

この記事では、Jsoup を使用してクローラ技術を実装する方法を紹介します。一定の参考価値があります。困っている友人は参考にしてください。お役に立てれば幸いです。
1. Jsoup の簡単な説明
Java では、WebMagic、Spider、Jsoup、等今日は Jsoup を使用して、単純なクローラー プログラムを実装します。
Jsoup には、DOM オブジェクトのドキュメント トラバーサル メソッドの参照、CSS セレクターの使用方法の参照など、HTML ドキュメントを処理するための非常に便利な API が用意されているため、Jsoup を使用してメソッドをすぐに習得できます。ページデータをクローリングするスキル。
2. クイック スタート
1) HTML ページを作成します

表の製品情報ページは私たちのものです クロールするデータ。このうち属性は、pnameクラスの商品名とpimgクラスに属する商品画像です。
2) HttpClient を使用して HTML ページを読み取る
HttpClient は Http プロトコル データを処理するツールで、HTML ページを入力ストリームとして Java プログラムに読み取るために使用できます。 HttpClient jar パッケージは http://hc.apache.org/ からダウンロードできます。

3) Jsoup を使用して HTML 文字列を解析する
Jsoup ツールを導入することで、parse メソッドを直接呼び出して、HTML のコンテンツを説明する文字列を解析します。 Document オブジェクトを取得するページ。 Document オブジェクトは、DOM ツリーを操作して、HTML ページ上の指定されたコンテンツを取得します。関連する API については、Jsoup 公式ドキュメントを参照してください: https://jsoup.org/cookbook/
以下では、Jsoup を使用して、上記の HTML で指定された製品名と価格情報を取得します。
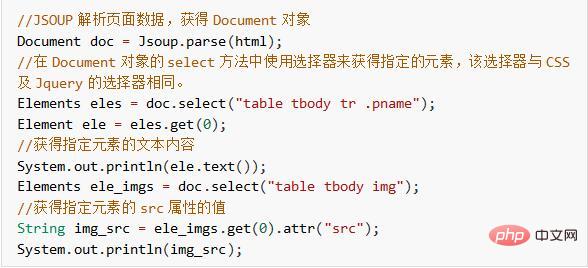
これまで、HttpClient Jsoup を使用して HTML ページのデータをクロールする機能を実装しました。次に、クロールされたデータをデータベースに保存したり、画像をサーバーに保存したりするなど、効果をより直感的にします。
3. クロールされたページ データを保存します
1) 通常のデータをデータベースに保存します
クロールされたデータをエンティティ Bean にカプセル化して、データベース。
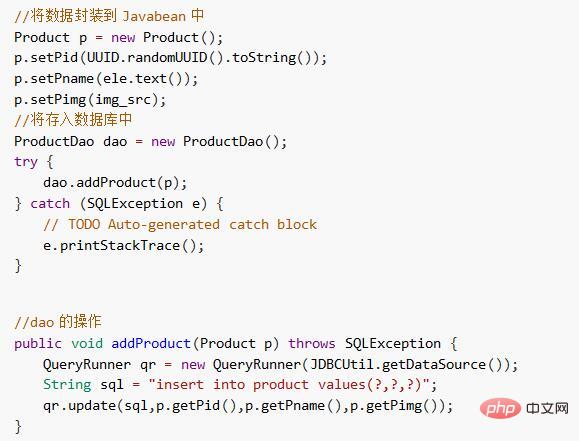
#2) 画像をサーバーに保存します
画像を直接ダウンロードして、画像をローカルのサーバーに保存します。

4. 概要
このケースでは、ネットワーク データをクロールするために HttpClient Jsoup の使用を実装しているだけです。クローラー技術そのものについては、後ほど詳しく説明します。
以上がJsoupを使用してクローラー技術を実装する方法の紹介の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



