

負荷分散の基本的な考え方はシンプルです。サーバー クラスター内の負荷を可能な限り平均化することです。この考えに基づいて、私たちの通常のアプローチは、サーバーのフロントエンドにロードバランサーをセットアップすることです。ロード バランサーの役割は、要求された接続をアイドル状態の利用可能なサーバーにルーティングすることです。
図 1 は、大規模な Web サイトの負荷分散セットアップを示しています。 1 つは HTTP トラフィックを担当し、もう 1 つは MySQL アクセスを担当します。
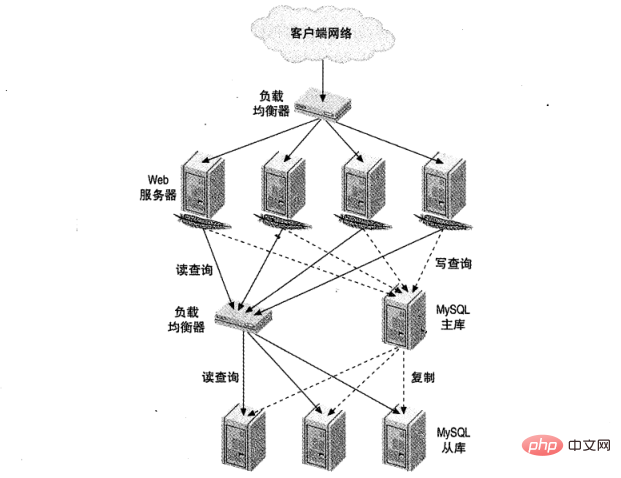
負荷分散には 5 つの共通の目的があります:
ロード バランシングとは、アプリケーションと MySQL の間に何かを直接設定することだと考える人もいます。しかし、実際にはこれが唯一の負荷分散方法ではありません。次に、一般的なアプリケーション直接接続方法とその注意点について説明します。 1.1 読み取りレプリケーションと書き込みレプリケーションの分離この方法では、最大の問題の 1 つである
ダーティ データが発生する可能性があります。典型的な例は、ユーザーがブログ投稿にコメントし、ページをリロードしても新しいコメントが表示されない場合です。 もちろん、ダーティ データの問題を理由に、読み取りと書き込みの分離を放棄することはできません。実際、多くのアプリケーションでは、ダーティ データに対する耐性が比較的高い可能性があるため、現時点ではこの方法を大胆に導入できます。
アプリケーションにダーティ データを許容できない少量のデータしかない場合は、許容できないすべての読み取りと書き込みを割り当てることができます。ダーティデータをマスターに送信します。他の読み取りクエリはスレーブに割り当てられます。この戦略は実装が簡単ですが、ダーティ データを許容するクエリがほとんどない場合、スタンバイ データベースを効果的に使用できない可能性があります。
2) ダーティ データに基づく分離これは、クエリベースの分離戦略に対する小さな改善です。スタンバイ データが最新かどうかを判断するためにアプリケーションにレプリケーションの遅延をチェックさせるなど、追加の作業が必要になります。多くのレポート アプリケーションはこの戦略を使用できます。夜間にロードされたデータをスタンバイ データベース インターフェイスにコピーするだけでよく、メイン データベースに完全に追いついたかどうかは気にしません。
3) セッション分離に基づく
この戦略は、ダーティ データ分離戦略よりも深いものです。ユーザーがデータを変更したかどうかを判断します。ユーザーは他のユーザーの最新データを見る必要はなく、自分の更新だけを見る必要があります。
具体的には、セッション層にフラグ ビットを設定して、ユーザーが更新を行ったかどうかを示すことができます。ユーザーが更新を行うと、ユーザーのクエリは一定期間メイン データベースに送信されます。 。 この戦略は、シンプルさと有効性の間で適切に妥協したものであり、より推奨される戦略です。
もちろん、十分なアイデアがある場合は、セッションベースの分離戦略とレプリケーション遅延監視戦略を組み合わせることができます。ユーザーが 10 秒前にデータを更新し、スタンバイ データベースの遅延がすべて 5 秒以内であれば、スタンバイ データベースからデータを大胆に読み取ることができます。セッション全体で同じスタンバイ データベースを選択することを忘れないでください。そうしないと、複数のスタンバイ データベースの遅延に一貫性がなくなると、ユーザーに迷惑がかかることになります。
4) グローバル バージョン/セッション分離に基づく
メイン データベースのログ座標を記録し、コピーされたログ座標と比較することで、スタンバイ データベースがデータを更新したかどうかを確認します。スタンバイデータベースの座標。アプリケーションが書き込み操作を指定している場合、トランザクションのコミット後に SHOW MASTER STATUS 操作を実行し、マスター ログの座標を変更されたオブジェクトまたはセッションのバージョン番号としてキャッシュに保存します。アプリケーションがスタンバイ・データベースに接続するときに、SHOW SLAVE STATUS を実行し、スタンバイ・データベース上の座標をキャッシュ内のバージョン番号と比較します。スタンバイ データベースがメイン データベースのレコード ポイントよりも新しい場合は、スタンバイ データベースが対応するデータを更新しており、安心して使用できることを意味します。
実際、多くの読み取り/書き込み分離戦略では、読み取りクエリの割り当てを決定するために レプリケーション レイテンシーの監視が必要です。ただし、SHOW SLAVE STATUS によって取得される Seconds_behind_master 列の値は遅延を正確に表していないことに注意してください。 Percona Toolkit の pt-heartbeat ツールを使用すると、遅延をより適切に監視できます。
一部の比較的単純なアプリケーションでは、さまざまな目的のために DNS を作成できます。最も簡単な方法は、読み取り専用サーバー (read.mysql-db.com) に 1 つの DNS 名を設定し、書き込み操作を担当するサーバー (write.mysql-db.com) に別の DNS 名を設定することです。スタンバイ データベースがプライマリ データベースを維持できる場合は、読み取り専用 DNS 名がスタンバイ データベースを指すようにし、それ以外の場合はプライマリ データベースを指すようにします。
この戦略は実装が非常に簡単ですが、DNS を完全に制御できないという大きな問題があります。
この戦略はより危険であり、/etc/hosts ファイルを変更することで DNS を完全に制御できないという問題を回避できるとしても、これは依然として理想的な戦略です。
サーバー間で仮想アドレスを転送することで負荷分散を実現します。 DNSを変更するのと同じような感じでしょうか?しかし、実際にはそれらは全く異なるものです。 IP アドレスを転送すると、DNS 名は変更されないままになります。ARP コマンドを使用して、IP アドレスの変更を迅速かつアトミックにローカル ネットワークに強制的に通知できます (ARP については知りません。ここを参照してください)。
より便利な手法は、各物理サーバーに固定 IP アドレスを割り当てることです。この IP アドレスはサーバー上で固定されており、変更されません。その後、各論理「サービス」(コンテナーとして理解できます) に仮想 IP アドレスを使用できます。
この方法では、アプリケーションを再構成することなく IP をサーバー間で簡単に転送できるため、実装が容易になります。
上記の戦略は、アプリケーションが MySQL サーバーに接続されていることを前提としていますが、多くの負荷分散では、ネットワーク通信のプロキシとしてミドルウェアが導入されます。一方ですべての通信を受け入れ、これらのリクエストをもう一方の指定されたサーバーに分散し、実行結果をリクエスト元のマシンに送り返します。図 2 は、このアーキテクチャを示しています。 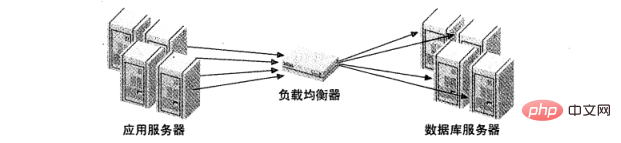
負荷分散ハードウェアとソフトウェアは数多くありますが、MySQL サーバー専用に設計されたものはほとんどありません。 Web サーバーは一般に負荷分散の必要性が高いため、多くの汎用負荷分散デバイスは HTTP をサポートし、他の用途のための基本的な機能はいくつかしか備えていません。
MySQL 接続は通常の TCP/IP 接続であるため、MySQL 上で多目的ロード バランサを使用できます。ただし、MySQL 固有の機能がないため、いくつかの制限があります。
どのサーバーが次の接続を受け入れるかを決定するために使用されるアルゴリズムが多数あります。各メーカーは独自の異なるアルゴリズムを持っており、一般的な方法は次のとおりです:
最も一般的なレプリケーション構造は、1 つのマスター データベースと複数のバックアップ データベースです。このアーキテクチャには拡張性がありませんが、いくつかの方法で負荷分散と組み合わせることで、より良い結果を達成できます。
実装し、急速な成長の可能性に備えて事前に計画を立てることです。 また、10,000 または 100,000 の同時実行数を満たすというパフォーマンスの正確な目標があるのと同じように、スケーラビリティについても
数値目標を設定することは理にかなっています。これにより、シリアル化や相互運用性などのオーバーヘッドの問題が、関連する理論を通じてアプリケーションに持ち込まれるのを回避できます。 MySQL の拡張戦略に関して言えば、一般的なアプリケーションが非常に大きなサイズに成長すると、通常はまず単一サーバーからスタンバイ データベースを備えたスケールアウト アーキテクチャに移行し、次にデータ シャーディングまたは機能パーティショニングに移行します。 。ここで注意していただきたいのは、「できるだけ早くシャードを作成し、できるだけ多くシャードを作成する」といったアドバイスを推奨しているわけではないことです。実際、シャーディングは複雑でコストがかかります。そして最も重要なことに、多くのアプリケーションではシャーディングがまったく必要ない可能性があります。シャーディングに多額の費用を費やすよりも、新しいハードウェアと MySQL の新しいバージョンの変更を確認する方が良いでしょう。おそらく、これらの新しい変更には驚かれるでしょう。
まとめ
直接接続と重い「分離」、イコライザーとアルゴリズムには限界があります。以上がMySQL によるロード バランシングを簡単な言葉で説明するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



