

mysql ストレージ エンジンの違いは何ですか?

MySQL のストレージ エンジンの違い: Innodb と myisam を例に挙げると、前者はトランザクションをサポートしますが、後者はサポートしません。前者は汎用性を重視し、より拡張された機能をサポートしますが、後者は主にパフォーマンスに重点を置きます。
INNODB
INNODB インデックスの実装
MyISAM と同じことは、InnoDB も B Tree を使用することです。 B-Treeインデックスを実装するためのデータ構造。大きな違いは、InnoDB ストレージ エンジンが B ツリー インデックスを実装するために「クラスター化インデックス」データ保存方法を使用していることです。いわゆる「集約」とは、データ行と隣接するキー値がまとめてコンパクトに保存されることを意味しますInnoDB では、リーフ ページ (16K) のレコードのみが集約される (つまり、クラスタード インデックスが一定の範囲のレコードを満たす) ため、隣接するキー値を含むレコードが大きく離れている可能性があることに注意してください。 InnoDB では、テーブルはインデックス構成テーブルと呼ばれます。InnoDB は主キーに従って B ツリーを構築します (主キーがない場合は、代わりに一意の空でないインデックスが選択されます)。主キーがない場合、代わりに一意で空でないインデックスが選択されます。そのようなインデックスの場合、InnoDB は主キーをクラスター化インデックスとして暗黙的に定義し、同時にリーフ ページには次の行レコード データが保存されます。テーブル全体 クラスター化インデックスのリーフ ノードはデータ ページと呼ぶこともできます 非リーフ ページも表示できます リーフ ページのスパース インデックスを実行します。 次の図は、InnoDB クラスター化インデックスの実装を示し、innoDB テーブルの構造も反映しています。InnoDB では、主キー インデックスとデータが分離されておらず、統合されていることがわかります。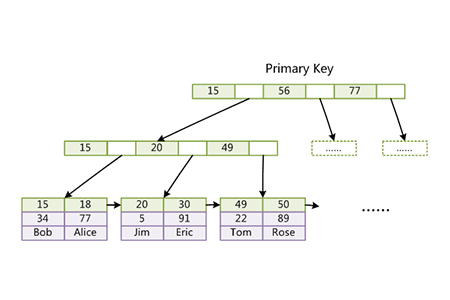
フル テーブル スキャン
InnoDB がフル テーブル スキャンを実行する場合、InnoDB は実際には順次に読み取らないため、効率的ではありません。ほとんどの場合、ランダムに読み取られます。 。フル テーブル スキャンを実行する場合、InnoDB は主キーの順序でページと行をスキャンします。これは、断片化されたテーブルを含むすべての InnoDB テーブルに適用されます。主キー ページ テーブル (主キーと行を格納するページ テーブル) が断片化されていない場合、読み取り順序が物理的な記憶順序に近いため、テーブル全体のスキャンは非常に高速になります。ただし、主キー ページが断片化されている場合、スキャンは非常に遅くなります。行レベル ロック
Oracle で提供される行ロック (行レベルでのロック) を提供します。 SELECT でのタイプ一貫性のある非ロック読み取り。また、InnoDB テーブルの行ロックは絶対的ではありません。SQL ステートメントの実行時に MySQL がスキャンする範囲を決定できない場合、InnoDB テーブルはテーブル全体もロックします。update table set num=1 where name like “%aaa%”
MYISAM
MyISAM インデックスの実装
各 MyISAM はディスク上に 3 つのファイルとして保存されます。最初のファイルの名前はテーブルの名前で始まり、拡張子はファイルの種類を示します。 MyISAM インデックス ファイル [.MYI (MYIndex)] とデータ ファイル [.MYD (MYData)] は分離されており、インデックス ファイルにはレコードが配置されているページのポインタ (物理的な場所) のみが保存されます。これらのアドレスを指定すると、ページが読み取られ、インデックス付きの行が読み取られます。まず構造図を見てみましょう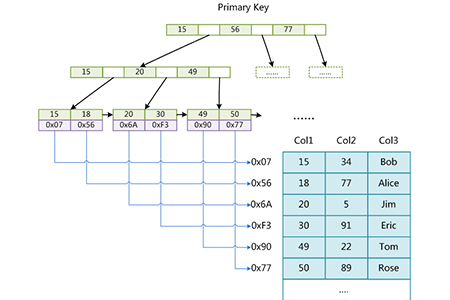
MyISAM はデフォルトでインデックスをメモリに読み取り、メモリ内で直接操作します;
テーブルレベルのロック要約: Innodb は汎用性を重視し、サポートされている拡張機能を比較します。関数は多く、myisam は主にパフォーマンスに重点を置いています
相違点1. InnoDB はトランザクションをサポートしますが、MyISAM はサポートしません。InnoDB の場合、すべての SQL 言語はトランザクションにカプセル化されます。デフォルトで自動的に送信されますが、これは速度に影響するため、begin と commit の間に複数の SQL ステートメントを入れてトランザクションを形成することをお勧めします;
2. InnoDB はクラスター化インデックスであり、データ ファイルは主キーが必要であり、主キーを使用したインデックス作成は非常に効率的です。ただし、補助インデックスには 2 つのクエリが必要です。最初に主キーをクエリし、次に主キーを介してデータをクエリします。したがって、主キーが大きすぎると、他のインデックスも大きくなるため、主キーは大きすぎないでください。 MyISAM は非クラスター化インデックスであり、データ ファイルは分離されており、インデックスにはデータ ファイルのポインタが保存されます。主キーインデックスと副キーインデックスは独立しています。
3. InnoDB はテーブル内の特定の行数を保存しないため、テーブルから select count(*) を実行する場合、テーブル全体のスキャンが必要です。 MyISAM は変数を使用してテーブル全体の行数を保存します。上記のステートメントを実行するときは、変数を読み取るだけで済みます。これは非常に高速です。
4. Innodb はフルテキスト インデックスをサポートしていません、MyISAM はフルテキスト インデックスをサポートしていますが、クエリ効率の点では MyISAM の方が優れています;
以上がmysql ストレージ エンジンの違いは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック



 mysql innodbとは何ですか
Apr 14, 2023 am 10:19 AM
mysql innodbとは何ですか
Apr 14, 2023 am 10:19 AM
InnoDB は、MySQL のデータベース エンジンの 1 つです。現在、MySQL のデフォルトのストレージ エンジンであり、MySQL AB によるバイナリ リリースの標準の 1 つです。InnoDB は、二重トラック認証システムを採用しており、1 つは GPL 認証、もう 1 つは独自のソフトウェアです認可。 InnoDB は、トランザクション データベースに推奨されるエンジンであり、トランザクション セキュリティ テーブル (ACID) をサポートしています。InnoDB は、同時実行性を最大限にサポートできる行レベルのロックをサポートしています。行レベルのロックは、ストレージ エンジン層によって実装されます。
 MySQL がバイナリ コンテンツから InnoDB 行フォーマットを認識する方法
Jun 03, 2023 am 09:55 AM
MySQL がバイナリ コンテンツから InnoDB 行フォーマットを認識する方法
Jun 03, 2023 am 09:55 AM
InnoDB はディスク上のテーブルにデータを保存するストレージ エンジンであるため、シャットダウンして再起動した後でもデータは残ります。データ処理の実際のプロセスはメモリ内で発生するため、ディスク内のデータをメモリにロードする必要があります。書き込みまたは変更要求を処理している場合は、メモリ内の内容もディスクに更新する必要があります。また、ディスクへの読み取りおよび書き込みの速度は非常に遅いことがわかっており、これはメモリ内での読み取りおよび書き込みとは数桁異なります。したがって、テーブルから特定のレコードを取得したい場合、InnoDB ストレージ エンジンは読み取りを行う必要がありますか?ディスクからレコードを 1 つずつ取り出しますか? InnoDB で採用されている方法は、データを複数のページに分割し、ページをディスクとメモリ間の対話の基本単位として使用することです。InnoDB のページのサイズは通常 16 です。
 MySQL の innoDB でのファントム読み取りを解決する方法
May 27, 2023 pm 03:34 PM
MySQL の innoDB でのファントム読み取りを解決する方法
May 27, 2023 pm 03:34 PM
1. MySQL トランザクション分離レベル これら 4 つの分離レベルでは、複数のトランザクションの同時実行性の競合がある場合、ダーティ リード、非反復読み取り、ファントム読み取りの問題が発生する可能性があり、innoDB は反復可能読み取り分離レベル モードでこれらの問題を解決します。ファントム リーディングの説明、2. ファントム リーディングとは? ファントム リーディングとは、図に示すように、同じトランザクション内で同じ範囲を前後 2 回クエリしたときに得られる結果が矛盾することを意味します。 . この時点では、条件を満たすデータは 1 つだけです。2 番目のトランザクションでは、データの行を挿入して送信します。最初のトランザクションが再度クエリを実行すると、取得される結果は、前のトランザクションの結果より 1 つ多くなります。最初のクエリ。データ。最初のトランザクションの最初と 2 番目のクエリは両方とも同じであることに注意してください
 mysql innodb例外を処理する方法
Apr 17, 2023 pm 09:01 PM
mysql innodb例外を処理する方法
Apr 17, 2023 pm 09:01 PM
1. mysql をロールバックして再インストールします。このデータを他の場所からインポートする手間を避けるために、まず現在のライブラリ (/var/lib/mysql/location) のデータベース ファイルのバックアップを作成します。次に、Perconaserver 5.7 パッケージをアンインストールし、元の 5.1.71 パッケージを再インストールし、mysql サービスを開始すると、Unknown/unsupportedtabletype:innodb というプロンプトが表示され、正常に開始できませんでした。 11050912:04:27InnoDB:バッファプールの初期化中、サイズ=384.0M11050912:04:27InnoDB:完了
 MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価
Jul 26, 2023 am 11:25 AM
MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価
Jul 26, 2023 am 11:25 AM
MySQL ストレージ エンジンの選択の比較: InnoDB、MyISAM、およびメモリのパフォーマンス インデックスの評価 はじめに: MySQL データベースでは、ストレージ エンジンの選択がシステム パフォーマンスとデータの整合性において重要な役割を果たします。 MySQL はさまざまなストレージ エンジンを提供します。最も一般的に使用されるエンジンには、InnoDB、MyISAM、Memory などがあります。この記事では、これら 3 つのストレージ エンジンのパフォーマンス指標を評価し、コード例を通じて比較します。 1. InnoDB エンジン InnoDB は私のものです
 MyISAM および InnoDB ストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法
May 11, 2023 pm 06:51 PM
MyISAM および InnoDB ストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法
May 11, 2023 pm 06:51 PM
MySQL は広く使用されているデータベース管理システムであり、ストレージ エンジンが異なればデータベースのパフォーマンスに与える影響も異なります。 MyISAM と InnoDB は、MySQL で最もよく使用される 2 つのストレージ エンジンですが、これらには異なる特性があり、不適切に使用するとデータベースのパフォーマンスに影響を与える可能性があります。この記事では、これら 2 つのストレージ エンジンを使用して MySQL のパフォーマンスを最適化する方法を紹介します。 1. MyISAM ストレージ エンジン MyISAM は、MySQL で最も一般的に使用されるストレージ エンジンであり、その利点は高速であり、ストレージ スペースが小さいことです。 MyISA
 MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析
Jul 26, 2023 am 10:01 AM
MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析
Jul 26, 2023 am 10:01 AM
MySQL ストレージ エンジンの読み取りパフォーマンスを向上させるためのヒントと戦略: MyISAM と InnoDB の比較分析 はじめに: MySQL は、最も一般的に使用されているオープン ソース リレーショナル データベース管理システムの 1 つで、主に大量の構造化データの保存と管理に使用されます。ほとんどのアプリケーションでは読み取り操作が主な操作であるため、アプリケーションではデータベースの読み取りパフォーマンスが非常に重要になることがよくあります。この記事では、MySQL ストレージ エンジンの読み取りパフォーマンスを向上させる方法に焦点を当て、一般的に使用される 2 つのストレージ エンジンである MyISAM と InnoDB の比較分析に焦点を当てます。
 INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBフルテキスト検索機能を説明します。
Apr 02, 2025 pm 06:09 PM
INNODBのフルテキスト検索機能は非常に強力であり、データベースクエリの効率と大量のテキストデータを処理する能力を大幅に改善できます。 1)INNODBは、倒立インデックスを介してフルテキスト検索を実装し、基本的および高度な検索クエリをサポートします。 2)一致を使用してキーワードを使用して、ブールモードとフレーズ検索を検索、サポートします。 3)最適化方法には、単語セグメンテーションテクノロジーの使用、インデックスの定期的な再構築、およびパフォーマンスと精度を改善するためのキャッシュサイズの調整が含まれます。
