

mysqlデータベースを最適化する方法

mysql データベースを最適化する方法: Index インデックスを確立し、選択ステートメントの使用を減らし、クエリ キャッシュを有効にし、適切なストレージ エンジンを選択し、接続する where 句での または の使用を避け、大量のデータを返さないようにします。
データ中心のアプリケーションの場合、データベースの品質はプログラムのパフォーマンスに直接影響するため、データベースのパフォーマンスは非常に重要です。したがって、誰もが mysql データベースの最適化操作を理解する必要があります。この記事では主に mysql データベースの一般的な最適化操作を要約します。以下ではこれ以上の詳細は説明しません。詳細な紹介を見てみましょう。
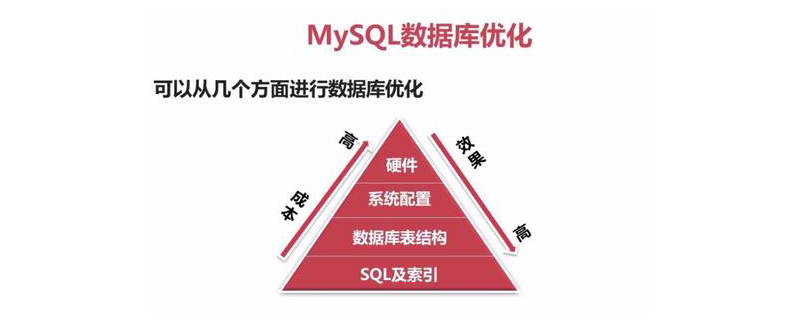
1. Index インデックス
Put Index first. 言うまでもなく、私たちはこの最適化手法をひっそりと行ってきました。主キーインデックスです。場合によっては気にしないこともありますが、適切なインデックスが定義されていれば、データベースのクエリのパフォーマンス (速度) は数倍、場合によっては数十倍も向上します。
2. SELECT は控えめに使用する*
データベースにクエリを実行するときに、クエリしたいものをすべて選択する人もいますが、これは不適切な動作です。すべてではなく、使用したいデータを取得する必要があります。選択すると、Web サーバーの負荷が増加し、ネットワーク送信の負荷が増加し、クエリ速度が自然に低下するためです。
3. EXPLAIN SELECT
この関数を見たことがない人も多いと思われますが、使用することを強くお勧めします。 Explain では、mysql がインデックスを使用して選択ステートメントを処理し、テーブルを結合する方法を示します。これは、より適切なインデックスを選択し、より最適化されたクエリ ステートメントを作成するのに役立ちます。主な用途は、select の前に Explain を追加することです。
EXPLAIN SELECT [查找字段名] FROM tab_name ...
4. クエリ キャッシュをオンにする
ほとんどの MySQL サーバーではクエリ キャッシュがオンになっています。これはパフォーマンスを向上させる最も効果的な方法の 1 つであり、MySQL データベース エンジンによって処理されます。同じクエリの多くが複数回実行されると、これらのクエリ結果はキャッシュに配置されるため、後続の同一のクエリではテーブルを操作する必要がなく、キャッシュされた結果に直接アクセスできます。
最初のステップは、query_cache_type を ON に設定し、システム変数 have_query_cache が利用可能かどうかをクエリすることです:
show variables like 'have_query_cache'
その後、クエリ キャッシュと制御にメモリ サイズを割り当てます。キャッシュされたクエリ結果の最大値。関連する操作は構成ファイルで変更されます。
5. NOT NULL を使用します
アプリケーションで NULL を保存する必要がない場合でも、多くのテーブルには NULL (NULL 値) になる可能性のある列が含まれています。 NULL は列のデフォルトのプロパティです。本当に NULL 値を格納する必要がない限り、通常は列を NOT NULL として指定するのが最善です。
クエリに NULL 列が含まれる場合、NULL 列によりインデックス、インデックス統計、値の比較がより複雑になるため、MySQL の最適化がより困難になります。 NULL にできるカラムはより多くのストレージ領域を使用するため、MySQL での特別な処理が必要になります。 NULL 許容カラムにインデックスが付けられると、各インデックス レコードに追加のバイトが必要になります。MyISAM では、これによって固定サイズのインデックス (整数カラムが 1 つだけあるインデックスなど) が可変サイズのインデックスになることもあります。
通常、NULL 列を NOT NULL に変更することによってもたらされるパフォーマンスの向上は比較的小さいため、(チューニング時に) 最初に既存のスキーマでこの状況を検索して変更する必要はありません。確かにこれは問題を引き起こします。ただし、列にインデックスを構築する予定がある場合は、列が NULL になるように設計しないようにする必要があります。もちろん例外もありますが、たとえば、InnoDB は NULL 値の格納に別のビットを使用するため、スパース データのスペース効率が良いことは言及する価値があります。ただし、これは MyISAM には当てはまりません。
6. ストレージエンジンの選択
MyISAM と InnoDB の選択方法ですが、トランザクション処理や外部キーが必要な場合は InnoDB の方が良いかもしれません。フルテキスト インデックスが必要な場合は、システムに組み込まれている MyISAM が通常は適切な選択となりますが、実際には 200 万行のレコードを頻繁にテストすることはありません。したがって、多少遅くても、Sphinx を使用して InnoDB からフルテキスト インデックスを取得できます。
データのサイズは、どのストレージ エンジンを選択するかに影響を与える重要な要素です。大規模なデータ セットでは、トランザクション処理と障害回復がサポートされている InnoDB が選択される傾向があります。データベースのサイズによって障害回復時間の長さが決まります。InnoDB はデータ回復にトランザクション ログを使用できるため、より高速になります。 MyISAM ではこれらの処理に数時間、場合によっては数日かかる場合がありますが、InnoDB では数分しかかかりません。
データベース テーブルを操作する習慣も、パフォーマンスに大きく影響する要因となる可能性があります。例: COUNT() は MyISAM テーブルでは非常に高速ですが、InnoDB テーブルでは苦痛になる可能性があります。 InnoDB では主キー クエリは非常に高速ですが、主キーが長すぎるとパフォーマンスの問題が発生することに注意する必要があります。多数の挿入ステートメントは MyISAM で高速化されますが、更新は InnoDB で高速化されます (特に同時実行量が多い場合)。
所以,到底你检使用哪一个呢?根据经验来看,如果是一些小型的应用或项目,那么MyISAM也许会更适合。当然,在大型的环境下使用MyISAM也会有很大成功的时候,但却不总是这样的。如果你正在计划使用一个超大数据量的项目,而且需要事务处理或外键支持,那么你真的应该直接使用InnoDB方式。但需要记住InnoDB的表需要更多的内存和存储,转换100GB的MyISAM 表到InnoDB 表可能会让你有非常坏的体验。
七、避免在 where 子句中使用 or 来连接
如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10 union all select id from t where Name = 'admin'
八、多使用varchar/nvarchar
使用varchar/nvarchar代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
九、避免大数据量返回
这里要考虑使用limit,来限制返回的数据量,如果每次返回大量自己不需要的数据,也会降低查询速度。
十、where子句优化
where 子句中使用参数,会导致全表扫描,因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
应尽量避免在 where 子句中对字段进行表达式操作,避免在where子句中对字段进行函数操作这将导致引擎放弃使用索引而进行全表扫描。不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
相关学习推荐:mysql教程(视频)
以上がmysqlデータベースを最適化する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7681
7681
 15
1393
52
1209
24
91
11
15
1393
52
1209
24
91
11

 新しい Win11 コンピューターを受け取った後に設定を最適化し、パフォーマンスを向上させるにはどうすればよいですか?
Mar 03, 2024 pm 09:01 PM
新しい Win11 コンピューターを受け取った後に設定を最適化し、パフォーマンスを向上させるにはどうすればよいですか?
Mar 03, 2024 pm 09:01 PM
新しいコンピュータを受け取った後、パフォーマンスをセットアップして最適化するにはどうすればよいですか? ユーザーは、[プライバシーとセキュリティ] を直接開き、[全般] (広告 ID、ローカル コンテンツ、アプリケーションの起動、推奨事項の設定、生産性向上ツール) をクリックするか、ローカル グループ ポリシーを直接開くことができます。新しい Win11 パソコンを受け取った後に、設定を最適化し、パフォーマンスを向上させる方法について詳しくご紹介します。 新しい Win11 パソコンを受け取った後に、設定を最適化し、パフォーマンスを向上させる方法について詳しくご紹介します。 1 つ: 1. [Win+i] ボタンを押します。 ] キーの組み合わせを押して設定を開き、左側の [プライバシーとセキュリティ] をクリックし、[右側のツールの Windows アクセス許可の下の一般 (広告 ID、ローカル コンテンツ、アプリの起動、設定の提案、生産性)] をクリックします。方法 2
 詳細な解釈: なぜ Laravel はカタツムリのように遅いのでしょうか?
Mar 07, 2024 am 09:54 AM
詳細な解釈: なぜ Laravel はカタツムリのように遅いのでしょうか?
Mar 07, 2024 am 09:54 AM
Laravel は人気のある PHP 開発フレームワークですが、カタツムリのように遅いと批判されることがあります。 Laravel の速度が満足できない原因は一体何でしょうか?この記事では、Laravel がカタツムリのように遅い理由をさまざまな側面から詳細に説明し、読者がこの問題をより深く理解できるように、具体的なコード例と組み合わせて説明します。 1. ORM クエリのパフォーマンスの問題 Laravel では、ORM (オブジェクト リレーショナル マッピング) は非常に強力な機能です。
 Laravelのパフォーマンスボトルネックを解読:最適化テクニックを完全公開!
Mar 06, 2024 pm 02:33 PM
Laravelのパフォーマンスボトルネックを解読:最適化テクニックを完全公開!
Mar 06, 2024 pm 02:33 PM
Laravelのパフォーマンスボトルネックを解読:最適化テクニックを完全公開! Laravel は人気のある PHP フレームワークとして、開発者に豊富な機能と便利な開発エクスペリエンスを提供します。ただし、プロジェクトのサイズが大きくなり、訪問数が増加すると、パフォーマンスのボトルネックという課題に直面する可能性があります。この記事では、開発者が潜在的なパフォーマンスの問題を発見して解決できるように、Laravel のパフォーマンス最適化テクニックについて詳しく説明します。 1. Eloquent の遅延読み込みを使用したデータベース クエリの最適化 Eloquent を使用してデータベースにクエリを実行する場合は、次のことを避けてください。
 C++ プログラムの最適化: 時間の複雑さを軽減する手法
Jun 01, 2024 am 11:19 AM
C++ プログラムの最適化: 時間の複雑さを軽減する手法
Jun 01, 2024 am 11:19 AM
時間計算量は、入力のサイズに対するアルゴリズムの実行時間を測定します。 C++ プログラムの時間の複雑さを軽減するためのヒントには、適切なコンテナー (ベクター、リストなど) を選択して、データのストレージと管理を最適化することが含まれます。クイックソートなどの効率的なアルゴリズムを利用して計算時間を短縮します。複数の操作を排除して二重カウントを削減します。条件分岐を使用して、不必要な計算を回避します。二分探索などのより高速なアルゴリズムを使用して線形探索を最適化します。
 Golang の GC 最適化戦略に関するディスカッション
Mar 06, 2024 pm 02:39 PM
Golang の GC 最適化戦略に関するディスカッション
Mar 06, 2024 pm 02:39 PM
Golang のガベージ コレクション (GC) は、開発者の間で常に話題になっています。高速プログラミング言語として、Golang の組み込みガベージ コレクターはメモリを適切に管理できますが、プログラムのサイズが大きくなるにつれて、パフォーマンスの問題が発生することがあります。この記事では、Golang の GC 最適化戦略を検討し、いくつかの具体的なコード例を示します。 Golang のガベージ コレクション Golang のガベージ コレクターは同時マークスイープ (concurrentmark-s) に基づいています。
 Laravel パフォーマンスのボトルネックが明らかに: 最適化ソリューションが明らかに!
Mar 07, 2024 pm 01:30 PM
Laravel パフォーマンスのボトルネックが明らかに: 最適化ソリューションが明らかに!
Mar 07, 2024 pm 01:30 PM
Laravel パフォーマンスのボトルネックが明らかに: 最適化ソリューションが明らかに!インターネット技術の発展に伴い、Web サイトやアプリケーションのパフォーマンスの最適化がますます重要になってきています。人気の PHP フレームワークである Laravel は、開発プロセス中にパフォーマンスのボトルネックに直面する可能性があります。この記事では、Laravel アプリケーションが遭遇する可能性のあるパフォーマンスの問題を調査し、開発者がこれらの問題をより適切に解決できるように、いくつかの最適化ソリューションと具体的なコード例を提供します。 1. データベース クエリの最適化 データベース クエリは、Web アプリケーションにおける一般的なパフォーマンスのボトルネックの 1 つです。存在する
 WIN7システムのスタートアップ項目を最適化する方法
Mar 26, 2024 pm 06:20 PM
WIN7システムのスタートアップ項目を最適化する方法
Mar 26, 2024 pm 06:20 PM
1. デスクトップでキーの組み合わせ (win キー + R) を押してファイル名を指定して実行ウィンドウを開き、[regedit] と入力して Enter キーを押して確定します。 2. レジストリ エディターを開いた後、[HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionExplorer] をクリックして展開し、ディレクトリに Serialize 項目があるかどうかを確認します。ない場合は、エクスプローラーを右クリックして新しい項目を作成し、Serialize という名前を付けます。 3. 次に、「シリアル化」をクリックし、右側のペインの空白スペースを右クリックして、新しい DWORD (32) ビット値を作成し、「Star」という名前を付けます。
 Vivox100s のパラメーター構成が明らかに: プロセッサーのパフォーマンスを最適化するには?
Mar 24, 2024 am 10:27 AM
Vivox100s のパラメーター構成が明らかに: プロセッサーのパフォーマンスを最適化するには?
Mar 24, 2024 am 10:27 AM
Vivox100s のパラメーター構成が明らかに: プロセッサーのパフォーマンスを最適化するには?テクノロジーが急速に発展する今日、スマートフォンは私たちの日常生活に欠かせないものとなっています。スマートフォンの重要な部分であるプロセッサのパフォーマンスの最適化は、携帯電話のユーザー エクスペリエンスに直接関係します。注目度の高いスマートフォンとして、Vivox100s のパラメータ構成は多くの注目を集めており、特にプロセッサー性能の最適化はユーザーからの注目を集めています。プロセッサは携帯電話の「頭脳」として、携帯電話の動作速度に直接影響します。
