

ブートストラップとブースティングは、機械学習で一般的に使用されるいくつかのリサンプリング手法です。このうち、ブートストラップ リサンプリング法は主に統計量の推定に使用され、ブースティング法は主に複数のサブ分類器の組み合わせに使用されます。

ブートストラップ: 統計を推定するためのリサンプリング方法 (推奨される学習: Python ビデオ チュートリアル )
ブートストラップ法では、サイズ n の元のトレーニング データ セット DD から n 個のサンプル ポイントをランダムに選択して新しいトレーニング セットを形成します。この選択プロセスは独立して B 回繰り返され、これらの B 個のデータ セットを使用してモデル統計が計算されます。推定値 (平均、分散など)。元のデータセットのサイズは n であるため、これら B 個の新しいトレーニング セットには必然的に重複サンプルが存在します。
統計量の推定値は、独立した B トレーニング セットの推定値 θbθb の平均として定義されます。
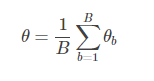
# #boosting:
boosting は k 個のサブ分類子を順番にトレーニングし、最終的な分類結果はこれらのサブ分類子による投票によって決定されます。 まず、サイズ n の元のトレーニング データ セットから n1n1 個のサンプルをランダムに選択して、最初の分類子 (C1C1 と表示) をトレーニングし、次に 2 番目の分類子 C2C2 のトレーニング セット D2D2 を構築します。要件: D2D2 の半分サンプルは C1C1 によって正しく分類できますが、サンプルの残りの半分は C1C1 によって誤分類されます。 次に、3 番目の分類子 C3C3 のトレーニング セット D3D3 の構築を続けます。要件は次のとおりです: C1C1 と C2C2 は、D3D3 のサンプルに対して異なる分類結果を持ちます。残りのサブ分類子も同様の方法でトレーニングされます。 新しいトレーニング セットを構築する際のブースティングの主な原則は、最も有益なサンプルを使用することです。Python チュートリアル 列にアクセスして学習してください。
以上がブースティングとブートストラップの違いの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


















![[Web フロントエンド] Node.js クイック スタート](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



