

Redisを拡張する方法

チームのクラスメートは、Redis をプロジェクトのキャッシュとして使用し、ホットスポット データを Redis に保存しました。パフォーマンスを向上させるため、Redis を記述するときにパイプライン方式が使用されます。通常に使用すると、Redis のパフォーマンスとリソース使用量はプロジェクトの要件を満たしますが、アクセス数が増加すると、Redis の QPS は要件を満たします。 , しかし、CPU 使用率が高いです。90% に達していますが、通常は 30% しかありません。ご存知のとおり、Redis は単一プロセスであり、1 つの CPU コアしか占有できません。フルになると 100% になります。使用できません。 CPU が 100% に達すると、必然的にパフォーマンスのボトルネックが発生します。どうやって対処すればいいのでしょうか?

Redis ビデオ チュートリアル 」
オプション 1:
最初に思いつくのは、Redis サーバーの数を増やし、クライアントに保存されているキーに対してハッシュ操作を実行し、それらを別の Redis サーバーに保存することです。読み取り時には、同じハッシュ操作が実行されて検索されます。問題は解決しますが、欠点もあります: 最初に、クライアントはコードを変更する必要があります;2 番目に、クライアントはすべての Redis サーバーのアドレスを記憶する必要があります;このソリューションは使用できますが、コードを変更せずに拡張できますか?オプション 2:
クラスターを構築します。Redis サーバーで使用されるバージョンは 3.0 より低いため、クラスターはサポートされていません。プロキシのみを使用できます。 , そこで私は有名な Redis プロキシ twemproxy を思い出しました。 twemproxy はパフォーマンスも非常に良く、プロキシでありながらアクセスパフォーマンスへの影響が非常に小さく、Redis 作者も推奨しています。 twemproxy は使いやすいです。初心者でも 1 時間以内に使い方を学ぶことができます。重要なのは、クライアント コードを変更する必要がないことです。ほぼすべての Redis コマンドとパイプライン操作をサポートしています。クライアント コードを変更するだけで、設定ファイルに設定されている Redis IP とポートが、元の Redis IP とポートから twemproxy サービスの IP とポートに変更されます。 クライアントはハッシュの問題を考慮する必要はありません。twemproxy がこれらを行います。クライアントは Redis を操作するのと同じです。 「keys *」などの一部のコマンドはサポートされていないため、上記で「ほぼ」という言葉が使用されています私たちは、twemproxy とそれに続く 4 つの Redis マシンをすぐにデプロイしました。テストでは、CPU が次の 4 つの Redis ユニットの使用率は低下しましたが、twemproxy も単一プロセスであるという新たな問題が発生しました。パフォーマンスのボトルネックが再び twemproxy に発生します。オプション 3:
Redis へのアクセスは、プロデューサーとコンシューマーと同様に、書き込みと読み取りに分割されます。慎重に分析した結果、書き込みと読み取りが少ないことがわかりました。読み取りが比較的少なくなります。さらに、これにより読み取りと書き込み、プライマリへの書き込みとバックアップからの読み取りを分離できます。読み取りと書き込みが 2 つのサービスであるという状況が発生します。読み取りと書き込みを分離するには、構成を変更するだけです。これは非常に簡単に実行できるため、メイン Redis への圧力が分散されます。 Redis へのアクセス圧力は改善されましたが、長期的な解決策ではなく、たとえばイベントが開催されてデータ量が増加した場合、パフォーマンスのリスクは依然として残ります。 最後に採用された方法は、次の図に示すように、包括的なプラン 2 と 3 です。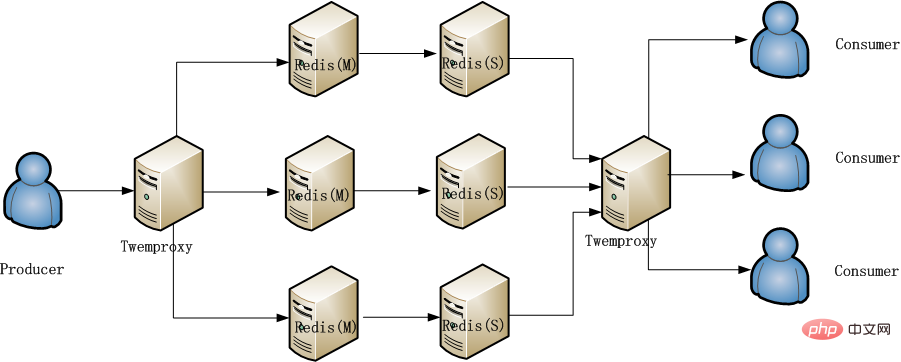
以上がRedisを拡張する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7524
7524
 15
1378
52
81
11
21
74
15
1378
52
81
11
21
74

 Redisクラスターでシャードキーを選択するにはどうすればよいですか?
Mar 17, 2025 pm 06:55 PM
Redisクラスターでシャードキーを選択するにはどうすればよいですか?
Mar 17, 2025 pm 06:55 PM
この記事では、Redisクラスターでシャードキーを選択し、パフォーマンス、スケーラビリティ、データ分布への影響を強調しています。重要な問題には、データ分布の確保、アクセスパターンの調整、一般的な間違いの回避lが含まれます。
 Redisで認証と承認を実装するにはどうすればよいですか?
Mar 17, 2025 pm 06:57 PM
Redisで認証と承認を実装するにはどうすればよいですか?
Mar 17, 2025 pm 06:57 PM
この記事では、Redisでの認証と承認の実装について説明し、ACLSを使用し、Redisを保護するためのベストプラクティスの有効化に焦点を当てています。また、Redisセキュリティを強化するためのユーザー許可とツールの管理をカバーしています。
 ジョブキューとバックグラウンド処理にRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:51 PM
ジョブキューとバックグラウンド処理にRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:51 PM
この記事では、ジョブキューとバックグラウンド処理にRedisを使用し、セットアップ、ジョブの定義、実行の詳細を使用しています。アトミックオペレーションやジョブの優先順位付けなどのベストプラクティスをカバーし、Redisが処理効率を高める方法を説明します。
 Redisでキャッシュ無効化戦略を実装するにはどうすればよいですか?
Mar 17, 2025 pm 06:46 PM
Redisでキャッシュ無効化戦略を実装するにはどうすればよいですか?
Mar 17, 2025 pm 06:46 PM
この記事では、時間ベースの有効期限、イベント駆動型の方法、バージョン化など、Redisでキャッシュの無効化を実装および管理するための戦略について説明します。また、キャッシュの有効期限と監視とオートマットのツールのベストプラクティスもカバーしています
 Redisクラスターのパフォーマンスを監視するにはどうすればよいですか?
Mar 17, 2025 pm 06:56 PM
Redisクラスターのパフォーマンスを監視するにはどうすればよいですか?
Mar 17, 2025 pm 06:56 PM
記事では、Redis CLI、Redis Insight、DatadogやPrometheusなどのサードパーティソリューションなどのツールを使用して、Redisクラスターのパフォーマンスと健康を監視しています。
 Pub/SubメッセージングにRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:48 PM
Pub/SubメッセージングにRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:48 PM
この記事では、Pub/サブメッセージング、セットアップ、ベストプラクティスのカバー、メッセージの信頼性の確保、監視のパフォーマンスにRedisを使用する方法について説明します。
 Webアプリケーションのセッション管理にRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:47 PM
Webアプリケーションのセッション管理にRedisを使用するにはどうすればよいですか?
Mar 17, 2025 pm 06:47 PM
この記事では、Webアプリケーションでのセッション管理にRedisを使用すること、セットアップの詳細、スケーラビリティやパフォーマンスなどの利点、セキュリティ対策について説明します。
 共通の脆弱性に対してRedisを保護するにはどうすればよいですか?
Mar 17, 2025 pm 06:57 PM
共通の脆弱性に対してRedisを保護するにはどうすればよいですか?
Mar 17, 2025 pm 06:57 PM
記事では、強力なパスワード、ネットワークバインディング、コマンドの無効化、認証、暗号化、更新、監視に焦点を当てた脆弱性に対するRedisの保護について説明します。
