

MySql のトランザクション分離レベルの詳細な紹介 (コード付き)

この記事では、MySql のトランザクション分離レベル (コード付き) を詳しく紹介します。一定の参考値があります。必要な友人は参照できます。お役に立てば幸いです。 . 役に立ちます。
1. トランザクション (ACID) の 4 つの特性
トランザクション分離レベルを理解する前に理解しておく必要があるトランザクションの 4 つの特性。
1. アトミック性
トランザクションの開始後、すべての操作は完了するか、または完了しません。トランザクションは分割できない全体です。トランザクションの実行中にエラーが発生した場合、トランザクションの整合性を確保するために、トランザクションが開始される前の状態にロールバックされます。原子の物理的説明と同様に、化学反応においてそれ以上分割できない基本的な粒子を指します。原子は化学反応において分割できません。
2. 一貫性
トランザクションの開始と終了後、データベースの整合性制約の正確性、つまりデータの整合性を保証できます。たとえば、古典的な送金の場合、A が B に送金するとき、A がその送金を差し引き、B が確実に送金を受け取るようにする必要があります。私の個人的な理解は、物理学におけるエネルギー保存に似ています。
3. 分離
トランザクション間の完全な分離。たとえば、A は、同時に多数の操作を行って口座金額が失われることを避けるために、銀行カードにお金を送金します。そのため、A の送金が完了するまで、このカードで他の操作を行うことはできません。
4. 耐久性
トランザクションがデータに与える影響は永続的です。一般的な説明は、トランザクションの完了後、データ操作をディスクに保存する必要がある (永続化) というものです。トランザクションは一度完了すると元に戻すことはできず、データベース操作の観点から言えば、一度完了したトランザクションをロールバックすることはできません。
2. トランザクションの同時実行の問題
インターネットの潮流の中で、プログラムの価値はもはや、伝統的な業界の複雑なビジネス ロジックを人々が解決できるようにすることではありません。ユーザーエクスペリエンスが最優先されるインターネット時代において、コードは地下鉄のXierqi駅でのプログラマーのスピード、スピード、スピードのようなものです。もちろん、座る方向を間違えてはいけないので、もともと西直門に行きたかったのに、東直門に行ってしまったのです(とりあえずこれが正しいとします)。従来の業界の複雑なビジネス ロジックと比較して、インターネットでは同時実行性がプログラムにもたらすスピードと情熱により多くの注意が払われています。もちろん、スピード違反には代償が伴います。同時トランザクションでは、注意しないと下手なプログラマーが逃げてしまいます。
1. ダーティ読み取り
は、無効なデータ読み取りとも呼ばれます。別のトランザクションによってまだコミットされていないデータを読み取るトランザクションは、ダーティ リードと呼ばれます。
例: トランザクション T1 はデータ行を変更しましたが、送信されていません。このとき、トランザクション T2 はトランザクション T1 によって変更されたデータを読み取りました。その後、トランザクション T1 が何らかの理由でロールバックされ、トランザクションT2 読み出しはダーティ データです。
2. 反復不可能な読み取り
同じトランザクション内で同じデータを複数回読み取ると、一貫性が失われます。
例: トランザクション T1 は特定のデータを読み取り、トランザクション T2 はそのデータを読み取りおよび変更し、T1 は読み取り値を確認するために再度データを読み取り、異なる結果が得られます。
3. 錯覚読書
説明するのは難しいので、例を挙げましょう:
倉庫管理では、管理者はバッチを与える必要があります。商品が倉庫管理に入る場合、当然ですが、倉庫に入る前に、正確性を確保するために以前の入庫記録があるかどうかを確認する必要があります。管理者Aが倉庫に商品が存在しないことを確認してから入庫した場合、管理者Bは手先が早くてすでに入庫してしまった場合。このとき、管理者 A は、その製品がすでに在庫にあることを発見しました。それはまるで幻の読書が起こったかのようで、それまで存在しなかった何かが、突然彼に現れたのだ。
注: 3 つのタイプの問題は理解するのが難しいようですが、ダーティ リーディングではデータの正確さに重点が置かれます。非再現性はデータの変更に焦点を当てますが、ファントム読み取りはデータの追加と削除に焦点を当てます。
3. MySql の 4 つのトランザクション分離レベル
前の章では、同時実行性が高い場合のトランザクションへの影響について学びました。トランザクションの 4 つの分離レベルは、上記の 3 つの問題の解決策です。
| 分離レベル | ダーティ リード | ##非再現性ファントム リーディング | |
| Yes | は | # です | |
| ##いいえ | はい | はい | Repeatable-read |
| No | No | Yes | #シリアル化可能 |
| #No | No | いいえ############### 4. 4 つの分離レベルの SQL デモ mysql バージョン: 5.6 ストレージ エンジン: InnoDB ツール: navicat テーブル ステートメント: CREATE TABLE `tb_bank` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(16) COLLATE utf8_bin DEFAULT NULL, `account` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (1, '小明', 1000); ログイン後にコピー 1. SQL でデモンストレーションする ------read-uncommitted ダーティ リーディング (2)read-uncommit によるダーティ リーディング いわゆるダーティ リーディングたとえば、2 つのトランザクションがあり、一方のトランザクションはもう一方のトランザクションのコミットされていないデータを読み取ることができます。 デモ手順: select @@tx_isolation;//查询当前事务隔离级别 set session transaction isolation level read uncommitted;//将事务隔离级别设置为 读未提交 ログイン後にコピー を実行します。 ② 両方のセッションでトランザクションがオープン start transaction;//开启事务 ログイン後にコピー ③ セッション 1 とセッション 2: 2 つの操作が実行される前の口座残高が 1000 select * from tb_bank where id=1;//查询结果为1000 ログイン後にコピー であることを証明します。 ④ セッション 2: この時点で、更新が行われたと仮定します。 session2 のものが最初に実行されます。 update tb_bank set account = account + 100 where id=1; ログイン後にコピー ⑤ session1: session1 は session2 がコミットする前に実行を開始します。 select * from tb_bank where id=1;//查询结果:1100 ログイン後にコピー ⑥ session2: 何らかの理由で転送が失敗し、トランザクションがロールバックされました。 rollback;//事务回滚 commit;//提交事务 ログイン後にコピー ⑦ この時点でセッション1の転送が始まり、セッション1は⑤のクエリ結果1100が正しいデータであると感じます。 update tb_bank set account=1100-200 where id=1; commit; ログイン後にコピー ⑧セッション 1 とセッション 2 のクエリ結果 select * from tb_bank where id=1;//查询结果:900 ログイン後にコピー この時点で、セッション 1 のダーティ リードにより最終データが不一致であることがわかりました。正しい結果は 800 であるはずです。 set session transaction isolation level read committed;//将隔离级别设置为 不可重复读 ログイン後にコピー select * from tb_bank where id=1;//查询结果为1000,这说明 不可重复读 隔离级别有效的隔离了两个会话的事务。 ログイン後にコピー READ COMMITTED 分離レベルでは、読み取りごとにスナップショットが再生成されるため、各スナップショットは最新となり、したがってトランザクション内の各 SELECT は他のコミットされたトランザクションによって加えられた変更も確認できます set session transaction isolation level read committed; ログイン後にコピー start transaction; ログイン後にコピー select * from tb_bank where id=1;//查询结果:1000 ログイン後にコピー update tb_bank set account = account+100 where id=1; select * from tb_bank where id=1;//查询结果:1100 ログイン後にコピー select * from tb_bank where id=1;//查询结果:1100。和③中查询结果对比,session1两次查询结果不一致。 ログイン後にコピー
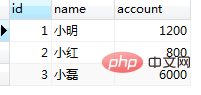
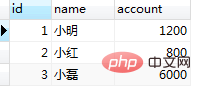
set session transaction isolation level repeatable read; ログイン後にコピー ⑤ session1 の 2 番目のクエリを繰り返します: select * from tb_bank where id=1;//查询结果为:1000 ログイン後にコピー 操作続行: update tb_bank set account=account+100 where id=1; ログイン後にコピー 在业务逻辑中,通常我们先获取数据库中的数据,然后在业务中判断该条件是否符合自己的业务逻辑,如果是的话,那么就可以插入一部分数据。但是mysql的快照读可能在这个过程中会产生意想不到的结果。 准备工作:插入两条数据 INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (2, '小红', 800); INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (3, '小磊', 6000); ログイン後にコピー (1)repeatable-read的幻读 ① 新建两个session都执行 set session transaction isolation level repeatable read; start transaction; select * from tb_bank;//查询结果:(这一步很重要,直接决定了快照生成的时间) ログイン後にコピー 结果都是:
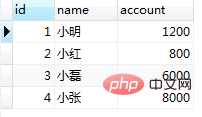
INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); select * from tb_bank; ログイン後にコピー
结果数据插入成功。此时session2提交事务 commit; ログイン後にコピー ③ session1进行插入 select * from tb_bank; ログイン後にコピー
结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。继续执行: INSERT INTO `demo`.`tb_bank`(`id`, `name`, `account`) VALUES (4, '小张', 8000); ログイン後にコピー
结果插入失败,提示该条已经存在,但是我们查询里面并没有这一条数据啊。为什么会插入失败呢? 因为①中的select语句生成了快照,之后的读操作(未加读锁)都是进行的快照读,即在当前事务结束前,所有的读操作的结果都是第一次快照读产生的快照版本。疑问又来了,为什么②步骤中的select语句读到的不是快照版本呢?因为update语句会更新当前事务的快照版本。具体参阅第五章节。 (2)repeatable-read利用当前读解决幻读重复(1)中的①② select * from tb_bank; ログイン後にコピー 结果session1中没有该条记录,这时按照我们通常的业务逻辑,此时应该是能成功插入id=4的数据。 select * from tb_bank lock in share mode;//采用当前读 ログイン後にコピー 结果:发现当前结果中已经有小张的账户信息了,按照业务逻辑,我们就不在继续执行插入操作了。 4、serializable隔离级别 在此级别下我们就不再做serializable的避免幻读的sql演示了,毕竟是给整张表都加锁的。 五、当前读和快照读 本想把当前读和快照读单开一片博客,但是为了把幻读总结明白,暂且在本章节先简单解释下快照读和当前读。后期再追加一篇MVCC,next-key的博客吧。。。 1、快照读:即一致非锁定读。 ① InnoDB存储引擎下,查询语句默认执行快照读。 ② RR隔离级别下一个事务中的第一次读操作会产生数据的快照。 ③ update,insert,delete操作会更新快照。 四种事务隔离级别下的快照读区别: ① read-uncommitted和read-committed级别:每次读都会产生一个新的快照,每次读取的都是最新的,因此RC级别下select结果能看到其他事务对当前数据的修改,RU级别甚至能读取到其他未提交事务的数据。也因此这两个级别下数据是不可重复读的。 ② repeatable-read级别:基于MVCC的并发控制,并发性能极高。第一次读会产生读数据快照,之后在当前事务中未发生快照更新的情况下,读操作都会和第一次读结果保持一致。快照产生于事务中,不同事务中的快照是完全隔离的。 ③ serializable级别:从MVCC并发控制退化为基于锁的并发控制。不区别快照读与当前读,所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。Serializable隔离级别下,读写冲突,因此并发度急剧下降。(锁表,不建议使用) 2、当前读:即一致锁定读。如何产生当前读 ① select ... lock in share mode ② select ... for update ③ update,insert,delete操作都是当前读。 读取之后,还需要保证当前记录不能被其他并发事务修改,需要对当前记录加锁。①中对读取记录加S锁 (共享锁),②③X锁 (排它锁)。 3、疑问总结① update,insert,delete操作为什么都是当前读? 简单来说,不执行当前读,数据的完整性约束就有可能遭到破坏。尤其在高并发的环境下。 分析update语句的执行步骤:update table set ... where ...; InnoDB エンジンは最初に where クエリを実行します。クエリされた結果セットは最初の項目から読み取りを開始し、次に更新操作を実行し、次に 2 番目のデータを読み取り、更新操作を実行します...つまり、更新を実行するたびに現在の読み取りが伴います。削除の場合も同様で、結局のところ、データを削除するには、まずデータが見つかる必要があります。挿入の場合は少し異なり、挿入操作を実行する前に一意のキーのチェックを実行する必要があります。 [関連する推奨事項: MySQL チュートリアル ]
|

以上がMySql のトランザクション分離レベルの詳細な紹介 (コード付き)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7803
7803
 15
1645
14
1402
52
1300
25
1236
29
15
1645
14
1402
52
1300
25
1236
29

 MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQL:世界で最も人気のあるデータベースの紹介
Apr 12, 2025 am 12:18 AM
MySQLはオープンソースのリレーショナルデータベース管理システムであり、主にデータを迅速かつ確実に保存および取得するために使用されます。その実用的な原則には、クライアントリクエスト、クエリ解像度、クエリの実行、返品結果が含まれます。使用法の例には、テーブルの作成、データの挿入とクエリ、および参加操作などの高度な機能が含まれます。一般的なエラーには、SQL構文、データ型、およびアクセス許可、および最適化の提案には、インデックスの使用、最適化されたクエリ、およびテーブルの分割が含まれます。
 Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheのデータベースに接続する方法
Apr 13, 2025 pm 01:03 PM
Apacheはデータベースに接続するには、次の手順が必要です。データベースドライバーをインストールします。 web.xmlファイルを構成して、接続プールを作成します。 JDBCデータソースを作成し、接続設定を指定します。 JDBC APIを使用して、接続の取得、ステートメントの作成、バインディングパラメーター、クエリまたは更新の実行、結果の処理など、Javaコードのデータベースにアクセスします。
 MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
MySQLの場所:データベースとプログラミング
Apr 13, 2025 am 12:18 AM
データベースとプログラミングにおけるMySQLの位置は非常に重要です。これは、さまざまなアプリケーションシナリオで広く使用されているオープンソースのリレーショナルデータベース管理システムです。 1)MySQLは、効率的なデータストレージ、組織、および検索機能を提供し、Web、モバイル、およびエンタープライズレベルのシステムをサポートします。 2)クライアントサーバーアーキテクチャを使用し、複数のストレージエンジンとインデックスの最適化をサポートします。 3)基本的な使用には、テーブルの作成とデータの挿入が含まれ、高度な使用法にはマルチテーブル結合と複雑なクエリが含まれます。 4)SQL構文エラーやパフォーマンスの問題などのよくある質問は、説明コマンドとスロークエリログを介してデバッグできます。 5)パフォーマンス最適化方法には、インデックスの合理的な使用、最適化されたクエリ、およびキャッシュの使用が含まれます。ベストプラクティスには、トランザクションと準備された星の使用が含まれます
 なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
なぜMySQLを使用するのですか?利点と利点
Apr 12, 2025 am 12:17 AM
MySQLは、そのパフォーマンス、信頼性、使いやすさ、コミュニティサポートに選択されています。 1.MYSQLは、複数のデータ型と高度なクエリ操作をサポートし、効率的なデータストレージおよび検索機能を提供します。 2.クライアントサーバーアーキテクチャと複数のストレージエンジンを採用して、トランザクションとクエリの最適化をサポートします。 3.使いやすく、さまざまなオペレーティングシステムとプログラミング言語をサポートしています。 4.強力なコミュニティサポートを提供し、豊富なリソースとソリューションを提供します。
 MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
MySQLの役割:Webアプリケーションのデータベース
Apr 17, 2025 am 12:23 AM
WebアプリケーションにおけるMySQLの主な役割は、データを保存および管理することです。 1.MYSQLは、ユーザー情報、製品カタログ、トランザクションレコード、その他のデータを効率的に処理します。 2。SQLクエリを介して、開発者はデータベースから情報を抽出して動的なコンテンツを生成できます。 3.MYSQLは、クライアントサーバーモデルに基づいて機能し、許容可能なクエリ速度を確保します。
 DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerによるMySQLを開始する方法
Apr 15, 2025 pm 12:09 PM
DockerでMySQLを起動するプロセスは、次の手順で構成されています。MySQLイメージをプルしてコンテナを作成および起動し、ルートユーザーパスワードを設定し、ポート検証接続をマップしてデータベースを作成し、ユーザーはすべての権限をデータベースに付与します。
 Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは紹介例
Apr 18, 2025 pm 12:45 PM
Laravelは、Webアプリケーションを簡単に構築するためのPHPフレームワークです。次のような強力な機能を提供します。インストール:Laravel CLIを作曲家にグローバルにインストールし、プロジェクトディレクトリにアプリケーションを作成します。ルーティング:ルート/web.phpのURLとハンドラーの関係を定義します。ビュー:リソース/ビューでビューを作成して、アプリケーションのインターフェイスをレンダリングします。データベース統合:MySQLなどのデータベースとのすぐ外側の統合を提供し、移行を使用してテーブルを作成および変更します。モデルとコントローラー:モデルはデータベースエンティティを表し、コントローラーはHTTP要求を処理します。
 MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをCentos7にインストールする方法
Apr 14, 2025 pm 08:30 PM
MySQLをエレガントにインストールするための鍵は、公式のMySQLリポジトリを追加することです。特定の手順は次のとおりです。MYSQLの公式GPGキーをダウンロードして、フィッシング攻撃を防ぎます。 mysqlリポジトリファイルを追加:rpm -uvh https://dev.mysql.com/get/mysql80-community-rease-el7-3.noarch.rpm update yumリポジトリキャッシュ:yumアップデートインストールmysql:yumインストールmysql-server startup mysql sportin
