

Python クローラーのためにインストールする必要があるもの


世界のクローラーの 80% は Python に基づいて開発されており、クローラーのスキルを学習すると、その後のビッグ データ分析、マイニング、機械学習などに重要なデータ ソースを提供できます。
Python クローラーは関連ライブラリをインストールする必要があります:
Python クローラーに関連するライブラリ:
リクエスト ライブラリ、解析ライブラリ、ストレージ ライブラリ、ツール ライブラリ
1. リクエスト ライブラリ: urllib/re/requests
(1) urllib/re は Python にデフォルトで付属するライブラリで、次のコマンドで確認できます:
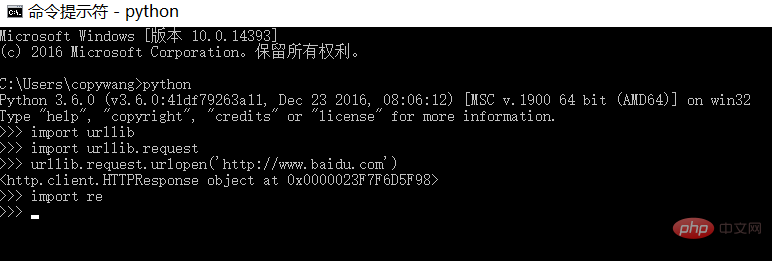
エラーメッセージは出力されず、環境が正常であることを示します
(2) インストールを要求します
2.1 CMD を開き、
pip3 install requests
 ## (3) Selenium のインストール (Web サイトへのアクセス動作のためにブラウザを駆動します)
## (3) Selenium のインストール (Web サイトへのアクセス動作のためにブラウザを駆動します)
3.1 CMD を開いて
と入力しますpip3 install selenium
3.2 chromedriver をインストールします
Web サイト: https://npm.taovao.org/
ダウンロードした圧縮パッケージを解凍し、exe を D:\Python3.6.0\Scripts\ に置きます
このパスは PATH 変数にのみ必要です
3.3 インストールが完了したら、確認してください
 Enter キーを押してクロムブラウザ インターフェースがポップアップ表示されます
Enter キーを押してクロムブラウザ インターフェースがポップアップ表示されます
3.4 他のブラウザをインストールします
#インターフェースレス ブラウザ phantomjsダウンロード URL: http://phantomjs.org/ダウンロード後、解凍してディレクトリ全体を配置します。 D:\Python3.6.0\Scripts\ に移動し、bin ディレクトリへのパスを PATH 変数に追加します。Verification:Open CMDphantomjs console.log('phantomjs') CTRL+C python from selenium import webdriver driver = webdriver.PhantomJS() dirver.get('http://www.baidu.com') driver.page_source
2.1 lxml (XPATH)
pip3 install lxml
pip3 install 文件名.whl
をインストールする必要があります。
pip3 install beautifulsoup4
python from bs4 import BeautifulSoup soup = BeautifulSoup('<html></html>','lxml')
pip3 install pyquery
python from pyquery import PyQuery as pq doc = pq('<html>hi</html>') result = doc('html').text() result
 3.1 pymysql (MySQL、リレーショナル データベースの操作)
3.1 pymysql (MySQL、リレーショナル データベースの操作)
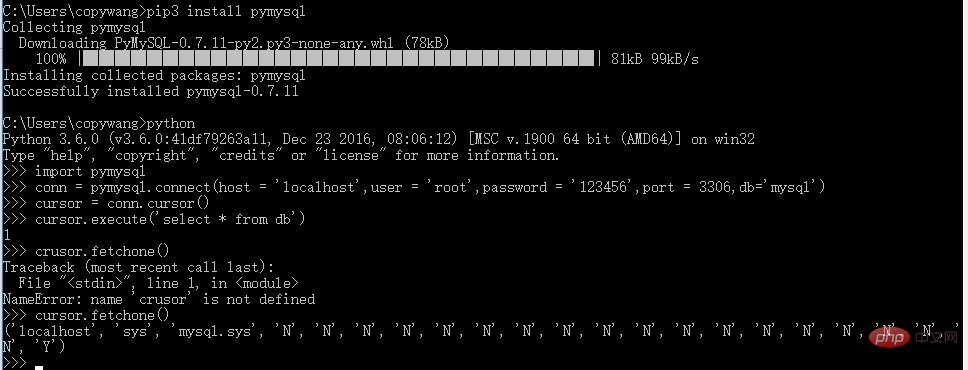
インストール:
pip3 install pymysql
インストール後のテスト:
pip3 install pymongo
python
import pymongo
client = pymongo.MongoClient('localhost')
db = client['testdb']
db['table'].insert({'name':'bob'})
db['table'].find_one({'name':'bob'})3.3 redis (分散クローラー、クローリングキューの維持)
インストール: 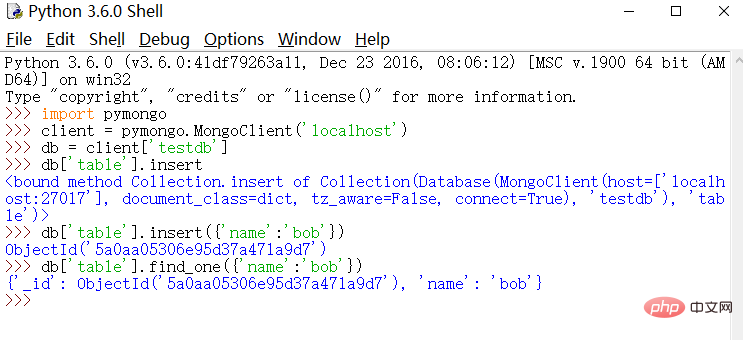
pip3 install redis
4. ツールライブラリ
4.1 flask (WEBライブラリ)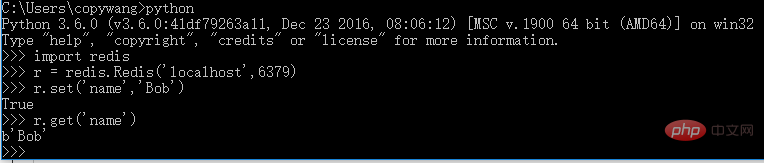
pip3 install flask
4.2 Django (分散クローラメンテナンスシステム) )
pip3 install django
4.3 jupyter (Web ページ上で実行されるメモ帳、マークダウンをサポートし、Web ページ上でコードを実行できます) 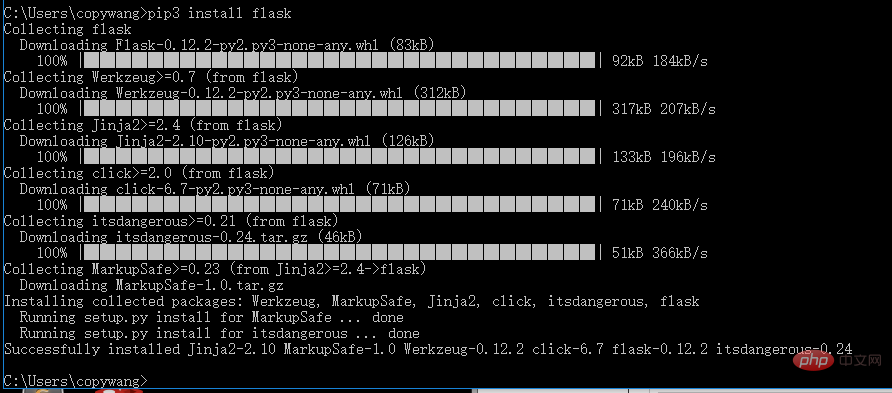
pip3 install jupyter
jupyter notebook
Python クローラーライブラリと関連ツール
2.以上がPython クローラーのためにインストールする必要があるものの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7322
7322
 9
1625
14
1350
46
1262
25
1209
29
9
1625
14
1350
46
1262
25
1209
29

 ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
ランプアーキテクチャの下でnode.jsまたはPythonサービスを効率的に統合する方法は?
Apr 01, 2025 pm 02:48 PM
多くのウェブサイト開発者は、ランプアーキテクチャの下でnode.jsまたはPythonサービスを統合する問題に直面しています:既存のランプ(Linux Apache MySQL PHP)アーキテクチャWebサイトのニーズ...
 LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示するときに発生する権限の問題を解決する方法は?
Apr 01, 2025 pm 05:09 PM
LinuxターミナルでPythonバージョンを表示する際の許可の問題の解決策PythonターミナルでPythonバージョンを表示しようとするとき、Pythonを入力してください...
 Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用するときにパイプラインの永続的なストレージファイルを書き込めない理由は何ですか?
Apr 01, 2025 pm 04:03 PM
Scapy Crawlerを使用する場合、パイプラインの永続的なストレージファイルを書くことができない理由は?ディスカッションデータクローラーにScapy Crawlerを使用することを学ぶとき、あなたはしばしば...
 PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
PythonプロセスプールがTCPリクエストを同時に処理し、クライアントが立ち往生する理由は何ですか?
Apr 01, 2025 pm 04:09 PM
Python Process Poolは、クライアントが立ち往生する原因となる同時TCP要求を処理します。ネットワークプログラミングにPythonを使用する場合、同時のTCP要求を効率的に処理することが重要です。 ...
 Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
Python functools.partialオブジェクトによって内部的にカプセル化された元の関数を表示する方法は?
Apr 01, 2025 pm 04:15 PM
python functools.partialオブジェクトのpython functools.partialを使用してPythonを使用する視聴方法を深く探索します。
 Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発:どのGUIライブラリが最適ですか?
Apr 01, 2025 pm 05:24 PM
Pythonクロスプラットフォームデスクトップアプリケーション開発ライブラリの選択多くのPython開発者は、WindowsシステムとLinuxシステムの両方で実行できるデスクトップアプリケーションを開発したいと考えています...
 Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python hourglassグラフ図面:可変未定義エラーを避ける方法は?
Apr 01, 2025 pm 06:27 PM
Python:Hourglassグラフィック図面と入力検証この記事では、Python NoviceがHourglass Graphic Drawingプログラムで遭遇する可変定義の問題を解決します。コード...
 GoogleとAWSはパブリックピピイメージソースを提供していますか?
Apr 01, 2025 pm 05:15 PM
GoogleとAWSはパブリックピピイメージソースを提供していますか?
Apr 01, 2025 pm 05:15 PM
多くの開発者はPypi(PythonPackageIndex)に依存しています...
