

クローラーの解析方法 4: PyQuery

多くの言語でクロールできますが、python に基づくクローラーはより簡潔で便利です。クローラーも Python 言語の重要な部分になっています。クローラーを解析する方法もたくさんあります。前回の記事では、 クローラーを解析する 3 番目の方法である正規表現 について説明しましたが、今日は別の方法である PyQuery について説明します。

PyQuery
PyQuery ライブラリは、非常に強力で柔軟な Web ページ解析ライブラリでもあります。経験があれば、それを使用できます。jQuery を使用したことがある場合は、PyQuery が最適です。PyQuery は、jQuery をモデルとした Python の厳密な実装です。構文は jQuery とほぼ同じなので、変なメソッドを覚えようとする必要はもうありません。
初期化中に渡すには、通常、文字列で渡す、URL で渡す、ファイルで渡すという 3 つの方法があります。
文字列の初期化
html =
<div>
<ul>
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
from pyquery
import PyQuery as pq
doc = pq(html)print(doc)
print(type(doc))
print(doc('li'))結果は次のとおりです。
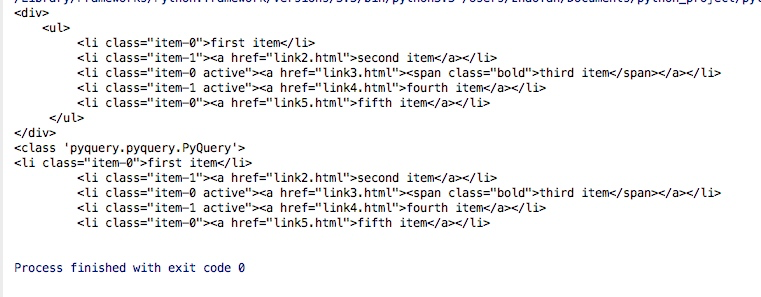
PyQuery は書くのが面倒なので、
from pyquery import PyQuery as pq
ここで、上記のコードの doc が実際には pyquery オブジェクトであることがわかります。doc を通じて要素を選択できます。実際、これは次のとおりです。 CSS セレクターなので、すべての CSS セレクター ルールを使用できます。直接 doc (タグ名) を実行して、タグのすべてのコンテンツを取得できます。クラスを取得したい場合は、doc('.class_name') を使用します。 ID、次に doc('#id_name') ...
URL 初期化
from pyquery import PyQuery as pq doc = pq(url="http://www.baidu.com",encoding='utf-8')print(doc('head'))
ファイル初期化
URL パラメータを渡すことができますまたは、 pq() 内のファイルパラメータ。もちろん、ここでのファイルは通常 HTML ファイルです。例: pq(filename='index.html')
Basic CSS selector
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''
from pyquery import PyQuery as pq
doc = pq(html)
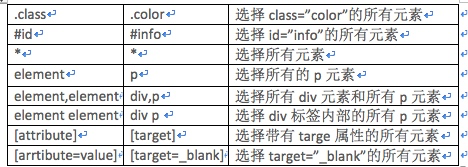
print(doc('#container .list li'))Oneここで注意する必要があるのは doc ('#container .list li') です。階層関係があれば、ここで 3 つが隣り合う必要はありません。一般的に使用される CSS は次のとおりです。セレクター メソッド:
要素の検索
子要素
children,find
Code例:
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
lis = items.find('li')
print(type(lis))
print(lis)実行結果は次のとおりです
結果から、pyquery で見つかった結果が実際には pyquery オブジェクトであることもわかり、検索を続行できます。上記のコードの ('li') は、ul 内のすべての li を検索することを意味します。
li = items.children() print(type(li)) print(li)
同時に、CSS セレクターは子でも使用できます
li2 = items.children('.active') print(li2)
親要素
parent,parents メソッド
例は次のとおりです:
html = '''<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()
print(type(container))
print(container)You can find the先祖ノード through .parents 内容と例は次のとおりです:
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
print(type(parents))
print(parents)結果は次のとおりです:結果から、コンテンツの 2 つの部分が返されたことがわかります。1 つは親ノードの情報で、もう 1 つは親ノードの親ノードの情報、つまり祖先ノードの情報です。
同様に、.parents を検索する場合、CSS セレクターを追加してコンテンツをフィルターすることもできます
兄弟要素siblings
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings())doc('.list .item-0.active') のコード .tem-0 と .active は互いに隣接しているため、マージされた関係にあり、条件を満たすものは 1 つだけ残ります。 3 番目の項目 そのタグ この方法で、.siblings を通じてすべての兄弟タグを取得できます。もちろん、ここには独自のタグは含まれません。
同様に、.siblings() では、CSS セレクターを介してフィルター処理することもできます。
単一要素
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
lis = doc('li').items()
print(type(lis))for li in lis:
print(type(li))
print(li)
属性の取得
pyquery object.attr(属性名)pyquery object.attr.属性名
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))
print(a.attr.href)したがって、ここで、属性値を取得するときに、直接 a.attr (属性名) または a.attr.attribute nameテキストを取得できることもわかります
多くの場合、html タグに含まれるテキスト情報を取得する必要があります。テキスト情報は .text()
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.text())によって取得できます。結果は次のようになります。

Get html
現在のタグに含まれる HTML 情報は、.html() を通じて取得できます。例は次のとおりです。
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())結果は次のとおりです。
 DOM 操作
DOM 操作
addClass、removeClass
熟悉前端操作的话,通过这两个操作可以添加和删除属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)attr,css
同样的我们可以通过attr给标签添加和修改属性,
如果之前没有该属性则是添加,如果有则是修改
我们也可以通过css添加一些css属性,这个时候,标签的属性里会多一个style属性
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)结果如下:

remove
有时候我们获取文本信息的时候可能并列的会有一些其他标签干扰,这个时候通过remove就可以将无用的或者干扰的标签直接删除,从而方便操作
html = '''<div class="wrap">
Hello, World
<p>This is a paragraph.</p>
</div>'''from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())结果如下:

以上がクローラーの解析方法 4: PyQueryの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7663
7663
 15
1393
52
1205
24
91
11
15
1393
52
1205
24
91
11

 PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPおよびPython:さまざまなパラダイムが説明されています
Apr 18, 2025 am 12:26 AM
PHPは主に手順プログラミングですが、オブジェクト指向プログラミング(OOP)もサポートしています。 Pythonは、OOP、機能、手続き上のプログラミングなど、さまざまなパラダイムをサポートしています。 PHPはWeb開発に適しており、Pythonはデータ分析や機械学習などのさまざまなアプリケーションに適しています。
 PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPとPythonの選択:ガイド
Apr 18, 2025 am 12:24 AM
PHPはWeb開発と迅速なプロトタイピングに適しており、Pythonはデータサイエンスと機械学習に適しています。 1.PHPは、単純な構文と迅速な開発に適した動的なWeb開発に使用されます。 2。Pythonには簡潔な構文があり、複数のフィールドに適しており、強力なライブラリエコシステムがあります。
 Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
Visual StudioコードはPythonで使用できますか
Apr 15, 2025 pm 08:18 PM
VSコードはPythonの書き込みに使用でき、Pythonアプリケーションを開発するための理想的なツールになる多くの機能を提供できます。ユーザーは以下を可能にします。Python拡張機能をインストールして、コードの完了、構文の強調表示、デバッグなどの関数を取得できます。デバッガーを使用して、コードを段階的に追跡し、エラーを見つけて修正します。バージョンコントロールのためにGitを統合します。コードフォーマットツールを使用して、コードの一貫性を維持します。糸くずツールを使用して、事前に潜在的な問題を発見します。
 Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
Windows 8でコードを実行できます
Apr 15, 2025 pm 07:24 PM
VSコードはWindows 8で実行できますが、エクスペリエンスは大きくない場合があります。まず、システムが最新のパッチに更新されていることを確認してから、システムアーキテクチャに一致するVSコードインストールパッケージをダウンロードして、プロンプトとしてインストールします。インストール後、一部の拡張機能はWindows 8と互換性があり、代替拡張機能を探すか、仮想マシンで新しいWindowsシステムを使用する必要があることに注意してください。必要な拡張機能をインストールして、適切に動作するかどうかを確認します。 Windows 8ではVSコードは実行可能ですが、開発エクスペリエンスとセキュリティを向上させるために、新しいWindowsシステムにアップグレードすることをお勧めします。
 Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学習曲線と使いやすさ
Apr 16, 2025 am 12:12 AM
Pythonは、スムーズな学習曲線と簡潔な構文を備えた初心者により適しています。 JavaScriptは、急な学習曲線と柔軟な構文を備えたフロントエンド開発に適しています。 1。Python構文は直感的で、データサイエンスやバックエンド開発に適しています。 2。JavaScriptは柔軟で、フロントエンドおよびサーバー側のプログラミングで広く使用されています。
 VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSCODE拡張機能は悪意がありますか?
Apr 15, 2025 pm 07:57 PM
VSコード拡張機能は、悪意のあるコードの隠れ、脆弱性の活用、合法的な拡張機能としての自慰行為など、悪意のあるリスクを引き起こします。悪意のある拡張機能を識別する方法には、パブリッシャーのチェック、コメントの読み取り、コードのチェック、およびインストールに注意してください。セキュリティ対策には、セキュリティ認識、良好な習慣、定期的な更新、ウイルス対策ソフトウェアも含まれます。
 PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPとPython:彼らの歴史を深く掘り下げます
Apr 18, 2025 am 12:25 AM
PHPは1994年に発信され、Rasmuslerdorfによって開発されました。もともとはウェブサイトの訪問者を追跡するために使用され、サーバー側のスクリプト言語に徐々に進化し、Web開発で広く使用されていました。 Pythonは、1980年代後半にGuidovan Rossumによって開発され、1991年に最初にリリースされました。コードの読みやすさとシンプルさを強調し、科学的コンピューティング、データ分析、その他の分野に適しています。
 ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
ターミナルVSCODEでプログラムを実行する方法
Apr 15, 2025 pm 06:42 PM
VSコードでは、次の手順を通じて端末でプログラムを実行できます。コードを準備し、統合端子を開き、コードディレクトリが端末作業ディレクトリと一致していることを確認します。プログラミング言語(pythonのpython your_file_name.pyなど)に従って実行コマンドを選択して、それが正常に実行されるかどうかを確認し、エラーを解決します。デバッガーを使用して、デバッグ効率を向上させます。
