

Redisメモリモデル(詳細説明)

Redis は、現在最も人気のあるインメモリ データベースの 1 つです。メモリ上でデータを読み書きすることで、読み書き速度が大幅に向上します。Web サイトで高い同時実行性を実現するには、Redis が不可欠な部分であると言えます。 。 [推奨される学習: Redis ビデオ チュートリアル ]

Redis を使用すると、Redis の 5 つのオブジェクト タイプ (文字列、ハッシュ) に触れることになります。 、リスト、コレクション、順序付きコレクションなど)、豊富な型は Memcached などに比べて Redis の大きな利点です。 Redis の 5 つのオブジェクト タイプの使用法と特性を理解した上で、Redis のメモリ モデルをさらに理解することは、Redis の使用に非常に役立ちます。 Redisの使用法。これまでのところ、メモリの使用コストはまだ比較的高く、メモリを無遠慮に使用することはできませんが、ニーズに基づいて Redis のメモリ使用量を合理的に評価し、適切なマシン構成を選択することで、ニーズを満たしながらコストを削減できます。
2. メモリ使用量を最適化します。 Redis メモリ モデルを理解すると、より適切なデータ型とエンコーディングを選択し、Redis メモリをより効果的に利用できるようになります。
3. 問題を分析して解決します。 Redis でブロックやメモリ使用量などの問題が発生した場合、分析と解決を容易にするために、問題の原因をできるだけ早く発見する必要があります。
この記事では、主に Redis のメモリ モデル (例として 3.0) を紹介します。これには、Redis が占有するメモリとそのクエリ方法、メモリ内のさまざまなオブジェクト タイプのエンコード方法、メモリ アロケータ (jemalloc) が含まれます。 )、シンプル ダイナミック ストリング (SDS)、RedisObject などを説明し、これに基づいていくつかの Redis メモリ モデルのアプリケーションを紹介します。
1. Redis メモリの統計情報
If you want to do your job better, you need first Sharp your tools. Redis メモリについて説明する前に、まず Redis のメモリ使用量をカウントする方法について説明します。
クライアントが redis-cli を介してサーバーに接続した後 (後で特別な指示がない場合、クライアントは常に redis-cli を使用します)、info コマンドを使用してメモリ使用量を確認できます。
info memory
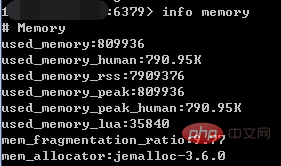 その中で、info コマンドは、基本的なサーバー情報、CPU、メモリ、永続性、クライアント接続情報などを含む、Redis サーバーに関する多くの情報を表示できます。パラメータ。メモリ関連の情報のみが表示されることを示します。
その中で、info コマンドは、基本的なサーバー情報、CPU、メモリ、永続性、クライアント接続情報などを含む、Redis サーバーに関する多くの情報を表示できます。パラメータ。メモリ関連の情報のみが表示されることを示します。
返された結果のより重要な命令のいくつかは次のとおりです:
(1)
used_memory:によって割り当てられたメモリの総量使用される仮想メモリ (つまり、スワップ) を含む Redis アロケータ (単位はバイト)。Redis アロケータについては後で紹介します。 used_memory_human はよりフレンドリーに見えます。 (2)
used_memory_rss: Redis プロセスは、オペレーティング システムのメモリ (単位はバイト) を占有します。これは、上位とで表示される値と一致します。 ps コマンド; used_memory_rss には、アロケーターによって割り当てられたメモリに加えて、プロセス自体の実行に必要なメモリ、メモリ フラグメントなども含まれますが、仮想メモリは含まれません。 したがって、used_memory と used_memory_rss は、前者は Redis から見た量、後者は OS から見た量になります。この 2 つが異なる理由は、メモリの断片化と Redis プロセスの実行に必要なメモリにより前者の方が後者よりも小さくなる可能性がある一方で、仮想メモリの存在により前者の方が小さくなる可能性があるためです。後者よりも大きい。
実際のアプリケーションでは、Redis のデータ量は比較的大きいため、このときに実行中のプロセスが占有するメモリは、Redis データおよびメモリ フラグメントの量よりもはるかに小さいため、比率はused_memory_rss と used_memory の値は Redis のメモリ断片化率を測定するパラメータとなっており、このパラメータが mem_fragmentation_ratio です。
(3)
mem_fragmentation_ratio:メモリ断片化率。この値は used_memory_rss/used_memory の比率です。 mem_fragmentation_ratio は通常 1 より大きく、値が大きいほどメモリの断片化率も大きくなります。 mem_fragmentation_ratio<1, Redis が仮想メモリを使用していることを示します。仮想メモリの媒体はディスクであるため、メモリよりもはるかに遅いです。この状況が発生した場合は、時間内にチェックする必要があります。メモリが不足している場合は、対処する必要があります。 Redis ノードの追加、Redis サーバー メモリの追加、最適化されたアプリケーションなど。
一般的に、mem_fragmentation_ratio は 1.03 (jemalloc の場合) 付近で比較的健全な状態にあります。データが Redis に保存されておらず、Redis プロセス自体が実行されているため、上のスクリーンショットの mem_fragmentation_ratio 値は非常に大きくなっています。メモリにより、used_memory_rss は used_memory よりもはるかに大きくなります。
(4)
mem_allocator: Redis によって使用されるメモリ アロケーターはコンパイル時に指定され、libc、jemalloc、または tcmalloc のいずれかが可能で、デフォルトは jemalloc です。スクリーンショットで使用されています。デフォルトは jemalloc です。 2. Redis のメモリ部門
Redis はインメモリ データベースであり、メモリに格納される内容は主にデータ (キーと値のペア) であることが、前の説明からわかります。データに加えて、Redis の他の部分もメモリを消費します。
Redis のメモリ使用量は、主に次の部分に分けることができます:
1. データ
データベースとして、データは最も重要な部分であり、メモリが占有するのはデータです。この部分の統計は used_memory にあります。
Redis はキーと値のペアを使用してデータを保存し、値 (オブジェクト) には文字列、ハッシュ、リスト、セット、順序付きセットの 5 つのタイプが含まれます。これら 5 つのタイプは、Redis によって外部に提供されます。実際、Redis 内では、各タイプは 2 つ以上の内部エンコーディング実装を持つことができます。さらに、Redis がオブジェクトを格納するとき、データをメモリに直接スローするのではなく、オブジェクトredisObject、SDS など、さまざまな方法でパッケージ化されます。この記事では、後ほど Redis でのデータ ストレージの詳細に焦点を当てます。
2. プロセス自体の実行に必要なメモリ
Redis メイン プロセス自体は、コード、定数プールなどの実行にメモリを確実に必要とします。メモリのこの部分は約数メガバイトであり、ほとんどの実稼働環境では、Redis データによって占有されるメモリと比較すると、無視できます。メモリのこの部分は jemalloc によって割り当てられないため、used_memory にはカウントされません。
補足: メインプロセスに加えて、Redis が AOF や RDB 書き換えを実行するときに作成されるサブプロセスなど、Redis によって作成されるサブプロセスの実行もメモリを占有します。もちろん、メモリのこの部分は Redis プロセスに属さないため、used_memory および used_memory_rss にはカウントされません。
3. バッファ メモリ
バッファ メモリには、クライアント バッファ、コピー バックログ バッファ、AOF バッファなどが含まれます。このうち、クライアント バッファには、クライアント接続の入力バッファと出力バッファが格納されます。コピー バックログ バッファはコピー機能の一部に使用され、AOF バッファは AOF 書き換え中に最新の書き込みコマンドを保存するために使用されます。対応する関数を理解する前に、これらのバッファーの詳細を知る必要はありません。メモリーのこの部分は jemalloc によって割り当てられるため、used_memory でカウントされます。
4. メモリの断片化
メモリの断片化は、物理メモリの割り当てとリサイクルのプロセス中に Redis によって生成されます。たとえば、データが頻繁に変更され、データのサイズが大きく異なる場合、redis によって解放された領域が物理メモリに解放されない可能性がありますが、redis はそれを効果的に使用できず、メモリの断片化が発生します。メモリの断片化は used_memory にはカウントされません。
メモリ断片化の生成は、データの操作、データの特性などに関連しており、さらに、使用されるメモリ アロケータにも関連しています。メモリ アロケータが適切に設計されている場合、メモリ断片化の発生を可能な限り減らすことができます。 jemalloc は後で説明しますが、メモリの断片化を制御するのに優れています。
Redis サーバーのメモリの断片化がすでに大きい場合は、再起動後に Redis がバックアップ ファイルからデータを再読み取り、メモリ内で再配置するため、安全に再起動することでメモリの断片化を減らすことができます。 - メモリの断片化を軽減するために、各データに適切なメモリ ユニットを選択します。
3. Redis データ ストレージの詳細
1. 概要
Redis データ ストレージの詳細には、メモリ アロケーター (jemalloc など)、単純な動的文字列 (SDS)、 5 つのオブジェクト タイプと内部エンコーディング、redisObject。具体的な内容を説明する前に、まずこれらの概念の関係について説明します。
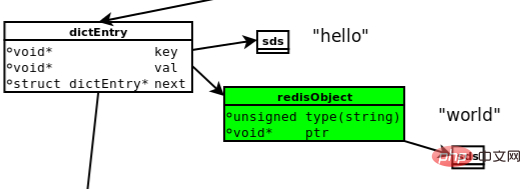
次の図は、set hello world の実行時に関係するデータ モデルです。
画像ソース: https://searchdatabase.techtarget.com.cn/7-20218/
(1) dictEntry: Redis は Key-Value ですデータベースでは、キーと値のペアごとに dictEntry があり、キーと値へのポインターが格納されます。next は、この Key-Value とは関係のない次の dictEntry を指します。
(2) キー: 図の右上隅に見られるように、キー (「hello」) は文字列として直接保存されず、SDS 構造に保存されます。
(3) redisObject: Value("world") は文字列として直接保存されず、Key のように SDS に直接保存されず、redisObject に保存されます。実際、5 つのタイプの Value のいずれであっても、それは redisObject を通じて保存されます。redisObject の type フィールドは Value オブジェクトのタイプを示し、ptr フィールドはオブジェクトのアドレスを指します。ただし、文字列オブジェクトは redisObject によってパッケージ化されていますが、それでも SDS を通じて保存する必要があることがわかります。
実際、redisObject には、type フィールドと ptr フィールドに加えて、オブジェクトの内部エンコーディングを指定するために使用されるフィールドなど、図には示されていない他のフィールドもあります。これらについては後で詳しく説明します。
(4) jemalloc: DictEntry オブジェクト、redisObject、または SDS オブジェクトのいずれであっても、ストレージ用のメモリを割り当てるにはメモリ アロケータ (jemalloc など) が必要です。 DictEntry オブジェクトを例にとると、このオブジェクトは 3 つのポインターで構成され、64 ビット マシン上で 24 バイトを占有し、jemalloc はそれに 32 バイトのメモリ ユニットを割り当てます。
以下では、jemalloc、redisObject、SDS、オブジェクト タイプ、および内部エンコーディングをそれぞれ紹介します。
2. jemalloc
Redis はコンパイル時にメモリ アロケータを指定します; メモリ アロケータには libc、jemalloc、または tcmalloc を指定でき、デフォルトは jemalloc です。
jemalloc は、Redis のデフォルトのメモリ アロケーターとして、メモリの断片化を軽減するのに比較的優れた機能を果たします。 64 ビット システムでは、jemalloc はメモリ空間をスモール、ラージ、ヒュージの 3 つの範囲に分割します。各範囲は多数の小さなメモリ ブロック単位に分割されます。Redis がデータを保存するとき、最適なサイズのメモリ ブロックが選択されます。ストレージ。
jemalloc で分割されるメモリ単位は以下のとおりです。
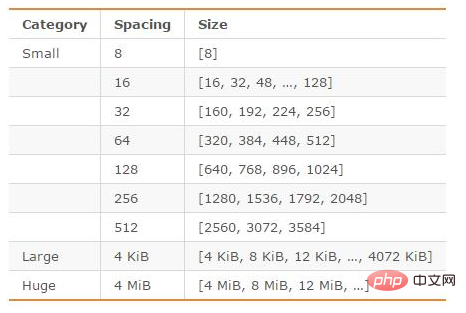
图片来源:http://blog.csdn.net/zhengpeitao/article/details/76573053
例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。
3、redisObject
前面说到,Redis对象有5种类型;无论是哪种类型,Redis都不会直接存储,而是通过redisObject对象进行存储。
redisObject对象非常重要,Redis对象的类型、内部编码、内存回收、共享对象等功能,都需要redisObject支持,下面将通过redisObject的结构来说明它是如何起作用的。
redisObject的定义如下(不同版本的Redis可能稍稍有所不同):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;redisObject的每个字段的含义和作用如下:
(1)type
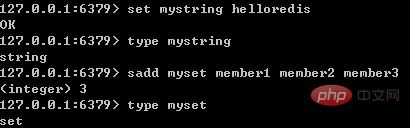
type字段表示对象的类型,占4个比特;目前包括REDIS_STRING(字符串)、REDIS_LIST (列表)、REDIS_HASH(哈希)、REDIS_SET(集合)、REDIS_ZSET(有序集合)。
当我们执行type命令时,便是通过读取RedisObject的type字段获得对象的类型;如下图所示:
(2)encoding
encoding表示对象的内部编码,占4个比特。
对于Redis支持的每种类型,都有至少两种内部编码,例如对于字符串,有int、embstr、raw三种编码。通过encoding属性,Redis可以根据不同的使用场景来为对象设置不同的编码,大大提高了Redis的灵活性和效率。以列表对象为例,有压缩列表和双端链表两种编码方式;如果列表中的元素较少,Redis倾向于使用压缩列表进行存储,因为压缩列表占用内存更少,而且比双端链表可以更快载入;当列表对象元素较多时,压缩列表就会转化为更适合存储大量元素的双端链表。
通过object encoding命令,可以查看对象采用的编码方式,如下图所示:
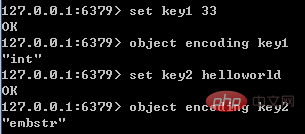
5种对象类型对应的编码方式以及使用条件,将在后面介绍。
(3)lru
lru记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
通过对比lru时间与当前时间,可以计算某个对象的空转时间;object idletime命令可以显示该空转时间(单位是秒)。object idletime命令的一个特殊之处在于它不改变对象的lru值。
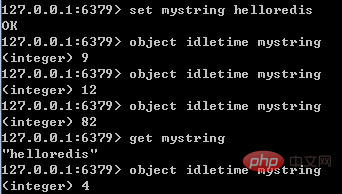
lru值除了通过object idletime命令打印之外,还与Redis的内存回收有关系:如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
(4)refcount
refcount与共享对象
refcount记录的是该对象被引用的次数,类型为整型。refcount的作用,主要在于对象的引用计数和内存回收。当创建新对象时,refcount初始化为1;当有新程序使用该对象时,refcount加1;当对象不再被一个新程序使用时,refcount减1;当refcount变为0时,对象占用的内存会被释放。
Redis中被多次使用的对象(refcount>1),称为共享对象。Redis为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。这个被重复使用的对象,就是共享对象。目前共享对象仅支持整数值的字符串对象。
共享对象的具体实现
Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)。
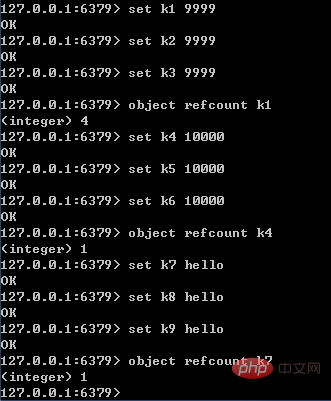
就目前的实现来说,Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;当Redis需要使用值为0~9999的字符串对象时,可以直接使用这些共享对象。10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是OBJ_SHARED_INTEGERS)的值进行改变。
共享对象的引用次数可以通过object refcount命令查看,如下图所示。命令执行的结果页佐证了只有0~9999之间的整数会作为共享对象。
(5)ptr
ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS。
(6)总结
综上所述,redisObject的结构与对象类型、编码、内存回收、共享对象都有关系;一个redisObject对象的大小为16字节:
4bit+4bit+24bit+4Byte+8Byte=16Byte。
4、SDS
Redis没有直接使用C字符串(即以空字符’\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
(1)SDS结构
sds的结构如下:
struct sdshdr {
int len;
int free;
char buf[];
};其中,buf表示字节数组,用来存储字符串;len表示buf已使用的长度,free表示buf未使用的长度。下面是两个例子。
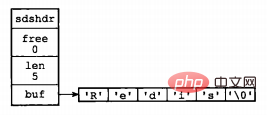
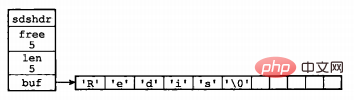
图片来源:《Redis设计与实现》
通过SDS的结构可以看出,buf数组的长度=free+len+1(其中1表示字符串结尾的空字符);所以,一个SDS结构占据的空间为:free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
(2)SDS与C字符串的比较
SDS在C字符串的基础上加入了free和len字段,带来了很多好处:
- 获取字符串长度:SDS是O(1),C字符串是O(n)
- 缓冲区溢出:使用C字符串的API时,如果字符串长度增加(如strcat操作)而忘记重新分配内存,很容易造成缓冲区的溢出;而SDS由于记录了长度,相应的API在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 修改字符串时内存的重分配:对于C字符串,如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。而对于SDS,由于可以记录len和free,因此解除了字符串长度和空间数组长度之间的关联,可以在此基础上进行优化:空间预分配策略(即分配内存时比实际需要的多)使得字符串长度增大时重新分配内存的概率大大减小;惰性空间释放策略使得字符串长度减小时重新分配内存的概率大大减小。
- 存取二进制数据:SDS可以,C字符串不可以。因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而SDS以字符串长度len来作为字符串结束标识,因此没有这个问题。
此外,由于SDS中的buf仍然使用了C字符串(即以’\0’结尾),因此SDS可以使用C字符串库中的部分函数;但是需要注意的是,只有当SDS用来存储文本数据时才可以这样使用,在存储二进制数据时则不行(’\0’不一定是结尾)。
(3)SDS与C字符串的应用
Redis在存储对象时,一律使用SDS代替C字符串。例如set hello world命令,hello和world都是以SDS的形式存储的。而sadd myset member1 member2 member3命令,不论是键(”myset”),还是集合中的元素(”member1”、 ”member2”和”member3”),都是以SDS的形式存储。除了存储对象,SDS还用于存储各种缓冲区。
只有在字符串不会改变的情况下,如打印日志时,才会使用C字符串。
四、Redis的对象类型与内部编码
前面已经说过,Redis支持5种对象类型,而每种结构都有至少两种编码;这样做的好处在于:一方面接口与实现分离,当需要增加或改变内部编码时,用户使用不受影响,另一方面可以根据不同的应用场景切换内部编码,提高效率。
Redis各种对象类型支持的内部编码如下图所示(图中版本是Redis3.0,Redis后面版本中又增加了内部编码,略过不提;本章所介绍的内部编码都是基于3.0的):
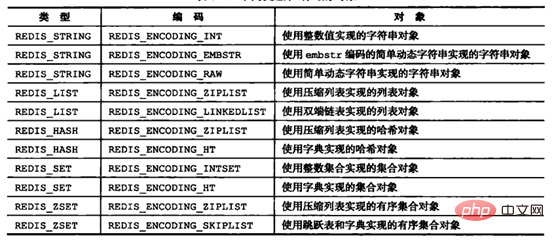
画像出典:「Redis の設計と実装」
Redis の内部エンコーディングの変換に関しては、次の規則に従っています。 エンコーディングの変換はRedisデータの書き込み時に完了し、変換プロセスは不可逆であり、小さいメモリのエンコーディングから大きいメモリのエンコーディングにのみ変換できます。
1. String
(1) 概要
String は、すべてのキーが文字列型であり、文字列である他のいくつかの複雑な型の要素であるため、最も基本的な型です。も文字列です。
文字列の長さは 512MB を超えることはできません。
(2) 内部エンコーディング
文字列型の内部エンコーディングには 3 種類あり、適用シナリオは次のとおりです:
- int: 8 バイト長の整数タイプ。文字列値が整数の場合、値は長整数で表されます。
- embstr: <=39 バイトの文字列。 embstr と raw はどちらも redisObject と sds を使用してデータを保存します。違いは、embstr はメモリ領域を 1 回だけ割り当てる (つまり redisObject と sds は連続的) のに対し、raw はメモリ領域を 2 回割り当てる必要がある (redisObject と sds にそれぞれ領域を割り当てる) ことです。したがって、embstr の利点は、raw と比較して、作成時に領域の割り当てが 1 回少なく、削除時に領域の解放が 1 回少なくなり、オブジェクトのすべてのデータが結合されるため、検索が容易になることです。 embstr の欠点も明らかで、文字列の長さが増加してメモリの再割り当てが必要になった場合、redisObject と sds 全体を再割り当てする必要があるため、redis の embstr は読み取り専用として実装されています。
- raw: 39 バイトを超える文字列
例は次のとおりです。
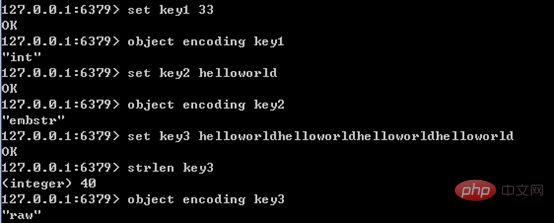
embstr と raw 長さ区別の値は 39 です。これは、redisObject の長さが 16 バイトで、sds の長さが 9 文字列長であるためです。したがって、文字列長が 39 の場合、embstr の長さは正確に 16 9 39=64 となり、jemalloc はこれをちょうど64バイトのメモリユニットを割り当てます。
(3) エンコード変換
int データが整数でなくなった場合、またはサイズがlong の範囲を超えた場合は、自動的に raw に変換されます。
embstr については、その実装が読み取り専用であるため、embstr オブジェクトが変更されると、まず raw に変換されてから変更されます。したがって、embstr オブジェクトが変更される限り、変更されたオブジェクトは39 バイトに達するかどうかに関係なく、生である必要があります。例を以下の図に示します:
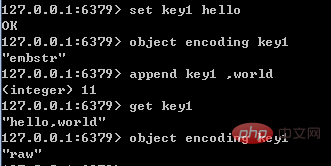
2. List
(1) 概要
List (リスト) は、次の目的で使用されます。複数の要素を格納 順序付けされた文字列。各文字列は要素と呼ばれます。リストには 2^32-1 個の要素を格納できます。 Redisのリストは両端で挿入とポップをサポートしており、指定した位置(または範囲)の要素を取得でき、配列、キュー、スタックなどとして機能します。
(2) 内部エンコーディング
リストの内部エンコーディングは、圧縮リスト (ziplist) または両端リンク リスト (linkedlist) のいずれかです。
両端リンク リスト: リスト構造と複数の listNode 構造で構成されます。典型的な構造は次のとおりです:
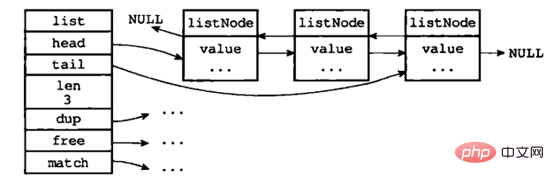
画像ソース: " Redis の設計と実装>>
図からわかるように、両端リンク リストは先頭ポインタと末尾ポインタの両方を保存し、各ノードには前方を指すポインタと後方を指すポインタがあり、ノードの長さはリストはリンク リストに保存されます。ノード値の dup、free、および match セット タイプ固有の関数があるため、リンク リストを使用してさまざまなタイプの値を保存できます。リンクされたリストの各ノードは、タイプが文字列である redisObject を指します。
圧縮リスト: 圧縮リストは、メモリを節約するために Redis によって開発されました。これは、一連の特別にエンコードされた 連続メモリ ブロック (二重メモリ ブロックのようなものではなく) で構成されています。各ノードはポインタで構成される逐次的なデータ構造ですが、具体的な構造は比較的複雑なので省略します。圧縮リストは両端リンクリストと比較してメモリスペースを節約できますが、操作の変更や追加、削除の複雑さが増すため、ノード数が少ない場合は圧縮リストを使用できますが、ノード数が増えると圧縮リストを使用できます。サイズは大きいですが、両端のリンク リストはまだ使用されています。
圧縮リストはリストの実装だけでなく、ハッシュや順序付きリストの実装にも使用され、非常に広く使用されています。
(3) エンコード変換
圧縮リストは、リストの要素数が 512 未満であること、すべての文字列オブジェクトが存在することの 2 つの条件が同時に満たされた場合にのみ使用されます。リスト内の文字数は 64 文字未満です。 1 つの条件が満たされない場合は、両端リストが使用され、エンコードは圧縮リストから両端リンク リストにのみ変換でき、逆方向は不可能です。
次の図は、リストエンコード変換の特徴を示しています。
其中,单个字符串不能超过64字节,是为了便于统一分配每个节点的长度;这里的64字节是指字符串的长度,不包括SDS结构,因为压缩列表使用连续、定长内存块存储字符串,不需要SDS结构指明长度。后面提到压缩列表,也会强调长度不超过64字节,原理与这里类似。
3、哈希
(1)概况
哈希(作为一种数据结构),不仅是redis对外提供的5种对象类型的一种(与字符串、列表、集合、有序结合并列),也是Redis作为Key-Value数据库所使用的数据结构。为了说明的方便,在本文后面当使用“内层的哈希”时,代表的是redis对外提供的5种对象类型的一种;使用“外层的哈希”代指Redis作为Key-Value数据库所使用的数据结构。
(2)内部编码
内层的哈希使用的内部编码可以是压缩列表(ziplist)和哈希表(hashtable)两种;Redis的外层的哈希则只使用了hashtable。
压缩列表前面已介绍。与哈希表相比,压缩列表用于元素个数少、元素长度小的场景;其优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于哈希中元素数量较少,因此操作的时间并没有明显劣势。
hashtable:一个hashtable由1个dict结构、2个dictht结构、1个dictEntry指针数组(称为bucket)和多个dictEntry结构组成。
正常情况下(即hashtable没有进行rehash时)各部分关系如下图所示:
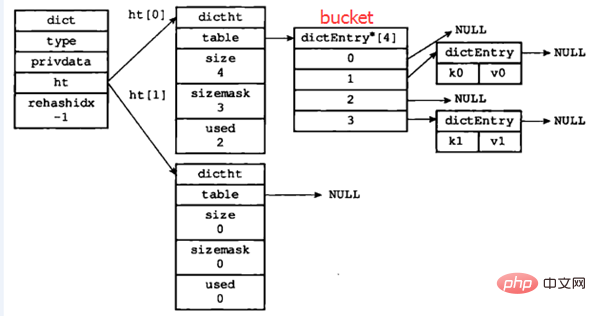
图片改编自:《Redis设计与实现》
下面从底层向上依次介绍各个部分:
dictEntry
dictEntry结构用于保存键值对,结构定义如下:
typedef struct dictEntry{
void *key;
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
struct dictEntry *next;
}dictEntry;其中,各个属性的功能如下:
- key:键值对中的键;
- val:键值对中的值,使用union(即共用体)实现,存储的内容既可能是一个指向值的指针,也可能是64位整型,或无符号64位整型;
- next:指向下一个dictEntry,用于解决哈希冲突问题
在64位系统中,一个dictEntry对象占24字节(key/val/next各占8字节)。
bucket
bucket是一个数组,数组的每个元素都是指向dictEntry结构的指针。redis中bucket数组的大小计算规则如下:大于dictEntry的、最小的2^n;例如,如果有1000个dictEntry,那么bucket大小为1024;如果有1500个dictEntry,则bucket大小为2048。
dictht
dictht结构如下:
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;其中,各个属性的功能说明如下:
- table属性是一个指针,指向bucket;
- size属性记录了哈希表的大小,即bucket的大小;
- used记录了已使用的dictEntry的数量;
- sizemask属性的值总是为size-1,这个属性和哈希值一起决定一个键在table中存储的位置。
dict
一般来说,通过使用dictht和dictEntry结构,便可以实现普通哈希表的功能;但是Redis的实现中,在dictht结构的上层,还有一个dict结构。下面说明dict结构的定义及作用。
dict结构如下:
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
int trehashidx;
} dict;其中,type属性和privdata属性是为了适应不同类型的键值对,用于创建多态字典。
ht属性和trehashidx属性则用于rehash,即当哈希表需要扩展或收缩时使用。ht是一个包含两个项的数组,每项都指向一个dictht结构,这也是Redis的哈希会有1个dict、2个dictht结构的原因。通常情况下,所有的数据都是存在放dict的ht[0]中,ht[1]只在rehash的时候使用。dict进行rehash操作的时候,将ht[0]中的所有数据rehash到ht[1]中。然后将ht[1]赋值给ht[0],并清空ht[1]。
因此,Redis中的哈希之所以在dictht和dictEntry结构之外还有一个dict结构,一方面是为了适应不同类型的键值对,另一方面是为了rehash。
(3)编码转换
如前所述,Redis中内层的哈希既可能使用哈希表,也可能使用压缩列表。
只有同时满足下面两个条件时,才会使用压缩列表:哈希中元素数量小于512个;哈希中所有键值对的键和值字符串长度都小于64字节。如果有一个条件不满足,则使用哈希表;且编码只可能由压缩列表转化为哈希表,反方向则不可能。
下图展示了Redis内层的哈希编码转换的特点:
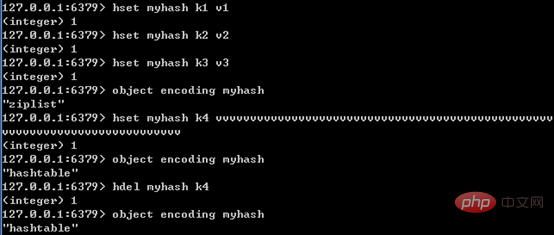
4、集合
(1)概况
集合(set)与列表类似,都是用来保存多个字符串,但集合与列表有两点不同:集合中的元素是无序的,因此不能通过索引来操作元素;集合中的元素不能有重复。
一个集合中最多可以存储2^32-1个元素;除了支持常规的增删改查,Redis还支持多个集合取交集、并集、差集。
(2)内部编码
集合的内部编码可以是整数集合(intset)或哈希表(hashtable)。
哈希表前面已经讲过,这里略过不提;需要注意的是,集合在使用哈希表时,值全部被置为null。
整数集合的结构定义如下:
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;其中,encoding代表contents中存储内容的类型,虽然contents(存储集合中的元素)是int8_t类型,但实际上其存储的值是int16_t、int32_t或int64_t,具体的类型便是由encoding决定的;length表示元素个数。
整数集合适用于集合所有元素都是整数且集合元素数量较小的时候,与哈希表相比,整数集合的优势在于集中存储,节省空间;同时,虽然对于元素的操作复杂度也由O(1)变为了O(n),但由于集合数量较少,因此操作的时间并没有明显劣势。
(3)编码转换
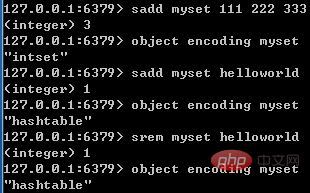
只有同时满足下面两个条件时,集合才会使用整数集合:集合中元素数量小于512个;集合中所有元素都是整数值。如果有一个条件不满足,则使用哈希表;且编码只可能由整数集合转化为哈希表,反方向则不可能。
下图展示了集合编码转换的特点:
5、有序集合
(1)概况
有序集合与集合一样,元素都不能重复;但与集合不同的是,有序集合中的元素是有顺序的。与列表使用索引下标作为排序依据不同,有序集合为每个元素设置一个分数(score)作为排序依据。
(2)内部编码
有序集合的内部编码可以是压缩列表(ziplist)或跳跃表(skiplist)。ziplist在列表和哈希中都有使用,前面已经讲过,这里略过不提。
跳跃表是一种有序数据结构,通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。除了跳跃表,实现有序数据结构的另一种典型实现是平衡树;大多数情况下,跳跃表的效率可以和平衡树媲美,且跳跃表实现比平衡树简单很多,因此redis中选用跳跃表代替平衡树。跳跃表支持平均O(logN)、最坏O(N)的复杂点进行节点查找,并支持顺序操作。Redis的跳跃表实现由zskiplist和zskiplistNode两个结构组成:前者用于保存跳跃表信息(如头结点、尾节点、长度等),后者用于表示跳跃表节点。具体结构相对比较复杂,略。
(3)编码转换
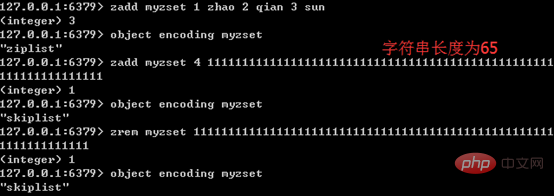
只有同时满足下面两个条件时,才会使用压缩列表:有序集合中元素数量小于128个;有序集合中所有成员长度都不足64字节。如果有一个条件不满足,则使用跳跃表;且编码只可能由压缩列表转化为跳跃表,反方向则不可能。
下图展示了有序集合编码转换的特点:
五、应用举例
了解Redis的内存模型之后,下面通过几个例子说明其应用。
1、估算Redis内存使用量
要估算redis中的数据占据的内存大小,需要对redis的内存模型有比较全面的了解,包括前面介绍的hashtable、sds、redisobject、各种对象类型的编码方式等。
下面以最简单的字符串类型来进行说明。
假设有90000个键值对,每个key的长度是7个字节,每个value的长度也是7个字节(且key和value都不是整数);下面来估算这90000个键值对所占用的空间。在估算占据空间之前,首先可以判定字符串类型使用的编码方式:embstr。
90000个键值对占据的内存空间主要可以分为两部分:一部分是90000个dictEntry占据的空间;一部分是键值对所需要的bucket空间。
每个dictEntry占据的空间包括:
1)一个dictEntry,24字节,jemalloc会分配32字节的内存块
2)一个key,7字节,所以SDS(key)需要7+9=16个字节,jemalloc会分配16字节的内存块
3)一个redisObject,16字节,jemalloc会分配16字节的内存块
4)一个value,7字节,所以SDS(value)需要7+9=16个字节,jemalloc会分配16字节的内存块
5)综上,一个dictEntry需要32+16+16+16=80个字节。
bucket空间:bucket数组的大小为大于90000的最小的2^n,是131072;每个bucket元素为8字节(因为64位系统中指针大小为8字节)。
因此,可以估算出这90000个键值对占据的内存大小为:90000*80 + 131072*8 = 8248576。
下面写个程序在redis中验证一下:
public class RedisTest {
public static Jedis jedis = new Jedis("localhost", 6379);
public static void main(String[] args) throws Exception{
Long m1 = Long.valueOf(getMemory());
insertData();
Long m2 = Long.valueOf(getMemory());
System.out.println(m2 - m1);
}
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aa" + i, "aa" + i); //key和value长度都是7字节,且不是整数
}
}
public static String getMemory(){
String memoryAllLine = jedis.info("memory");
String usedMemoryLine = memoryAllLine.split("\r\n")[1];
String memory = usedMemoryLine.substring(usedMemoryLine.indexOf(':') + 1);
return memory;
}
}运行结果:8247552
理论值与结果值误差在万分之1.2,对于计算需要多少内存来说,这个精度已经足够了。之所以会存在误差,是因为在我们插入90000条数据之前redis已分配了一定的bucket空间,而这些bucket空间尚未使用。
作为对比将key和value的长度由7字节增加到8字节,则对应的SDS变为17个字节,jemalloc会分配32个字节,因此每个dictEntry占用的字节数也由80字节变为112字节。此时估算这90000个键值对占据内存大小为:90000*112 + 131072*8 = 11128576。
在redis中验证代码如下(只修改插入数据的代码):
public static void insertData(){
for(int i = 10000; i < 100000; i++){
jedis.set("aaa" + i, "aaa" + i); //key和value长度都是8字节,且不是整数
}
}运行结果:11128576;估算准确。
对于字符串类型之外的其他类型,对内存占用的估算方法是类似的,需要结合具体类型的编码方式来确定。
2、优化内存占用
了解redis的内存模型,对优化redis内存占用有很大帮助。下面介绍几种优化场景。
(1)利用jemalloc特性进行优化
上一小节所讲述的90000个键值便是一个例子。由于jemalloc分配内存时数值是不连续的,因此key/value字符串变化一个字节,可能会引起占用内存很大的变动;在设计时可以利用这一点。
例如,如果key的长度如果是8个字节,则SDS为17字节,jemalloc分配32字节;此时将key长度缩减为7个字节,则SDS为16字节,jemalloc分配16字节;则每个key所占用的空间都可以缩小一半。
(2)使用整型/长整型
如果是整型/长整型,Redis会使用int类型(8字节)存储来代替字符串,可以节省更多空间。因此在可以使用长整型/整型代替字符串的场景下,尽量使用长整型/整型。
(3)共享对象
利用共享对象,可以减少对象的创建(同时减少了redisObject的创建),节省内存空间。目前redis中的共享对象只包括10000个整数(0-9999);可以通过调整REDIS_SHARED_INTEGERS参数提高共享对象的个数;例如将REDIS_SHARED_INTEGERS调整到20000,则0-19999之间的对象都可以共享。
考虑这样一种场景:论坛网站在redis中存储了每个帖子的浏览数,而这些浏览数绝大多数分布在0-20000之间,这时候通过适当增大REDIS_SHARED_INTEGERS参数,便可以利用共享对象节省内存空间。
(4)避免过度设计
然而需要注意的是,不论是哪种优化场景,都要考虑内存空间与设计复杂度的权衡;而设计复杂度会影响到代码的复杂度、可维护性。
如果数据量较小,那么为了节省内存而使得代码的开发、维护变得更加困难并不划算;还是以前面讲到的90000个键值对为例,实际上节省的内存空间只有几MB。但是如果数据量有几千万甚至上亿,考虑内存的优化就比较必要了。
3、关注内存碎片率
内存碎片率是一个重要的参数,对redis 内存的优化有重要意义。
如果内存碎片率过高(jemalloc在1.03左右比较正常),说明内存碎片多,内存浪费严重;这时便可以考虑重启redis服务,在内存中对数据进行重排,减少内存碎片。
如果内存碎片率小于1,说明redis内存不足,部分数据使用了虚拟内存(即swap);由于虚拟内存的存取速度比物理内存差很多(2-3个数量级),此时redis的访问速度可能会变得很慢。因此必须设法增大物理内存(可以增加服务器节点数量,或提高单机内存),或减少redis中的数据。
要减少redis中的数据,除了选用合适的数据类型、利用共享对象等,还有一点是要设置合理的数据回收策略(maxmemory-policy),当内存达到一定量后,根据不同的优先级对内存进行回收。
以上がRedisメモリモデル(詳細説明)の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

SublimeText3 中国語版
中国語版、とても使いやすい

ゼンドスタジオ 13.0.1
強力な PHP 統合開発環境

ドリームウィーバー CS6
ビジュアル Web 開発ツール

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)
ホットトピック
 7504
7504
 15
1378
52
78
11
19
55
15
1378
52
78
11
19
55

 Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードの構築方法
Apr 10, 2025 pm 10:15 PM
Redisクラスターモードは、シャードを介してRedisインスタンスを複数のサーバーに展開し、スケーラビリティと可用性を向上させます。構造の手順は次のとおりです。異なるポートで奇妙なRedisインスタンスを作成します。 3つのセンチネルインスタンスを作成し、Redisインスタンスを監視し、フェールオーバーを監視します。 Sentinel構成ファイルを構成し、Redisインスタンス情報とフェールオーバー設定の監視を追加します。 Redisインスタンス構成ファイルを構成し、クラスターモードを有効にし、クラスター情報ファイルパスを指定します。各Redisインスタンスの情報を含むnodes.confファイルを作成します。クラスターを起動し、CREATEコマンドを実行してクラスターを作成し、レプリカの数を指定します。クラスターにログインしてクラスター情報コマンドを実行して、クラスターステータスを確認します。作る
 Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redisコマンドの使用方法
Apr 10, 2025 pm 08:45 PM
Redis指令を使用するには、次の手順が必要です。Redisクライアントを開きます。コマンド(動詞キー値)を入力します。必要なパラメーターを提供します(指示ごとに異なります)。 Enterを押してコマンドを実行します。 Redisは、操作の結果を示す応答を返します(通常はOKまたは-ERR)。
 Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisでサーバーを開始する方法
Apr 10, 2025 pm 08:12 PM
Redisサーバーを起動する手順には、以下が含まれます。オペレーティングシステムに従ってRedisをインストールします。 Redis-Server(Linux/Macos)またはRedis-Server.exe(Windows)を介してRedisサービスを開始します。 Redis-Cli ping(Linux/macos)またはRedis-Cli.exePing(Windows)コマンドを使用して、サービスステータスを確認します。 Redis-Cli、Python、node.jsなどのRedisクライアントを使用して、サーバーにアクセスします。
 基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
基礎となるRedisを実装する方法
Apr 10, 2025 pm 07:21 PM
Redisはハッシュテーブルを使用してデータを保存し、文字列、リスト、ハッシュテーブル、コレクション、注文コレクションなどのデータ構造をサポートします。 Redisは、スナップショット(RDB)を介してデータを維持し、書き込み専用(AOF)メカニズムを追加します。 Redisは、マスタースレーブレプリケーションを使用して、データの可用性を向上させます。 Redisは、シングルスレッドイベントループを使用して接続とコマンドを処理して、データの原子性と一貫性を確保します。 Redisは、キーの有効期限を設定し、怠zyな削除メカニズムを使用して有効期限キーを削除します。
 Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法
Apr 10, 2025 pm 10:06 PM
Redisデータをクリアする方法:Flushallコマンドを使用して、すべての重要な値をクリアします。 FlushDBコマンドを使用して、現在選択されているデータベースのキー値をクリアします。 [選択]を使用してデータベースを切り替え、FlushDBを使用して複数のデータベースをクリアします。 DELコマンドを使用して、特定のキーを削除します。 Redis-CLIツールを使用してデータをクリアします。
 Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisキューの読み方
Apr 10, 2025 pm 10:12 PM
Redisのキューを読むには、キュー名を取得し、LPOPコマンドを使用して要素を読み、空のキューを処理する必要があります。特定の手順は次のとおりです。キュー名を取得します:「キュー:キュー」などの「キュー:」のプレフィックスで名前を付けます。 LPOPコマンドを使用します。キューのヘッドから要素を排出し、LPOP Queue:My-Queueなどの値を返します。空のキューの処理:キューが空の場合、LPOPはnilを返し、要素を読む前にキューが存在するかどうかを確認できます。
 Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisのソースコードを読み取る方法
Apr 10, 2025 pm 08:27 PM
Redisソースコードを理解する最良の方法は、段階的に進むことです。Redisの基本に精通してください。開始点として特定のモジュールまたは機能を選択します。モジュールまたは機能のエントリポイントから始めて、行ごとにコードを表示します。関数コールチェーンを介してコードを表示します。 Redisが使用する基礎となるデータ構造に精通してください。 Redisが使用するアルゴリズムを特定します。
 Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisロックの使用方法
Apr 10, 2025 pm 08:39 PM
Redisを使用して操作をロックするには、setnxコマンドを介してロックを取得し、有効期限を設定するために有効期限コマンドを使用する必要があります。特定の手順は次のとおりです。(1)SETNXコマンドを使用して、キー価値ペアを設定しようとします。 (2)expireコマンドを使用して、ロックの有効期限を設定します。 (3)Delコマンドを使用して、ロックが不要になったときにロックを削除します。
