能です。キーポイント:トランザクションロールバック:トランザクションがデータの回復にコミットする前にロールバックを実行します。バックアップ:データベースの定期的なバックアップを使用して、データをすばやく復元できます。データベーススナップショット:データベースの読み取り専用コピーを作成し、データが誤って削除された後にデータを復元できます。削除ステートメントを使用して注意してください:誤って削除されないように条件を慎重に確認してください。 WHERE句を使用します:削除するデータを明示的に指定します。テスト環境を使用:削除操作を実行する前にテストします。
 NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する方法
Apr 08, 2025 pm 11:42 PM
NAVICATでSQLを実行する手順:データベースに接続します。 SQLエディターウィンドウを作成します。 SQLクエリまたはスクリプトを書きます。 [実行]ボタンをクリックして、クエリまたはスクリプトを実行します。結果を表示します(クエリが実行された場合)。
