

検索エンジンによるウェブサイトの掲載を拒否する方法

検索エンジンによる Web サイトの組み込みを拒否する方法: head タグにコンテンツ [<meta name="robots" content="noarchive">] を追加して、検索エンジンが Web サイトをクロールしないようにすることができます。 Web ページのスナップショットを表示します。

新しい Web サイトを構築した後、検索エンジン スパイダーによってクロールされる Web サイトのコンテンツがよほど悪くない限り、検索エンジンは問題を解決する可能性が非常に高くなります。何らかの理由で検索エンジンに自分の Web サイトを含めたくない場合は、どうすればよいでしょうか?次の記事で説明します。
方法 1: robots.txt を設定する方法
検索エンジン スパイダーをブロックするために robots.txt を設定するために使用できます。では、robots.txt とは何ですか?
検索エンジンはスパイダー プログラムを使用して、インターネット上の Web ページに自動的にアクセスし、Web ページの情報を取得します。スパイダーが Web サイトにアクセスすると、まず Web サイトのルート ドメインに robots.txt というプレーン テキスト ファイルがあるかどうかを確認します。このファイルは、Web サイト上でスパイダーのクロール範囲を指定するために使用されます。 Web サイトに robots.txt を作成し、ファイル内で検索エンジンに含めたくない Web サイトの部分を宣言したり、検索エンジンに特定の部分のみを含めるよう指定したりできます。
robots.txt ファイルを使用する必要があるのは、Web サイトに検索エンジンによるインデックスを作成したくないコンテンツが含まれている場合のみであることに注意してください。検索エンジンにサイト上のすべてのコンテンツを含めたい場合は、robots.txt ファイルを作成しないでください。
robots.txt を使用して検索エンジンのスパイダーをブロックするにはどうすればよいですか?
検索エンジンはデフォルトで robots.txt プロトコルに準拠しています。robots.txt テキスト ファイルを作成し、Web サイトのルート ディレクトリに配置します。コードを次のように編集します:
User-agent: * Disallow: /
上記のコードを通じて、検索エンジンがこのサイトをクロールしたり、このサイトを含めたりしないように指示できます。また、上記のコードを使用する場合は注意してください。これにより、すべての検索エンジンがサイトのどの部分にもアクセスできなくなります。
Baidu にサイト全体を含めることだけを禁止したい場合は、次のコードを編集できます:
User-agent: Baiduspider Disallow: /
Google にサイト全体を含めることだけを禁止したい場合は、次のコードを編集できます。次のコード:
User-agent: Googlebot Disallow: /
方法 2: Web ページのコード メソッドを設定します
コード
と < の間に次のコードを追加します。 ;/head> を Web サイトのホームページに配置して、検索エンジンのクロールを防止します。 Web サイトを取得し、Web ページのスナップショットを表示します。<meta name="robots" content="noarchive">
Web サイトのホームページのコード
と の間に次のコードを追加して、Baidu 検索エンジンが Web サイトをクロールして Web ページのスナップショットを表示しないようにします。<meta name="Baiduspider" content="noarchive">
Web サイトのホームページのコード
と の間に次のコードを追加して、Google 検索エンジンが Web サイトをクロールして Web ページのスナップショットを表示しないようにします。うわー
以上が検索エンジンによるウェブサイトの掲載を拒否する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7530
7530
 15
1379
52
82
11
21
76
15
1379
52
82
11
21
76

 C言語を学べるサイトはありますか?
Jan 30, 2024 pm 02:38 PM
C言語を学べるサイトはありますか?
Jan 30, 2024 pm 02:38 PM
C 言語を学習するための Web サイト: 1. C Language Chinese Website; 2. Rookie Tutorial; 3. C Language Forum; 4. C Language Empire; 5. Script House; 6. Tianji.com; 7. Red and Black Alliance; 8, 51 自習ネットワーク; 9. リコウ; 10. C プログラミング。詳細な紹介: 1. C 言語中国語 Web サイトは、初心者向けの C 言語学習教材を提供することに特化した Web サイトであり、基本的な文法、ポインタ、配列、関数、構造体およびその他のモジュールを含む豊富なコンテンツが含まれています; 2. ルーキー チュートリアル、プログラミング学習などの総合サイトです。
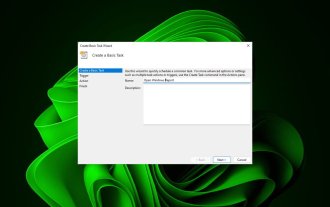 タスク スケジューラを使用して Web サイトを開く方法
Oct 02, 2023 pm 11:13 PM
タスク スケジューラを使用して Web サイトを開く方法
Oct 02, 2023 pm 11:13 PM
毎日ほぼ同じ時間に同じ Web サイトに頻繁にアクセスしますか?これにより、日常のタスクを実行する際に、複数のブラウザー タブを開いたまま長時間を費やし、ブラウザーが乱雑になる可能性があります。では、ブラウザを手動で起動せずに開いてみてはどうでしょうか?以下に示すように、これは非常にシンプルで、サードパーティのアプリをダウンロードする必要はありません。 Web サイトを開くためにタスク スケジューラを設定するにはどうすればよいですか?キーを押し、検索ボックスに「タスク スケジューラ」と入力し、[開く] をクリックします。 Windows 右側のサイドバーで、「基本タスクの作成」オプションをクリックします。 「名前」フィールドに、開きたい Web サイトの名前を入力し、「次へ」をクリックします。次に、「トリガー」で「時間頻度」をクリックし、「次へ」をクリックします。イベントを繰り返す時間を選択し、「次へ」をクリックします。有効を選択します
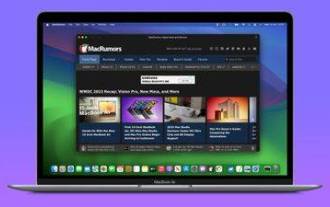 Web サイトをスタンドアロンの Mac アプリに変換する方法
Oct 12, 2023 pm 11:17 PM
Web サイトをスタンドアロンの Mac アプリに変換する方法
Oct 12, 2023 pm 11:17 PM
macOS Sonoma および Safari 17 では、Web サイトを「Web アプリ」に変換できます。Web アプリは Mac のドックに常駐し、ブラウザーを開かずに他のアプリと同様にアクセスできます。それがどのように機能するかを学び続けてください。 Apple の Safari ブラウザの新しいオプションのおかげで、頻繁にアクセスするインターネット上の Web サイトを、Mac のドックに常駐していつでもアクセスできるスタンドアロンの「Web アプリ」に変えることができるようになりました。この Web アプリは、他のアプリと同様に Mission Control および Stage Manager で動作し、Launchpad または SpotlightSearch 経由で開くこともできます。あらゆるウェブサイトを次のようなものに変える方法
 Baidu クラウド ディスク検索エンジンの入り口
Feb 27, 2024 pm 01:00 PM
Baidu クラウド ディスク検索エンジンの入り口
Feb 27, 2024 pm 01:00 PM
Baidu Cloud は多くのファイルを保存できるソフトウェアですが、Baidu Cloud Disk 検索エンジンへの入り口は何でしょうか?ユーザーは URL https://pan.baidu.com を入力して Baidu Cloud Disk にアクセスできます。Baidu Cloud Disk 検索エンジンへの最新の入り口を共有することで、詳細な紹介が得られます。以下は詳細な紹介です。見てください。 。 Baidu クラウド ディスク検索エンジンの入り口 1. Qianfan 検索 Web サイト: https://pan.qianfan.app ネットワーク ディスクをサポート: 集約検索、Alibaba、Baidu、Quark、Lanzuo、Tianyi、Xunlei ネットワーク ディスクの表示方法: ログインが必要、会社に従ってくださいアクティベーション コードを取得する利点: ネットワーク ディスクは包括的で、多くのリソースがあり、インターフェイスがシンプルです。 2. マオリパンソウのウェブサイト: alipansou.c
 Java開発:検索エンジンと全文検索機能の実装方法
Sep 21, 2023 pm 01:10 PM
Java開発:検索エンジンと全文検索機能の実装方法
Sep 21, 2023 pm 01:10 PM
Java 開発: 検索エンジンと全文検索機能の実装方法、具体的なコード例が必要です 検索エンジンと全文検索は、現代のインターネット時代において重要な機能です。これらは、ユーザーが必要なものをすぐに見つけられるようにするだけでなく、Web サイトやアプリのユーザー エクスペリエンスを向上させます。この記事では、Java を使用して検索エンジンと全文検索機能を開発する方法と、いくつかの具体的なコード例を紹介します。 Lucene ライブラリを使用した全文検索 Lucene は、ApacheSo によって開発されたオープンソースの全文検索エンジン ライブラリです。
 Google Chrome を設定して検索エンジンを変更する方法 ブラウザの検索エンジンを変更する方法
Mar 15, 2024 pm 12:49 PM
Google Chrome を設定して検索エンジンを変更する方法 ブラウザの検索エンジンを変更する方法
Mar 15, 2024 pm 12:49 PM
Google Chrome で検索エンジンを変更するにはどうすればよいですか? Google Chrome はユーザーの間で非常に人気のあるブラウザです。シンプルで使いやすいサービス、実用的なツール、その他の補助機能を備えているだけでなく、さまざまなユーザーのさまざまなニーズを満たすことができます。一般に、検索エンジンのデフォルトは Google です。交換するにはどのように設定すればよいですか?以下にその方法をシェアさせていただきます。交換方法 1. クリックして Google Chrome を開きます。 2. 三点アイコンをクリックしてメニュー インターフェイスを開きます。 3. [設定] オプションをクリックして、ブラウザの設定インターフェイスに入ります。 4. 設定インターフェースで検索エンジンモジュールを見つけます。 5. 「検索エンジンの管理」ボタンをクリックします。 6. 追加ボタンが表示されるので、この追加ボタンをクリックして検索エンジンを追加します。
 Google Chrome検索エンジンの使い方
Jan 04, 2024 am 11:15 AM
Google Chrome検索エンジンの使い方
Jan 04, 2024 am 11:15 AM
Google Chrome は非常に優れています。多くの友人がそれを使用しています。多くの友人が Google 独自の検索エンジンを使いたいと思っていますが、使い方がわかりません。ここでは、Google Chrome の Google 検索エンジンの使い方を簡単に説明します。バー。 Google Chrome で Google 検索エンジンを使用する方法: 1. Google Chrome を開き、右上隅にある [詳細] をクリックして設定を開きます。 2. 設定を入力したら、左側の「検索エンジン」をクリックします。 3. 検索エンジンが「Google」かどうかを確認します。 4. そうでない場合は、ドロップダウン ボタンをクリックして「Google」に変更します。
 Web サイト上のデッドリンクを確認する方法
Oct 30, 2023 am 09:26 AM
Web サイト上のデッドリンクを確認する方法
Oct 30, 2023 am 09:26 AM
Web サイト上のデッドリンクを確認する方法には、オンライン リンク ツールの使用、Web マスター ツールの使用、robots.txt ファイルの使用、ブラウザー開発者ツールの使用などがあります。詳細な紹介: 1. オンライン リンク ツールを使用します。LinkDeath、LinkDefender、Xenu などのオンライン デッド リンク検出ツールが多数あります。これらのツールは、Web サイト内のデッド リンクを自動的に検出できます。2. ウェブマスター ツールを使用します。ほとんどのウェブマスター ツール。 GoogleのウェブマスターツールやBaiduのウェブマスターツールなどはデッドリンク検出機能などを提供しています。
