

Javaを使用してp2pシード検索機能を実装する方法

この記事の内容は、Java を使用して p2p シード検索機能を実装する方法に関するもので、一定の参考価値があります。必要な友人は参考にしてください。
私は何年も前に p2p に非常に興味がありましたが、理論に留まり、実践する機会がありませんでした。私も最近これを実装したのですが、最初から現在に至るまで、共感できる部分がいくつかあると思います。本題に入りましょう。
基本概念
p2p について話す前に、ファイルをダウンロードする方法について話したいと思います。ファイルをダウンロードするいくつかの方法をリストします。
1. http プロトコルを使用してダウンロードします。最も一般的に使用される方法は、おそらくブラウザ経由でファイルをダウンロードすることです。
2. ftp を使用してダウンロードします。ftp には 2 つのモードがあります。1 つはポート (アクティブ) モードです。このモードでは、クライアントはローカルでポート N (>1023) を開き、ftp 接続を確立しますFTP サーバーにデータ送信用の N 1 リスニング ポートを与えます ファイアウォールがある場合、またはクライアントが NAT である場合、ダウンロードできません。もう 1 つの方法はパッシブ モードです。このモードでは、FTP サーバーはポート 21 に加えて、1023 より大きいポートを開きます。つまり、FTP サーバーが接続している限り、クライアントはアクティブに FTP 接続とデータ送信接続を開始します。このポートは開いていますので問題ありません。
上記 2 つの方式を総称して cs アーキテクチャと呼びますが、このアーキテクチャではサーバーにリソースが集中するため、データ量が一定以上になると問題が発生します。この問題を解決するために、分散分散化を考える必要があるため、p2p が登場しました。p2p は、ピア ツー ピアの略です。これは、ピア ツー ピア アーキテクチャです。各ノードは、クライアントとサーバーの両方です。
p2p アーキテクチャ
各ノードにリソースを保存するとき、リソースをダウンロードするときに、このファイルがどのマシンにあるのかをどうやって知ることができるのか、ダウンロードできるのか、と考えることがあります。
初期の p2p アーキテクチャにはトラッカーの役割があり、このトラッカーはファイルのメタデータ情報を保存する役割を担っていました。したがって、ファイルは各ピアに保存され、ファイル情報はトラッカーを通じて取得されます。
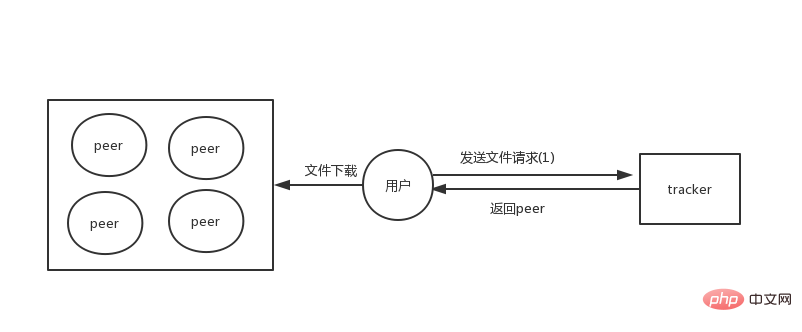
このアーキテクチャでは、すべてのファイルが分散されますが、トラッカーはすべてのファイルのメタデータ情報を保存する責任があるため、トラッカーが保存する必要があるのは少量だけです既存のファイルに比べて、データの削除が比較的簡単になります。
しかし、トラッカー サーバーがハングするかサービスが利用できなくなると、完全に分散されていないため、すべてのファイルはダウンロードされません。完全に分散化するために、トラッカーレス アーキテクチャが後で開発される予定です。,
現時点では、トラッカーは存在せず、ファイルのメタデータ情報を含むすべてのファイルが分散形式で保存されます。
DHT
DHT (分散ハッシュ テーブル) 分散ハッシュ テーブル。トラッカーの置き換えに使用されます。 dht を実装するには、Kademlia アルゴリズムなど、多くのアルゴリズムがあります。
いくつかの概念:
1.nodeid dht ネットワーク内の各ノード ID は 160 ビットです。
2.XOR 2 つのノード間の距離は XOR を使用して計算されます
3.ルーティング テーブルルーティング テーブル
ここでは実装が主なので、原理部分についてはインターネット上に多くの情報があります。
実装方法については、それを参照してください。 it
シード検索を実装するには 2 つのステップがあります。最初のステップは、インターネット上のシード情報をクロールするために使用されるクローラーです。2 番目のステップは、検索に参加することです。
次の知識が必要です: シード、bittorrent dht プロトコル、ベンコードされた
p2p に関して言えば、.torrent の結果であるファイルの種類であるシードについて言及する必要があります。誰もが bt Torrent を使用してファイルをダウンロードしたことがあると思いますが、ダウンロードされたファイルは bittorrent プロトコルを使用します。では、インターネット上で種子を収集するにはどうすればよいでしょうか?
bt シードに含まれる主なフィールド: https://segmentfault.com/a/1190000000681331
dht で取得されたシードは、トラッカーレス トレントと呼ばれます。代わりにノード属性を使用します。公式では、router.bittorrent.com をシードに追加したり、ルーティング テーブルに追加したりしないことが推奨されています。
1.dht からシードを取得する方法
シード情報を取得したい場合は、DHT プロトコルを深く理解する必要があります。 DHT プロトコルについて説明します。
詳細については、ここをクリックしてください。http://www.bittorrent.org/beps/bep_0005.html
ルーティング テーブルの実装方法:
ルーティング テーブルは、0 から 2 の 160 乗までのすべてのノード ID をカバーします。ルーティング テーブルはバケットで構成でき、各バケットはすべてのノードの一部をカバーします。
最初、ルーティング テーブルにはバケットが 1 つだけあり、すべてのノード ID をカバーしています。各バケットには最大 K 個のノードしか保持できません。現在の K 値は 8 です。バケットがいっぱいで、その中のすべてのノードが良好で、独自のノード ID がこのバケットにない場合、元のバケットは 2 つの新しいバケットに分割され、それぞれ 0..2159 をカバーします。および 2159..2160。
バケットがいっぱいになると、新しいノードは簡単に破棄され、その中のノードがオフラインになった場合は置き換えられます。過去 15 分間にノードに ping が送信されていない場合は、ノードに ping を実行します。応答が返されない場合は、ノードも置き換えられます。
各バケットには、このバケットのアクティビティを示す最終変更属性が必要です。このフィールドは次の状況で更新されます:
1. バケット内のノードに ping が送信され、応答があります
2. ノードがバケットに追加されました
3バケット内のノードが置き換えられました。
バケットが 15 分以内にこのフィールドを更新しない場合、バケット範囲内の ID がランダムに選択され、find_node 操作が実行されます。
KRPC プロトコル
メッセージは、dht ネットワークの KRPC プロトコルを通じて送信されます。
1.ping
ping クエリは主にハートビート チェックに使用されます
2.find_node
ノードの場合、相手は自身のルーティング テーブルから最も近い N 個のノードをクエリし、それらを返します。通常は 8
3.get_peers
ノードの所有者を見つけます。 infohash に基づく infohash ピアが見つかった場合、nodes
#4.announce_peer
を返し、他のピアにも infohash があることを伝えます。
上記の 4 つによりルーティング テーブルが更新されることに注意してください。
最初はルーティング テーブルにノードがないため、スーパー ノード (dht.transmissionbt.com など) から開始して、find_node リクエストを通じてノードを検索して追加する必要があります。返されたノードは find_node に使用されます。
私が自分で実装したルーティング テーブルは、上記のものとは少し異なります。
DHT ネットワークはデータ送信に udp を使用するため、upd ポートを開いて find_node リクエストを継続的に送信してルーティング テーブルを確立し、get_peers を通じてシードの infohash を取得するだけで済みます。そして、announce_peer。
dht ネットワークに参加すると、上で紹介した 4 つの方法でしかシード ファイルの infohash を取得できないため、infohash を通じてシードをダウンロードする必要もあります。 bep_009 を参照してくださいhttp://www.bittorrent.org/beps/bep_0009.html
主に bep_009 を使用してシードの名前フィールドを取得します。ファイル名フィールドを取得した後、インデックスに基づいてインデックスを作成できます。名前と情報ハッシュを使用して検索を提供します。 (ここでは主にマグネット リンクを構築します。マグネット リンクを使用すると、Thunder、Baidu Netdisk などにアクセスしてリソースをダウンロードできます)
ほとんどのマグネット リンク形式: Magnet:?xt=urn : btih:infohash
上記で紹介した方法は、infohash を取得してマグネット リンクを構築し、サードパーティ ソフトウェアを使用してダウンロードする方法ですが、もちろん BitTorrent プロトコルを使用して自分でダウンロードすることもできます。興味があれば、自分で勉強することもできます。
わかりました。上記は実装手順を簡単に紹介しただけです。多くの詳細や具体的な実装については言及されていません。私自身の言葉で言えば、いくつかの github dht プロジェクトを参照し、自分で実装しました。具体的なアドレスは次のとおりです。 :https://github.com/mistletoe9527/dht-spider
以上がJavaを使用してp2pシード検索機能を実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7569
7569
 15
1386
52
87
11
28
107
15
1386
52
87
11
28
107


 ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
ジャワのウェカ
Aug 30, 2024 pm 04:28 PM
Java の Weka へのガイド。ここでは、weka java の概要、使い方、プラットフォームの種類、利点について例を交えて説明します。

 Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
Java Springのインタビューの質問
Aug 30, 2024 pm 04:29 PM
この記事では、Java Spring の面接で最もよく聞かれる質問とその詳細な回答をまとめました。面接を突破できるように。
 Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8 Stream Foreachから休憩または戻ってきますか?
Feb 07, 2025 pm 12:09 PM
Java 8は、Stream APIを導入し、データ収集を処理する強力で表現力のある方法を提供します。ただし、ストリームを使用する際の一般的な質問は次のとおりです。 従来のループにより、早期の中断やリターンが可能になりますが、StreamのForeachメソッドはこの方法を直接サポートしていません。この記事では、理由を説明し、ストリーム処理システムに早期終了を実装するための代替方法を調査します。 さらに読み取り:JavaストリームAPIの改善 ストリームを理解してください Foreachメソッドは、ストリーム内の各要素で1つの操作を実行する端末操作です。その設計意図はです
 Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプ
Aug 30, 2024 pm 04:28 PM
Java での日付までのタイムスタンプに関するガイド。ここでは、Java でタイムスタンプを日付に変換する方法とその概要について、例とともに説明します。
 カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルの量を見つけるためのJavaプログラム
Feb 07, 2025 am 11:37 AM
カプセルは3次元の幾何学的図形で、両端にシリンダーと半球で構成されています。カプセルの体積は、シリンダーの体積と両端に半球の体積を追加することで計算できます。このチュートリアルでは、さまざまな方法を使用して、Javaの特定のカプセルの体積を計算する方法について説明します。 カプセルボリュームフォーミュラ カプセルボリュームの式は次のとおりです。 カプセル体積=円筒形の体積2つの半球体積 で、 R:半球の半径。 H:シリンダーの高さ(半球を除く)。 例1 入力 RADIUS = 5ユニット 高さ= 10単位 出力 ボリューム= 1570.8立方ユニット 説明する 式を使用してボリュームを計算します。 ボリューム=π×R2×H(4
 Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Tool Suiteで最初のSpring Bootアプリケーションを実行するにはどうすればよいですか?
Feb 07, 2025 pm 12:11 PM
Spring Bootは、Java開発に革命をもたらす堅牢でスケーラブルな、生産対応のJavaアプリケーションの作成を簡素化します。 スプリングエコシステムに固有の「構成に関する慣習」アプローチは、手動のセットアップを最小化します。
