JavaScript での DOM ノードへのアクセス、作成、変更、削除_基礎知識-jsチュートリアル-php.cn
ホームページ
ウェブフロントエンド
jsチュートリアル
JavaScript での DOM ノードへのアクセス、作成、変更、削除_基礎知識
JavaScript での DOM ノードへのアクセス、作成、変更、削除_基礎知識
May 16, 2016 pm 03:32 PM
dom
javascript
js
ドム DOMはDocument object Modelの略称です。文書オブジェクトモデルは、XMLやHTMLをツリーノードの形で表現した文書である。 DOM メソッドとプロパティを使用すると、ページ上の任意の要素にアクセス、変更、削除でき、また要素を追加することもできます。 DOM は言語に依存しない API であり、JavaScript
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html>
<head>
<title>My page</title>
</head>
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<p id="closer">final</p>
</body>
</html>
ログイン後にコピー
<p><em>second</em> paragraph</p>
ログイン後にコピー
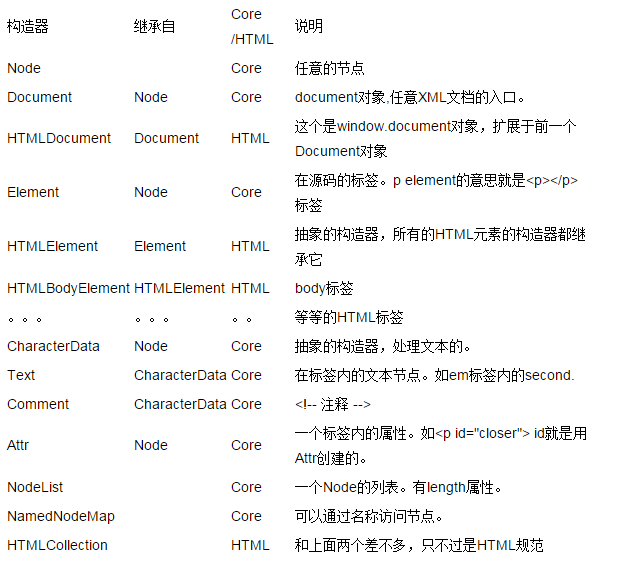
これは p タグであることがわかります。 bodyタグに含まれています。したがって、body は p の親ノードであり、p は子ノードです。最初と 3 番目の段落も本文の子ノードです。これらはすべて 2 番目の段落の兄弟ノードです。この em タグは、2 番目のセグメント p の子ノードです。したがって、 p はその親ノードになります。親子ノード関係は、ツリー状の関係を表すことができます。したがって、DOM ツリーと呼ばれます。コア DOM と HTML DOM DOM で HTML ドキュメントと XML ドキュメントを表現できることはすでにわかっています。実際、HTML ドキュメントは XML ドキュメントですが、より標準化されています。したがって、DOM レベル 1 の一部として、Core DOM 仕様はすべての XML ドキュメントに適用され、HTML DOM 仕様は Core DOM を拡張します。もちろん、HTML DOM はすべての XML ドキュメントに適用されるわけではなく、HTML ドキュメントにのみ適用されます。 Core DOM と HTML DOM のコンストラクターを見てみましょう。 コンストラクター関係
DOM ノードにアクセスします フォームを検証したり画像を変更したりする前に、要素 (element.) にアクセスする方法を知っておく必要があります。要素を取得するにはさまざまな方法があります。 ドキュメントを通じて現在のドキュメントにアクセスできます。 firebugs (Firefox プラグイン) を使用して、ドキュメントのプロパティとメソッドを表示できます。
のnodeTypeを見てみましょう
document.nodeType;//9
ログイン後にコピー
ノードタイプは全部で 12 種類あります。資料は9です。よく使われるのは、要素(要素:1)、属性(属性:2)、テキスト(テキスト:3)です。 documentElement XML にはドキュメントをラップする ROOT ノードがあります。 HTMLドキュメントの場合。 ROOT ノードは html タグです。ルートノードにアクセスします。 documentElement のプロパティを使用できます。
document.documentElement;//<html>
document.documentElement.nodeType;//1
document.documentElement.nodeName;//HTML
document.documentElement.tagName;//对于element,nodeName和tagName相同 ログイン後にコピー
子ノード 子ノードが含まれているかどうかを判断するには、次のメソッドを使用できます
document.documentElement.hasChildNodes();//true
ログイン後にコピー
HTML には 2 つの子ノードがあります。
document.documentElement.childNodes.length;//2
document.documentElement.childNodes[0];//<head>
document.documentElement.childNodes[1];//<body>
ログイン後にコピー
子ノードを通じて親ノードにアクセスすることもできます
document.documentElement.childNodes[1].parentNode;//<html>
ログイン後にコピー
本体の参照を変数
に代入します
var bd = document.documentElement.childNodes[1];
bd.childNodes.length;//9
ログイン後にコピー
体の構造を見てみよう
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<p id="closer">final</p>
<!-- and that's about it -->
</body> ログイン後にコピー
の間の空白ノードです。 最初のノードは空白ノードなので、2 番目のノードが最初の p ラベルになります。
bd.childNodes[1];// <p class="opener">
ログイン後にコピー
属性があるかどうかを確認できます
bd.childNodes[1].hasAttributes();//true
ログイン後にコピー
属性の数も確認できます
bd.childNodes[1].attributes.length;//1
//可以用index和名字来访问属性,也可以用getAttribute方法。
bd.childNodes[1].attributes[0].nodeName;//class
bd.childNodes[1].attributes[0].nodeValue;//opener
bd.childNodes[1].attributes['class'].nodeValue;//opener
bd.childNodes[1].getAttribute('class');//opener
ログイン後にコピー
タグ内のコンテンツにアクセスします 最初のタグ p を見てみましょう
bg.childNodes[1].textContent;// "first paragraph"
ログイン後にコピー
innerHTML という属性もありますが、これは DOM 仕様ではありません。ただし、主要なブラウザはすべてこの属性をサポートしています。返されるのは HTML コードです。
bg.childNodes[1].innerHTML;// "first paragraph"
ログイン後にコピー
最初の段落には HTML コードがないため、結果は textContent (IE の innerText) と同じになります。 HTML コード
を含む 2 番目のタグを見てみましょう。
bd.childNodes[3].innerHTML;//"<em>second</em> paragraph"
bd.childNodes[3].textContent;//second paragraph
ログイン後にコピー
bd.childNodes[1].childNodes.length;//1 子节点个数
bd.childNodes[1].childNodes[0].nodeName;// 节点名称 #text
bd.childNodes[1].childNodes[0].nodeValue;//节点值 first paragraph
ログイン後にコピー
快速访问DOM 通过childNodes,parentNode,nodeName,nodeValue以及attributes,可以访问文档任意的节点了。但是在实际运用过程中,文本节点是比较讨厌的。如果文本改变了,有可能就影响脚本了。还有如果DOM树足够的深入,那么访问起来的确有些不方便。幸好我们可以用更为方便的方法来访问节点。这些方法是
getElementsByTagName()
getElementsByName()
getElementById()
ログイン後にコピー
首先说下getElementsByTagName()
document.getElementsByTagName('p').length;//3
ログイン後にコピー
因为返回的是个集合,我们可以用过数组下标的形式来访问或者通过item方法。比较一下还是推荐用数组的访问方法。更简单一些。
document.getElementsByTagName('p')[0];// <p class="opener">
document.getElementsByTagName('p').item(0);//和上面的结果一样
document.getElementsByTagName('p')[0].innerHTML;//first paragraph
ログイン後にコピー
document.getElementsByTagName('p')[2].id;//closer
ログイン後にコピー
要注意的是,class属性不能正常的使用。。要用className。因为class在javascript规范中是保留字。
document.getElementsByTagName('p')[0].className;//opener
ログイン後にコピー
我们可以用如下方法访问页面所有元素
<span style="color: #ff0000;">document.getElementsByTagName('*').length;//9</span>
ログイン後にコピー
注意:在IE早期的版本不支持上述方法。可以用document.all来取代。IE7已经支持了,但是返回的是所有节点(node),而不仅仅是元素节点(element nodes)。Siblings, Body, First, Last Child nextSibling和previousSibling是两个比较方便访问DOM的方法。用来访问相邻的节点的。例子如下
var para = document.getElementById('closer')
para.nextSibling;//"\n"
para.previousSibling;//"\n"
para.previousSibling.previousSibling;//<p>
para.previousSibling.previousSibling.previousSibling;//"\n"
para.previousSibling.previousSibling.nextSibling.nextSibling;// <p id="closer">
ログイン後にコピー
document.body;//<body>
ログイン後にコピー
firstChild 和lastChild 。firstChild是和childNodes[0]一样.lastChild和 childNodes[childNodes.length - 1]一样。遍历DOM 通过以上的学习,我们可以写个函数,用来遍历DOM
function walkDOM(n) {
do {
alert(n);
if (n.hasChildNodes()) {
walkDOM(n.firstChild)
}
} while (n = n.nextSibling)
}
walkDOM(document.body);//测试
ログイン後にコピー
修改节点 下面来看看DOM节点的修改。
var my = document.getElementById('closer');
ログイン後にコピー
非常容易更改这个元素的属性。我们可以更改innerHTML.
my.innerHTML = 'final';//final
ログイン後にコピー
因为innerHTML可以写入html,所以我们来修改html。
my.innerHTML = '<em>my</em> final';//<em>my</em> fnal
ログイン後にコピー
em标签已经成为dom树的一部分了。我们可以测试一下
my.firstChild;//<em>
my.firstChild.firstChild;//my
ログイン後にコピー
我们也可以通过nodeValue来改变值。
my.firstChild.firstChild.nodeValue = 'your';//your
ログイン後にコピー
修改样式 大部分修改节点可能都是修改样式。元素节点有style属性用来修改样式。style的属性和css属性是一一对应的。如下代码
my.style.border = "1px solid red";
ログイン後にコピー
CSS属性很多都有破折号("-"),如padding-top,这在javascript中是不合法的。这样的话一定要省略波折号并把第二个词的开头字母大写,规范如下。 margin-left变为marginLeft。依此类推
my.style.fontWeight = 'bold';
ログイン後にコピー
我们还可以修改其他的属性,无论这些属性是否被初始化。
my.align = "right";
my.name = 'myname';
my.id = 'further';
my;//<p id="further" align="right" style="border: 1px solid red; font-weight: bold;">
ログイン後にコピー
为了创建一个新的节点,可以使用createElement和createTextNode.如果新建完成,可以用appendChild()把节点添加到DOM树中。
var myp = document.createElement('p');
myp.innerHTML = 'yet another';
ログイン後にコピー
myp.style.border = '2px dotted blue'
ログイン後にコピー
接下来可以用appendChild把新的节点添加到DOM树中的。
document.body.appendChild(myp)
ログイン後にコピー
使用DOM的方法 用innerHTML方法的确很简单,我们可以用纯的dom方法来实现上面的功能。
新建一个文本节点(yet another)
新建一个段落
把文本节点添加到段落中。
把段落添加到body中
// 创建p
var myp = document.createElement('p');
// 创建一个文本节点
var myt = document.createTextNode('one more paragraph')
myp.appendChild(myt);
// 创建一个STRONG元素
var str = document.createElement('strong');
str.appendChild(document.createTextNode('bold'));
// 把STRONG元素添加到P中
myp.appendChild(str);
// 把P元素添加到BODY中
document.body.appendChild(myp);
//结果<p>one more paragraph<strong>bold</strong></p>
cloneNode()
ログイン後にコピー
另一种新建节点的方法是,我们可以用cloneNode来复制一个节点。cloneNode()可以传入一个boolean参数。如果为true就是深度复制,包括他的子节点,false,仅仅复制自己。
var el = document.getElementsByTagName('p')[1];//<p><em>second</em> paragraph</p>
ログイン後にコピー
先不用深度复制。
document.body.appendChild(el.cloneNode(false))
ログイン後にコピー
我们发现页面并没有变化,因为仅仅复制的是元素p。和下面的效果一样。
document.body.appendChild(document.createElement('p'));
ログイン後にコピー
如果用深度复制,包括p下面所有的子节点都会被复制。当然包括文本节点和EM元素。
document.body.appendChild(el.cloneNode(true))
ログイン後にコピー
insertBefore() 用appendChild,就是把元素添加到最后。而insertBefore方法可以更精确控制插入元素的位置。
elementNode.insertBefore(new_node,existing_node)
ログイン後にコピー
实例
document.body.insertBefore(
document.createTextNode('boo!'),
document.body.firstChild
); ログイン後にコピー
删除节点
要从DOM树删除一个节点,我们可以使用removeChild().我们来看看要操作的HTML
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<p id="closer">final</p>
<!-- and that's about it -->
</body>
ログイン後にコピー
来看看下面代码,删除第二段
var myp = document.getElementsByTagName('p')[1];
var removed = document.body.removeChild(myp);
ログイン後にコピー
removed节点就是删除的节点。以后还可以用这删除的节点。
<body>
<p class="opener">first paragraph</p>
<p id="closer">final</p>
<!-- and that's about it -->
</body>
ログイン後にコピー
我们来看看replaceChild的使用。我们把上一个删除节点来替代第二个p
var replaced = document.body.replaceChild(removed, p);
ログイン後にコピー
和removeChild返回一样。replaced就是移除的节点。现在结果为
<body>
<p class="opener">first paragraph</p>
<p><em>second</em> paragraph</p>
<!-- and that's about it -->
</body>
ログイン後にコピー
このウェブサイトの声明
この記事の内容はネチズンが自主的に寄稿したものであり、著作権は原著者に帰属します。このサイトは、それに相当する法的責任を負いません。盗作または侵害の疑いのあるコンテンツを見つけた場合は、admin@php.cn までご連絡ください。
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法
Dec 17, 2023 pm 02:54 PM
WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法 はじめに: 技術の継続的な発展により、音声認識技術は人工知能の分野の重要な部分になりました。 WebSocket と JavaScript をベースとしたオンライン音声認識システムは、低遅延、リアルタイム、クロスプラットフォームという特徴があり、広く使用されるソリューションとなっています。この記事では、WebSocket と JavaScript を使用してオンライン音声認識システムを実装する方法を紹介します。
株価分析に必須のツール: PHP と JS を使用してローソク足チャートを描画する手順を学びます
Dec 17, 2023 pm 06:55 PM
株式分析に必須のツール: PHP および JS でローソク足チャートを描画する手順を学びます。特定のコード例が必要です。インターネットとテクノロジーの急速な発展に伴い、株式取引は多くの投資家にとって重要な方法の 1 つになりました。株価分析は投資家の意思決定の重要な部分であり、ローソク足チャートはテクニカル分析で広く使用されています。 PHP と JS を使用してローソク足チャートを描画する方法を学ぶと、投資家がより適切な意思決定を行うのに役立つ、より直感的な情報が得られます。ローソク足チャートとは、株価をローソク足の形で表示するテクニカルチャートです。株価を示しています
推奨: 優れた JS オープンソースの顔検出および認識プロジェクト
Apr 03, 2024 am 11:55 AM
顔の検出および認識テクノロジーは、すでに比較的成熟しており、広く使用されているテクノロジーです。現在、最も広く使用されているインターネット アプリケーション言語は JS ですが、Web フロントエンドでの顔検出と認識の実装には、バックエンドの顔認識と比較して利点と欠点があります。利点としては、ネットワーク インタラクションの削減とリアルタイム認識により、ユーザーの待ち時間が大幅に短縮され、ユーザー エクスペリエンスが向上することが挙げられます。欠点としては、モデル サイズによって制限されるため、精度も制限されることが挙げられます。 js を使用して Web 上に顔検出を実装するにはどうすればよいですか? Web 上で顔認識を実装するには、JavaScript、HTML、CSS、WebRTC など、関連するプログラミング言語とテクノロジに精通している必要があります。同時に、関連するコンピューター ビジョンと人工知能テクノロジーを習得する必要もあります。 Web 側の設計により、次の点に注意してください。
WebSocket と JavaScript: リアルタイム監視システムを実装するための主要テクノロジー
Dec 17, 2023 pm 05:30 PM
WebSocketとJavaScript:リアルタイム監視システムを実現するためのキーテクノロジー はじめに: インターネット技術の急速な発展に伴い、リアルタイム監視システムは様々な分野で広く利用されています。リアルタイム監視を実現するための重要なテクノロジーの 1 つは、WebSocket と JavaScript の組み合わせです。この記事では、リアルタイム監視システムにおける WebSocket と JavaScript のアプリケーションを紹介し、コード例を示し、その実装原理を詳しく説明します。 1.WebSocketテクノロジー
PHP および JS 開発のヒント: 株価ローソク足チャートの描画方法をマスターする
Dec 18, 2023 pm 03:39 PM
インターネット金融の急速な発展に伴い、株式投資を選択する人がますます増えています。株式取引では、ローソク足チャートは一般的に使用されるテクニカル分析手法であり、株価の変化傾向を示し、投資家がより正確な意思決定を行うのに役立ちます。この記事では、PHP と JS の開発スキルを紹介し、株価ローソク足チャートの描画方法を読者に理解してもらい、具体的なコード例を示します。 1. 株のローソク足チャートを理解する 株のローソク足チャートの描き方を紹介する前に、まずローソク足チャートとは何かを理解する必要があります。ローソク足チャートは日本人が開発した
JavaScript と WebSocket を使用してリアルタイムのオンライン注文システムを実装する方法
Dec 17, 2023 pm 12:09 PM
JavaScript と WebSocket を使用してリアルタイム オンライン注文システムを実装する方法の紹介: インターネットの普及とテクノロジーの進歩に伴い、ますます多くのレストランがオンライン注文サービスを提供し始めています。リアルタイムのオンライン注文システムを実装するには、JavaScript と WebSocket テクノロジを使用できます。 WebSocket は、TCP プロトコルをベースとした全二重通信プロトコルで、クライアントとサーバー間のリアルタイム双方向通信を実現します。リアルタイムオンラインオーダーシステムにおいて、ユーザーが料理を選択して注文するとき
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築
Dec 17, 2023 pm 05:13 PM
JavaScript と WebSocket: 効率的なリアルタイム天気予報システムの構築 はじめに: 今日、天気予報の精度は日常生活と意思決定にとって非常に重要です。テクノロジーの発展に伴い、リアルタイムで気象データを取得することで、より正確で信頼性の高い天気予報を提供できるようになりました。この記事では、JavaScript と WebSocket テクノロジを使用して効率的なリアルタイム天気予報システムを構築する方法を学びます。この記事では、具体的なコード例を通じて実装プロセスを説明します。私たちは
簡単な JavaScript チュートリアル: HTTP ステータス コードを取得する方法
Jan 05, 2024 pm 06:08 PM
JavaScript チュートリアル: HTTP ステータス コードを取得する方法、特定のコード例が必要です 序文: Web 開発では、サーバーとのデータ対話が頻繁に発生します。サーバーと通信するとき、多くの場合、返された HTTP ステータス コードを取得して操作が成功したかどうかを判断し、さまざまなステータス コードに基づいて対応する処理を実行する必要があります。この記事では、JavaScript を使用して HTTP ステータス コードを取得する方法を説明し、いくつかの実用的なコード例を示します。 XMLHttpRequestの使用
See all articles