
ヒープ ソート
ヒープ ソートは、ヒープのデータ構造を使用して設計されたソート アルゴリズムです。ヒープ ソートは選択ソートです。最悪の場合も最良の場合も、平均時間計算量は O です(nlogn)、これも不安定なソートです。まず、ヒープ構造を簡単に理解しましょう。
ヒープ
ヒープは、次のプロパティを持つ完全なバイナリ ツリーです: 各ノードの値は以上です。ノードの値はビッグトップヒープと呼ばれ、各ノードの値はその左右の子ノードの値以下であり、スモールトップヒープと呼ばれます。
推奨コース: PHP チュートリアル 。
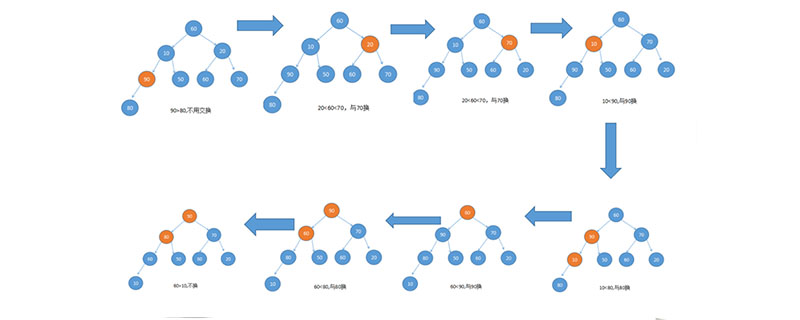
#以下に示すように:

#同時に、ヒープ内のノードにレイヤーごとに番号を付け、この論理マップを作成します。構造 配列では次のようになります

ヒープソートの基本的な考え方は次のとおりです:
ソートされるシーケンスを構築します。 big top Heap では、このときシーケンス全体の最大値はヒープの先頭のルート ノードになります。それを最後の要素と交換すると、最後の値が最大値になります。次に、残りの n-1 個の要素をヒープに再構築し、n 個の要素のうち次に小さい値が取得されるようにします。これを繰り返し実行すると、順序付けられたシーケンスが得られます。以上がヒープソートの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



