

線形連結リストは線形リストの連結された記憶構造ですか?

データ構造内の各データ要素間の関係の複雑さに応じて、データ構造は通常、線形構造と非線形構造の 2 つの主要なタイプに分類されます。
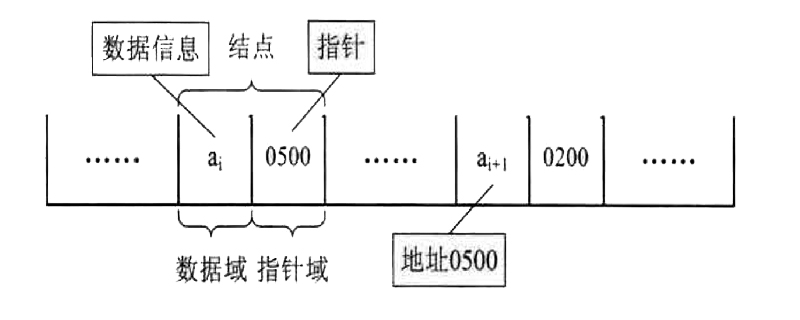
#線形リンク リストは、名前が示すように、チェーン リストに似ています。線形リンク リストの反対は次のとおりです。線形シーケンス リスト両方の違いは、線形シーケンス テーブルはメモリ内に連続領域を開く必要があるため、メモリに格納されるデータの状態は連続的ですが、線形リンク リストのメモリへの格納はランダムであることです。データ間の接続はポインタに依存します。 (推奨学習: Web フロントエンド ビデオ チュートリアル )
空ではないデータ構造が次の 2 つの条件を満たす場合: ①存在するのは 1 つだけですルート ノード ポイント;②各ノードには最大 1 つの前件と最大 1 つの後件があります。データ構造は線形構造と呼ばれ、線形テーブルとも呼ばれます。したがって、線形リスト、スタックとキュー、および線形リンク リストはすべて線形構造ですが、バイナリ ツリーは非線形構造です。 リンクされたストレージ構造を持つ線形テーブル。任意のアドレスを持つ一連のストレージ ユニットを使用して、線形テーブルにデータ要素を格納します。論理的に隣接する要素は物理的に隣接している必要はなく、ランダムにアクセスすることはできません。 。一般にノードによって説明されます: ノード (データ要素を表す) = データ ドメイン (データ要素のイメージ) ポインタ ドメイン (後続の要素の格納場所を示す) チェーン ストレージ構造では、データ構造のストレージデータ要素間の論理関係はポインタフィールドによって決定されますが、空間は不連続である可能性があり、各データノードの格納順序はデータ要素間の論理関係と一致しない可能性があります。連鎖記憶法は、線形構造と非線形構造の両方を表現するために使用できます。 一般に、線形リストの連結記憶構造では、各データノードの記憶シンボルが不連続であり、記憶空間内での各ノードの位置関係や論理関係も不整合となる。線形リンク リストの場合、先頭ポインタから開始して、各ノードのポインタに沿ってリンク リスト内のすべてのノードをスキャンできます。 線形リンク リストの構築は、リンク ポイントを動的に生成し、それらをリンク リストに順番にリンクするプロセスです。線形リンクリストの最初のリンク点のポインタをリストとする。 最初のリンク ポイントが生成されるとき、リンク リストは空です。リンク ポイントをリストに直接送信するだけです。データ要素が取得されるたびに、そのデータ要素に対してリンクポイントが生成され、取得したデータ要素のデータ情報が新規ノードのデータフィールドに送信される一方で、新規ノードのポインタフィールドはNULLに設定され、新しいノードは、リンクされたリストの最後に挿入されます。 次のアルゴリズムは、data.txt という名前のファイルから文字列を線形リンク リストのデータ要素として 1 行ずつ読み取ります。アルゴリズムは次のとおりです:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
以上が線形連結リストは線形リストの連結された記憶構造ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。
人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7814
7814
 15
1646
14
1402
52
1300
25
1236
29
15
1646
14
1402
52
1300
25
1236
29